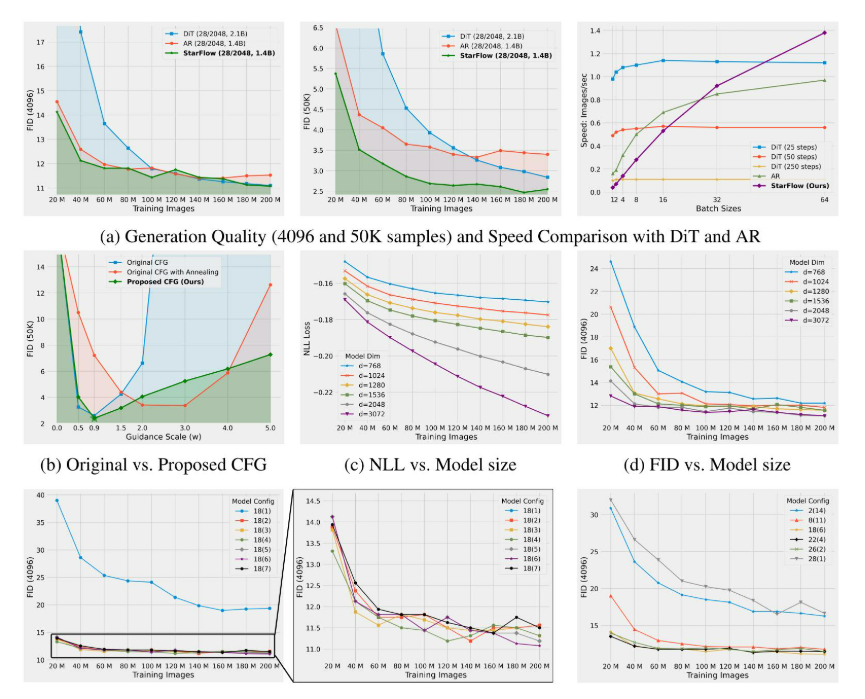
一、mysql2 原生驱动及其连接机制
概念介绍
mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。
主要特点:
-
支持 Promise / async-await(对现代项目更友好)
-
提供 Prepared Statement(预处理语句)支持,防止 SQL 注入
-
支持 连接池(Pool)机制,提升并发性能和复用率
-
兼容 ORM 工具(如 Sequelize)也可用于原生 SQL 操作
代码示例
1. 基础连接
import mysql from 'mysql2';
// 创建连接
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'your_password',
database: 'your_database',
});
// 执行查询
connection.query('SELECT * FROM users', (err, results) => {
if (err) throw err;
console.log(results);
});
// 关闭连接
connection.end();
2. 使用 Promise 封装(推荐)
import mysql from 'mysql2/promise';
async function main() {
const connection = await mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'your_password',
database: 'your_database',
});
const [rows] = await connection.execute('SELECT * FROM users WHERE id = ?', [1]);
console.log(rows);
await connection.end();
}
main();
3. 创建连接池
import mysql from 'mysql2/promise';
const pool = mysql.createPool({
host: 'localhost',
user: 'root',
password: 'your_password',
database: 'your_database',
waitForConnections: true,
connectionLimit: 10,
queueLimit: 0,
});
export default pool;
使用:
const [rows] = await pool.execute('SELECT * FROM users');
讲解说明
-
连接方式:
mysql2支持传统回调和Promise接口,推荐使用mysql2/promise提供的createConnection()和createPool(),便于与async/await编程风格融合。 -
连接机制:
-
单次连接:适合执行短暂任务,连接后立即关闭
-
连接池(Pool):创建若干可复用连接,自动分配,提高系统性能和稳定性,避免频繁创建/销毁连接的开销
-
-
连接复用:
连接池通过connectionLimit限制并发数,通过复用连接提升吞吐效率,是 Web3 + API 项目中常用的 MySQL 接入方式。 -
与 Web3 应用结合:
在 Web3 项目中,常使用mysql2存储链下数据(如用户账户信息、链上事件索引、NFT 交易记录等),与合约数据联动提供更完整的数据视图。
二、Sequelize ORM 工具的使用
概念介绍
Sequelize 是一个基于 Promise 的 Node.js ORM 框架,支持多种 SQL 数据库(如 MySQL、PostgreSQL、SQLite、MariaDB 等)。它可以帮助开发者使用 JavaScript/TypeScript 以对象的方式操作数据库,减少手写 SQL 的负担,同时提升项目可维护性和安全性。
主要特性:
-
支持模型定义、关联(关系建模)、事务、原始查询等
-
支持数据迁移与同步(schema migration/sync)
-
支持 TypeScript 的类型定义
-
常用于链下数据库建模(如用户、合约事件、NFT 记录)
示例代码(基于 TypeScript + MySQL)
1. 安装依赖
npm install sequelize mysql2
2. 初始化 Sequelize 实例
// db.ts
import { Sequelize } from 'sequelize';
const sequelize = new Sequelize('your_database', 'root', 'password', {
host: 'localhost',
dialect: 'mysql',
});
export default sequelize;
3. 定义模型(Model)
// models/User.ts
import { DataTypes, Model } from 'sequelize';
import sequelize from '../db';
class User extends Model {
public id!: number;
public username!: string;
public ethAddress!: string;
}
User.init(
{
id: {
type: DataTypes.INTEGER.UNSIGNED,
autoIncrement: true,
primaryKey: true,
},
username: {
type: DataTypes.STRING,
allowNull: false,
},
ethAddress: {
type: DataTypes.STRING,
allowNull: false,
unique: true,
},
},
{
tableName: 'users',
sequelize,
}
);
export default User;
4. 使用模型进行操作
// index.ts
import sequelize from './db';
import User from './models/User';
async function main() {
await sequelize.sync(); // 创建表结构(如不存在)
const user = await User.create({
username: 'alice',
ethAddress: '0xAbC123...',
});
const found = await User.findOne({ where: { ethAddress: '0xAbC123...' } });
console.log(found?.username);
}
main();
讲解说明
-
ORM 编程模型:
Sequelize 把表结构映射为类(Model),通过create、findOne、update等方法操作数据库,无需手写 SQL。 -
数据迁移与模型同步:
sequelize.sync()会根据模型定义自动创建或修改表结构,也可以用 CLI 工具进行版本控制的数据库迁移。 -
与 Web3 项目的结合:
-
可用于存储 钱包地址、链上事件记录、NFT mint 记录、元数据等
-
可结合 Web3.js / Ethers.js,作为链上与链下的桥梁
-
-
优势:
-
减少重复代码
-
避免 SQL 注入(通过绑定参数)
-
统一数据结构与类型定义
-
三、TypeORM 工具的使用
概念介绍
TypeORM 是一款支持 TypeScript 的现代化 ORM 框架,适用于 Node.js 应用程序。它支持多种数据库(如 MySQL、PostgreSQL、SQLite、MongoDB 等),提供实体(Entity)映射、关系关联、迁移工具、查询构建器等功能。
在 Web3 全栈开发中,TypeORM 常用于 DApp 后端中存储链下数据,如用户钱包信息、合约事件索引、NFT 元数据等,是构建结构化链下存储的理想选择,尤其适合与 NestJS 框架集成。
示例代码(基于 NestJS + MySQL)
安装依赖
npm install @nestjs/typeorm typeorm mysql2
配置数据库模块
// app.module.ts
import { Module } from '@nestjs/common';
import { TypeOrmModule } from '@nestjs/typeorm';
import { User } from './user.entity';
@Module({
imports: [
TypeOrmModule.forRoot({
type: 'mysql',
host: 'localhost',
port: 3306,
username: 'root',
password: 'password',
database: 'web3_db',
entities: [User],
synchronize: true, // 自动同步实体到表结构(开发用)
}),
TypeOrmModule.forFeature([User]),
],
})
export class AppModule {}
定义实体(Entity)
// user.entity.ts
import { Entity, Column, PrimaryGeneratedColumn } from 'typeorm';
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
username: string;
@Column({ unique: true })
wallet: string;
}
使用服务进行数据库操作
// user.service.ts
import { Injectable } from '@nestjs/common';
import { InjectRepository } from '@nestjs/typeorm';
import { Repository } from 'typeorm';
import { User } from './user.entity';
@Injectable()
export class UserService {
constructor(
@InjectRepository(User)
private userRepo: Repository<User>,
) {}
async createUser(username: string, wallet: string) {
const user = this.userRepo.create({ username, wallet });
return await this.userRepo.save(user);
}
async findByWallet(wallet: string) {
return await this.userRepo.findOneBy({ wallet });
}
}
讲解说明
-
Entity 映射:将数据库表映射为 TypeScript 类,字段即为列,支持数据类型、主键、索引等定义。
-
Repository 模式:封装所有数据库操作,提供
.find()、.save()、.update()等方法,便于解耦业务逻辑。 -
NestJS 集成:TypeORM 是 NestJS 默认推荐的 ORM,支持依赖注入和模块化设计,非常适合构建后端微服务。
四、MongoDB 的聚合管道
概念介绍
MongoDB 的 聚合管道(Aggregation Pipeline) 是一种功能强大的数据处理框架,用于对 MongoDB 集合中的文档进行批量处理、转换、统计和过滤。它通过一系列的阶段(stage),像流水线一样一步步处理数据,常用于实现复杂查询、报表生成、数据分析等场景。
在 Web3 应用中,聚合管道常用于处理链上事件落库后的分析查询,例如统计某个用户的 NFT 持有数、代币交易次数等。
示例代码
以下使用 Node.js 的官方 MongoDB 驱动实现聚合查询。
安装依赖
npm install mongodb
示例场景:统计每个用户持有的 NFT 数量
假设我们有如下 MongoDB 集合结构:
// collection: nfts
{
"_id": ObjectId("..."),
"owner": "0x1234...abcd",
"tokenId": 1,
"collection": "CryptoCats"
}
使用聚合管道查询
// aggregate-example.ts
import { MongoClient } from 'mongodb';
async function run() {
const client = new MongoClient('mongodb://localhost:27017');
await client.connect();
const db = client.db('web3app');
const nfts = db.collection('nfts');
const result = await nfts.aggregate([
{
$group: {
_id: '$owner',
nftCount: { $sum: 1 }
}
},
{
$sort: { nftCount: -1 }
}
]).toArray();
console.log(result);
await client.close();
}
run();
常见聚合管道阶段
| 阶段名 | 作用说明 |
|---|---|
$match | 条件过滤(类似 SQL 的 WHERE) |
$group | 分组聚合(类似 SQL 的 GROUP BY) |
$sort | 排序(类似 SQL 的 ORDER BY) |
$project | 投影(控制输出字段) |
$lookup | 联表(类似 SQL 的 JOIN) |
$limit | 限制返回条数 |
$skip | 跳过指定数量文档 |
讲解说明
-
聚合管道支持多个阶段组合执行,适用于处理复杂业务逻辑。
-
聚合性能远高于应用层处理,适合大数据量链上数据的离线处理与前端展示。
-
可以嵌套
$lookup实现链上数据与用户表等链下数据的联合展示。
五、MongoDB 的文档建模
概念介绍
MongoDB 是一种基于文档的 NoSQL 数据库,其核心是以 BSON 格式存储文档(类似 JSON)。文档建模(Schema Design) 指的是设计和组织数据库中数据结构的过程,以满足应用性能和业务需求。
MongoDB 的文档建模与传统关系型数据库的表结构设计不同,主要特点有:
-
灵活的结构:文档可以包含嵌套文档和数组,方便表示复杂关系。
-
数据去范式化:为了查询效率,常常将相关数据合并存储在同一文档内,减少关联查询。
-
基于业务访问模式设计:设计模型时优先考虑应用的查询和更新场景,优化性能和扩展性。
文档建模常见设计策略:
-
嵌套(Embedded Documents):将相关数据放在同一文档中,适合一对多、需要一起读取的数据。
-
引用(References):存储关联文档的 ID,通过程序或
$lookup进行关联查询,适合数据复用频繁或文档过大时。
示例代码
假设我们设计一个链上 NFT 平台的数据模型,有用户和他们的 NFT 集合。
1. 嵌套文档设计(用户和NFT放在同一文档内)
{
"_id": "user_0xabc123",
"name": "Alice",
"wallet": "0xabc123...",
"nfts": [
{
"tokenId": 1,
"collection": "CryptoCats",
"metadata": {
"name": "Cat #1",
"rarity": "rare"
}
},
{
"tokenId": 2,
"collection": "CryptoDogs",
"metadata": {
"name": "Dog #2",
"rarity": "common"
}
}
]
}
优点:读取用户和NFT一次完成,适合NFT数量较少且常一起访问的场景。
缺点:NFT数量爆炸时文档变大,可能超过文档大小限制(16MB)。
2. 引用设计(用户与NFT分开存储,通过ID关联)
用户文档:
{
"_id": "user_0xabc123",
"name": "Alice",
"wallet": "0xabc123..."
}
NFT文档:
{
"_id": "nft_1",
"ownerId": "user_0xabc123",
"tokenId": 1,
"collection": "CryptoCats",
"metadata": {
"name": "Cat #1",
"rarity": "rare"
}
}
查询时通过 ownerId 字段关联。
优点:数据量大时结构更灵活,支持NFT单独更新。
缺点:读取时需要额外查询或使用 $lookup 关联,性能受访问模式影响。
实践讲解
-
设计文档模型前,先分析业务场景,确认最常见的查询和写入操作。
-
若业务对性能要求高且访问模式固定,倾向于嵌套文档,避免多次查询。
-
若数据复用、增长快或复杂关联多,使用引用关系,配合索引和聚合管道优化查询。
-
合理设计索引,避免文档过大影响性能。
-
对于链上事件、日志等海量数据,建议拆分存储,按时间分区。
六、存储链上事件索引
概念介绍
链上事件(On-chain events)是智能合约在区块链上触发的日志,用于记录合约内部状态变化和交互信息。为了方便查询和分析,DApp 通常会将这些事件从区块链节点同步到数据库中,形成“链上事件索引”。
链上事件索引 是指通过监听区块链事件,将事件数据结构化存储在数据库(如 MongoDB、PostgreSQL)中,便于快速检索、统计和跨链查询。它是区块链数据和应用层交互的桥梁,提高了用户体验和数据处理效率。
示例代码
以下示例使用 Node.js 和 ethers.js 监听以太坊智能合约事件,并将事件存储到 MongoDB 中作为链上事件索引。
const { ethers } = require("ethers");
const { MongoClient } = require("mongodb");
const provider = new ethers.providers.JsonRpcProvider("https://sepolia.infura.io/v3/YOUR_INFURA_PROJECT_ID");
const contractAddress = "0xYourContractAddress";
const abi = [ // 合约事件 ABI
"event Transfer(address indexed from, address indexed to, uint256 value)"
];
const client = new MongoClient("mongodb://localhost:27017");
const dbName = "blockchain";
const collectionName = "events";
async function main() {
await client.connect();
console.log("Connected to MongoDB");
const db = client.db(dbName);
const eventsCollection = db.collection(collectionName);
const contract = new ethers.Contract(contractAddress, abi, provider);
contract.on("Transfer", async (from, to, value, event) => {
console.log(`Transfer event: from=${from}, to=${to}, value=${value.toString()}`);
// 存储事件到MongoDB
await eventsCollection.insertOne({
txHash: event.transactionHash,
blockNumber: event.blockNumber,
from,
to,
value: value.toString(),
timestamp: new Date() // 实际应用中可以通过区块时间戳获取更准确时间
});
});
console.log("Listening for Transfer events...");
}
main().catch(console.error);
讲解总结
-
监听链上事件:通过 Web3 库(如 ethers.js 或 web3.js)连接以太坊节点,订阅智能合约事件。
-
结构化存储:将事件信息包括交易哈希、区块号、事件参数及时间戳存入数据库,形成链上事件索引。
-
快速查询:索引化存储方便 DApp 后端进行条件过滤、分页查询和统计分析。
-
提升体验:链上事件索引使前端应用不必直接查询区块链,提升响应速度和用户体验。
-
扩展性:结合聚合管道或全文检索技术,可支持复杂的数据分析和跨合约关联查询。
该方式是 Web3 应用中常见的数据同步和缓存技术基础。
七、DApp 结构化数据
概念介绍
DApp(去中心化应用)结构化数据是指将区块链上分散、非结构化的原始数据(如交易、事件、合约状态)经过处理、解析和组织后,存储为便于查询、展示和业务逻辑使用的有序数据结构。
结构化数据通常存放在传统数据库(如 MongoDB、PostgreSQL)或专门的数据索引层,用于:
-
快速响应前端查询请求
-
实现复杂的业务逻辑和数据分析
-
支持链上链下数据结合的功能,如账户资产展示、NFT 元数据管理、交易历史统计等
通过结构化,DApp 能有效提升性能和用户体验,避免频繁访问区块链节点的高延迟。
示例代码
以下示例展示如何将链上 NFT 交易事件结构化存储,便于前端展示用户 NFT 资产。
const { ethers } = require("ethers");
const { MongoClient } = require("mongodb");
const provider = new ethers.providers.JsonRpcProvider("https://sepolia.infura.io/v3/YOUR_INFURA_PROJECT_ID");
const contractAddress = "0xYourNFTContractAddress";
const abi = [
"event Transfer(address indexed from, address indexed to, uint256 indexed tokenId)"
];
const client = new MongoClient("mongodb://localhost:27017");
const dbName = "dapp";
const collectionName = "nft_ownership";
async function main() {
await client.connect();
console.log("Connected to MongoDB");
const db = client.db(dbName);
const nftCollection = db.collection(collectionName);
const contract = new ethers.Contract(contractAddress, abi, provider);
contract.on("Transfer", async (from, to, tokenId, event) => {
console.log(`NFT Transfer: from=${from}, to=${to}, tokenId=${tokenId.toString()}`);
// 结构化更新持有者信息
// 先移除 tokenId 旧持有者记录
if (from !== ethers.constants.AddressZero) {
await nftCollection.updateOne(
{ owner: from },
{ $pull: { tokenIds: tokenId.toString() } }
);
}
// 添加 tokenId 到新持有者
if (to !== ethers.constants.AddressZero) {
await nftCollection.updateOne(
{ owner: to },
{ $addToSet: { tokenIds: tokenId.toString() } },
{ upsert: true }
);
}
});
console.log("Listening for NFT Transfer events...");
}
main().catch(console.error);
讲解总结
-
监听事件:通过监听智能合约的 NFT Transfer 事件,获取资产所有权变更。
-
结构化数据存储:将用户地址和对应持有的 NFT tokenId 列表存入数据库,方便快速查询用户资产。
-
去中心化数据与传统数据库结合:链上数据通过事件同步到数据库,实现链上链下数据融合。
-
支持业务逻辑:结构化数据支持 DApp 的资产展示、交易历史、收藏夹等功能模块。
-
提升效率和用户体验:避免每次访问都请求区块链节点,减少延迟和资源消耗。
结构化数据设计是开发高性能、用户友好的 DApp 关键环节。