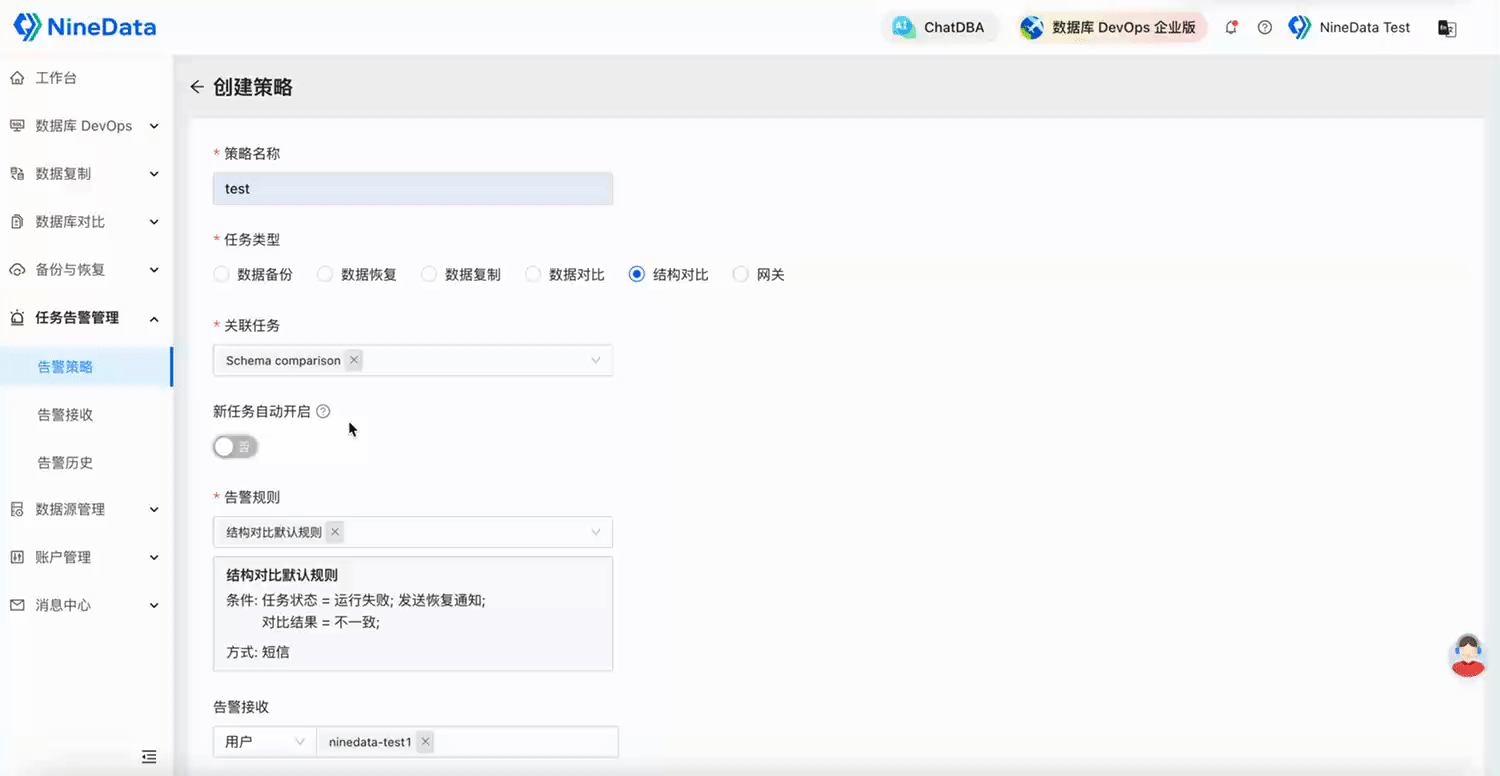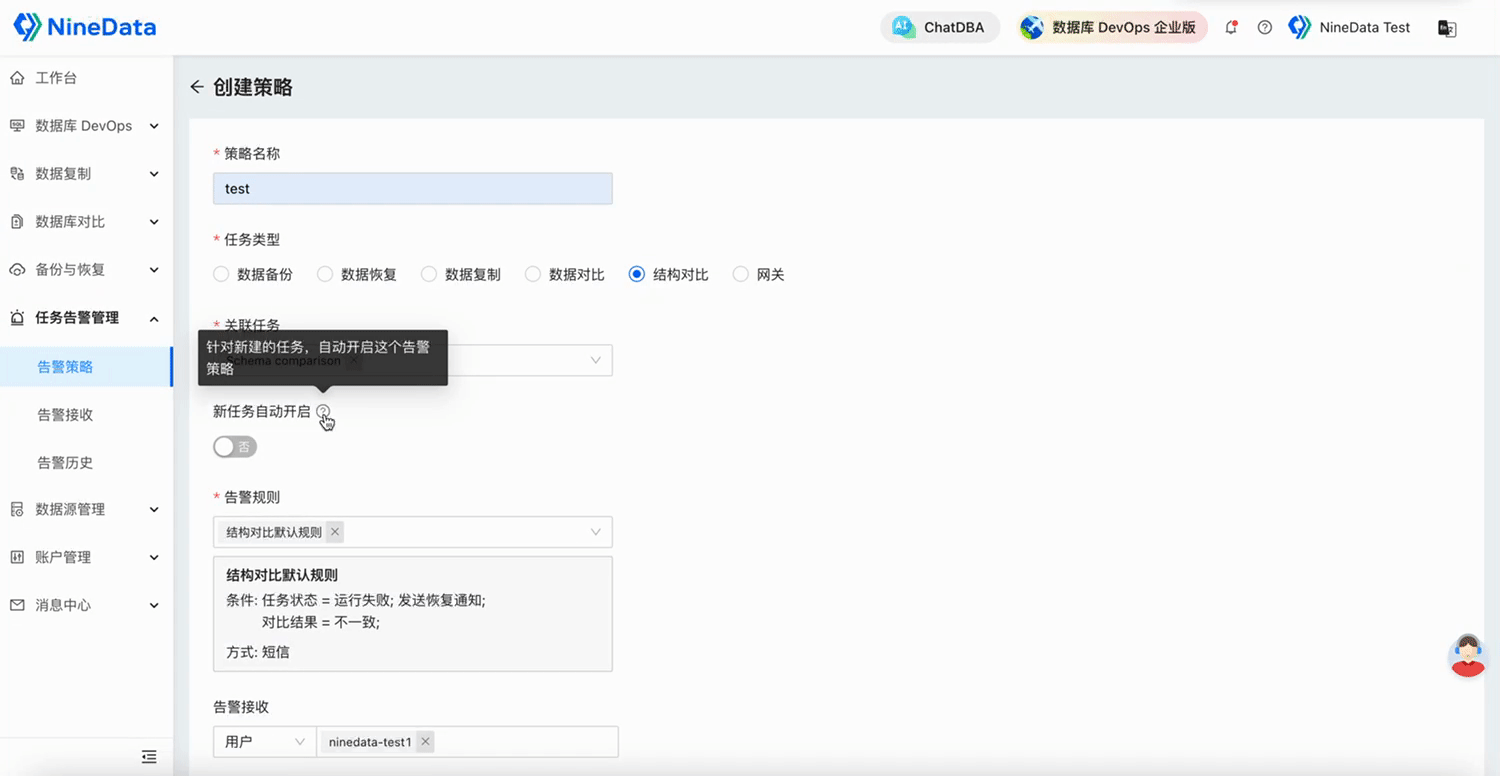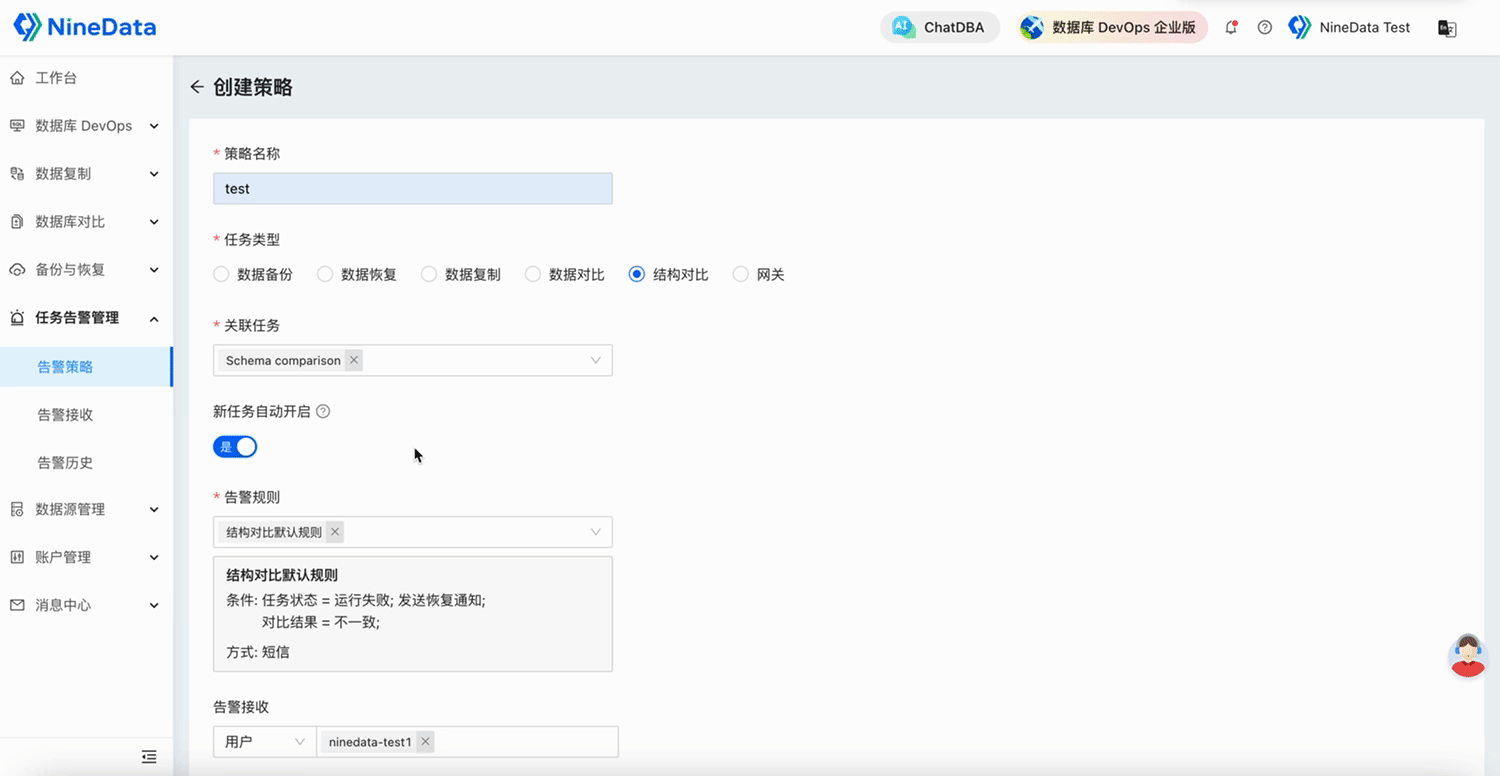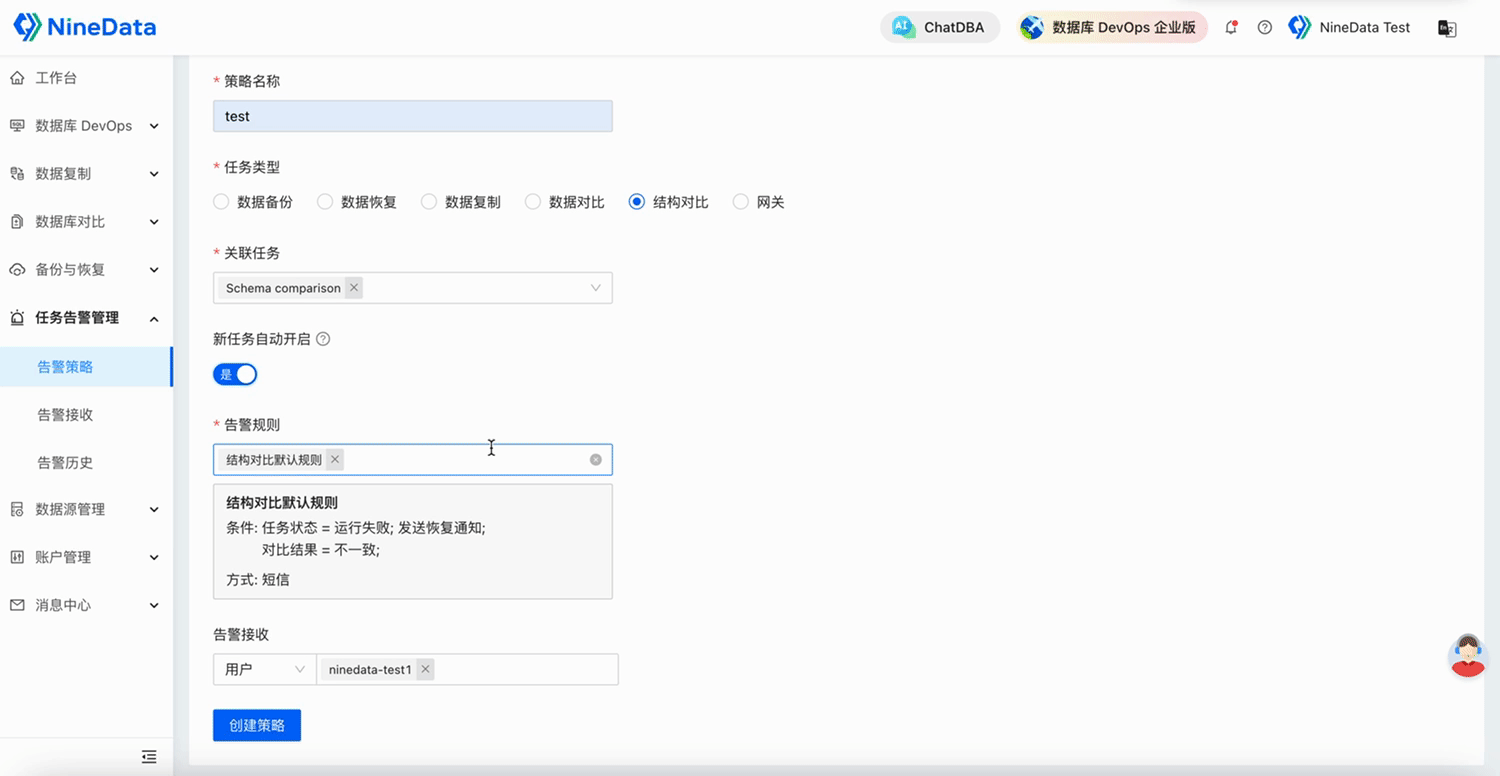
蒙特卡罗模拟不仅仅是一种理论练习,它还是一种强大的工具,在金融、医疗保健、物流等领域都有实际应用。本篇文章将探讨高级和复杂的现实生活场景,深入探讨它们的细微差别,并通过详细的解释在 Python 中实现它们。
什么是蒙特卡罗模拟?
蒙特卡罗模拟(Monte Carlo Simulation)是一种利用重复随机抽样来了解系统行为的计算技术。通过运行数以千计或数以百万计的模拟,你可以估算出概率、风险和其他涉及不确定性问题的统计量。它的核心思想是:通过大量重复的随机实验,逼近真实世界的统计规律。
关键特点:
-
概率驱动:输入变量可以具有概率分布(如正态分布、均匀分布等),模拟结果反映随机性影响。
-
大数定律:模拟次数越多,结果越接近理论预期值。
-
适用性广:适用于金融、工程、物理、医疗、物流等多个领域。
基本步骤:
-
定义模型:确定输入变量及其概率分布(如股票收益率、设备故障率等)。
-
随机抽样:从输入分布中生成大量随机样本。
-
计算输出:运行模拟(如投资组合回报、系统可靠性等)。
-
统计分析:汇总结果(均值、标准差、置信区间等)。
为什么用Python 实现?
Python的numpy、scipy和pandas等库能高效生成随机数并进行统计分析,而matplotlib和seaborn可帮助可视化模拟结果。
蒙特卡罗模拟将“不确定性”转化为可量化的概率,是数据驱动决策的重要工具。
1. 投资组合风险评估
问题
投资者经常面临一个关键问题: 资产组合的风险有多大?投资组合风险来自
-
资产回报: 单个资产的收益或损失。
-
相关性: 资产收益的相对变化。
-
波动性: 资产收益的波动性。
蒙特卡罗模拟(Monte Carlo Simulation)允许我们模拟收益的不确定性,并评估特定时间段后投资组合的潜在价值。
步骤
-
根据平均值、标准差和相关性模拟单个资产的收益。
-
计算每次模拟的投资组合总回报。
-
分析结果分布以衡量风险。
# 年均收益率和标准差
mean_returns = np.array([0.08, 0.12, 0.06]) # 资产收益率
std_devs = np.array([0.2, 0.3, 0.15]) # 波动率
# 模拟相关矩阵
correlation_matrix = np.array([
[1.0, 0.2, 0.4],
[0.2, 1.0, 0.3],
[0.4, 0.3, 1.0]
])
# 模拟相关随机回报
cov_matrix = np.diag(std_devs) @ correlation_matrix @ np.diag(std_devs)
returns = np.random.multivariate_normal(mean_returns, cov_matrix, n_simulations)
# 模拟投资组合权重
weights = np.array([0.4, 0.4, 0.2])
# 模拟投资组合回报
portfolio_returns = np.dot(returns, weights)
# 分析风险
mean_portfolio_return = np.mean(portfolio_returns)
value_at_risk_95 = np.percentile(portfolio_returns, 5) # 5th percentile (95% VaR)
loss_prob = np.mean(portfolio_returns < 0) # Probability of loss
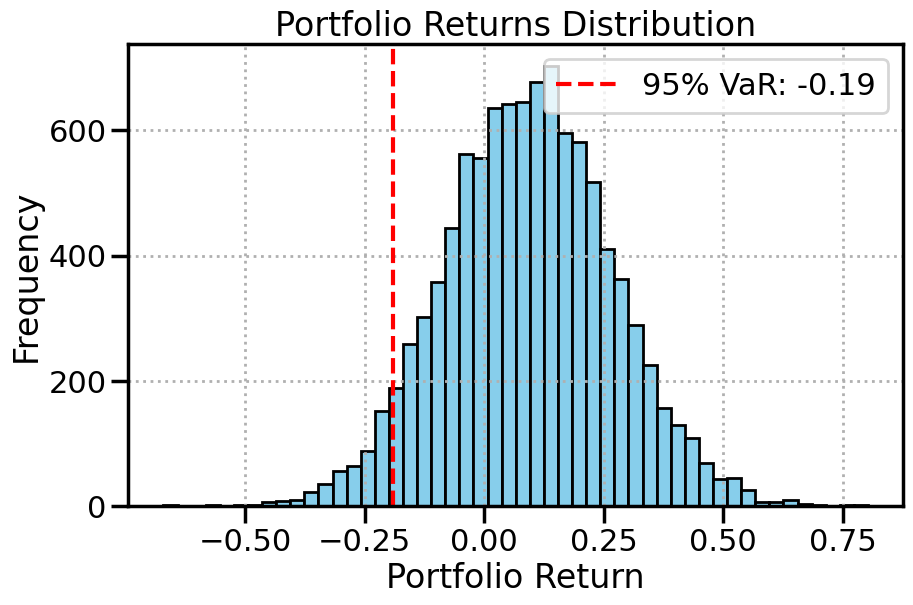
观察到
-
投资组合平均收益: 投资组合的平均预期回报。
-
风险值(VaR): 95% 置信度下的最大潜在损失。
-
损失概率: 投资组合出现亏损的可能性。
2. 疾病传播模拟(流行病学)
问题
像 COVID-19 这样的传染病爆发需要建模来预测传播和评估干预措施。蒙特卡罗模拟法可以通过为感染率和康复率等参数添加随机性来扩展SEIR 模型(易感-暴露-感染-康复)。
步骤
-
使用随机 SEIR 方程模拟疾病的传播。
-
在传播率和恢复率中引入随机性。
-
评估不同干预措施(如疫苗接种率)下的结果。
population = 10000
initial_infected = 10
initial_exposed = 5
transmission_rate = 0.2
incubation_rate = 0.1
recovery_rate = 0.05
time_steps = 100
n_simulations = 100
results = []
for _ in range(n_simulations):
susceptible = population - initial_infected - initial_exposed
exposed = initial_exposed
infected = initial_infected
recovered = 0
s, e, i, r = [], [], [], []
for _ in range(time_steps):
new_exposed = np.random.binomial(susceptible, transmission_rate * infected / population)
new_infected = np.random.binomial(exposed, incubation_rate)
new_recovered = np.random.binomial(infected, recovery_rate)
susceptible -= new_exposed
exposed += new_exposed - new_infected
infected += new_infected - new_recovered
recovered += new_recovered
s.append(susceptible)
e.append(exposed)
i.append(infected)
r.append(recovered)
results.append((s, e, i, r))
average_results = np.mean(results, axis=0)
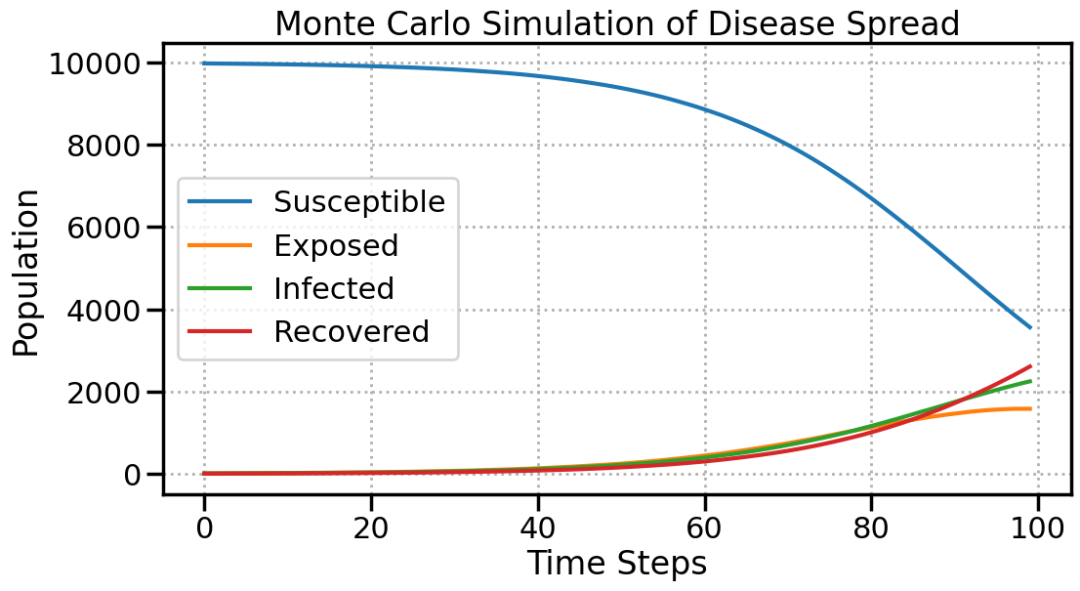
观察到
-
感染高峰: 确定感染率达到峰值的时间,评估医疗保健系统的能力。
-
干预措施的效果: 使用模拟来比较社会隔离或疫苗接种等方案。
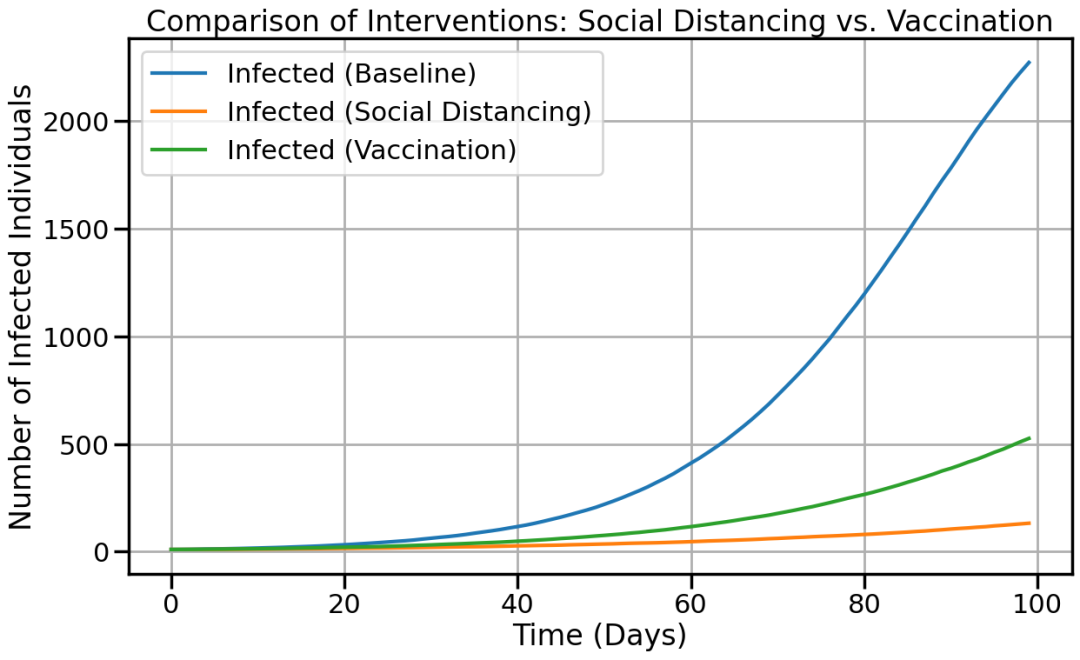
比较干预措施的效果(社会隔离与疫苗接种)
模拟假设:
-
人口 : 10,000 人。
-
基准传播率(β) : 0.2(接触率)。
-
潜伏率(σ) :0.1(接触者感染率)。
-
恢复率(γ) :0.05(感染个体的恢复率)。
-
干预:
-
社会隔离 : 将 β 减少 50%。
-
接种疫苗 : 为 30% 的人口接种疫苗,使他们直接进入恢复群体。
-
时间范围: 100 天。
-
模拟次数: 每个方案运行 100 次,以纳入随机性。
population = 10000
initial_infected = 10
initial_exposed = 5
transmission_rate = 0.2 # baseline beta
incubation_rate = 0.1 # sigma
recovery_rate = 0.05 # gamma
time_steps = 100
n_simulations = 100
scenarios = {
"Baseline": transmission_rate,
"Social Distancing": transmission_rate * 0.5,
"Vaccination": transmission_rate
}
results = {scenario: {"Susceptible": [], "Exposed": [], "Infected": [], "Recovered": []} for scenario in scenarios}
for scenario, beta in scenarios.items():
for _ in range(n_simulations):
susceptible = population - initial_infected - initial_exposed
exposed = initial_exposed
infected = initial_infected
recovered = 0
# apply vaccination for the "Vaccination" scenario
if scenario == "Vaccination":
vaccinated = int(0.3 * population) # 30% vaccinated
susceptible -= vaccinated
recovered += vaccinated
s, e, i, r = [], [], [], []
for _ in range(time_steps):
new_exposed = np.random.binomial(susceptible, beta * infected / population)
new_infected = np.random.binomial(exposed, incubation_rate)
new_recovered = np.random.binomial(infected, recovery_rate)
susceptible -= new_exposed
exposed += new_exposed - new_infected
infected += new_infected - new_recovered
recovered += new_recovered
s.append(susceptible)
e.append(exposed)
i.append(infected)
r.append(recovered)
results[scenario]["Susceptible"].append(s)
results[scenario]["Exposed"].append(e)
results[scenario]["Infected"].append(i)
results[scenario]["Recovered"].append(r)
3. 可再生能源系统的能源生产
问题
风能或太阳能发电场等可再生能源系统受天气条件等随机因素的影响。蒙特卡罗模拟有助于估算不确定情况下的能源生产量,并据此规划产能。
步骤
-
使用概率分布模拟天气条件的变化。
-
模拟每日或每小时的能源产出。
-
汇总结果,确定平均和最坏情况下的生产方案。
days = 365
n_simulations = 1000
mean_wind_speed = 12 # m/s
std_dev_wind_speed = 4 # m/s
capacity_factor = 0.3 # efficiency of wind conversion
rated_capacity = 3.0 # mW per turbine
daily_energy = []
for _ in range(n_simulations):
wind_speeds = np.random.normal(mean_wind_speed, std_dev_wind_speed, days)
wind_speeds = np.clip(wind_speeds, 0, None) # No negative wind speeds
power_output = rated_capacity * capacity_factor * (wind_speeds / mean_wind_speed)
daily_energy.append(np.sum(power_output))
average_annual_energy = np.mean(daily_energy)
percentile_5 = np.percentile(daily_energy, 5) # wrst-case production
percentile_95 = np.percentile(daily_energy, 95) # best-case production
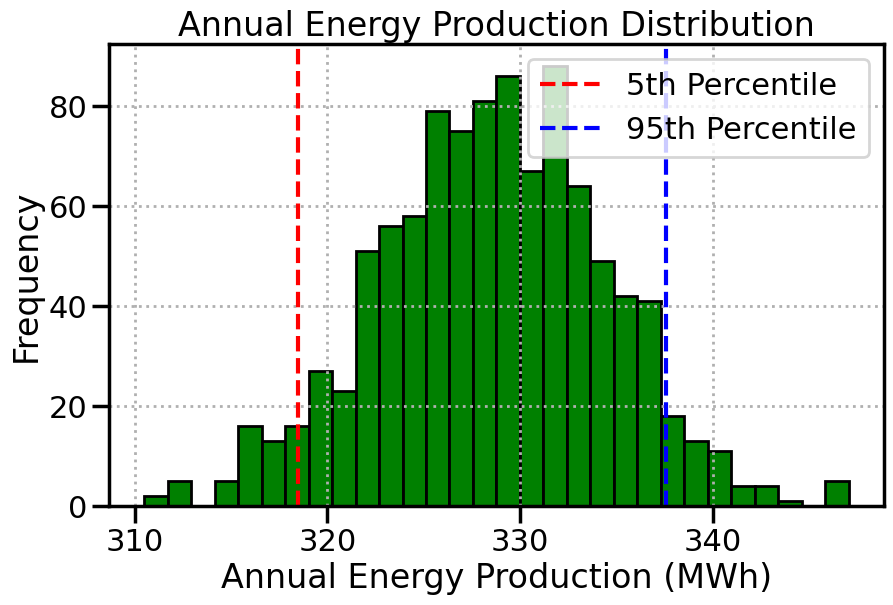
观察到:
-
平均产量: 有助于设定切合实际的预期。
-
最坏情况: 评估低风速时的可靠性。
蒙特卡洛模拟是解决现实世界问题中不确定性的一种通用而强大的技术。从金融到流行病学和能源规划,它的应用范围广泛,影响深远。这里介绍的详细示例展示了其模拟复杂系统和提取可行见解的能力。
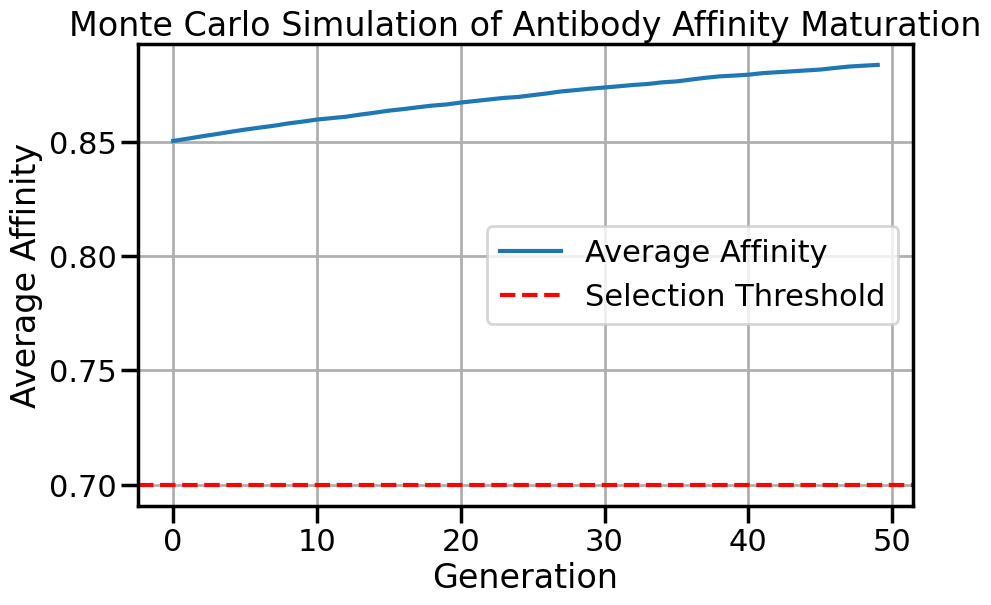
4. 抗体亲和力成熟建模
问题
在免疫学中,亲和力成熟是一个 B 细胞经历体细胞超突变和选择以产生对特定抗原具有更高亲和力的抗体的过程。这一过程涉及随机突变和选择压力。蒙特卡罗模拟(Monte Carlo Simulation)可以对这一过程进行建模,分析不同的突变率或选择阈值如何影响结果。
步骤
1. 定义模型:
-
从具有随机初始亲和力的 B 细胞群体开始。
-
在每一代中,根据突变率对群体进行突变。
-
施加选择压力,只保留亲和力高于阈值的 B 细胞。
2. 运行模拟:
-
改变突变率或选择阈值,以探索其影响。
3. 分析:
-
跟踪各代的平均亲和力。
-
比较突变策略或阈值。
写在最后
蒙特卡罗模拟以其独特的概率视角,为复杂现实问题的决策提供了强大的数据驱动支持。从简单的随机抽样到多变量、多层次的复杂系统建模,它能够揭示传统分析方法难以捕捉的不确定性和风险。Python 凭借其丰富的科学计算库(如 NumPy、SciPy 和 Pandas)以及可视化工具(如 Matplotlib 和 Seaborn),使得这些高级应用的实现既高效又可扩展。无论是金融风险评估、医疗方案优化,还是物流网络设计,蒙特卡罗模拟都展现了其作为跨领域决策工具的非凡价值。掌握其核心思想并灵活运用 Python 生态系统,将帮助你在面对不确定性时,做出更明智、更自信的选择。