引言:光影的魔法师——神经辐射场概览
在前三篇笔记中,我们逐步揭开了 AI 生成 3D 技术的面纱:从宏观的驱动力与价值(S2E01),到主流技术流派的辨析(S2E02),再到实用工具的选择与评估框架(S2E03)。在这些讨论中,一个名字被反复提及,并被誉为近年来三维计算机视觉和图形学领域最具革命性的突破之一——它就是 **NeRF (Neural Radiance Fields,神经辐射场)**。
NeRF 以其前所未有的能力,从一组稀疏的二维图像中学习并渲染出具有照片级真实感的三维场景新视图,迅速吸引了学术界和工业界的广泛关注。它不仅仅是一种三维重建技术,更是一种全新的、基于神经网络的场景表示与渲染范式。理解 NeRF 的核心原理、洞察其关键优势、正视其当前局限,并展望其广阔的应用前景,对于我们产品经理把握 AI+3D 的技术前沿、构思创新产品至关重要。

本篇笔记(S2E04)将聚焦于 NeRF 技术本身,进行一次相对深入的"技术潜航"。我们将一同探索:
● 核心思想探索: NeRF 是如何用一个简单的神经网络"记住"复杂场景的光影信息的?其核心思想是什么?
● 独特优势分析: 相比传统的三维重建和渲染方法,NeRF 的独特优势体现在哪些方面?为何它能产生如此惊艳的效果?
● 挑战与局限认识: 当前 NeRF 技术在实际应用中面临哪些主要的挑战和技术瓶颈?(例如效率、可编辑性、场景规模等)
● 应用前景展望: NeRF 及其变种正在哪些前沿领域展现出巨大的应用潜力?未来的发展趋势如何?
目标是帮助产品经理们不仅"听过"NeRF,更能"理解"NeRF,从而在未来的产品规划和技术决策中,能够更准确地评估其价值和可行性。
一、 NeRF 的核心思想:用神经网络"记住"光线如何与场景互动

NeRF 的核心思想可以概括为:用一个连续的、隐式的神经场函数来表示一个静态三维场景的完整体积光学特性,并通过可微分的体积渲染技术从该表示中合成新视图。 这个看似复杂的定义,可以拆解为以下几个关键组成部分:
1. 隐式神经表示 (Implicit Neural Representation)
传统的三维场景表示方法,如多边形网格 (Polygon Meshes)、点云 (Point Clouds)、体素网格 (Voxel Grids),都是显式的,即直接用离散的几何元素(顶点、面、点、小方块)来描述场景的形状。而 NeRF 则采用了一种隐式的表示方法。
a. 场景函数:
它将整个三维场景(包括其几何形状和外观材质)表示为一个连续的函数 F_Θ。这个函数通常由一个标准的多层感知机(MLP,即一个简单的前馈神经网络)来实现,其权重参数为 Θ。
b. 输入与输出:
这个 MLP 的输入是一个五维向量:空间中一个点的位置坐标 (x, y, z) 和一个观察该点的方向 (θ, φ)(通常用单位方向向量 (d_x, d_y, d_z) 表示)。其输出是两个值:该点在该观察方向下的体积密度 (σ) 和颜色 (c)(通常是 RGB 值)。
● 体积密度 (σ): 这是一个非负标量,表示光线在穿过 (x, y, z) 这一点时,被吸收或散射的"概率"或"强度"。密度越大的地方,场景越"实";密度为零的地方,场景是"空"的。体积密度主要决定了场景的几何形状。
● 颜色 (c): 这是一个三维颜色向量 (R, G, B),表示如果光线在该点被反射或散射出来,它会呈现什么颜色。为了模拟非朗伯体(non-Lambertian)表面的视角相关反射效果(如高光),颜色通常也依赖于观察方向 (θ, φ)。
c. 连续性:
由于 MLP 是一个连续函数,因此 NeRF 对场景的表示也是连续的,理论上可以查询空间中任意精细位置的光学特性,这与离散表示方法有本质区别。
本质上,这个 MLP 就像一个"记忆黑盒",通过其网络权重 Θ,"记住"了整个三维场景中每一点对光线的响应方式。
2. 体积渲染方程 (Volume Rendering Equation)
拥有了场景的隐式神经表示(即训练好的 MLP F_Θ)之后,如何从这个表示中生成一张特定视角的二维图像呢?NeRF 采用了经典的体积渲染原理。
a. 光线投射 (Ray Casting):
对于目标图像中的每一个像素,从虚拟相机的视点(Camera Origin, o)出发,沿着该像素的方向(Ray Direction, d)投射一条光线 r(t) = o + t*d 进入场景。
b. 沿光线采样 (Sampling along Ray):
在这条光线的近裁剪面 t_n 和远裁剪面 t_f 之间,采样一系列离散的点 {t_i}。对于每个采样点 p_i = r(t_i),将其空间坐标 (x_i, y_i, z_i) 和光线方向 d 输入到 MLP F_Θ 中,查询得到该点的体积密度 σ_i 和颜色 c_i。
c. 颜色累积 (Color Accumulation):
光线最终呈现的颜色 C(r),是沿着光线所有采样点的颜色 c_i 根据其密度 σ_i 和前面所有点的"遮挡程度"(透射率 T_i)进行加权累积的结果。离散形式的体积渲染方程可以表示为:
C(r) = Σ (T_i * α_i * c_i)
其中,α_i = 1 - exp(-σ_i * δ_i) 是第 i 个采样段的透明度(δ_i 是相邻采样点之间的距离),而 T_i = exp(-Σ_{j<i} (σ_j * δ_j)) 是光线到达第 i 个采样点之前的累积透射率(即未被吸收的程度)。
这个公式直观地模拟了光线穿过一个半透明体积介质时,沿途吸收和散射光线并最终形成颜色的物理过程。
d. 可微分性:
NeRF 的一个核心创新在于,整个从 MLP 查询到体积渲染计算像素颜色的过程是完全可微分的。这意味着,如果我们知道渲染出的像素颜色与真实图像中对应像素颜色之间的差异(例如,通过均方误差损失函数计算),我们就可以通过反向传播算法(Backpropagation)计算出这个损失对于 MLP 网络权重 Θ 的梯度。
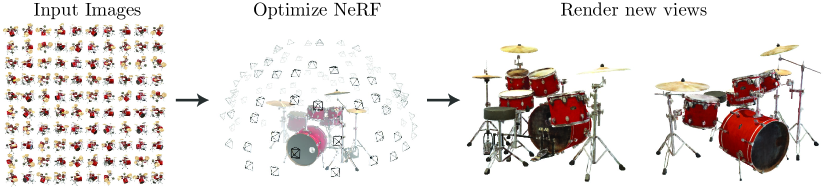
3. 从多视图图像中学习 (Learning from Multi-view Images)
NeRF 的训练过程正是利用了其可微分渲染的特性,通过优化 MLP 的权重 Θ,使其能够为任意输入视角渲染出与真实观测图像尽可能一致的图像。
a. 输入数据:
训练 NeRF 需要一组从不同已知视角拍摄的关于同一静态场景的图像,以及每张图像对应的精确相机参数(包括内参如焦距、主点,和外参如相机位置、姿态)。这些相机参数通常可以通过 Structure-from-Motion (SfM) 算法(如 COLMAP)从图像中预先估计得到。
b. 优化目标:
目标是找到一组 MLP 权重 Θ,使得对于训练集中的每一张图像 I_k 及其对应的相机位姿 P_k,从 P_k 视角通过 NeRF 渲染出的图像 I_hat_k(Θ) 与真实图像 I_k 之间的差异最小化。这个差异通常用所有像素颜色的均方误差(MSE)之和来衡量。
c. 训练过程:
● 在每次训练迭代中,随机从所有训练图像的所有像素中采样一批光线(Ray Batch)。
● 对于每条光线,沿其路径采样点,使用当前的 MLP F_Θ 查询密度和颜色。
● 通过体积渲染计算每条光线的预测颜色。
● 计算预测颜色与光线对应的真实像素颜色之间的损失。
● 根据损失反向传播梯度,更新 MLP 的权重 Θ。
● 重复此过程成千上万次(通常需要数十万到数百万次迭代),直至 MLP 收敛,能够准确地复现所有训练视图。
训练完成后,这个 MLP 就"学会"了整个场景的三维几何形状和外观材质信息,可以用来合成任意新视角的图像。
4. 代表性技术/模型/工具/案例/文献与讨论
● [NeRF开创性论文,首次提出神经辐射场的完整理论框架和实现方法]
[来源:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - https://arxiv.org/abs/2003.08934]
● [计算机图形学经典体积渲染技术的深入解析教程]

[来源:The Design and Evolution of Disney's Hyperion Renderer -https://www.yiningkarlli.com/projects/hyperiondesign.html]
● [神经辐射场的数学原理和体积渲染理论详解]

[来源:Volume Rendering - Computer Graphics Tutorial -https://graphics.stanford.edu/courses/cs348b-01/course8.pdf]
二、 NeRF 的关键优势:为何它如此引人注目?

NeRF 之所以能在短时间内引起学术界和工业界的巨大反响,并迅速成为研究热点,主要归功于其相比传统三维重建和渲染方法所展现出的一系列显著优势:
1. 无与伦比的新视图合成质量 (Unparalleled Novel View Synthesis Quality)
这是 NeRF 最令人印象深刻的特点。对于训练数据覆盖较好的区域,NeRF 能够生成具有照片级真实感、细节极其丰富、且在不同视角间保持高度一致性的新视图图像。
a. 精细几何细节的捕捉:
由于其连续的隐式表示,NeRF 能够捕捉到传统基于离散网格的重建方法难以表达的极其精细的几何细节,例如复杂的表面纹理、微小的孔洞、或者毛发、织物等柔软结构的微妙形态。
b. 逼真的视角相关外观:
NeRF 将观察方向作为 MLP 的输入之一来预测颜色,这使其能够准确地学习和再现视角相关的光学效应,如高光反射(Specular Highlights)、菲涅尔效应(Fresnel Effect)等,这些对于提升渲染结果的真实感至关重要。
c. 视图间的高度连贯性:
当在不同新视点之间平滑移动相机时,NeRF 生成的图像序列通常表现出极佳的时间和空间连贯性,不会出现传统方法中可能出现的跳变、闪烁或伪影。这使得 NeRF 非常适合用于创建平滑的相机漫游动画或自由视角视频。
这种高质量的视图合成能力,使得 NeRF 在许多对视觉效果要求极高的应用(如影视特效、VR/AR 内容、数字人)中展现出巨大潜力。
2. 对复杂光学现象的强大表现力 (Strong Representation of Complex Optical Phenomena)
传统三维渲染管线通常需要对场景中的材质属性(如漫反射率、镜面反射率、粗糙度、折射率等)进行显式建模,并依赖复杂的光照传输模拟(如光线追踪、路径追踪)来计算最终图像。而 NeRF 则通过其端到端的学习方式,能够隐式地学习到场景中复杂的全局光照和材质交互效果。
a. 处理反射与折射:
NeRF 能够较好地处理包含镜面反射(如金属表面、水面)或透明/半透明材质(如玻璃、烟雾)的场景,而这些对于许多传统 MVS 方法来说是极大的挑战。它通过学习光线在这些复杂介质中的传播和散射规律来实现这一点。
b. 隐式的全局光照:
虽然基础 NeRF 模型本身不直接建模光源或阴影,但由于它学习的是从特定视角看到的"最终颜色",这个颜色实际上已经包含了场景中所有直接光照、间接光照(全局光照 GI)、软阴影等复杂光线传播效应的综合结果。因此,其渲染结果往往比只考虑局部光照模型的方法更具真实感。
c. 无需显式材质建模:
NeRF 不需要用户预先定义场景中物体的材质类型或参数,它从图像数据中"自行"学习这些光学特性。这简化了内容创建流程,但也可能导致难以对材质进行单独编辑。
这种对复杂光学现象的强大捕捉能力,使得 NeRF 能够生成更接近真实世界光影效果的图像。
3. 连续且紧凑的场景表示 (Continuous and Compact Scene Representation)
NeRF 用一个相对较小的神经网络(通常只有几 MB 到几十 MB 的权重参数)来表示整个三维场景,这与一些需要存储大量离散几何数据(如高分辨率体素网格或密集点云)的表示方法相比,具有显著的存储优势。
a. 紧凑性:
一个训练好的 MLP 网络权重文件通常比存储同等细节水平的显式几何模型(如高精度 Mesh 或密集点云)要小得多。这对于场景的存储、传输和分发非常有利。
b. 连续性与分辨率无关性:
由于场景被表示为连续函数,理论上 NeRF 可以以任意分辨率进行渲染,其细节水平仅受限于 MLP 网络的容量和训练数据的质量,而非像体素或网格那样受限于固定的离散分辨率。这意味着可以从同一个 NeRF 模型中渲染出既适合快速预览的低分辨率图像,也适合精细查看的高分辨率图像。
c. 隐式表示的优势:
隐式表示天然地避免了显式网格可能存在的拓扑问题(如孔洞、非流形)、自相交等,其表面通常是平滑且封闭的(如果场景本身是这样)。
这种表示方式为高效存储和传输高质量三维场景数据提供了新的可能性。
4. 代表性技术/模型/工具/案例/文献与讨论
● [NeRF在新视图合成方面的卓越性能和质量评估]

[来源:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - https://www.matthewtancik.com/nerf]
● [对比研究NeRF与传统多视图立体视觉方法的优势分析]

[来源:Advances in Neural Rendering - Computer Graphics Forum - https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.14507]
● [NeRF在处理复杂光照和反射效果方面的技术突破]
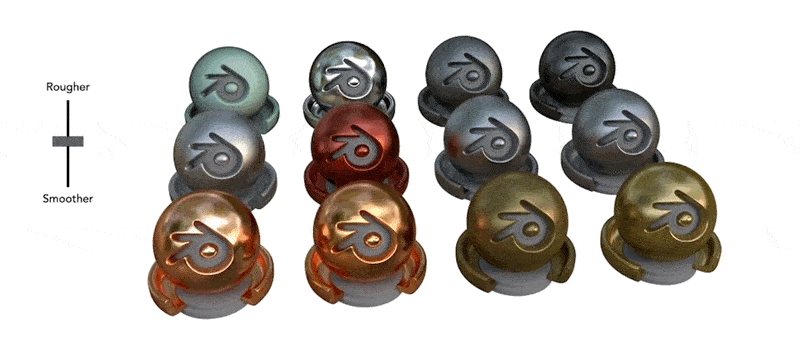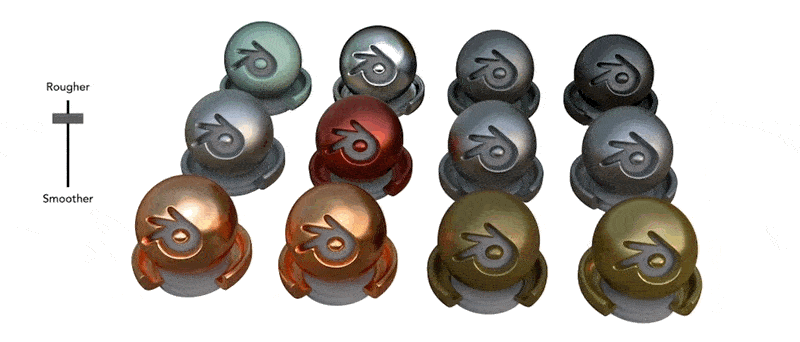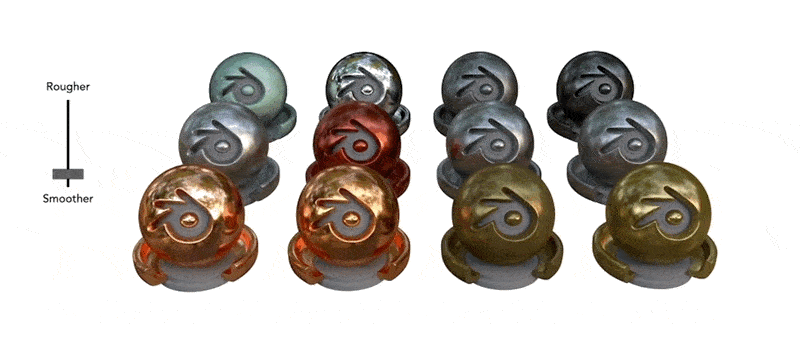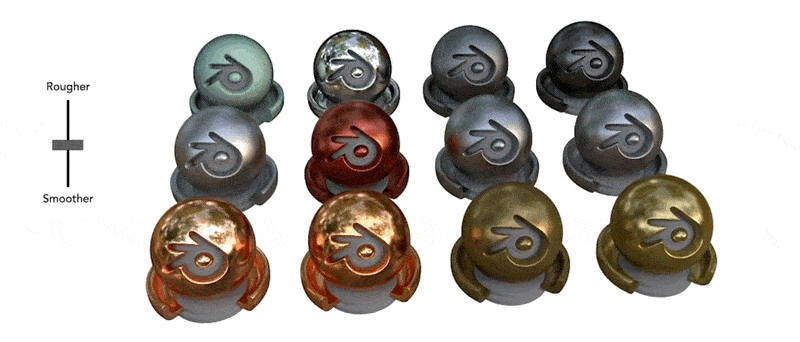
[来源:Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields - https://dorverbin.github.io/refnerf/]
三、 NeRF 的主要挑战与技术局限

尽管 NeRF 带来了革命性的进步,但它并非没有缺点。在将其广泛应用于实际产品和生产流程之前,我们必须清醒地认识到其当前面临的主要挑战和技术局限。这些局限性正是当前研究社区努力攻克的方向。
1. 训练与渲染效率问题 (Training and Rendering Efficiency Issues)
这是早期 NeRF 最受诟病的问题之一,也是阻碍其在许多实时应用中落地的主要障碍。
a. 漫长的训练时间:
原始 NeRF 模型通常需要针对单个场景进行数小时甚至一两天的训练(在单个高端 GPU 上),才能达到较好的收敛效果。这对于需要快速迭代或处理大量场景的应用来说是不可接受的。其原因是 MLP 需要查询海量光线上的海量采样点,并进行大量迭代才能充分学习场景。
b. 缓慢的渲染速度:
从训练好的 NeRF 模型渲染一张新视图(例如 800x800 分辨率)也可能需要数十秒甚至数分钟。这是因为每条光线都需要进行密集的采样和多次 MLP 前向传播,计算量巨大。这使得实时交互式渲染(如 VR/AR 应用所需的 >30 FPS)变得非常困难。
c. 后续改进的努力:
幸运的是,效率问题是 NeRF 研究中最活跃的方向之一。后续涌现了大量旨在加速训练和渲染的工作,例如:
● 基于数据结构优化的方法: 如 PlenOctrees (Plenoxels), DVGO, TensoRF 等,它们使用稀疏体素网格或其他显式数据结构来存储部分场景信息(如特征、密度或球谐系数),从而减少 MLP 的查询次数和复杂度,或者完全替代 MLP。
● 基于哈希编码的方法: 以 Nvidia 的 Instant-NGP (Instant Neural Graphics Primitives) 为代表,通过多分辨率哈希表编码空间坐标,极大地提高了 MLP 的学习效率和表达能力,能够将训练时间从数天缩短到数分钟甚至数秒,渲染速度也大幅提升。
● 显式点云/高斯表示: 近期大热的 3D Gaussian Splatting 则完全抛弃了隐式的 MLP 和体积渲染,转而使用一组带有位置、旋转、缩放、颜色、不透明度等属性的 3D 高斯函数来显式表示场景,通过可微分的光栅化渲染器进行高效渲染,实现了极快的训练速度和SOTA级的实时渲染质量。
尽管效率问题已得到显著改善,但对于超大规模场景、超高分辨率渲染或极低延迟的实时交互,仍然存在挑战。
2. 可编辑性与可控性的难题 (Challenges in Editability and Controllability)
NeRF 将整个场景"烘焙"到一个神经网络的权重中,这种端到端的隐式表示方式虽然强大,但也带来了编辑和控制上的巨大困难。
a. 难以进行直观的几何编辑:
相比于传统的基于 Mesh 的建模软件(用户可以直接选择、移动、变形顶点/边/面),对 NeRF 进行精细的几何修改非常困难。我们无法直接"抓住"NeRF 中的某个物体或表面进行拖拽。
b. 材质与光照的解耦和编辑困难:
NeRF 学习到的是最终的"外观颜色",其中混合了物体的固有材质、场景的全局光照、阴影等多种因素。想要单独修改某个物体的材质(如改变颜色、粗糙度)、或者改变场景的光照条件(如移动光源、改变光照强度/颜色)并得到物理正确的结果,对于标准 NeRF 来说非常困难。
c. 物体级别的操纵与场景组合:
标准 NeRF 将整个场景视为一个整体进行表示。如果想对场景中的单个物体进行移动、旋转、复制、删除,或者将多个独立训练的 NeRF 场景无缝地组合在一起,都面临很大挑战。
d. 语义理解与编辑的缺乏:
NeRF 本身不具备高层语义理解能力。它不知道场景中哪些部分是"桌子",哪些是"椅子"。因此,难以进行基于语义的编辑(例如,"把所有窗户变大一点")。
e. 研究进展:
提升 NeRF 的可编辑性和可控性是当前非常活跃的研究方向。已经出现了一些探索性的工作,例如:
● NeRF-Editing / EditNeRF: 尝试通过变形场或用户引导来修改 NeRF 的几何或外观。
● Object-centric NeRF / Compositional NeRF: 试图将场景分解为多个独立的物体级 NeRF,以便进行单独控制和组合。
● Relighting NeRF / Material-aware NeRF: 致力于从 NeRF 中解耦出物体的固有材质属性(如反照率、法线、粗糙度等)和场景光照,从而实现对光照和材质的独立编辑。
● Instruct-NeRF2NeRF / EditAnything: 结合大型语言模型或视觉语言模型,允许用户通过自然语言指令或简单的视觉提示来编辑 NeRF 场景。
尽管取得了一些进展,但要达到传统 3D 建模软件那样灵活、精确、直观的编辑体验,NeRF 还有很长的路要走。
3. 对输入数据与相机位姿的敏感性 (Sensitivity to Input Data and Camera Poses)
NeRF 的重建质量在很大程度上依赖于输入的多视图图像的质量和对应的相机参数的准确性。
a. 图像质量要求:
输入图像最好清晰、曝光良好、噪声低。模糊、过曝/欠曝、或者包含运动模糊、相机抖动的图像,都会降低重建质量,导致细节丢失或产生伪影。
b. 视角覆盖与数量:
需要有足够数量、从不同角度充分覆盖目标场景的图像。如果某些区域的视角覆盖不足(例如,物体背面完全没有拍到),NeRF 也很难准确重建这些区域,可能会产生"漂浮"或不合理的结构。
c. 相机参数的精度:
NeRF 训练高度依赖于准确的相机内参(焦距、主点、畸变参数)和外参(每张图像的精确位置和姿态)。如果通过 SfM 预处理得到的相机参数存在较大误差,会导致 NeRF 学习到的几何结构变形、模糊或无法收敛。对于某些 SfM 难以处理的场景(如对称结构、重复纹理、运动物体),获取准确相机位姿本身就是一个挑战。
d. 处理动态元素的困难:
标准 NeRF 假设场景是完全静态的。如果训练图像中包含了移动的物体、变化的光照或相机自身的运动(如卷帘快门效应),都会对重建质量造成严重干扰,导致模糊或"鬼影"。处理动态场景是 NeRF 的一个重要扩展方向(如 D-NeRF, Nerfies, HyperNeRF 等)。
因此,在实际应用 NeRF 时,高质量的数据采集和精确的相机位姿估计是保证最终效果的关键前提。
4. 动态场景与大范围场景的扩展挑战 (Challenges in Extending to Dynamic and Large-scale Scenes)
标准 NeRF 主要针对静态、小范围的场景设计,将其直接应用于复杂的动态场景或城市级别的大范围场景面临诸多挑战。
a. 动态场景建模:
如何有效地表示和学习随时间变化的场景几何与外观?如何处理运动物体的遮挡、形变和光照变化?如何从稀疏的视频输入中重建出连贯的动态 NeRF?这些都是极具挑战性的问题。现有方法通常通过引入时间作为 MLP 的额外输入、学习形变场、或者将场景分解为静态背景和动态前景等方式来尝试解决。
b. 大范围场景建模:
单个 MLP 的容量有限,难以精确表示一个非常大(如城市街区)或非常复杂(包含大量物体和细节)的场景。直接用单个 NeRF 训练大场景,不仅训练时间极长,效果也可能不佳(容易丢失细节或产生模糊)。因此,需要研究如何将大场景分解为多个小的、可独立建模的 NeRF 子块,并能实现它们之间的平滑过渡和高效查询。Block-NeRF, Mega-NeRF 等工作是这方面的代表。此外,如何处理大场景中光照的复杂变化(如日夜交替)也是一个难题。
5. 从隐式表示到显式网格的转换 (Conversion from Implicit Representation to Explicit Mesh)
尽管 NeRF 的隐式表示有很多优点,但在许多实际应用中(如游戏引擎、物理模拟、传统建模软件编辑),我们仍然需要一个显式的、高质量的三角网格(Mesh)作为最终交付物。从 NeRF(特别是其核心的密度场 σ)中提取出高质量的表面网格是一个被称为"表面重建"或"Mesh 提取"的过程,本身也存在挑战。
a. 经典方法 Marching Cubes 的局限:
传统上,从隐式函数(如 SDF 或密度场)提取等值面的常用方法是 Marching Cubes 算法。但直接将其应用于 NeRF 的密度场,可能会产生包含大量噪声、不平滑、或者面数过多的网格,尤其是在密度变化不剧烈或存在细小浮空结构的区域。
b. 需要后处理与优化:
通常需要对 Marching Cubes 的输出进行平滑、简化、拓扑修复等后处理操作,才能得到可用的网格。
c. 新的提取算法:
研究者们也在探索更适合 NeRF 的网格提取算法,例如基于可微分渲染进行网格优化的方法(如 DMTet, FlexiCubes)、或者直接从 NeRF 学习生成高质量网格的端到端方法。
d. 纹理烘焙:
提取出网格后,还需要将 NeRF 学习到的视角相关的颜色信息"烘焙"到网格的 UV 纹理贴图上,以便在标准渲染器中使用。这个过程也需要仔细处理,以保留尽可能多的细节和光照效果。
虽然已经有很多工具和方法可以从 NeRF 中提取 Mesh,但要自动、高效地获得与 NeRF 渲染质量相媲美的高质量、低面数、优化拓扑的 Mesh 仍然是一个有待进一步完善的环节。
6. 代表性技术/模型/工具/案例/文献与讨论
效率提升工作:
● [NVIDIA开发的突破性神经图形原语技术,实现千倍加速训练和实时渲染]

[来源:Instant Neural Graphics Primitives with a Multiresolution Hash Encoding - https://nvlabs.github.io/instant-ngp/]
● [革命性的3D高斯点云表示方法,实现实时神经辐射场渲染]

[来源:3D Gaussian Splatting for Real-Time Radiance Field Rendering - https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/]
● [稀疏体素网格优化技术,大幅提升NeRF渲染速度]
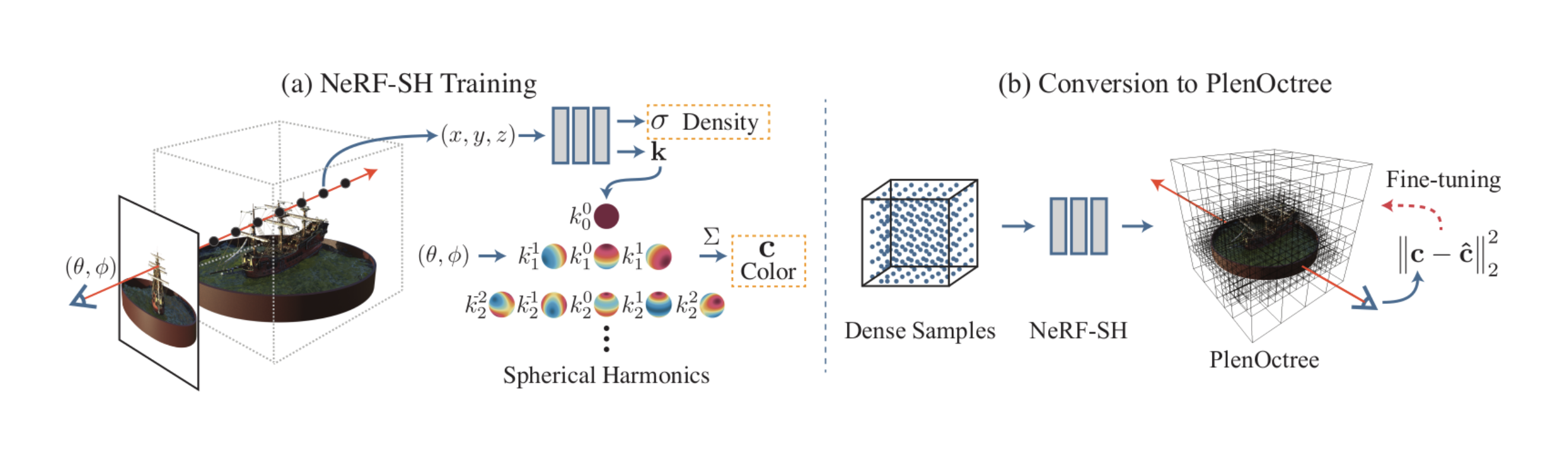
[来源:PlenOctrees for Real-time Rendering of Neural Radiance Fields - https://alexyu.net/plenoctrees/]
可编辑性研究:
● [基于文本指令的NeRF场景编辑技术]

[来源:Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions - https://instruct-nerf2nerf.github.io/]
● [神经表面重建技术,实现从NeRF到高质量网格的转换]

[来源:NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction - https://lingjie0206.github.io/papers/NeuS/]
● [动态场景神经辐射场技术,处理时变几何和外观]
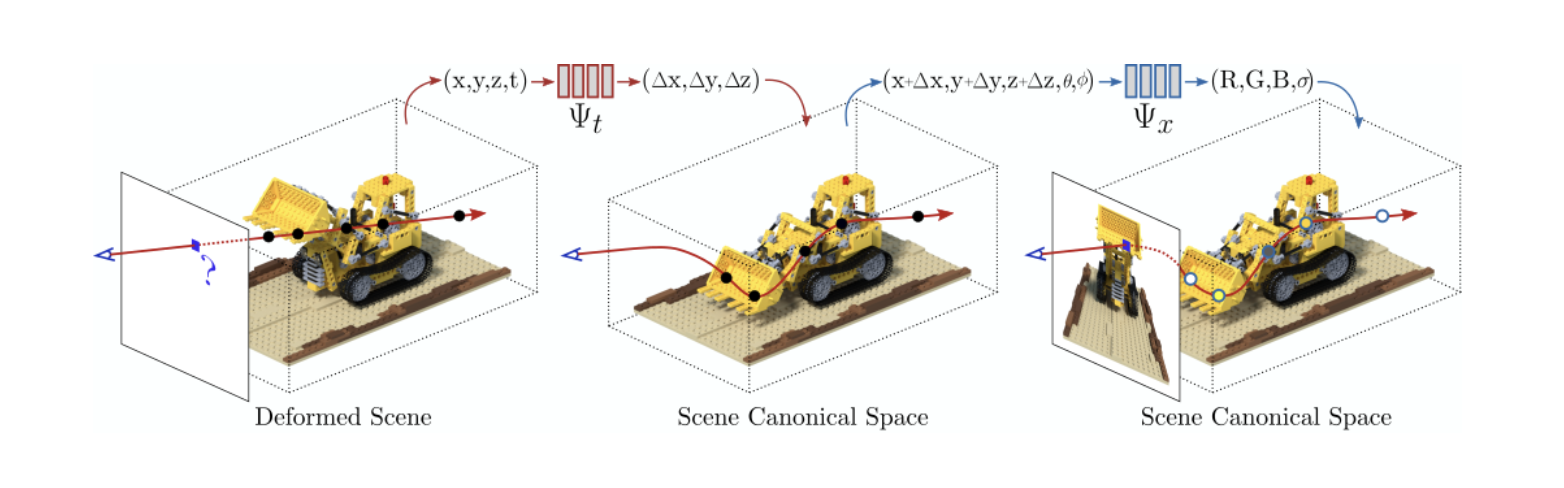
[来源:D-NeRF: Neural Radiance Fields for Dynamic Scenes - https://www.albertpumarola.com/research/D-NeRF/index.html]
● [大场景神经辐射场的分块处理方法]

[来源:Block-NeRF: Scalable Large Scene Neural View Synthesis - https://waymo.com/research/block-nerf/]
● [Mesh提取和几何重建的高级技术方法]

[来源:NeuS: Learning Neural Implicit Surfaces by Volume Rendering - https://arxiv.org/abs/2106.10689]
四、 NeRF 的前沿应用探索与未来展望

尽管面临诸多挑战,NeRF 及其快速发展的变种技术,凭借其独特的优势,已经在多个前沿领域展现出巨大的应用潜力,并预示着三维内容创建与交互方式的深刻变革。
1. 数字孪生与高精度场景重建 (Digital Twins and High-fidelity Scene Reconstruction)
NeRF 能够从真实世界的图像或视频中重建出高保真的三维数字副本,这使其成为构建数字孪生(Digital Twin)的理想技术之一。
a. 城市与建筑数字化:
利用无人机拍摄的城市航拍照片或街景视频,可以训练 NeRF 模型生成整个城市街区或特定建筑的高精度三维数字模型,用于城市规划、智慧交通、建筑信息模型(BIM)可视化、灾害模拟等。
b. 工业场景与设备数字化:
对工厂车间、生产线、复杂机械设备进行 NeRF 重建,可以用于远程监控、设备维护指导、操作流程培训、虚拟装配验证等。
c. 文化遗产保护与展示:
对古迹、文物、艺术品进行高精度 NeRF 扫描和数字化存档,不仅可以永久保存其珍贵信息,还可以通过 VR/AR 等方式向公众提供沉浸式的虚拟参观和互动体验。
2. VR/AR 内容创建与沉浸式体验 (VR/AR Content Creation and Immersive Experiences)
NeRF 生成的场景具有照片级的真实感和视图间的强一致性,非常适合用于创建高质量的 VR(虚拟现实)和 AR(增强现实)内容,提供更具沉浸感的体验。
a. 真实场景的 VR 漫游:
用户可以"走进"通过 NeRF 重建的真实场景(如旅游景点、博物馆、房产样板间)进行自由探索和互动。
b. AR 内容与现实世界的融合:
将 NeRF 重建的虚拟物体或场景叠加到现实环境中,实现更逼真的增强现实效果,例如在真实桌面预览虚拟家具、在真实街道上进行 AR 导航指引等。
c. 提高虚拟社交与远程协作的真实感:
在元宇宙或远程协作平台中,使用 NeRF 技术创建更逼真的虚拟环境和用户化身,可以增强临场感和社交互动体验。
3. 虚拟制片与影视特效 (Virtual Production and VFX)
NeRF 在影视行业的应用潜力也备受关注,尤其是在虚拟制片和视觉特效(VFX)领域。
a. 场景预演与概念设计:
导演和美术团队可以利用 NeRF 快速将真实场景或概念草图转化为可交互的三维预览,用于镜头设计、光照测试和美术风格确认。
b. 背景替换与环境扩展:
使用 NeRF 重建真实拍摄场景的数字副本,可以在后期制作中更方便地进行背景元素的替换、擦除或数字环境的扩展,甚至生成无法实际拍摄的极端视角。
c. 数字演员与虚拟角色:
虽然挑战仍大,但利用 NeRF(特别是动态 NeRF)技术创建高度逼真的数字演员或虚拟角色,并能自然地融入真实或虚拟场景中,是未来的重要发展方向。
4. 机器人感知与自主导航 (Robotics Perception and Autonomous Navigation)
NeRF 作为一种强大的场景表示方法,也开始被应用于机器人领域,帮助机器人更好地理解和感知周围环境,并进行更智能的导航和交互。
a. 高精度环境建图:
机器人可以利用其搭载的摄像头,在探索未知环境时实时或离线构建 NeRF 地图,这种地图比传统的点云或栅格地图包含更丰富的外观和几何信息。
b. 自主导航与路径规划:
基于 NeRF 地图,机器人可以进行更精确的自身定位,并规划出更安全、更高效的导航路径,尤其是在包含复杂几何和外观的室内或室外环境中。
c. 物体识别与位姿估计:
NeRF 表示有助于机器人从不同视角识别场景中的物体,并估计其精确的六自由度位姿,这对于抓取、操纵等任务至关重要。
5. 作为生成模型的中间表示 (Intermediate Representation for Generative Models)
正如我们在 S2E02 中讨论的,NeRF(或其变种如 SDF)由于其连续、可微的特性,已经成为许多先进的 Text-to-3D 或 Image-to-3D 生成模型(特别是基于优化的方法如 DreamFusion)首选的底层三维表示。AI 首先生成或优化一个 NeRF 场景,然后再从中提取出最终的 Mesh。NeRF 在这里扮演了连接高层语义输入(文本、图像)和低层三维几何输出的关键桥梁角色。
6. 未来趋势:更快、更可控、更通用、更可交互
展望未来,NeRF 技术的发展将主要围绕以下几个方向持续演进:
a. 效率的极致追求 (Faster):
训练和渲染速度将继续提升,目标是实现大规模场景的秒级训练和超高分辨率的实时交互渲染,使其能广泛应用于对延迟要求极高的场景。3D Gaussian Splatting 等显式表示方法在这方面已经取得了巨大进展,未来可能会与 NeRF 的思想进一步融合。
b. 可控性与可编辑性的增强 (More Controllable & Editable):
发展更直观、更精确、更细粒度的 NeRF 编辑工具和交互方式,让用户能够像编辑传统 Mesh 一样方便地修改 NeRF 场景的几何、材质、光照,甚至进行语义级别的操纵。
c. 通用性与泛化能力的提升 (More General & Generalizable):
训练能够理解和表示更广泛类别场景、甚至能从少量新视图快速泛化到全新场景的通用 NeRF 模型(Foundation Models for 3D Scenes)。处理无界大场景、复杂动态场景的能力也将持续增强。
d. 与其他 AI 技术的深度融合 (Deeper Integration with other AI):
例如,与大型语言模型(LLM)结合实现通过自然语言对话进行场景创建和编辑;与强化学习(RL)结合训练智能体在 NeRF 环境中进行交互和学习;与物理引擎结合实现对 NeRF 场景的真实物理模拟等。
e. 走向更广泛的终端设备 (Wider Device Accessibility):
优化 NeRF 模型和渲染算法,使其能够在算力相对有限的移动设备、VR/AR 一体机上高效运行,从而推动相关应用的普及。
NeRF 及其引发的神经场景表示研究浪潮,无疑正在深刻地改变我们创建、感知和交互三维世界的方式。
7. 代表性技术/模型/工具/案例/文献与讨论
● [NeRF在数字孪生和虚拟现实中的创新应用案例]

[来源:Neuralangelo: High-Fidelity Neural Surface Reconstruction - https://research.nvidia.com/labs/dir/neuralangelo/]
● [基于NeRF的虚拟制片和影视制作技术革新]
[来源:Neural Volumes: Learning Dynamic Renderable Volumes from Images - https://stephenlombardi.github.io/projects/neuralvolumes/]
● [NeRF技术在机器人视觉和自主导航中的应用前景]
[来源:NeRF for Robotics: A Survey - https://arxiv.org/abs/2309.07891]
● [下一代NeRF变种技术和3D生成模型的发展趋势]

[来源:Plenoxels: Radiance Fields without Neural Networks - https://alexyu.net/plenoxels/]
结语:NeRF——开启三维内容创作新纪元的钥匙之一
通过本篇笔记的深度剖析,我们一同探索了 NeRF (神经辐射场) 这一革命性技术的奥秘。从其精巧的核心思想——用一个简单的神经网络隐式地"记住"整个三维场景的光学特性,并通过可微分的体积渲染重现光影——到其令人惊叹的关键优势,如无与伦比的新视图合成质量、对复杂光学现象的强大表现力以及连续紧凑的场景表示。NeRF 无疑为三维计算机视觉和图形学领域带来了全新的视角和强大的工具。
然而,我们也清醒地认识到,作为一项仍在快速发展的技术,NeRF 并非没有软肋。其在训练与渲染效率、可编辑性与可控性、对输入数据的敏感性、以及向动态和大范围场景扩展等方面,仍面临着诸多亟待解决的挑战。这些挑战也正是当前学术界和工业界投入巨大热情进行攻关的方向,催生了 Instant-NGP, Gaussian Splatting, Instruct-NeRF2NeRF 等一系列令人振奋的后续工作。
对于我们产品经理而言,理解 NeRF 的原理、优势与局限,其意义远不止于增加一项技术谈资。它关系到我们能否:
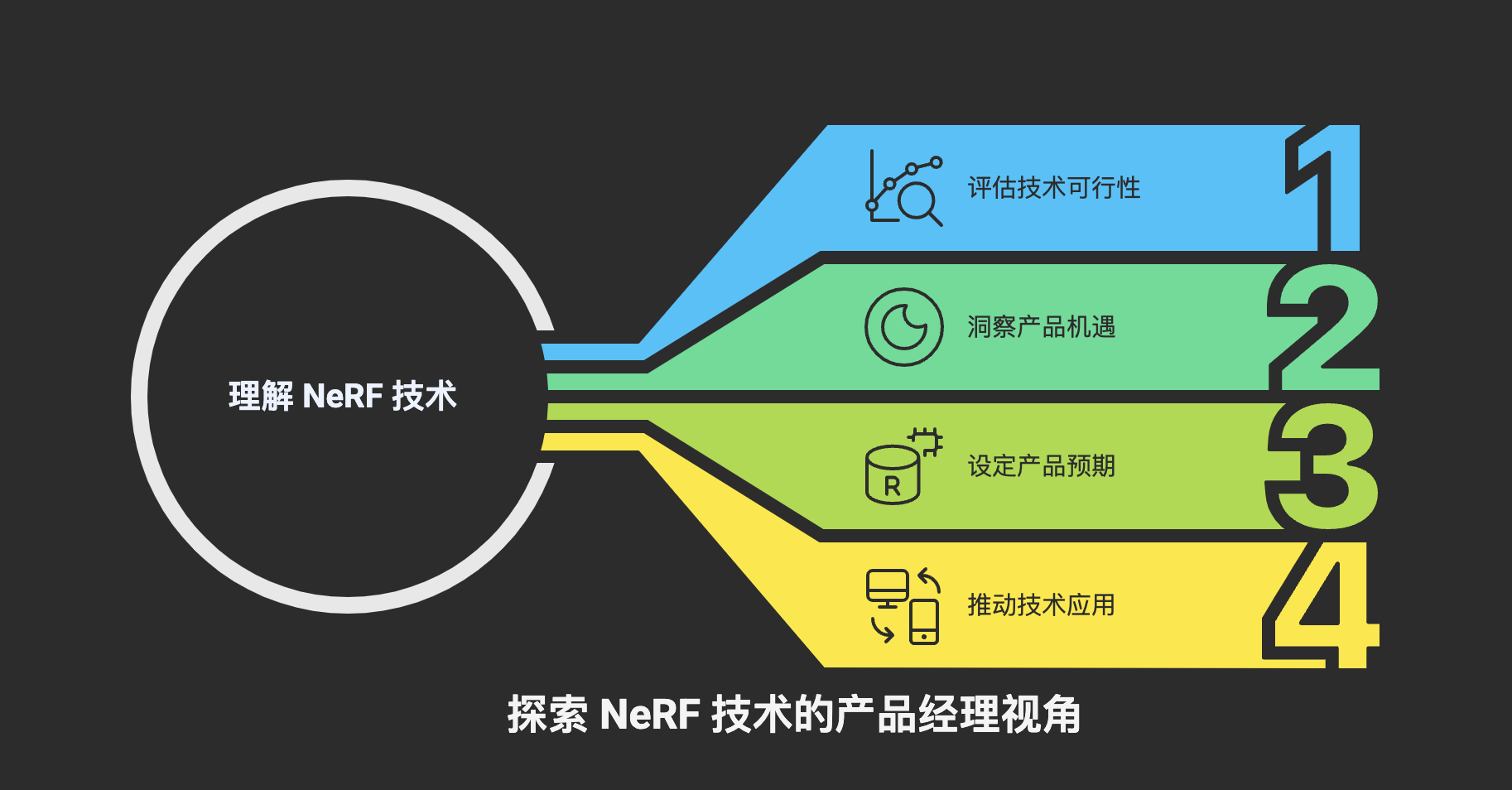
● 准确评估技术可行性: 在规划包含高保真三维场景重建、新视图合成、或沉浸式体验的产品功能时,能够判断 NeRF 类技术是否是合适的选择,其当前成熟度是否能满足项目需求。
● 洞察新的产品机遇: NeRF 的出现正在催生或赋能一系列新的应用场景,如更易用的 3D 扫描工具、更逼真的 VR/AR 内容、更高效的虚拟制片流程等。我们需要思考如何在这些新兴领域中找到产品的切入点。
● 设定合理的产品预期: 了解 NeRF 的局限性,有助于我们向团队、用户和市场传递准确的信息,避免过度承诺,管理好各方预期。
● 推动技术与应用的结合: 在理解技术边界的前提下,与研发团队共同探索如何扬长避短,将 NeRF 的优势与具体的用户痛点和业务场景相结合,创造出真正有价值的产品。
NeRF 及其所代表的神经场景表示方法,无疑是开启下一代三维内容创作与交互新纪元的重要钥匙之一。它正在从实验室走向更广泛的应用,其影响力将日益深远。作为产品经理,持续关注其发展,深入理解其内涵,积极思考其应用,将是我们在这个激动人心的变革时代保持竞争力的关键。
在下一篇笔记(S2E05)中,我们将聚焦另一个 AI 生成 3D 的核心技术引擎——Diffusion Model (扩散模型),探讨它是如何从二维图像生成的辉煌走向三维内容创造的新大陆的。


![[面试精选] 0104. 二叉树的最大深度](https://i-blog.csdnimg.cn/img_convert/cd7b0a2ec004958ca69ffbdd8f1a4287.jpeg)