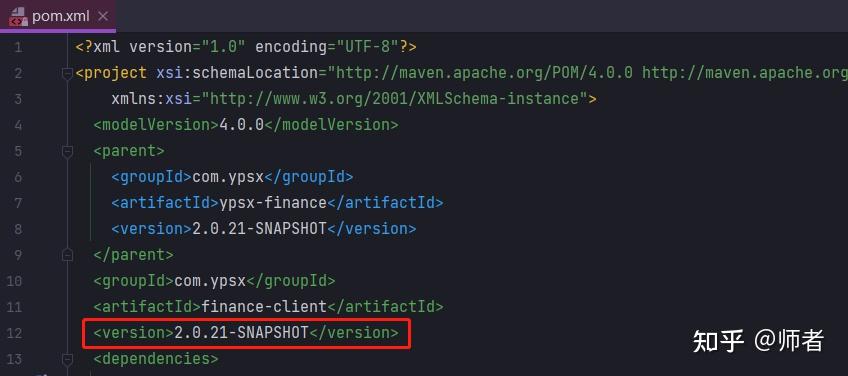
1. Scrapy的核心组成
引擎(engine):scrapy的核心,所有模块的衔接,数据流程梳理。
调度器(scheduler):本质可以看成一个集合和队列,里面存放着一堆即将要发送的请求,可以看成是一个url容器,它决定了下一步要爬取哪一个url,通常我们在这里可以对url进行去重操作。
下载器(downloader):本质是一个用来发动请求的模块,可以理解成是一个requests.get()的功能,只不过返回的是一个response对象。
爬虫(spider):负载解析下载器返回的response对象,从中提取需要的数据。
管道(pipeline):主要负责数据的存储和各种持久化操作。
2. 安装步骤
这里安装的scrapy版本为2.5.1版,在pycharm命令行内输入pip install scrapy==2.5.1即可。
pip install scrapy==2.5.1但是要注意OpenSSL的版本,其查看命令为
scrapy version --verbose
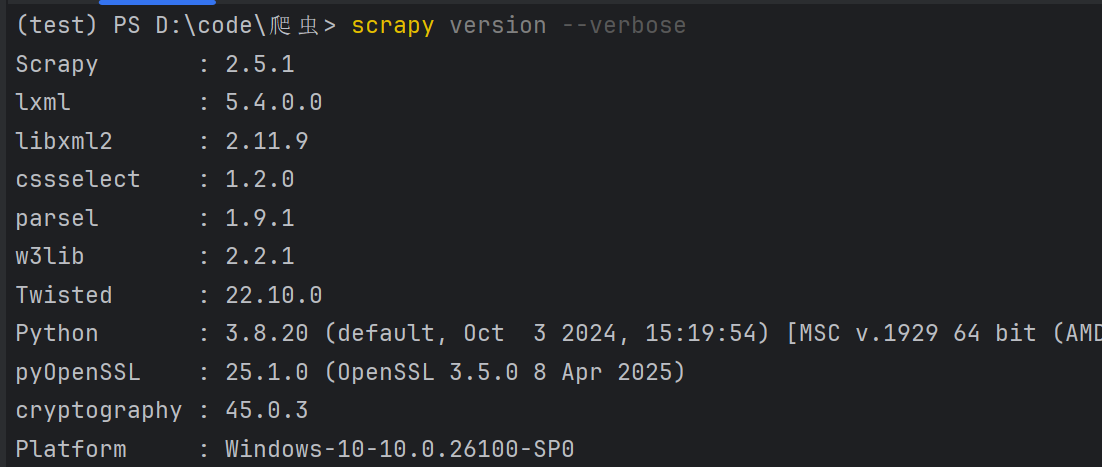
如果OpenSSL版本不为1.1版本的话,需要对其进行降级。
pip uninstall cryptography
pip install cryptography==36.0.2注:如果降级之后使用scrapy version --verbose出现错误:TypeError: deprecated() got an unexpected keyword argument 'name',可能是OpenSSL版本过低导致,这里需要根据自身情况,进行对应处理。
卸载cryptography:pip uninstall cryptography
重新安装cryptography 36.0.2:pip install cryptography==36.0.2
卸载pyOpenSSL:pip uninstall pyOpenSSL
重新安装pyOpenSSL 22.0.0:pip install pyOpenSSL==22.0.0 如果查看时出现错误:AttributeError: 'SelectReactor' object has no attribute '_handleSignals'
可能是由于Twisted版本问题,进行卸载重新安装Twisted即可。
pip uninstall Twisted
pip install Twisted==22.10.03. 基础使用
1.创建项目
scrapy startproject 项目名
2.进入项目目录
cd 项目名
3.生成spider
scrapy genspider 爬虫名字 网站的域名
4.调整spider
给出start_urls以及如何解析数据
5.调整setting配置文件
配置user_agent,robotstxt_obey,pipeline
取消日志信息,留下报错,需调整日志级别 LOG_LEVEL
6.允许scrapy程序
scrapy crawl 爬虫的名字
4. 案例分析
当使用 scrapy startproject csdn 之后,会出现csdn的文件夹
当输入 scrapy genspider csdn_spider blog.csdn.net 之后,会出现
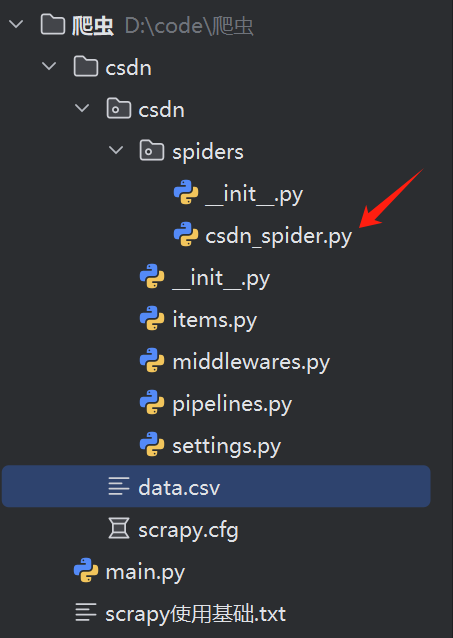
我们这里以爬取自己csdn所发表的文章为例,在csdn_spider.py中编辑页面元素的定位方式
import scrapy
class CsdnSpiderSpider(scrapy.Spider):
name = 'csdn_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/mozixiao__']
def parse(self, response):
print('===>',response)
infos = response.xpath('//*[@id="navList-box"]/div[2]/div/div/div') #这里的路径需要注意的是,最后一个div不需要加确定的值,这里是一个模糊匹配,不然infos就只有一个信息
for info in infos:
title = info.xpath('./article/a/div/div[1]/div[1]/h4/text()').extract_first().strip()
date = info.xpath('./article/a/div/div[2]/div[1]/div[2]/text()').extract_first().strip().split()[1]
view = info.xpath('./article/a/div/div[2]/div[1]/div[3]/span/text()').extract_first().strip()
dianzan = info.xpath('./article/a/div/div[2]/div[1]/div[4]/span/text()').extract_first().strip()
pinglun = info.xpath('./article/a/div/div[2]/div[1]/div[5]/span/text()').extract_first().strip()
shouchang = info.xpath('./article/a/div/div[2]/div[1]/div[6]/span/text()').extract_first().strip()
yield {
'title':title,
'date':date,
'view':view,
'dianzan':dianzan,
'pinglun':pinglun,
'shouchang':shouchang
}
# print(title,date,view,dianzan,pinglun,shouchang)通过yield返回的数据会传到piplines.py文件中,在pipelines.py文件中进行数据的保存。
#管道想要使用要在setting开启
class CsdnPipeline:
def process_item(self, item, spider):
# print(type(item['title']),type(item['date']),type(item['view']),type(item['dianzan']),type(item['pinglun']),type(item['shouchang']))
with open('data.csv',mode='a+',encoding='utf-8') as f:
# line =
f.write('标题:{} 更新日期:{} 浏览量:{} 点赞:{} 评论:{} 收藏:{} \n'.format(
item['title'],item['date'],item['view'],item['dianzan'],item['pinglun'],item['shouchang']))
# f.write(f"标题:{item['title']} 更新日期:{item['date']} 浏览量:{item['view']} 点赞:{item['dianzan']} 评论:{item['pinglun']} 收藏:{item['shouchang']} \n")
return item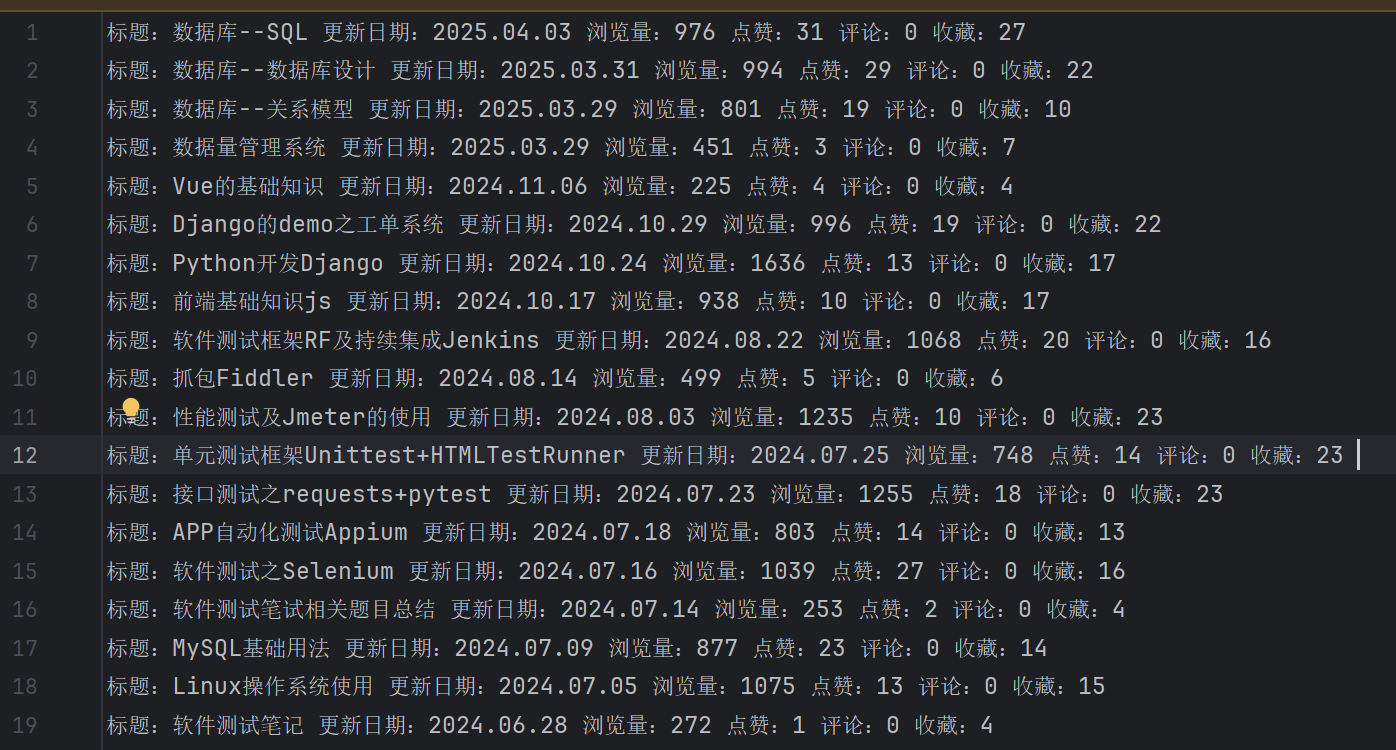
5. pipelines.py改进
上面的pipelines.py文件中对于文件的open次数与爬取的信息数量有关,为了减少文件的读取关闭操作,采用全局操作的方式。
class CsdnPipeline:
def open_spider(self,spider):
self.f = open('data.csv',mode='a+',encoding='utf-8')
def close_spider(self,spider):
self.f.close()
def process_item(self, item, spider):
self.f.write('标题:{} 更新日期:{} 浏览量:{} 点赞:{} 评论:{} 收藏:{} \n'.format(
item['title'],item['date'],item['view'],item['dianzan'],item['pinglun'],item['shouchang']))
# f.write(f"标题:{item['title']} 更新日期:{item['date']} 浏览量:{item['view']} 点赞:{item['dianzan']} 评论:{item['pinglun']} 收藏:{item['shouchang']} \n")
return item6. 爬虫时,当前页面爬取信息时,需要跳转到其他url
爬取当前页面时,爬取到的信息是一个url信息,这是需要将其与之前的url进行拼接。
以https://desk.zol.com.cn/dongman/为主url,/bizhi/123.html为跳转url为例。如果链接以 / 开头,需要拼接的是域名,最前面的 / 是根目录。结果为https://desk.zol.com.cn/bizhi/123.html。如果不是以 / 开头,需要冥界的是当前目录,同级文件夹中找到改内容。结果为https://desk.zol.com.cn/dongman/bizhi/123.html。
为了方便url的跳转,可以使用python中urllib库或者scrapy封装好的函数。
class PicSpiderSpider(scrapy.Spider):
name = 'pic_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/mozixiao__']
def parse(self, response):
infos = response.xpath('')
for info in infos:
if info.endswith(''):
continue
#方法1
from urllib.parse import urljoin
child_url = urljoin(response.url,info)
#方法2
child_url = response.urljoin(info)为了更好地处理跳转之后的链接(不需要用requests库写图片的提取),同时为了方式新的url继续跳转到parse,我们可以重写一个new_parse来处理跳转url。
import scrapy
from scrapy import Request
class PicSpiderSpider(scrapy.Spider):
name = 'pic_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/mozixiao__']
def parse(self, response):
infos = response.xpath('')
for info in infos:
if info.endswith(''):
continue
#方法1
# from urllib.parse import urljoin
# child_url = urljoin(response.url,info)
#方法2
child_url = response.urljoin(info)
yield Request(child_url,callback=self.new_parse)
def new_parse(self,response):
img_src = response.xpath('')
yield {
"src":img_src
}7. pipelines.py保存对象是图片或者文件等
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from scrapy.pipelines.files import FilesPipeline
from scrapy import Request
class PicPipeline(ImagesPipeline):
def get_media_requests(self,item,info):
srcs = item['src']
for src in srcs:
yield Request(src,meta={'path':src})
def file_path(self,request,response=None,info=None,*,item=None):
path = request.meta['path']
file_name = path.split('/')[-1]
return '***/***/***/{}'.format(file_name)
def item_completed(self, results, item,info):
return item注:为了使图片可以成功的保存,需要在settings.py文件中设置一个IMAGES_STORE的路径。同时,如果在下载图片时,出现了302的问题,需要设置MEDIA_ALLOW_REDIRECTS。

8. Scrapy爬虫遇到分页跳转的时候
1.普通分页
表现为:上一页 1,2,3,4,5,6 下一页
类型1:
观察页面源代码发现url直接在页面源代码里体现
解决方案:
1.访问第一页->提取下一个url,访问下一页
2.直接观察最多大少爷,然后观察每一页url的变化
类型2:
观察页面源代码发现url不在页面源代码中体现
解决方案:
通过抓包找规律(可能在url上体现,也可能在参数上体现)
2.特殊分页
类型1:
显示为加载更多的图标,点击之后出来一推新的信息
解决方案:
通过抓包找规律
类型2:
滚动刷新,滑倒数据结束的时候会再次加载新数据
这种通常的逻辑是:这一次更新时获得的参数会附加到下一次更新的请求中情况1:如果遇到分页跳转信息在url中体现,可以通过重写start_request的方式来进行
import scrapy
from scrapy import Request
class FenyeSpiderSpider(scrapy.Spider):
name = 'fenye_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/']
def start_requests(self):
num = int(input())
for i in range(1,num):
url = "https://***.com/page_{}.html".format(i)
yield Request(url)
def parse(self, response):
pass情况2:分页跳转信息的url体现在的页面源代码中
import scrapy
from scrapy import Request
class FenyeSpiderSpider(scrapy.Spider):
name = 'fenye_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/page_1.html']
def parse(self, response):
infos = response.xpath('')
for info in infos:
if info.startswith('***'):
continue
child_info = response.urljoin(info)
#这里无需考虑死循环的问题,scrapy中的调度器会自动去重
yield Request(child_info,callback=self.parse)9. Scrapy面对带有cookie的信息页面时的登陆操作
1.常规登录
网站会在cookie中写入登录信息,在登陆成功之后,返回的响应头里面会带着set-cookie字样,后续的请求会在请求头中加入cookie内容
可以用session来自动围护响应头中的set-cookie
2. ajax登陆
登陆后,从浏览器中可能发现响应头没有set-cookie信息,但是在后续的请求中存在明显的cookie信息
该情况90%的概率是:cookie通过JavaScript脚本语言动态设置,seesion就不能自动维护了,需要通过程序手工去完成cookie的拼接
3. 依然是ajax请求,也没有响应头,也是js
和2的区别是,该方式不会把登录信息放在cookie中,而是放在storage里面。每次请求时从storage中拿出登录信息放在请求参数中。
这种方式则必须要做逆向。
该方式有一个统一的解决方案,去找公共拦截器。
方法1,直接在settings.py文件中设置请求头信息。但是由于scrapy(引擎和下载器之间的中间件)会自动管理cookie,因此设置时,也需要将COOKIES_ENABLED设置为False

方法2,重写start_requests函数,将cookie作为参数传入
import scrapy
from scrapy import Request
class LoginSpiderSpider(scrapy.Spider):
name = 'login_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/']
def start_requests(self):
cookie_info = ""
cookie_dic = {}
for item in cookie_info.split(';'):
item = item.strip()
k,v = item.split('=',1)
cookie_dic[k]=v
#需要注意的是,这里的cookie要以自己的参数传入,而不是字符串
yield Request(self.start_urls[0],cookies=cookie_dic)
def parse(self, response):
pass方法3,自己走一个登录流程,登录之后,由于scrapy(引擎和下载器之间的中间件)会自己管理cookie信息,所以直接执行start_urls即可。
import scrapy
from scrapy import Request
class LoginSpiderSpider(scrapy.Spider):
name = 'login_spider'
allowed_domains = ['blog.csdn.net']
start_urls = ['http://blog.csdn.net/']
def start_requests(self):
login_url = "https://blog.csdn.net/login"
data = {
'login':'123456',
'password':'123456'
}
#但是这里要注意,Request中的body需要传入的是字符串信息,而不是字典
#方法1
login_info = []
for k,v in data.items():
login_info.append(k+"="+v)
login_info = '&'.join(login_info)
#方法2
from urllib.parse import urlencode
login_info = urlencode(data)
yield Request(login_url,method='POST',body=login_info)
def parse(self, response):
pass10. Scrapy中间件
中间件位于middlewares.py文件中,
11. Scrapy之链接url提取器
上面提到当爬虫需要跳转url时,需要使用urljoin的函数来进行url的凭借,这个操作可以使用LinkExtractor来简化。
from urllib.request import Request
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy import Request
import re
class LinkSpiderSpider(scrapy.Spider):
name = 'link_spider'
allowed_domains = ['4399.com']
start_urls = ['https://www.4399.com/flash_fl/5_1.htm']
def parse(self, response):
# print(response.text)
game_le = LinkExtractor(restrict_xpaths=("//ul[@class='list affix cf']/li/a",))
game_links = game_le.extract_links(response)
for game_link in game_links:
# print(game_link.url)
yield Request(url=game_link.url,callback=self.game_name_date)
if '5_1.htm' in response.url:
page_le = LinkExtractor(restrict_xpaths=("//div[@class='bre m15']//div[@class='pag']/a",))
else:
page_le = LinkExtractor(restrict_xpaths=("//div[@class='pag']/a",))
page_links = page_le.extract_links(response)
for page_link in page_links:
# print(page_link.url)
yield Request(url=page_link.url,callback=self.parse)
def game_name_date(self,response):
try:
name = response.xpath('//*[@id="skinbody"]/div[7]/div[1]/div[1]/div[2]/div[1]/h1/a/text()')
info = response.xpath('//*[@id="skinbody"]/div[7]/div[1]/div[1]/div[2]/div[2]/text()')
if not info:
info = response.xpath('//*[@id="skinbody"]/div[6]/div[1]/div[1]/div[2]/div[2]/text()')
# print(name,info)
# print(1)
name = name.extract_first()
infos = info.extract()[1].strip()
size = re.search(r'大小:(.*?)M',infos).group(1)
date = re.search(r'日期:(\d{4}-\d{2}-\d{2})',infos).group(1)
yield {
'name':name,
'size':size+'M',
'date':date
}
except Exception as e:
print(e,info,response.url)12. 增量式爬虫
当爬取的数据中包含之前访问过的数据时,需要对url进行判断,以保证不重复爬取。增量式爬虫不能将中间数据存储在内存级别的存储,只能选择硬盘上的存储。
import scrapy
from redis import Redis
from scrapy import Request,signals
class ZengliangSpiderSpider(scrapy.Spider):
name = 'zengliang_spider'
allowed_domains = ['4399.com']
start_urls = ['http://4399.com/']
#观察到middlewares中间间中的写法,想要减少程序连接redis数据库的次数
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
#如果遇到Crawler中找不到当前spider时,可以参考父类中的写法,将去copy过来
#s._set_crawler(crawler)
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def spider_opened(self, spider):
self.red = Redis(host='',port=123,db=3,password='')
def spider_closed(self,spider):
self.red.save()
self.red.close()
def parse(self, response):
hrefs = response.xpath('').extract()
for href in hrefs:
href = response.urljoin(href)
if self.red.sismember('search_path',href):
continue
yield Request(
url=href,
callback=self.new_parse,
meta={'href':href} #防止url重定向
)
def new_parse(self,response):
href = response.meta.get('href')
self.red.sadd('save_path',href)
pass13. 分布式爬虫
scrapy可以借助scrapy-redis插件来进行分布式爬虫,但要注意两个库的版本问题。
与普通的scrapy不同,redis版本的在spider文件中继承时采用redis的继承。
from scrapy_redis.spiders import RedisSpider
class FbSpider(RedisSpider):
name = 'fb'
allowed_domains = ['4399.com']
redis_key = "path"
def parse(self, response):
pass同时,需要在settings.py中设置redis相关的信息。
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'fenbu.pipelines.FenbuPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline':301
}
REDIS_HOST = ''
REDIS_PORT = ''
REDIS_DB = ''
REDIS_PARAMS = {
'':''
}以上这些就是我关于scrapy爬虫的基本学习,有疑问可以相互交流。




![[ElasticSearch] DSL查询](https://i-blog.csdnimg.cn/direct/b56fdbff20444ae7918ba17ea8501727.png)