random recording 随心记录
What seems to us as bitter trials are often blessings in disguise.
看起来对我们痛苦的试炼,常常是伪装起来的好运。
递归
背景导入
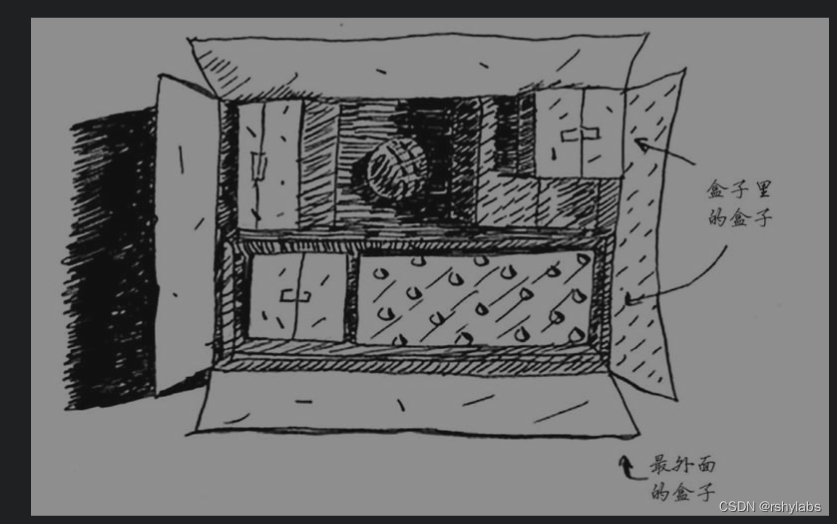
在一个盒中盒找钥匙
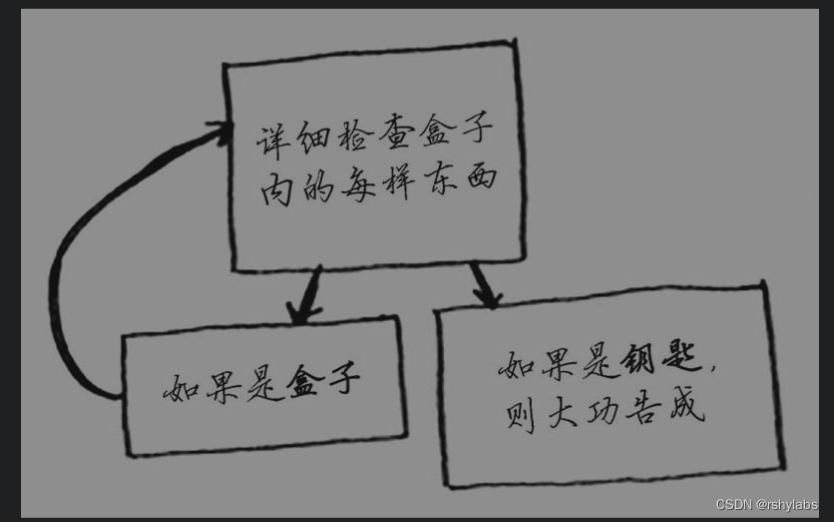
第一种实现方法,如下图
第二种方法,如图
两种方法伪代码实现
第一种,递归
# 第一种 递归 伪代码
def look_for_key(box):
for item in box:
if item.is_box():
look_for_key(item)
else:
print("找到钥匙")
第二种,while循环
# 第二种 while循环 伪代码
def look_for_key(box):
pile = box.make_pile_to_look_through()
while pile is not empty:
b = pile.grap_box()
for item in b:
if item.is_box():
pile.append(item)
else:
print("找到")
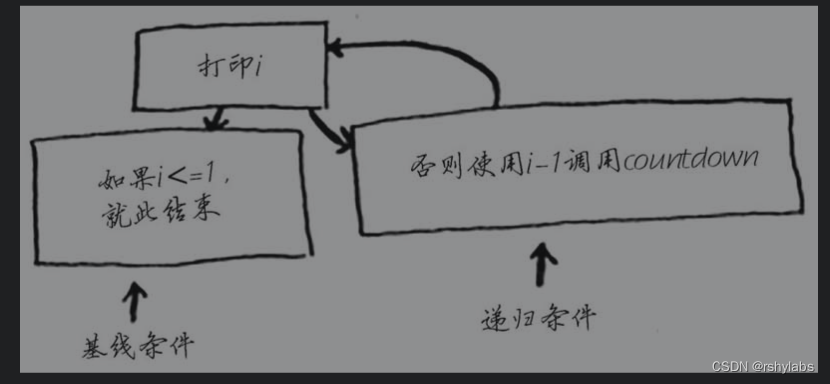
极限条件和递归条件
编写递归函数时,必须告诉它何时停止递归。正因为如此,每个递归函数都有两部分:基线条件(base case)和递归条件(recursive case)。递归条件指的是函数调用自己,而基线条件则指的是函数不再调用自己,从而避免形成无限循环。
计数方法示例
def count_num(n):
if n < 0: # 基线条件
return
print(n)
return count_num(n-1) # 递归条件
count_num(10)
栈
引入
假设你去野外烧烤,并为此创建了一个待办事项清单——一叠便条。对比之前的数组和链表实现待办清单,一叠便条要简单得多:插入的待办事项放在清单的最前面;读取待办事项时,你只读取最上面的那个,并将其删除。因此这个待办事项清单只有两种操作:压入(插入)和弹出(删除并读取),这种数据结构称为栈。
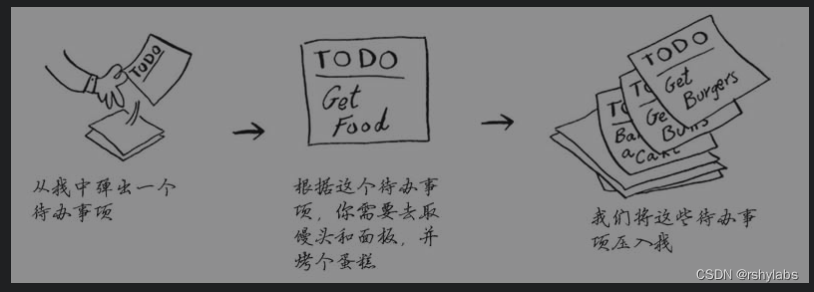
调用栈(call stack)
函数调用栈
# 函数调用栈
def greet(name):
print('hello,'+name+'!')
greet2(name)
print('ready to say -bye')
bye()
def greet2(name):
print('how are you,'+name)
def bye():
print('bye~')
greet('kangkang')
以上计算机内部实现过程:
先调用greet方法,计算机为该方法分配内存,变量名kangkang,被存储到内存中,每次调用方法都执行该操作。

然后执行print,打印 hello,kangkang!接下来,调用greet2方法,并分配第二块内存,置于greet方法内存之上,执行greet2内部print,打印 how are you,kangkang,最后,销毁第二块内存调用。
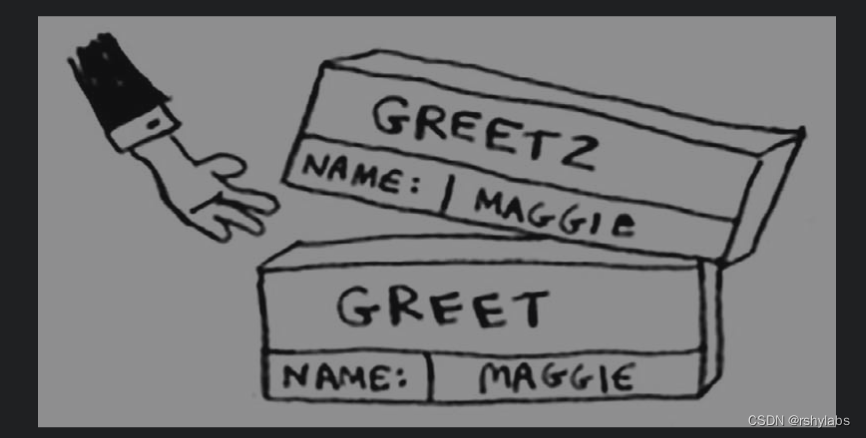
同样,继续调用bye方法,分配内存,置于greet方法内存之上,执行内部print,打印bye~,销毁此内存,最后再销毁greet内存。

以上过程就是函数调用栈实现,分配和销毁内存对应压栈和出栈操作,是一种先进后出的数据结构。
递归调用栈
阶乘方法
def factorial(n):
if n == 1:
return 1
return n*factorial(n-1)
print(factorial(5))
图解调用过程:
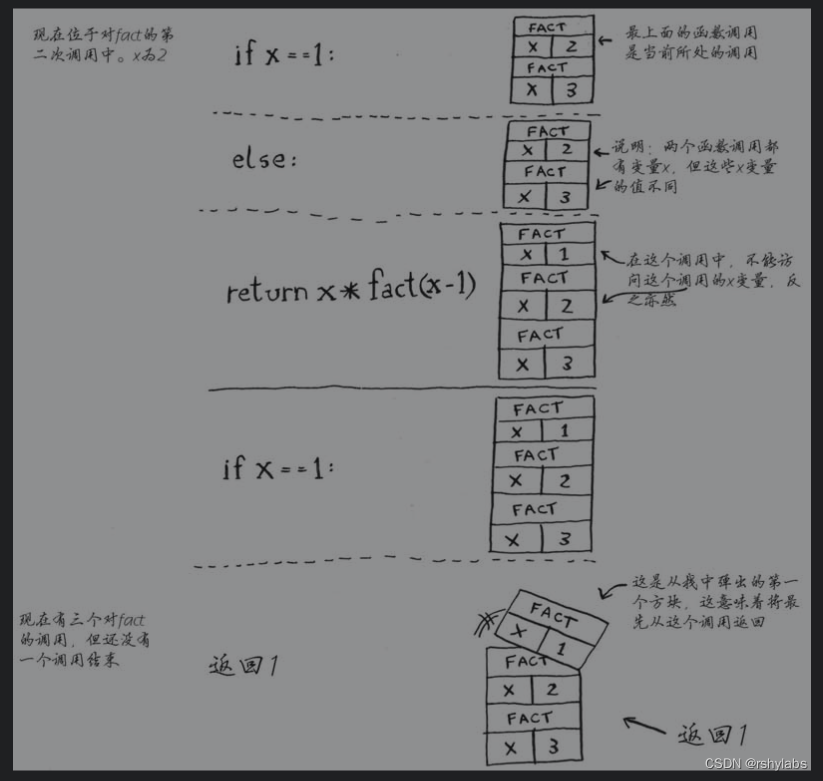
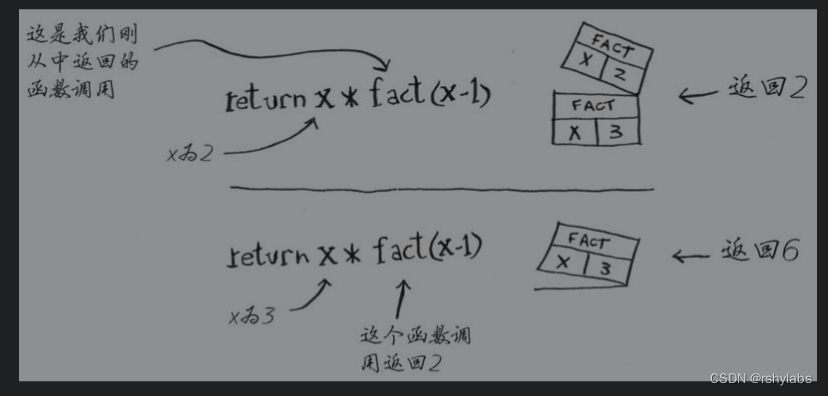
使用栈虽然很方便,但是也要付出代价:存储详尽的信息可能占用大量的内存。每个函数调用都要占用一定的内存,如果栈很高,就意味着计算机存储了大量函数调用的信息。在这种情况下,有两种选择:
重新编写代码,转而使用循环。
使用尾递归。
小结
- 递归指的是调用自己的函数。
- 每个递归函数都有两个条件:基线条件和递归条件。
- 栈有两种操作:压入和弹出。
- 所有函数调用都进入调用栈。
- 调用栈可能很长,这将占用大量的内存。


![[附源码]java毕业设计游戏战队考核系统](https://img-blog.csdnimg.cn/a54ed513fc89414daa4d75975c3f043f.png)

![[附源码]java毕业设计疫情期间物资分派管理系统](https://img-blog.csdnimg.cn/48e79de86a9d45b1a654ab918be752e5.png)