Arrays类的概述
Java中的Arrays类位于java.util包中,提供了一系列静态方法用于操作数组(如排序、搜索、填充、比较等)。这些方法适用于基本类型数组和对象数组。
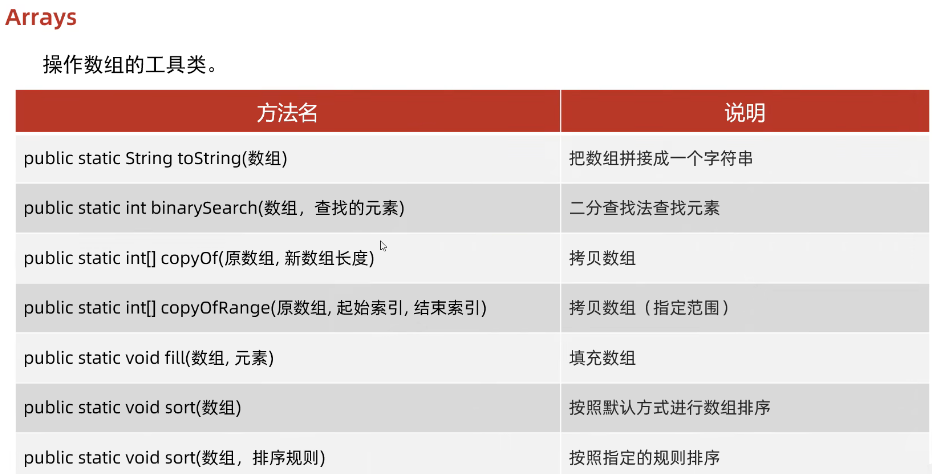
常用成员方法及代码示例
排序(sort)
对数组进行升序排序(基本类型采用快速排序,对象类型采用归并排序)。
int[] numbers = {5, 2, 9, 1, 5};
Arrays.sort(numbers); // 排序后:[1, 2, 5, 5, 9]
System.out.println(Arrays.toString(numbers));
对对象数组排序(需实现Comparable接口或传入Comparator):
String[] names = {"John", "Alice", "Bob"};
Arrays.sort(names); // 按字典序排序
System.out.println(Arrays.toString(names));
二分查找(binarySearch)
前提:数组必须已排序。返回找到元素的索引(未找到时返回负数)。
int[] sortedArr = {1, 3, 5, 7, 9};
int index = Arrays.binarySearch(sortedArr, 5); // 返回2
System.out.println("Index of 5: " + index);
填充(fill)
将数组的所有元素设置为指定值。
char[] chars = new char[5];
Arrays.fill(chars, 'A'); // ['A', 'A', 'A', 'A', 'A']
System.out.println(Arrays.toString(chars));
数组转字符串(toString)
格式化数组为可读字符串。
double[] doubles = {1.1, 2.2, 3.3};
System.out.println(Arrays.toString(doubles)); // [1.1, 2.2, 3.3]
比较数组(equals)
判断两个数组内容是否相同(包括元素顺序)。
int[] arr1 = {1, 2, 3};
int[] arr2 = {1, 2, 3};
System.out.println(Arrays.equals(arr1, arr2)); // true
拷贝数组(copyOf/copyOfRange)
copyOf:从原数组的起始位置拷贝指定长度。
copyOfRange:拷贝指定范围(左闭右开)。
int[] original = {10, 20, 30, 40, 50};
int[] copy1 = Arrays.copyOf(original, 3); // [10, 20, 30]
int[] copy2 = Arrays.copyOfRange(original, 1, 4); // [20, 30, 40]
深度操作(deepEquals/deepToString)
用于多维数组或嵌套对象数组的比较和打印。
int[][] matrix1 = {{1, 2}, {3, 4}};
int[][] matrix2 = {{1, 2}, {3, 4}};
System.out.println(Arrays.deepEquals(matrix1, matrix2)); // true
System.out.println(Arrays.deepToString(matrix1)); // [[1, 2], [3, 4]]
高级应用示例
将数组转换为列表(asList):
String[] fruits = {"Apple", "Banana", "Orange"};
List<String> list = Arrays.asList(fruits); // 返回固定大小的列表
System.out.println(list);
注意:此方法返回的列表不支持增删操作(会抛出UnsupportedOperationException)。
并行排序(parallelSort):
int[] largeArray = new int[100000];
// 使用多线程并行排序(大数据量时效率更高)
Arrays.parallelSort(largeArray);
实例:
public class test1_Arrays {
public static void main(String[] args) {
/*
public static String toString(数组) 把数组拼接成一个字符串
public static int binarySearch(数组,查找的元素) 二分查找法查找元素
public static int[] copyOf(原数组,新数组长度) 拷贝数组
public static int[] copyOfRange(原数组,起始索引,结束索引) 拷贝数组(指定范围)
public static void fill(数组,元素) 填充数组
public static void sort(数组) 按照默认方式进行数组排序
public static void sort(数组,排序规则) 按照指定的规则排序
*/
//toString: 将数组变成字符串
System.out.println("-----------toString-------------");
int[] arr = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
System.out.println(Arrays.toString(arr));//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
//binarySearch:二分查找法查找元素
//细节1:二分查找的前提:数组中的元素必须是有序,数组中的元素必须是升序的
//细节2:如果要查找的元素是存在的,那么返回的是真实的索引
//但是,如果要查找的元素是不存在的,返回的是--插入点 - 1
//疑问:为什么要减1呢?
//解释:如果此时,我现在要查找数字0,那么如果返回的值是-插入点,就会出现问题了。
//如果要查找数字0,此时0是不存在的,但是按照上面的规则--插入点,应该就是-0
//为了避免这样的情况,Java在这个基础上又减一。
System.out.println("-----------binarySearch-------------");
System.out.println(Arrays.binarySearch(arr, 10));//9
System.out.println(Arrays.binarySearch(arr, 21));//-1
System.out.println(Arrays.binarySearch(arr, 0));//-11
//copyOf:拷贝数组
//参数一:老数组
//参数二:新数组的长度
//方法的底层会根据第二个参数来创建新的数组
//如果新数组的长度是小于老数组的长度,会部分拷贝
//如果新数组的长度是等于老数组的长度,会完全拷贝
//如果新数组的长度是大于老数组的长度,会补上默认初始化值
System.out.println("-----------copyOf-------------");
int[] newArr1 = Arrays.copyOf(arr, 10);
System.out.println(Arrays.toString(newArr1));//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
//copyOfRange:拷贝数组(指定范围)
//细节:包头不包尾,包左不包右
System.out.println("-----------copyOfRange-------------");
int[] newArr2 = Arrays.copyOfRange(arr, 0, 9);
System.out.println(Arrays.toString(newArr2));//[1, 2, 3, 4, 5, 6, 7, 8, 9]
//fill:填充数组
System.out.println("-----------fill-------------");
Arrays.fill(arr, 100);
System.out.println(Arrays.toString(arr));
//sort:排序。默认情况下,给基本数据类型进行升序排列。底层使用的是快速排序。
System.out.println("-----------sort-------------");
int[] arr2 = {10, 2, 3, 5, 6, 1, 7, 8, 4, 9};
Arrays.sort(arr2);
System.out.println(Arrays.toString(arr2));//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
}
}
public class test2_Arrays {
public static void main(String[] args) {
/*
public static void sort(数组,排序规则) 按照指定的规则排序
参数一:要排序的数组
参数二:排序的规则
细节:
只能给引用数据类型的数组进行排序
如果数组是基本数据类型的,需要变成其对丁的包装类
*/
Integer[] arr = {2, 3, 1, 5, 6, 7, 8, 4, 9};
//第二个参数是一个接口,所以我们在调用方法的时候,需要传递这个接口的实现类对象,作为排序的规则。
//但是这个实现类,我只要使用一次,所以就没有必要单独的去写一个类,直接采取匿名内部类的方式就可以了
//底层原理:
//利用插入排序 + 二分查找的方式进行排序的。
//默认把@索引的数组当做是有序的序列,1索引到最后认为是无序的序列。
//把无序的序列得到里面的每一个元素,假设当前遍历得到的元素是A元素
//在有序序列中进行插入,在插入的时候,是利用二分查找确定A元素的插入点。
//拿着A元素,跟插入点的元素进行比较,比较的规则就是compare方法的方法体
//如果方法的返回值是负数,拿着A继续跟前面的数据进行比较
//如果方法的返回值是正数,拿着A继续跟后面的数据进行比较
//如果方法的返回值是0,也拿着A跟后面的数据进行比较
//直到能确定A的最终位置为止。
//compare方法的形式参数:
//参数一:o1:表示在无序序列中,遍历得到的每一个元素
//参数二:o2:有序序列中的元素
//返回值:
//负数:表示当前要插入的元素是小的,放在前面
//正数:表示当前要插入的元素是大的,放在后面
//0:表示当前要插入的元素跟现在的元素是一样的,他们也会放在后面
//简单理解:
//o1 - o2 : 升序排列
//o2 - o1 : 降序排列
//Integer[] arr = {2, 3, 1, 5, 6, 7, 8, 4, 9};
Arrays.sort(arr, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println("-------------");
System.out.println("o1 : " + o1);
System.out.println("o2 : " + o2);
return o1 - o2;
}
});
System.out.println(Arrays.toString(arr));
}
}
通过灵活组合这些方法,可以高效处理数组相关的常见任务。
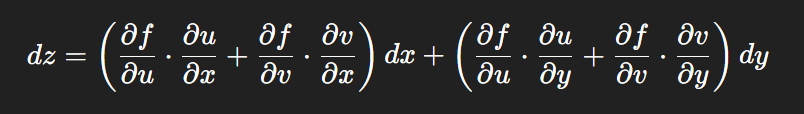



![[拓扑优化] 1.概述](https://i-blog.csdnimg.cn/direct/97dd8744ddbb4418b480fbeb1276e192.png)