Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
➡️ 论文标题:Math-PUMA: Progressive Upward Multimodal Alignment to Enhance Mathematical Reasoning
➡️ 论文作者:Wenwen Zhuang, Xin Huang, Xiantao Zhang, Jin Zeng
➡️ 研究机构: University of Chinese Academy of Sciences、Beijing Institute of Technology、Beihang University
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在解决基于文本的数学问题方面表现出色,但在处理涉及图像的数学问题时面临挑战。这些模型主要在自然场景图像上进行训练,导致在处理数学图表时性能下降。人类在解决问题时,无论信息以何种模态呈现,难度通常相似,且视觉辅助通常能增强解决问题的能力。然而,MLLMs在处理视觉信息时的能力显著下降,尤其是在从文本到视觉的过渡中。
➡️ 研究动机:为了解决MLLMs在处理数学图表时的不足,研究团队提出了Math-PUMA,一种基于渐进式向上多模态对齐(Progressive Upward Multimodal Alignment, PUMA)的方法,旨在通过三个阶段的训练过程增强MLLMs的数学推理能力。该方法通过构建大规模的数据集和多模态对齐技术,有效缩小了不同模态问题之间的性能差距。
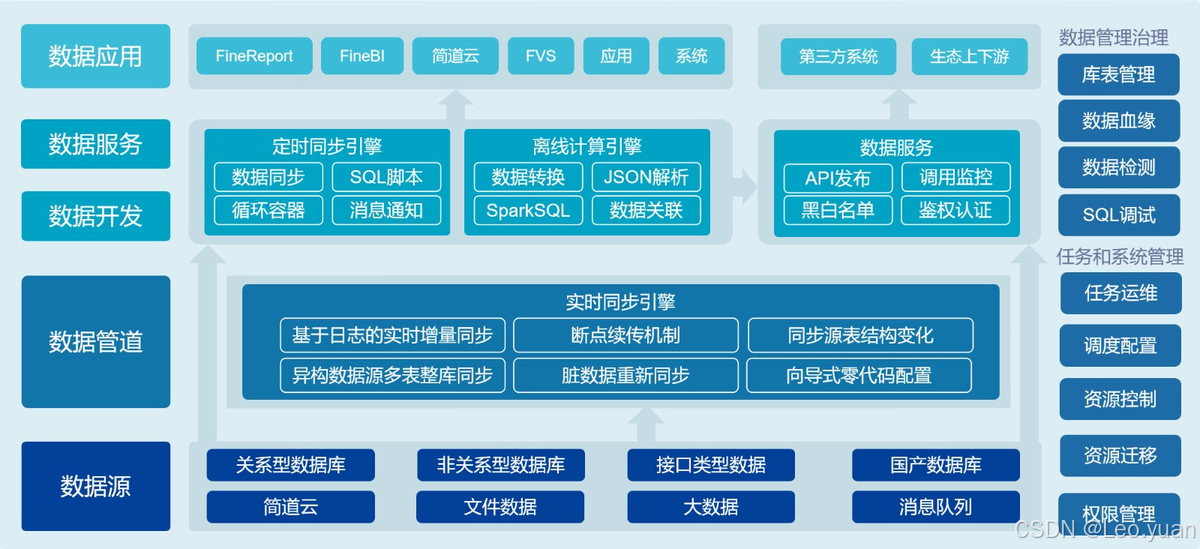
➡️ 方法简介:Math-PUMA方法包括三个阶段:1) 首先,通过大量基于文本的数学问题数据集训练语言模型,增强其数学推理能力;2) 然后,构建包含不同模态信息的数据对,通过计算KL散度实现视觉和文本模态的对齐,逐步提升模型处理多模态数学问题的能力;3) 最后,利用高质量的多模态数据进行指令调优,进一步增强模型的多模态数学推理能力。
➡️ 实验设计:研究团队在三个广泛使用的多模态数学问题解决基准上进行了实验,包括MATHVERSE、MATHVISTA和WE-MATH。实验结果表明,经过Math-PUMA训练的MLLMs在多个基准上显著优于大多数开源模型,特别是在处理不同模态的问题时,性能差距明显缩小。
Med-PMC: Medical Personalized Multi-modal Consultation with a Proactive Ask-First-Observe-Next Paradigm
➡️ 论文标题:Med-PMC: Medical Personalized Multi-modal Consultation with a Proactive Ask-First-Observe-Next Paradigm
➡️ 论文作者:Hongcheng Liu, Yusheng Liao, Siqv Ou, Yuhao Wang, Heyang Liu, Yanfeng Wang, Yu Wang
➡️ 研究机构: Shanghai Jiao Tong University, Shanghai AI Lab
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在医疗领域展现出处理多模态信息的能力,但其在临床场景中的应用仍处于探索阶段。现有的医疗多模态基准测试主要集中在医疗视觉问答(VQA)和报告生成上,未能全面评估MLLMs在复杂临床多模态任务中的表现。此外,这些模型在处理个性化患者模拟器时,未能有效收集多模态信息,并在决策任务中表现出潜在的偏见。
➡️ 研究动机:为了更全面地评估MLLMs在实际临床场景中的性能,研究团队提出了一个新颖的医疗个性化多模态咨询(Med-PMC)范式。Med-PMC通过构建模拟临床环境,要求MLLMs与患者模拟器进行多轮互动,以完成多模态信息收集和决策任务。研究旨在通过这一范式,揭示MLLMs在处理复杂和动态临床互动中的能力,为未来医疗MLLMs的发展提供指导。
➡️ 方法简介:研究团队设计了一个模拟临床环境,其中MLLMs需要与个性化患者模拟器进行多轮互动,以收集患者的多模态症状信息,并最终提供可能的诊断结果和治疗建议。患者模拟器由状态跟踪器、响应生成器和个性化演员三个主要组件构成,能够模拟真实临床场景中的患者多样性,确保模拟的可靠性和真实性。
➡️ 实验设计:研究在30个真实的医疗案例上进行了实验,这些案例主要来自普通外科。实验评估了12种不同类型的MLLMs在信息收集和最终决策两个方面的表现。评估指标包括信息收集的召回率和决策的准确性,采用自动评估和基于大语言模型的评估方法进行验证。实验结果表明,即使是最先进的医疗MLLMs在处理多模态医疗信息时仍存在显著不足,为未来的研究指明了方向。
ECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
➡️ 论文标题:ECG-Chat: A Large ECG-Language Model for Cardiac Disease Diagnosis
➡️ 论文作者:Yubao Zhao, Tian Zhang, Xu Wang, Puyu Han, Tong Chen, Linlin Huang, Youzhu Jin, Jiaju Kang
➡️ 研究机构: 北京师范大学、中国地质大学、法国高等电力学院、山东建筑大学、南方科技大学、英国利物浦大学、吉林大学珠海学院、北京工业大学
➡️ 问题背景:多模态大语言模型(MLLMs)在医疗辅助领域展现了巨大潜力,允许患者使用生理信号数据进行对话。然而,现有的MLLMs在心脏病诊断方面表现不佳,尤其是在ECG数据分析和长文本医疗报告生成的整合上,主要原因是ECG数据分析的复杂性和文本与ECG信号模态之间的差距。此外,模型在长文本生成中往往表现出严重的稳定性不足,缺乏与用户查询紧密相关的精确知识。
➡️ 研究动机:为了解决上述问题,研究团队提出了ECG-Chat,这是第一个专注于ECG医疗报告生成的多任务MLLM,提供基于心脏病学知识的多模态对话能力。研究旨在通过对比学习方法整合ECG波形数据与文本报告,实现ECG特征与报告内容的细粒度对齐,从而提高模型在信号数据表示上的性能。此外,研究还构建了一个19K的ECG诊断数据集和25K的多轮对话数据集,用于训练和微调ECG-Chat,以提供专业的诊断和对话能力。
➡️ 方法简介:研究团队提出了一种系统的方法,通过对比学习方法将ECG波形数据与文本报告结合,实现ECG特征与报告内容的细粒度对齐。此外,研究团队还构建了一个新的数据生成管道,使用现有数据集和GPT-4创建了一个ECG指令调优数据集(ECG-Instruct),包含19K的诊断数据和25K的对话数据。基于这些数据集,研究团队微调了Vicuna-13B,创建了一个ECG领域的语言模型ECG-Chat,支持报告生成、ECG问题回答等多种功能。
➡️ 实验设计:研究团队在多个任务上测试了模型的性能,包括ECG报告检索、ECG分类和ECG报告生成,并建立了ECG报告生成任务的基准。实验结果表明,ECG-Chat在分类、检索、多模态对话和医疗报告生成任务上均取得了最佳性能。此外,研究团队还提出了一种诊断驱动的提示(DDP)方法,有效提高了模型的准确性,并使用自动化LaTeX生成管道生成了详细的ECG报告。
Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models
➡️ 论文标题:Reefknot: A Comprehensive Benchmark for Relation Hallucination Evaluation, Analysis and Mitigation in Multimodal Large Language Models
➡️ 论文作者:Kening Zheng, Junkai Chen, Yibo Yan, Xin Zou, Xuming Hu
➡️ 研究机构: Hong Kong University of Science and Technology (Guangzhou), Hong Kong University of Science and Technology
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种任务中展现了强大的能力,但它们在生成过程中容易产生幻觉(hallucinations),尤其是关系幻觉(relation hallucinations)。现有的研究和基准测试主要集中在对象级和属性级幻觉上,而忽视了更复杂的关系幻觉,这些幻觉需要更高级的推理能力。此外,现有的关系幻觉基准测试缺乏详细的评估和有效的缓解策略,且数据集往往存在系统性偏差。
➡️ 研究动机:为了应对上述研究空白,研究团队提出了Reefknot,这是一个全面的基准测试,旨在评估和缓解多模态大语言模型中的关系幻觉。Reefknot包含超过20,000个真实世界的样本,通过系统地定义关系幻觉并构建基于场景图数据集的关系语料库,研究团队揭示了当前MLLMs在处理关系幻觉方面的显著局限性。此外,研究团队提出了一种基于置信度的缓解策略,该策略在三个数据集上平均减少了9.75%的幻觉率。
➡️ 方法简介:研究团队构建了Reefknot基准测试,该基准测试包括感知和认知两个类别的关系幻觉,以及三种评估任务(Yes/No、多项选择题和视觉问答)。Reefknot的数据集基于Visual Genome场景图数据集中的语义三元组构建,确保了数据的真实性和多样性。研究团队还提出了一种名为“Detect-Then-Calibrate”的方法,通过分析模型在生成过程中的置信度变化来检测和缓解幻觉。
➡️ 实验设计:研究团队在Reefknot基准测试上评估了多个主流的MLLMs,包括LLaVA、MiniGPT4-v2、Qwen-vl等。实验设计了不同的任务类型(如Yes/No、多项选择题和视觉问答),以全面评估模型在处理关系幻觉方面的表现。实验结果表明,MLLMs在感知关系幻觉方面比认知关系幻觉更容易出现问题。此外,研究团队通过分析模型在不同层的置信度变化,揭示了关系幻觉生成的机制,并提出了基于置信度的缓解策略。
FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant
➡️ 论文标题:FFAA: Multimodal Large Language Model based Explainable Open-World Face Forgery Analysis Assistant
➡️ 论文作者:Zhengchao Huang, Bin Xia, Zicheng Lin, Zhun Mou, Wenming Yang, Jiaya Jia
➡️ 研究机构: Tsinghua University、The Chinese University of Hong Kong、HKUST
➡️ 问题背景:随着深度伪造技术的快速发展,面部伪造对公共信息安全构成了严重威胁。现有的面部伪造分析数据集缺乏对伪造技术、面部特征和环境因素的详细描述,导致模型在复杂条件下的伪造检测能力有限。此外,现有的方法难以提供用户友好且可解释的结果,阻碍了对模型决策过程的理解。
➡️ 研究动机:为了应对上述挑战,研究团队引入了一种新的开放世界面部伪造分析视觉问答任务(OW-FFA-VQA)及其相应的基准测试。通过构建包含多样化的真伪面部图像及其描述和伪造推理的FFA-VQA数据集,研究团队旨在提高模型的泛化能力和鲁棒性,同时提供用户友好且可解释的结果。
➡️ 方法简介:研究团队提出了FFAA(Face Forgery Analysis Assistant),该系统由一个微调的多模态大语言模型(MLLM)和多答案智能决策系统(MIDS)组成。通过在FFA-VQA数据集上微调MLLM,并结合假设性提示,FFAA能够有效缓解模糊分类边界的影响,增强模型的鲁棒性。
➡️ 实验设计:研究团队在多个公开数据集上进行了实验,包括OW-FFA-Bench。实验设计了多种因素的变化,如图像质量、面部属性和环境因素,以全面评估模型在复杂条件下的表现。实验结果表明,FFAA不仅提供了用户友好且可解释的结果,还在准确性和鲁棒性方面显著优于现有方法。




![[ElasticSearch] DSL查询](https://i-blog.csdnimg.cn/direct/b56fdbff20444ae7918ba17ea8501727.png)