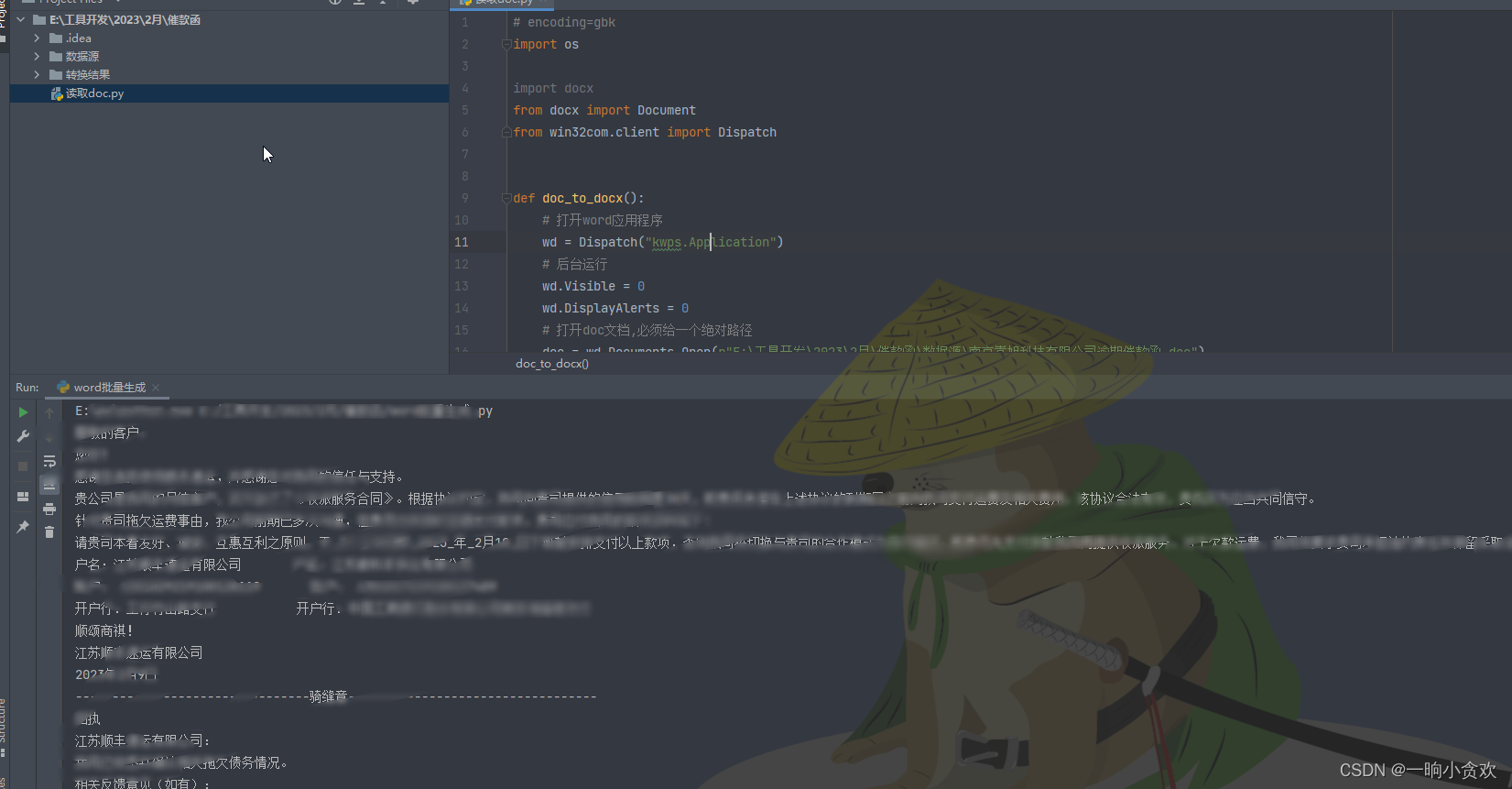
import os
import docx
from docx import Document
from win32com. client import Dispatch
def doc_to_docx ( ) :
wd = Dispatch( "kwps.Application" )
wd. Visible = 0
wd. DisplayAlerts = 0
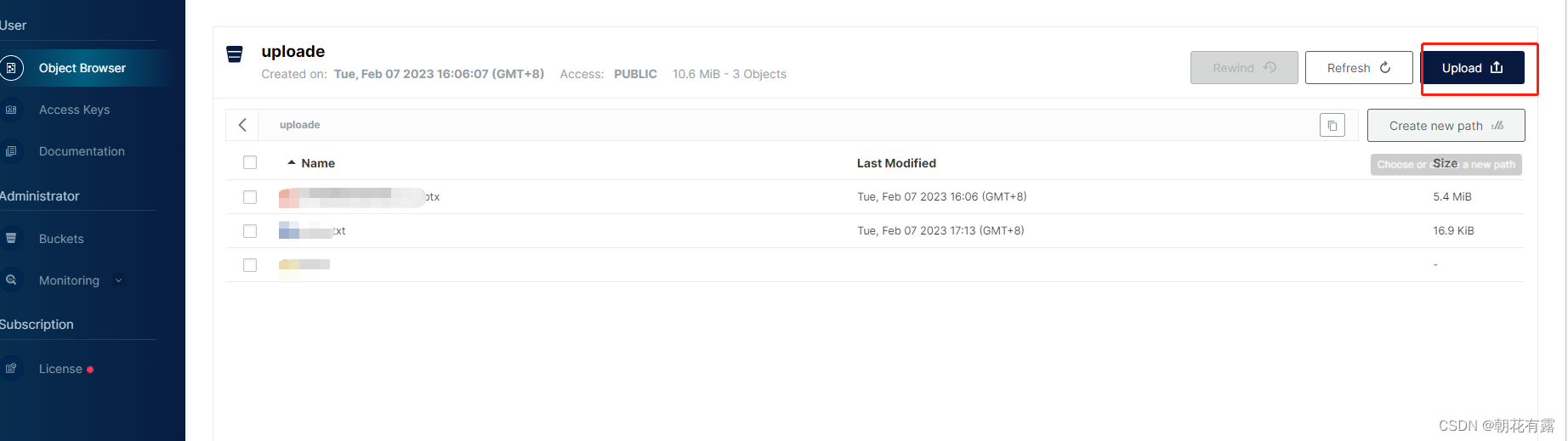
doc = wd. Documents. Open( r"E:\工具开发\2023\2月\催款函\数据源\南京嵩旭科技有限公司逾期催款函.doc" )
doc. SaveAs( r"E:\工具开发\2023\2月\催款函\转换结果\南京嵩旭科技有限公司逾期催款函.docx" , 12 )
doc. Close( )
wd. Quit( )
doc_to_docx( )
def read_docx ( ) :
docStr = Document( "./转换结果/" + os. listdir( "./转换结果/" ) [ 0 ] )
for paragraph in docStr. paragraphs:
parStr = paragraph. text
print ( parStr)
read_docx( )
这里感谢这位老哥,帮我解决了,点我看原博
pywintypes.com_error: (-2147221005, ‘无效的类字符串’, None, None)




![纯CSS实现[喵咪小挂件]](https://img-blog.csdnimg.cn/img_convert/7b0bb1f072ee7000b5fd6052b386c9ae.png)