note
- 阿里的序列召回MIND模型:引入了胶囊网络,将胶囊网络的动态路由算法引入到了用户的多兴趣建模上,通过B2I动态路由很好的从用户的原始行为序列中提取出用户的多种兴趣表征。
- 在离线训练阶段,通过提出Label-Aware Attention详细的探讨了多兴趣建模下的模型参数更新范式。
文章目录
- note
- 一、论文解读
- 1.1 论文核心方法
- 1.2 问题定义
- 1.3 capsule network
- (1)初识胶囊网络
- (2)动态路由机制
- 二、MIND模型细节
- 2.1 Embedding & Pooling Layer
- 2.2 Multi-Interest Extractor Layer
- (1)算法流程图
- (2)三次动态路由内容
- 2.3 Label-aware Attention Layer
- (1)使用注意力机制
- (2)每次只激活一个兴趣向量
- 三、代码实践
- 3.1 CapsuleNetwork定义
- 3.2 MIND类
- 3.3 基于Faiss的向量召回
- 时间安排
- Reference
MIND全称:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall

一、论文解读
论文链接:https://arxiv.org/pdf/1904.08030
该论文是阿里巴巴2019年在CIKM上发表的一篇关于多兴趣召回的论文,该论文属于U2I召回的一种,传统的召回方法往往针对User的行为序列只生产单一的向量,但是在用户行为序列中往往蕴含着多种兴趣,生产单一的用户的嵌入向量无法很好的对用户的行为进行建模,所以阿里巴巴提出了对用户的行为序列生产多个向量以表示用户的多个兴趣表征,从而大大的提高了用户的行为表征能力。
1.1 论文核心方法
1.2 问题定义
问题定义:根据User的历史行为序列来预测User下一个会点击的 Item, 所以我们针对User的行为序列的标签就是User下一个点击的Item。
目标:
(1)学习一个函数
f
user
f_{\text {user }}
fuser 使得:
V
u
=
f
u
s
e
r
(
I
u
,
P
u
)
V_u=f_{u s e r}\left(I_u, P_u\right)
Vu=fuser(Iu,Pu)
其中:
- V u = ( v u 1 → , … , v u K → ) ∈ R d × K V_u=\left(\overrightarrow{v_u^1}, \ldots, \overrightarrow{v_u^K}\right) \in \mathbb{R}^{d \times K} Vu=(vu1,…,vuK)∈Rd×K ,
- I u I_u Iu 计作是User u u u 的行为序列,
- P u P_u Pu 计作是 User u u u 的基本特征例如年龄, 性别等),
- d表示User的Embedding向量的维度,
- K代表着所提取出的用户的兴趣个数,当 K = 1 K=1 K=1 的时候, 其退化为正常的U2I序列召回.
(2)对于Item我们也需要对其学习一个函数
f
item
f_{\text {item }}
fitem :
e
i
→
=
f
i
t
e
m
(
F
i
)
\overrightarrow{e_i}=f_{i t e m}\left(F_i\right)
ei=fitem(Fi)
其中:
- e ⃗ i ∈ R d × 1 \vec{e}_i \in \mathbb{R}^{d \times 1} ei∈Rd×1, 表示每个ltem的Embedding向量表征。
-
F
i
F_i
Fi 为 Item
i
i
i 的基本特征(例如
item_id,cate_id等)
在获取了User和Item的向量表征之后,那我们该如何对User的多兴趣表征与指定的Item,采用以下公式进行打分:
f
score
(
V
u
,
e
i
→
)
=
max
1
≤
k
≤
K
e
i
→
T
→
v
u
k
→
f_{\text {score }}\left(V_u, \overrightarrow{e_i}\right)=\max _{1 \leq k \leq K} \overrightarrow{e_i} \overrightarrow{\mathrm{T}} \overrightarrow{v_u^k}
fscore (Vu,ei)=1≤k≤KmaxeiTvuk
即对User的所有兴趣向量挨个与Item的向量进行内积, 从所有的内积结果中挑出最大的得分作为最终的得分。
1.3 capsule network
(1)初识胶囊网络
神经网络和capsule network的对比图如下,后者每一层的胶囊输出是一个向量值,input也是多个向量,即vector to vector的形式。经过线性映射的两个向量,进行加权求和,最后一个squash压缩操作。其中
c
i
c_i
ci不是反向传播学习的到的参数,而是用动态路由机制算出来的。
u
1
=
W
1
v
1
u
2
=
W
2
v
2
s
=
c
1
u
1
+
c
2
u
2
v
=
Squash
(
s
)
=
∥
s
∥
2
1
+
∥
s
∥
2
s
∥
s
∥
\begin{aligned} &u^1=W^1 v^1 \quad u^2=W^2 v^2 \\ &s=c_1 u^1+c_2 u^2 \\ &v=\operatorname{Squash}(s)=\frac{\|s\|^2}{1+\|s\|^2} \frac{s}{\|s\|} \end{aligned}
u1=W1v1u2=W2v2s=c1u1+c2u2v=Squash(s)=1+∥s∥2∥s∥2∥s∥s

(2)动态路由机制
dynamic routing其实就一个迭代聚类过程:


二、MIND模型细节
2.1 Embedding & Pooling Layer
模型的输入有三部分组成, 也就是我们在上一小节中的
I
u
,
P
u
,
F
i
I_u, P_u, F_i
Iu,Pu,Fi:
- I u I_u Iu 计作是User u u u 的行为序列,
- P u P_u Pu 计作是 User u u u 的基本特征例如年龄, 性别等),
-
F
i
F_i
Fi 为 Item
i
i
i 的基本特征(例如
item_id,cate_id等)
这里对所有的离散特征都使用Embedding Layer获取其 Embedding向量, 但是对于User/Item而言都是由一个或者多个Embedding向量组成, 这里如果User/tem的向量表征有多个的话, 我们对这些向量 进行mean pooling操作, 将其变成单一的Embedding向量。
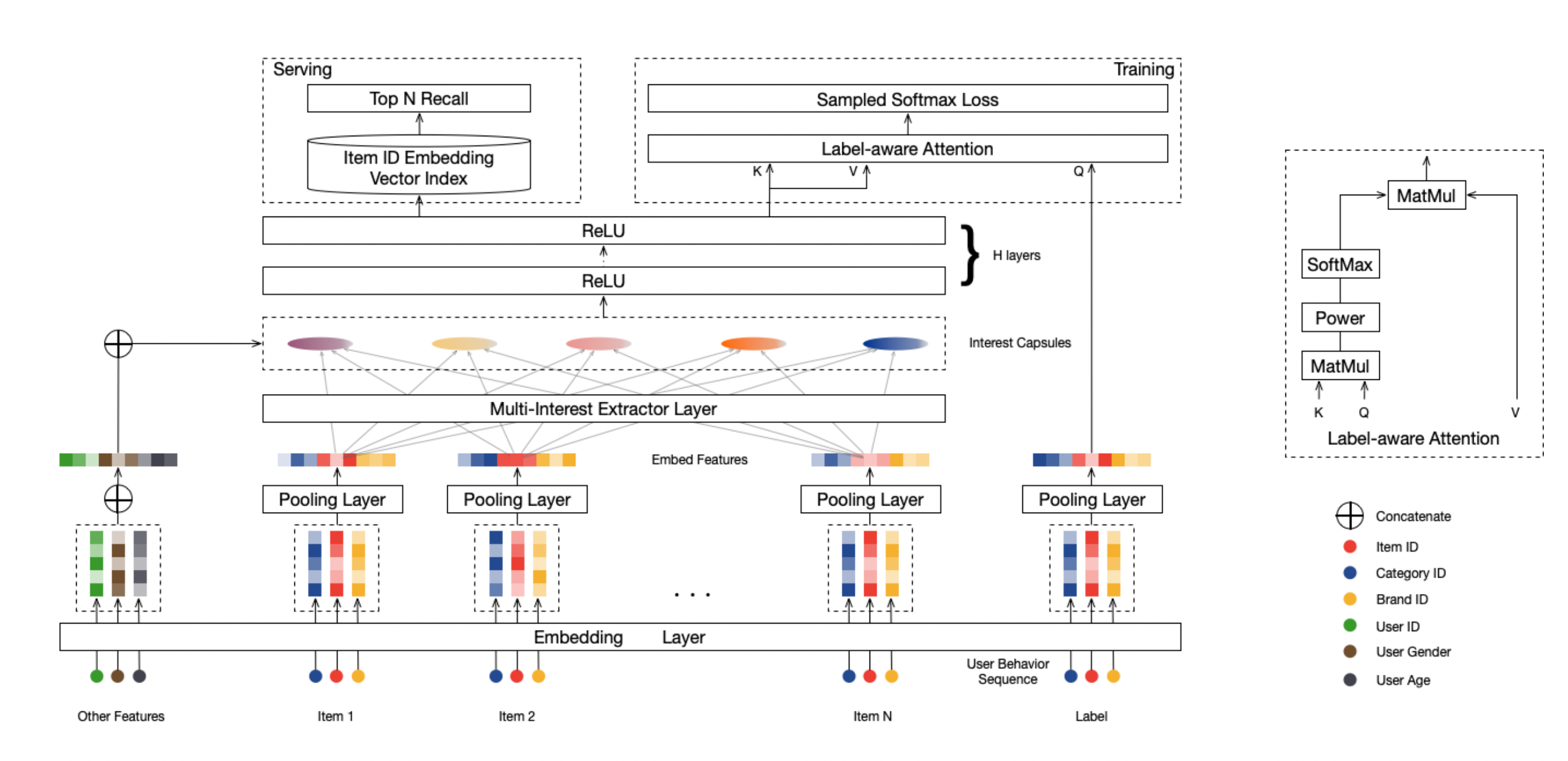
2.2 Multi-Interest Extractor Layer
在获取了用户行为序列的Embedding之后, 我们就需要对用户的行为序列的Embedding向量进行多兴趣建模了, MIND 论文中对于多兴趣建模的相关内容 MIND中对于多兴趣建模是参考了胶囊网络中的动态路由的方法来做的。
(1)算法流程图
- 这里将输入的用户的历史行为序列中的每 所得的用户的多兴趣向量(胶囊)计作 { u j → j = 1 , … , K u ′ } \left\{\overrightarrow{u_j} j=1, \ldots, K_u^{\prime}\right\} {ujj=1,…,Ku′} ,其主要的算法流程如下所示:

对于上面的流程图:
- 第一行:我们需要根据输入的用户User的长度来动态的计算所提取的User的兴趣向量个数, 可以简单的认为一个User的行为序列越长, 其所包含的潜在兴趣的个数就越多, 这里用户兴趣向量的计算公式如下:
K u ′ = max ( 1 , min ( K , log 2 I u ) ) K_u^{\prime}=\max \left(1, \min \left(K, \log _2 I_u\right)\right) Ku′=max(1,min(K,log2Iu))
这里的 K K K 是我们设置的一个超参数, 代表着最小兴趣的个数,当然了, 我们也可以直接给所有用户都指定提取出固定个数的兴趣向量, 这一部分在作者的实验部分会有体现。 - 第二行:我们需要给User的行为胶囊
i和User的兴趣胶囊j之间声明一个系数 b i j b_{ij} bij,这里我们对 b i j b_{ij} bij使用高斯分布进行初始化。 - 第三行:开始是一个for循环, 这里是对动态路由的次数进行for循环, 在原论文中, 这里是循环三次, 即做三次动态路由。
(2)三次动态路由内容
具体分析一下每一次动态路由需要做什么操作:
- 首先对
b
i
j
b_{ij}
bij进行softmax,这里softmax的维度是-1,即让每个user的行为胶囊
i的所有兴趣胶囊j的和为1,即:
w i j = exp ( b i j ) ∑ i = 1 m exp ( b i k ) w_{i j}=\frac{\exp \left(b_{i j}\right)}{\sum_{i=1}^m \exp \left(b_{i k}\right)} wij=∑i=1mexp(bik)exp(bij) - 在得到
w
i
j
w_{ij}
wij后,来生成兴趣胶囊
z
j
z_j
zj,生成方法是遍历user行为序列,对每个user的行为胶囊
i执行第五行的公式,就可以将user行为序列的信息聚合到每一个兴趣胶囊中。- 注意 S ∈ R d × d S \in \mathbb{R}^{d \times d} S∈Rd×d是一个可学习参数,S相当于是对user的行为胶囊和兴趣胶囊进行信息交互融合的一个权重。
- 在得到兴趣胶囊
z
j
z_j
zj后,对其使用如下的squash激活函数,其中
∥
z
j
∥
\left\|z_j\right\|
∥zj∥表示向量的模长:
squash ( z j ) = ∥ z j ∥ 2 1 + ∥ z j ∥ 2 z j ∥ z j ∥ \operatorname{squash}\left(z_j\right)=\frac{\left\|z_j\right\|^2}{1+\left\|z_j\right\|^2} \frac{z_j}{\left\|z_j\right\|} squash(zj)=1+∥zj∥2∥zj∥2∥zj∥zj - 最后,需要来根据第七行的公式来更行所有的 b i j b_{ij} bij,然后继续重复这一循环过程,直到达到预设的循环次数。 在完成动态路由之后,我们就针对User的行为序列得到了他的多兴趣表征了,下面我们来看一下怎么根据用户的多兴趣表征来进行模型的训练
2.3 Label-aware Attention Layer
我们在得到了用户的多兴趣表征之后, 我们就要对其进行Loss计算, 以此来进行模型的反向传播了, 那这个时候我们手里有的信息其实只有两个:
- 第一个就是我们上一小节刚刚得到的用户的多兴趣向量 V u ∈ R d × K V_u \in \mathbb{R}^{d \times K} Vu∈Rd×K ,
- 另一个就是我们User的“标签”, 也就是User下一个点击的Item, 我们同样也可以获取到这一个Item的Embedding向量 e i → ∈ R d \overrightarrow{e_i} \in \mathbb{R}^d ei∈Rd, 对于传统的序列召回, 我们得到的只有单一的User/ltem的Embedding向量,
这时我们可以通过 Sample Softmax, Softmax或者是一些基于Pair-Wise的方法来对其进行Loss的计算, 但是我们这里对于User的Embedding表征的向量是有多个, 这里就涉及到了怎么把User的多兴趣表征重新整合成单一的向量了, 这里作者进行了详细的实验与讨论。
(1)使用注意力机制
(1)使用注意力机制:首先作者通过attention计算出各个兴趣向量对目标item的权重, 用于将多兴趣向量融合为用户向量, 其中
p
p
p 为可调节的参数
v
u
→
=
Attention
(
e
i
→
,
V
u
,
V
u
)
=
V
u
softmax
(
pow
(
V
u
T
e
i
→
,
p
)
)
\overrightarrow{v_u}=\operatorname{Attention}\left(\overrightarrow{e_i}, V_u, V_u\right)=V_u \operatorname{softmax}\left(\operatorname{pow}\left(V_u^T \overrightarrow{e_i}, p\right)\right)
vu=Attention(ei,Vu,Vu)=Vusoftmax(pow(VuTei,p))
可以看出, 上述式子中只有 p p p 为超参数, 下面作者对 p p p 的不同取值进行了讨论
- 1.当 p = 0 p=0 p=0 的时候, 每个用户兴趣向量有相同的权重,相当于对所有的User兴趣向量做了一个Mean Pooling
- 2.当 p > 1 p>1 p>1 的时候, p越大, 与目标商品向量点积更大的用户兴趣向量会有更大的权重
- 3.当p趋于无穷大的时候, 实际上就相当于只使用与目标商品向量点积最大的用户兴趣向量, 忽略其他用户向量, 可以理解是每次只激活一个兴趣向量
(2)每次只激活一个兴趣向量
(2)每次只激活一个兴趣向量:在作者的实际实验中发现,当p趋于无穷大的时候模型的训练效果是最好的,即在进行Loss计算的时候,我们只对和目标Item最相似的那个兴趣向量进行Loss计算,这样我们就将多兴趣模型的Loss计算重新转换为一个一般的序列召回的问题,这里作者采用了Sample-Softmax当作损失函数。
这里的Sample-Softmax可以认为是Softmax的简化版,其核心也是一个多分类任务,但是当Item的个数很大的时候,直接当作多分类做会有很大的计算压力,所以这里引出了Sample-Softmax,这里的Sample-Softmax是对负样本进行了随机采样,这样就可以极大的缩小多分类的总类别数,也就可以在大规模的推荐数据上进行训练了。
注:在后面的代码实践中,由于我们使用的是公开数据集,其Item的个数比较小,所以我们就没有使用Sample-Softmax而是直接使用了Softmax。
三、代码实践
3.1 CapsuleNetwork定义
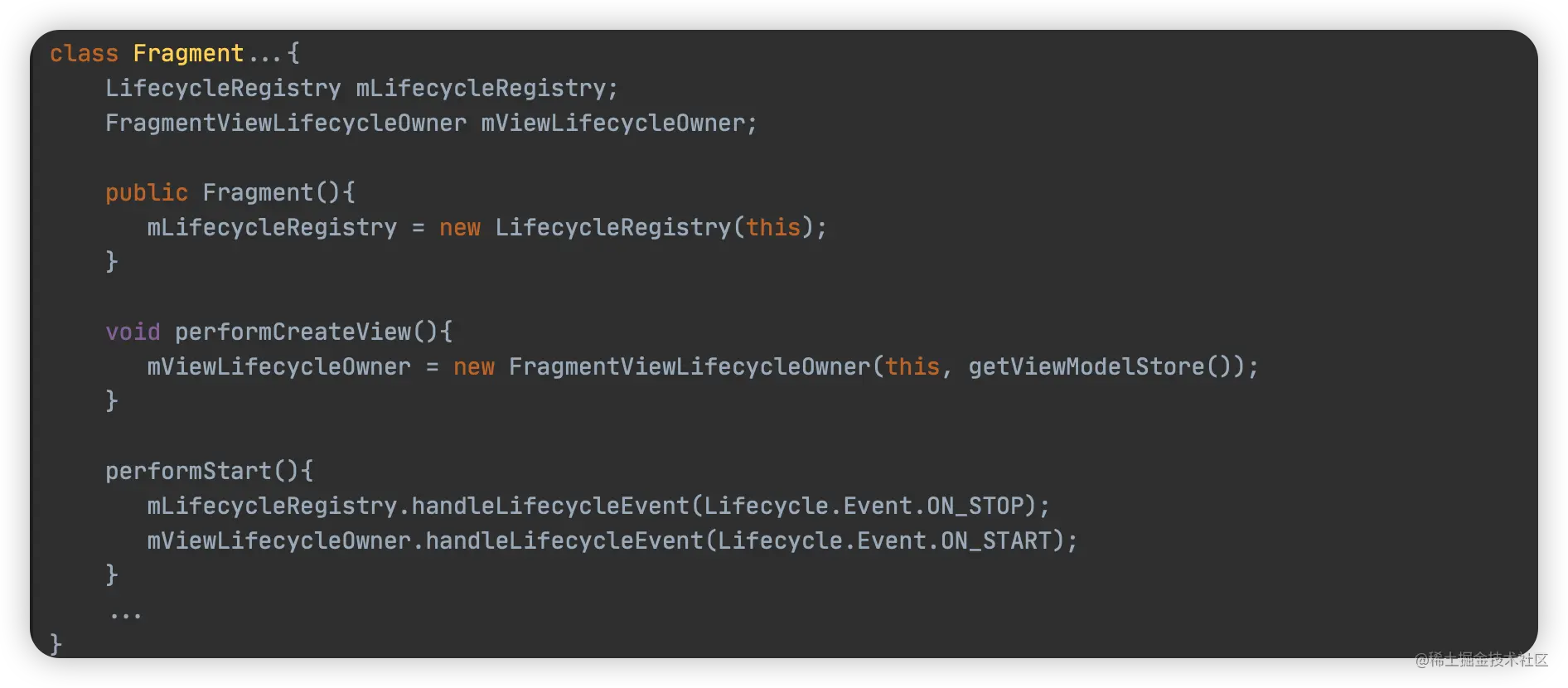
class CapsuleNetwork(nn.Layer):
def __init__(self, hidden_size, seq_len, bilinear_type=2, interest_num=4, routing_times=3, hard_readout=True,
relu_layer=False):
super(CapsuleNetwork, self).__init__()
self.hidden_size = hidden_size # h
self.seq_len = seq_len # s
self.bilinear_type = bilinear_type
self.interest_num = interest_num
self.routing_times = routing_times
self.hard_readout = hard_readout
self.relu_layer = relu_layer
self.stop_grad = True
self.relu = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False),
nn.ReLU()
)
if self.bilinear_type == 0: # MIND
self.linear = nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False)
elif self.bilinear_type == 1:
self.linear = nn.Linear(self.hidden_size, self.hidden_size * self.interest_num, bias_attr=False)
else: # ComiRec_DR
self.w = self.create_parameter(
shape=[1, self.seq_len, self.interest_num * self.hidden_size, self.hidden_size])
def forward(self, item_eb, mask):
if self.bilinear_type == 0: # MIND
item_eb_hat = self.linear(item_eb) # [b, s, h]
item_eb_hat = paddle.repeat_interleave(item_eb_hat, self.interest_num, 2) # [b, s, h*in]
elif self.bilinear_type == 1:
item_eb_hat = self.linear(item_eb)
else: # ComiRec_DR
u = paddle.unsqueeze(item_eb, 2) # shape=(batch_size, maxlen, 1, embedding_dim)
item_eb_hat = paddle.sum(self.w[:, :self.seq_len, :, :] * u,
3) # shape=(batch_size, maxlen, hidden_size*interest_num)
item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.seq_len, self.interest_num, self.hidden_size))
item_eb_hat = paddle.transpose(item_eb_hat, perm=[0,2,1,3])
# item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.interest_num, self.seq_len, self.hidden_size))
# [b, in, s, h]
if self.stop_grad: # 截断反向传播,item_emb_hat不计入梯度计算中
item_eb_hat_iter = item_eb_hat.detach()
else:
item_eb_hat_iter = item_eb_hat
# b的shape=(b, in, s)
if self.bilinear_type > 0: # b初始化为0(一般的胶囊网络算法)
capsule_weight = paddle.zeros((item_eb_hat.shape[0], self.interest_num, self.seq_len))
else: # MIND使用高斯分布随机初始化b
capsule_weight = paddle.randn((item_eb_hat.shape[0], self.interest_num, self.seq_len))
for i in range(self.routing_times): # 动态路由传播3次
atten_mask = paddle.repeat_interleave(paddle.unsqueeze(mask, 1), self.interest_num, 1) # [b, in, s]
paddings = paddle.zeros_like(atten_mask)
# 计算c,进行mask,最后shape=[b, in, 1, s]
capsule_softmax_weight = F.softmax(capsule_weight, axis=-1)
capsule_softmax_weight = paddle.where(atten_mask==0, paddings, capsule_softmax_weight) # mask
capsule_softmax_weight = paddle.unsqueeze(capsule_softmax_weight, 2)
if i < 2:
# s=c*u_hat , (batch_size, interest_num, 1, seq_len) * (batch_size, interest_num, seq_len, hidden_size)
interest_capsule = paddle.matmul(capsule_softmax_weight,
item_eb_hat_iter) # shape=(batch_size, interest_num, 1, hidden_size)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True) # shape=(batch_size, interest_num, 1, 1)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9) # shape同上
interest_capsule = scalar_factor * interest_capsule # squash(s)->v,shape=(batch_size, interest_num, 1, hidden_size)
# 更新b
delta_weight = paddle.matmul(item_eb_hat_iter, # shape=(batch_size, interest_num, seq_len, hidden_size)
paddle.transpose(interest_capsule, perm=[0,1,3,2])
# shape=(batch_size, interest_num, hidden_size, 1)
) # u_hat*v, shape=(batch_size, interest_num, seq_len, 1)
delta_weight = paddle.reshape(delta_weight, (
-1, self.interest_num, self.seq_len)) # shape=(batch_size, interest_num, seq_len)
capsule_weight = capsule_weight + delta_weight # 更新b
else:
interest_capsule = paddle.matmul(capsule_softmax_weight, item_eb_hat)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9)
interest_capsule = scalar_factor * interest_capsule
interest_capsule = paddle.reshape(interest_capsule, (-1, self.interest_num, self.hidden_size))
if self.relu_layer: # MIND模型使用book数据库时,使用relu_layer
interest_capsule = self.relu(interest_capsule)
return interest_capsule
3.2 MIND类
MIND类:
class MIND(nn.Layer):
def __init__(self, config):
super(MIND, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.capsule = CapsuleNetwork(self.embedding_dim, self.max_length, bilinear_type=0,
interest_num=self.config['K'])
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
if train:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
item_e = self.item_emb(item).squeeze(1)
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
cos_res = paddle.bmm(multi_interest_emb, item_e.squeeze(1).unsqueeze(-1))
k_index = paddle.argmax(cos_res, axis=1)
best_interest_emb = paddle.rand((multi_interest_emb.shape[0], multi_interest_emb.shape[2]))
for k in range(multi_interest_emb.shape[0]):
best_interest_emb[k, :] = multi_interest_emb[k, k_index[k], :]
loss = self.calculate_loss(best_interest_emb,item)
output_dict = {
'user_emb': multi_interest_emb,
'loss': loss,
}
else:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
output_dict = {
'user_emb': multi_interest_emb,
}
return output_dict
3.3 基于Faiss的向量召回
def get_predict(model, test_data, hidden_size, topN=20):
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
test_gd = dict()
preds = dict()
user_id = 0
for (item_seq, mask, targets) in tqdm(test_data):
# 获取用户嵌入
# 多兴趣模型,shape=(batch_size, num_interest, embedding_dim)
# 其他模型,shape=(batch_size, embedding_dim)
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 用内积来近邻搜索,实际是内积的值越大,向量越近(越相似)
if len(user_embs.shape) == 2: # 非多兴趣模型评估
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
test_gd[user_id] = iid_list
preds[user_id] = I[i,:]
user_id +=1
else: # 多兴趣模型评估
ni = user_embs.shape[1] # num_interest
user_embs = np.reshape(user_embs,
[-1, user_embs.shape[-1]]) # shape=(batch_size*num_interest, embedding_dim)
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
recall = 0
dcg = 0.0
item_list_set = []
# 将num_interest个兴趣向量的所有topN近邻物品(num_interest*topN个物品)集合起来按照距离重新排序
item_list = list(
zip(np.reshape(I[i * ni:(i + 1) * ni], -1), np.reshape(D[i * ni:(i + 1) * ni], -1)))
item_list.sort(key=lambda x: x[1], reverse=True) # 降序排序,内积越大,向量越近
for j in range(len(item_list)): # 按距离由近到远遍历推荐物品列表,最后选出最近的topN个物品作为最终的推荐物品
if item_list[j][0] not in item_list_set and item_list[j][0] != 0:
item_list_set.append(item_list[j][0])
if len(item_list_set) >= topN:
break
test_gd[user_id] = iid_list
preds[user_id] = item_list_set
user_id +=1
return test_gd, preds
def evaluate(preds,test_gd, topN=50):
total_recall = 0.0
total_ndcg = 0.0
total_hitrate = 0
for user in test_gd.keys():
recall = 0
dcg = 0.0
item_list = test_gd[user]
for no, item_id in enumerate(item_list):
if item_id in preds[user][:topN]:
recall += 1
dcg += 1.0 / math.log(no+2, 2)
idcg = 0.0
for no in range(recall):
idcg += 1.0 / math.log(no+2, 2)
total_recall += recall * 1.0 / len(item_list)
if recall > 0:
total_ndcg += dcg / idcg
total_hitrate += 1
total = len(test_gd)
recall = total_recall / total
ndcg = total_ndcg / total
hitrate = total_hitrate * 1.0 / total
return {f'recall@{topN}': recall, f'ndcg@{topN}': ndcg, f'hitrate@{topN}': hitrate}
# 指标计算
def evaluate_model(model, test_loader, embedding_dim,topN=20):
test_gd, preds = get_predict(model, test_loader, embedding_dim, topN=topN)
return evaluate(preds, test_gd, topN=topN)
时间安排
| 任务信息 | 截止时间 | 完成情况 |
|---|---|---|
| 11月14日周一正式开始 | ||
| Task01:Paddle开发深度学习模型快速入门 | 11月14、15、16日周三 | 完成 |
| Task02:传统序列召回实践:GRU4Rec | 11月17、18、19日周六 | 完成 |
| Task03:GNN在召回中的应用:SR-GNN | 11月20、21、22日周二 | 完成 |
| Task04:多兴趣召回实践:MIND | 11月23、24、25、26日周六 | 完成 |
| Task05:多兴趣召回实践:Comirec-DR | 11月27、28日周一 | |
| Task06:多兴趣召回实践:Comirec-SA | 11月29日周二 |
Reference
[1] task4:多兴趣召回实践:MIND
论文:Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
链接:https://arxiv.org/pdf/1904.08030
[2] deepmatch的MIND实现:https://github.com/shenweichen/DeepMatch
[3] 召回模型(一) MIND网络:Capsules网络启发下的用户多兴趣向量表达
[4] 代码1:https://github.com/THUDM/ComiRec/blob/a576eed8b605a531f2971136ce6ae87739d47693/src/model.py
[5] 代码2:https://github.com/ShiningCosmos/pytorch_ComiRec/blob/main/MIND.py
[6] AI上推荐 之 MIND(动态路由与胶囊网络的奇光异彩)
[7] 推荐场景中召回模型的演化过程. 京东大佬
[8] 李宏毅课程-胶囊网络-Capsule Network
[9] 苏神-揭开迷雾,来一顿美味的Capsule盛宴
[10] https://github.com/shenweichen/DeepMatch/blob/master/deepmatch/models/mind.py