第三章 数据可视化
文章目录
目录
第三章 数据可视化
文章目录
前言
一、数据可视化
二、使用步骤
1.pyplot
1.1引入库
1.2 设置汉字字体
1.3 数据准备
1.4 设置索引列
编辑
1.5 调用绘图函数
2.使用seaborn绘图
2.1 安装导入seaborn
2.2 设置背景风格
2.3 调用绘图方法
2.4 确认调整统计口径
2.5 通过hue等参数指定更多特征
2.6 优化边框、配色等
2.7 查看配色方案
2.8 优化子图排列
三、案例
3.1 案例数据介绍
3.2 理解字段含义和分析缺失情况
3.3 找出销量前五的国家和地区 哪个地区销售额最高?什么类别的商品销量最好? 其中有什么规律?
3.4 柱状图
3.5 气泡图展现大维度差距
3.5.1怎样绘制差距悬殊的数字
3.5.2 气泡图的绘制方法与细节
3.5.3 利用维度展示数据技巧
3.6 雷达图看整体对比,柱状图堆叠
任务:比较不同国家每类商品采购总额
3.6.1 catplot与多图表格对象
3.6.2 分组柱形图的绘制
3.6.3 使用Pandas绘制堆叠图
3.6.4 使用pygal绘制雷达图
3.7 箱型图分清上中下层
3.7.1 swarmplot(蜂群图)
3.7.2 箱型图的绘制与解读
3.7.3 异常点的概念和意义
3.7.4 使用whis参数调整估算区间
3.7.5 增强箱型,收拢异常值
3.7.6 增强箱型拆分的依据
总结
前言
图形查看数据更为直观清晰。
一、数据可视化
数据可视化是指通过图表、图形、地图、仪表盘等视觉形式,将复杂的数据转化为直观易懂的信息,帮助人们快速理解数据中的模式、趋势、关系和异常。它是数据分析和沟通的重要工具,广泛应用于商业、科研、教育、媒体等领域。
二、使用步骤
1.pyplot
1.1引入库
代码如下(示例):
import pandas as pd
from IPython.core.pylabtools import figsize
from matplotlib import pyplot as plt1.2 设置汉字字体
plt.rcParams['font.sans-serif'] = ['SimHei'] #避免中文乱码
plt.rcParams['axes.unicode_minus'] = False #设定符号,避免出错1.3 数据准备
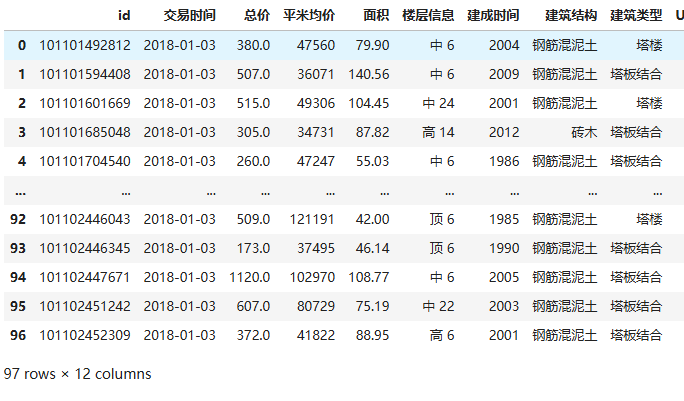
df = pd.read_excel(r'D:\python学习\house2017.xlsx')
df输出结果:
1.4 设置索引列
df.set_index('id', inplace=True)
df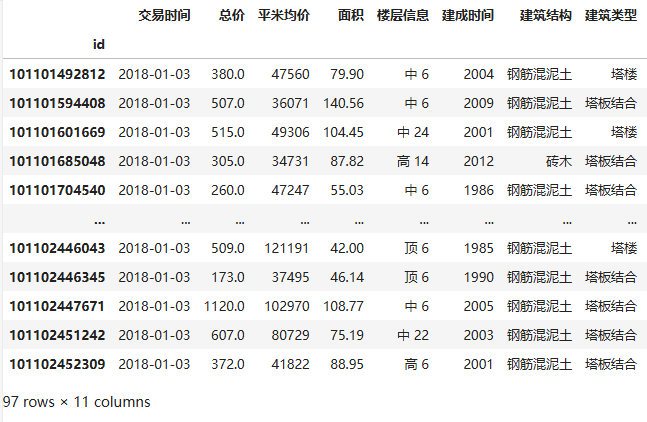
1.5 调用绘图函数
plt.scatter(df['面积'],df['总价'])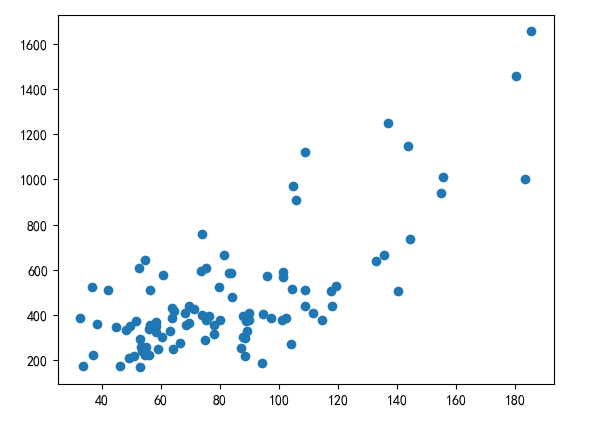
2.使用seaborn绘图
2.1 安装导入seaborn
conda install seaborn2.2 设置背景风格
seaborn自带风格:
暗底有网格 : darkgrid
白底有网格 : whitegrid
暗底无网格 : dark
白底无网格 : white
matplotlib默认: ticks
import seaborn as sns
sns.set_style('white',{'font.sans-serif':['simhei','Arial']}) #设置风格为暗色网格,设置字体格式2.3 调用绘图方法
sns.scatterplot(x=df['面积'],y=df['总价'])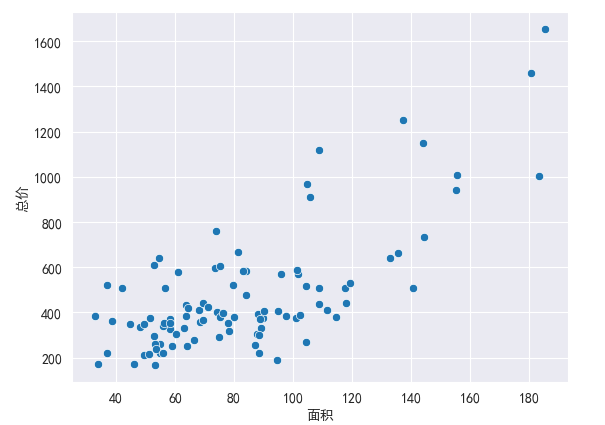
2.4 确认调整统计口径
散点图
sns.scatterplot(x='面积',y='总价',data=df)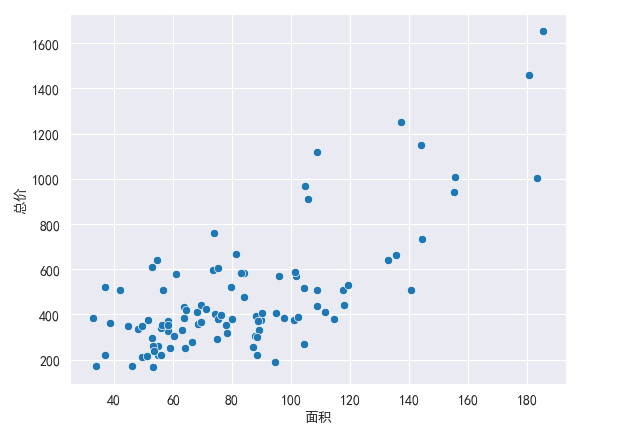
柱状图
sns.barplot(x='建筑结构',y = '总价',data=df)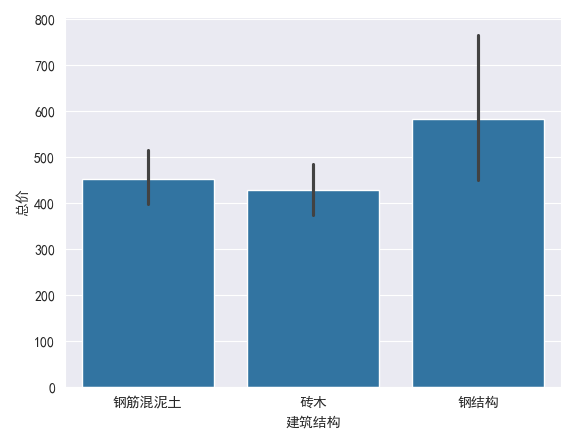
2.5 通过hue等参数指定更多特征
sns.scatterplot(x='面积',y='总价',hue = '建筑类型',data=df)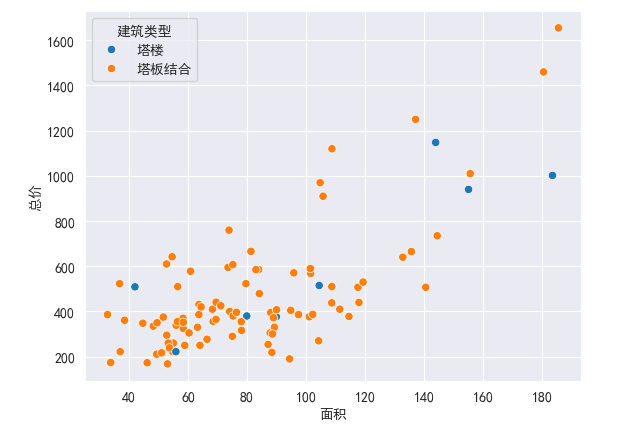
2.6 优化边框、配色等
去掉轴线 despine left=True 删除左边,另一边 right=True offset=n 设置坐标轴偏移量
sns.scatterplot(x='面积',y='总价',hue = '建筑类型',data=df)
sns.despine()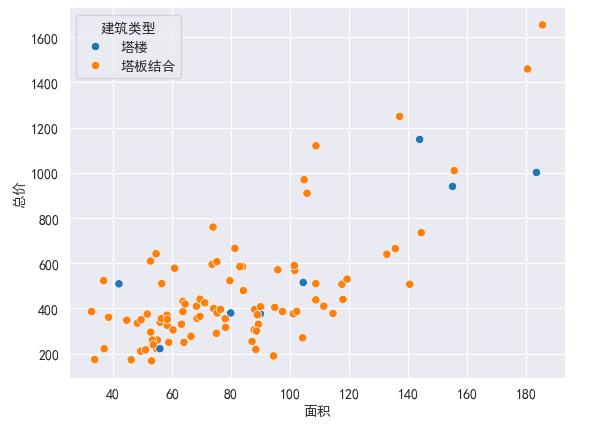
sns.scatterplot(x='面积',y='总价',hue = '建筑类型',data=df)
sns.despine(offset=10)
2.7 查看配色方案
sns.color_palette() sg = sns.color_palette('Greens',10) #指定颜色和数量
sns.set_palette(sg) #通过自定义调色板,改变显示的颜色2.8 优化子图排列
matplotlib.subplots
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 假设这里已经有了正确的DataFrame对象df,包含'面积'、'总价'、'建筑类型'、'建筑结构'等列数据
# 创建子图布局,这里应该使用plt.subplots而不是plt.subplot,plt.subplots会返回画布fig和子图对象组成的元组
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(16, 4))
# 去除子图的边框(默认设置),这里可以根据需要调整参数来保留某些边框等
sns.despine()
# 在ax1子图上绘制散点图
sns.scatterplot(x='面积', y='总价', data=df, ax=ax1)
# 在ax2子图上绘制柱状图
sns.barplot(x='建筑类型', y='面积', data=df, ax=ax2)
# 在ax3子图上绘制柱状图
sns.barplot(x='建筑结构', y='面积', data=df, ax=ax3)
# 显示图形
plt.show()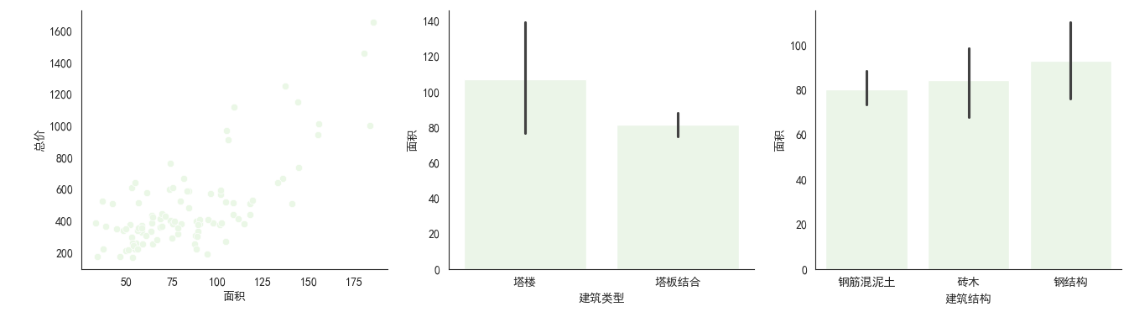
三、案例
案例数据:superstore_dataset2011-2015 (超市数据集 2011-2015 年),这是一个常用于数据分析和可视化的公开数据集,通常包含某超市在 2011 年至 2015 年期间的销售记录。
3.1 案例数据介绍
import pandas as pd
df= pd.read_csv(r'D:\superstore_dataset2011-2015.csv')
df.head()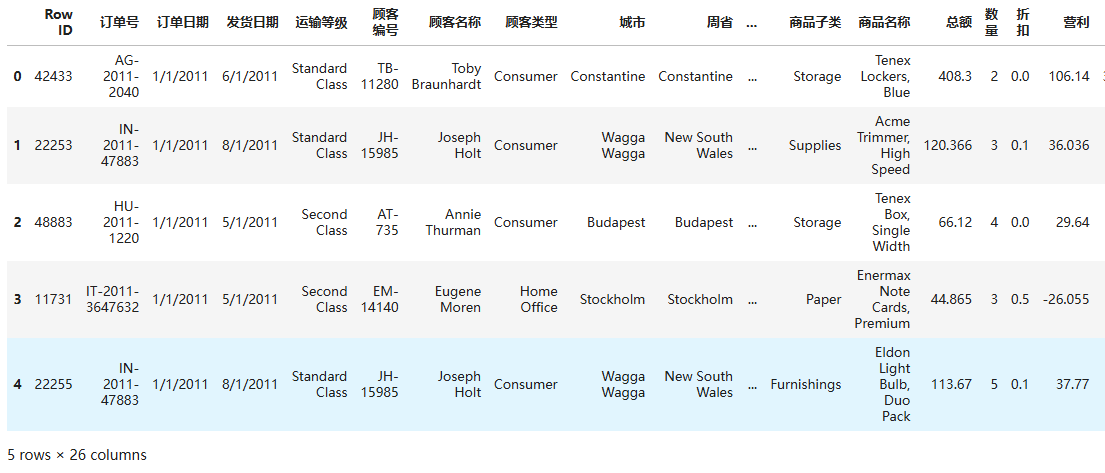
3.2 理解字段含义和分析缺失情况
df.info()
这些字段可以帮助我们从多个维度分析销售数据,包括时间趋势、地理分布、客户细分和产品表现等。
非空值比较接近,因此数据价值也就较高
3.3 找出销量前五的国家和地区 哪个地区销售额最高?什么类别的商品销量最好? 其中有什么规律?
1.提取相应的需分析的属性字段
data=df[ ['订单号','国家地区','商品门类','总额'] ] #通过花式索引提取相关数据列
data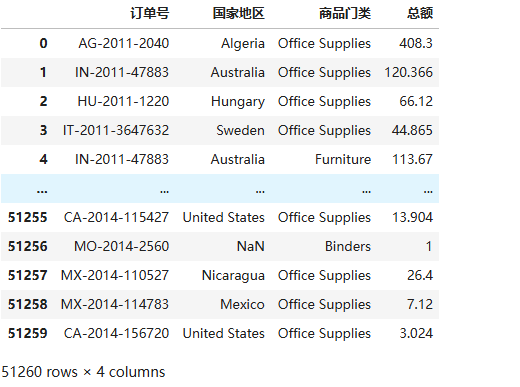
2.得到不重复的国家和地区
unique函数: 用于获取 Series 或 DataFrame 列中的唯一值,返回一个包含所有唯一值的数组。
isin函数:用于判断元素是否存在于指定的可迭代对象中,返回布尔型 Series 或 DataFrame。
区别与联系
unique()用于去重,返回唯一值列表isin()用于筛选,返回布尔掩码- 常结合使用:先用
unique()查看有哪些唯一值,再用isin()筛选特定值的行
国家地区数量:
len(data['国家地区'].unique())商品门类数量:
len(data['商品门类'].unique())3.属性规划分类,分为科技、办公、文化、家具等类
data['商品门类'].replace(["Advantus Light Bulb, Black"],'科技',inplace=True)
data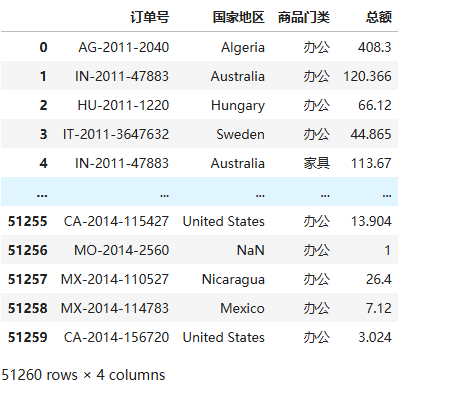
4.分组排名问题
属性字段的类型转换,原始数据大多为文本类型
data2['总额'] = data2['总额'].astype('float')data2.groupby('国家地区')['总额'].sum()
5. 汇总结果排序sort_values()
data2.groupby('国家地区')['总额'].sum().sort_values(ascending=False)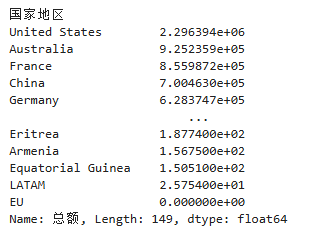
6.切片取值
data2.groupby('国家地区')['总额'].sum().sort_values(ascending=False)[:5]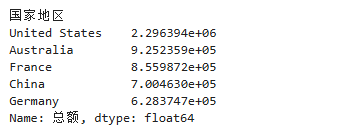
data2.groupby('国家地区')['总额'].sum().sort_values(ascending=False)[-6:-1]
7. 取出销售前五的国家详细数据 Series.isin()
data2[data2['国家地区'].isin(['United States','Australia','France','China','Germany'])]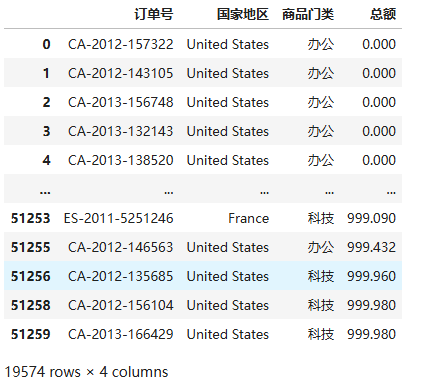
3.4 柱状图
以销售前五的国家为例
1.指定柱形图的统计口径
指定误差线 ci参数:指定为浮点数:显示误差线并表示置信区间,大小由该浮点数确定;指定为”sd“:显示误差线并表示标准离差;指定为None:不显示误差线¶
palette='spring',(输入一个不存在的可以看全部)选择颜色面板,alpha透明度设置
import seaborn as sns
sns.set_style('whitegrid',{'font.sans-serif':['Simhei','Arial']})sns.barplot(x='