音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。

不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄?
—————天热了,讲个冷笑话—————
实际上,中国近几年的太阳能发电和风电发展可谓突飞猛进。2025年第一季度,全国风电和光伏发电合计装机达到14.82亿千瓦,历史性首次超过火电的14.5亿千瓦。
放眼全世界,你可能觉得全球都在经历轰轰烈烈的能源转型。但实际上,这个转型几乎全靠中国的一己之力。
2023和2024年,全球的风电和光伏发电新装机容量接近三分之二来自中国,一枝独秀。
其余国家的新增装机,发电装备也主要来自中国。尤其是太阳能,中国为全球各国提供了80%以上的光伏组件。

无敌是多么寂寞。
但装机容量高,不代表发电就多。各地一直存在令人心痛的“弃风、弃光、弃水”问题。有的地方甚至出现过单日弃风率70%的极端案例,可以认为有70%的风机实际没有发电。

为何弃风?因为电网“实发实用”且风机发电功率不稳定。风来了,电量供过于求,电网面临冲击。风走了,电不够用,显然也不行。
缓解弃风,关键在于精准预测未来一段时间的风电功率。我们不怕风电不稳定,只怕它产生预期外的不稳定。换句话说,要将风电的“不确定性”转化为“可预见性”。
风机功率影响因素复杂,怎么预测?
下面展示一个案例,用数据预测风电功率。来自清华大学孙逸凡团队,主题《面向复杂风电数据的核密度清洗与功率预测分区模型》。
该案例荣获第三届“天洑杯”数据建模大赛的特等奖。

数据采集自陕西某风电场,规模相当庞大,有442809 条,59个维度。
这59个维度,其中一个是输出功率,即因变量。另外58个是自变量,包括风速、温度、风向、叶片桨距角等等,它们或多或少都会影响输出功率。
工具采用DTEmpower,一款门槛超低上手简单的智能数据建模软件。
建模过程包括数据读取、数据清理、敏感性分析、模型训练、模型对比等步骤,下面为完整工程界面。
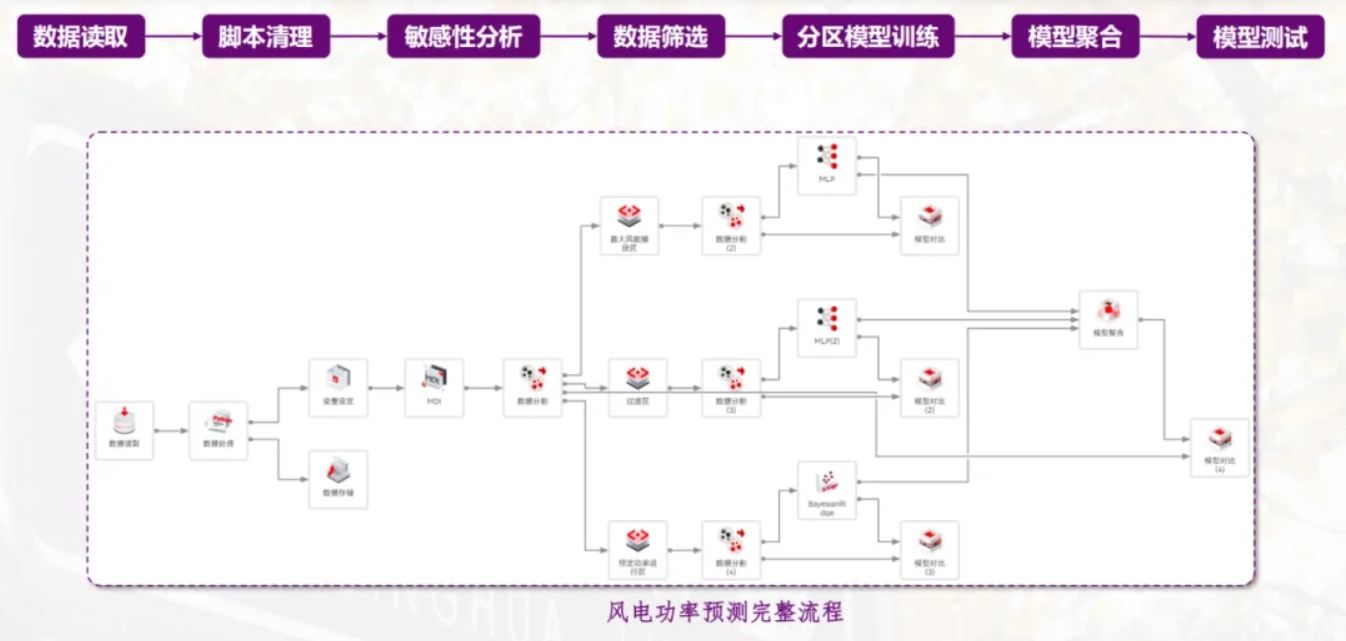
其中:
-
数据清理部分,项目团队基于软件的数据处理模块,开发自编程清洗程序,实现数据高效批量化处理。同时考虑风机工作特征和数据异常原因,将建模过程结合业务背景。
-
敏感性分析部分筛选掉“不重要”的自变量,提高建模精度。
-
模型训练部分,先根据风电特征将数据分区,然后分别用不同的训练算法做模型训练。
-
模型对比阶段,用测试集对基于不同算法训练得到的模型进行精度对比。
最后一步模型聚合,将优选出的分区模型合并为一个。

最终经测试集数据测试,合并后的模型精度非常高,R2值达到0.99。
这说明基于风速、温度以及桨距角这些容易测量或容易预测的数据,就能实时预测未来一段时间的风机功率。
如果预测到功率偏低,那就让火电机组做好准备,甚至让风电停机检修。反过来,如果预测到功率偏高,火电就能歇息一阵了。
如此一来,大大提升风机的利用率,降低“弃风”率,让每一缕风都有机会点亮万家灯火。
最后,欢迎到天洑软件官网下载试用DTEmpower,从数据中挖掘价值,预测未来。



















