1.println(Array(1,2,3,4,5).filter(_%2==0).toList()
输出结果是(B)
A.
2
4
B.
List(2,4)
C.
List(1,3,5)
D.
1
3
5
2.println(Array("tom","team","pom")
.filter(_.matches("")).toList)
输出结果为(List(tom,team)请填空
A.t[a-z]+m
B.t[a-z]m
C.la-z]+
D.t[a-z]{2}
答案:A
3.println(List("c","java","c","python").map(myf))
def myf(s:String):Map[String,Int]={
Map(s->s.length)
输出结果是(C)
A.Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6)
B.List(Map(c ->1),Map(java->1),Map(c ->1),Map(python ->1))
C.List(Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6))
D.Tuple4(Map(c ->1),Map(java ->4),Map(c->1),Map(python ->6))
4.println(Array("tom","jerry").filter().toList)
输出结果为List("jerry")
下列错误的是
A._.length>3
B._.startsWith("j")
C._≥7”
D._.endsWith("y")
5.println(List"信计-201,信计-202",大数据-201",大数据-202)
.groupBy(_.split("-")(0)))
输出结果是
A
Map(大数据->List(大数据-201,大数据-202),信计->List(信计-201,信计-202)
B
Map(大数据-20->List(大数据-201,大数据-202),信计-20->List(信计-201,信计-202)
C
Map(大数据-->List(大数据-201,大数据-202),信计-->List(信计-201,信计-202)
D
Map(大数据->List(201,202),信计->List(201,202)
6. (阅读理解, 25.0 分)资料--data--ajk_utf8.csv(utf-8编码)数据处理分析。
第一列是小区,第二列是地址,第三列是租金。
var rdd1=sc.textFile("d:/ajk/ajk_utf8.csv") //spark-core读取数据
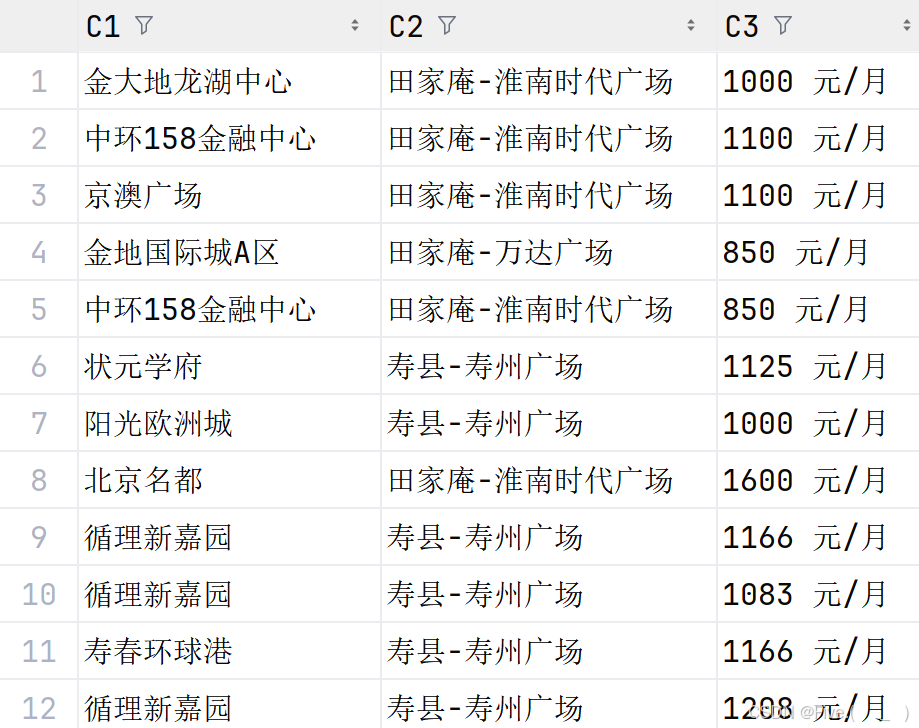
(1) (单选题)统计共有多少个小区?
A.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x->(x(2),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
B.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x<-(x(0),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
C.var rdd2=rdd1.map(_.split(" "))
var rdd3=rdd2.map(x=>(x(0),x(1)))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
D.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.groupByKey()
println(rdd4.count())
正确答案是:D
解释:
- 选项D正确地使用了第一列(小区名)作为key:
x(0) - 使用
groupByKey()来分组统计 - 最后使用
count()计算总数
其他选项的问题:
- A选项使用了第三列(租金)作为key:
x(2) - B选项使用了错误的语法:
x<-应该是x=> - C选项使用了空格分隔符:
split(" ")而不是逗号split(",")
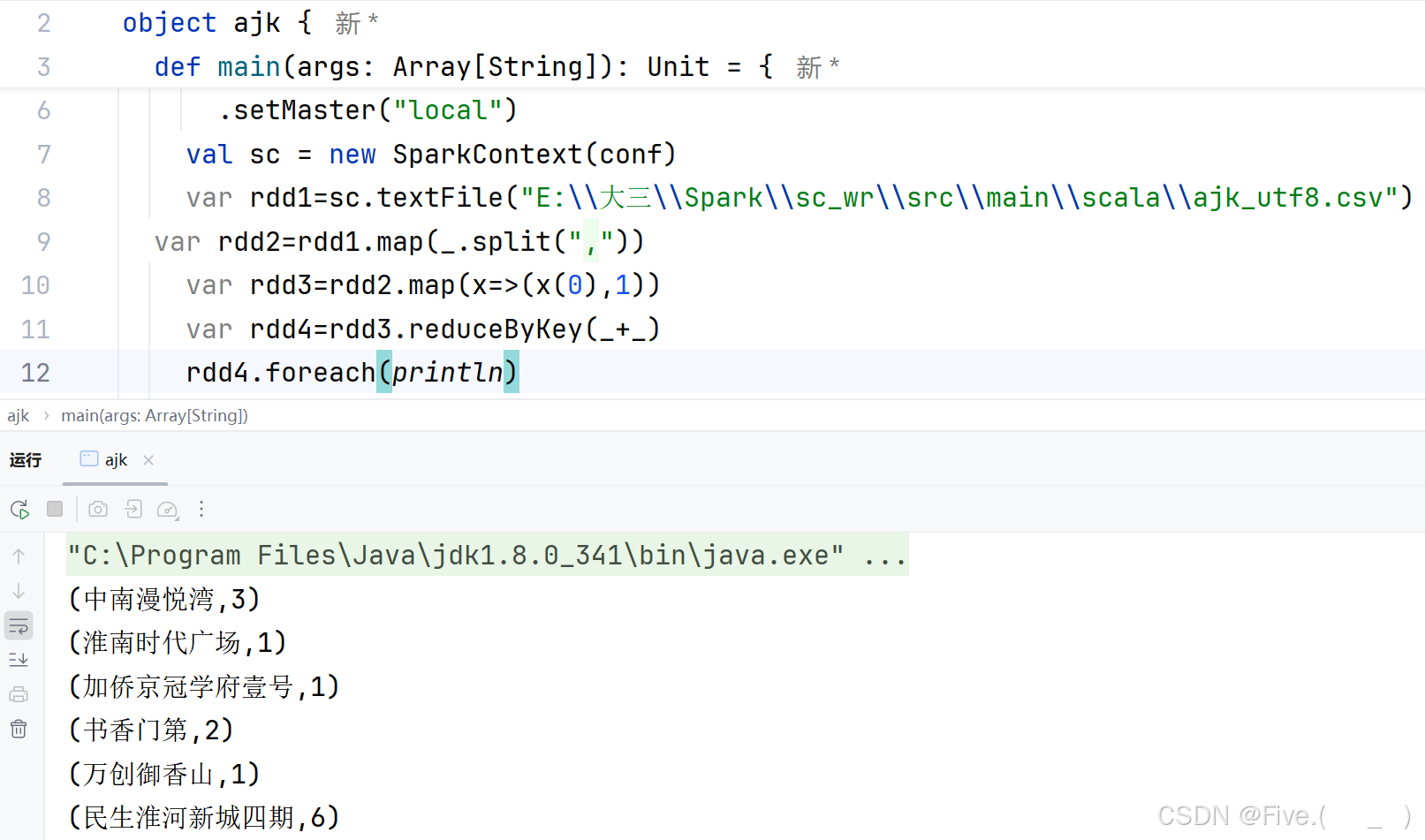
(2) (单选题)统计每个小区有多少房子出租?请选择
A var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(2),1))
var rdd4=rdd3.reduce(_+_)
rdd4.foreach(println)
B var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.reduce(_+_)
rdd4.foreach(println)
C var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
正确答案是:D
解释:
- 使用第一列(小区名)作为key:
x(0) - 使用
reduceByKey(_+_)来统计每个小区的房源数量 - 使用
foreach(println)打印结果
其他选项的问题:
- A选项使用了第三列(租金)作为key:
x(2) - B选项使用了
reduce而不是reduceByKey,这会导致所有数据被合并成一个值 - C选项使用了第二列(地址)作为key:
x(1)
(3) (单选题)统计不同区、县房源数量,请选择
A.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1).split("-")(0),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
B.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(2).split("-")(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
C.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(0).split("-")(1),1))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D.var rdd2=rdd1.map(_.split(","))
var rdd3=rdd2.map(x=>(x(1).split("-")(0),1))
var rdd4=rdd3.groupByKey()
rdd4.foreach(println)
正确答案是:A
解释:
- 从地址列(第二列)中提取区县信息:
x(1).split("-")(0) - 使用
reduceByKey(_+_)来统计每个区县的房源数量 - 使用
foreach(println)打印结果
其他选项的问题:
- B选项使用了第三列(租金)来提取区县信息:
x(2) - C选项使用了第一列(小区名)来提取区县信息:
x(0) - D选项虽然提取地址正确,但使用了
groupByKey()而不是reduceByKey(_+),这会导致结果是分组后的集合而不是计数
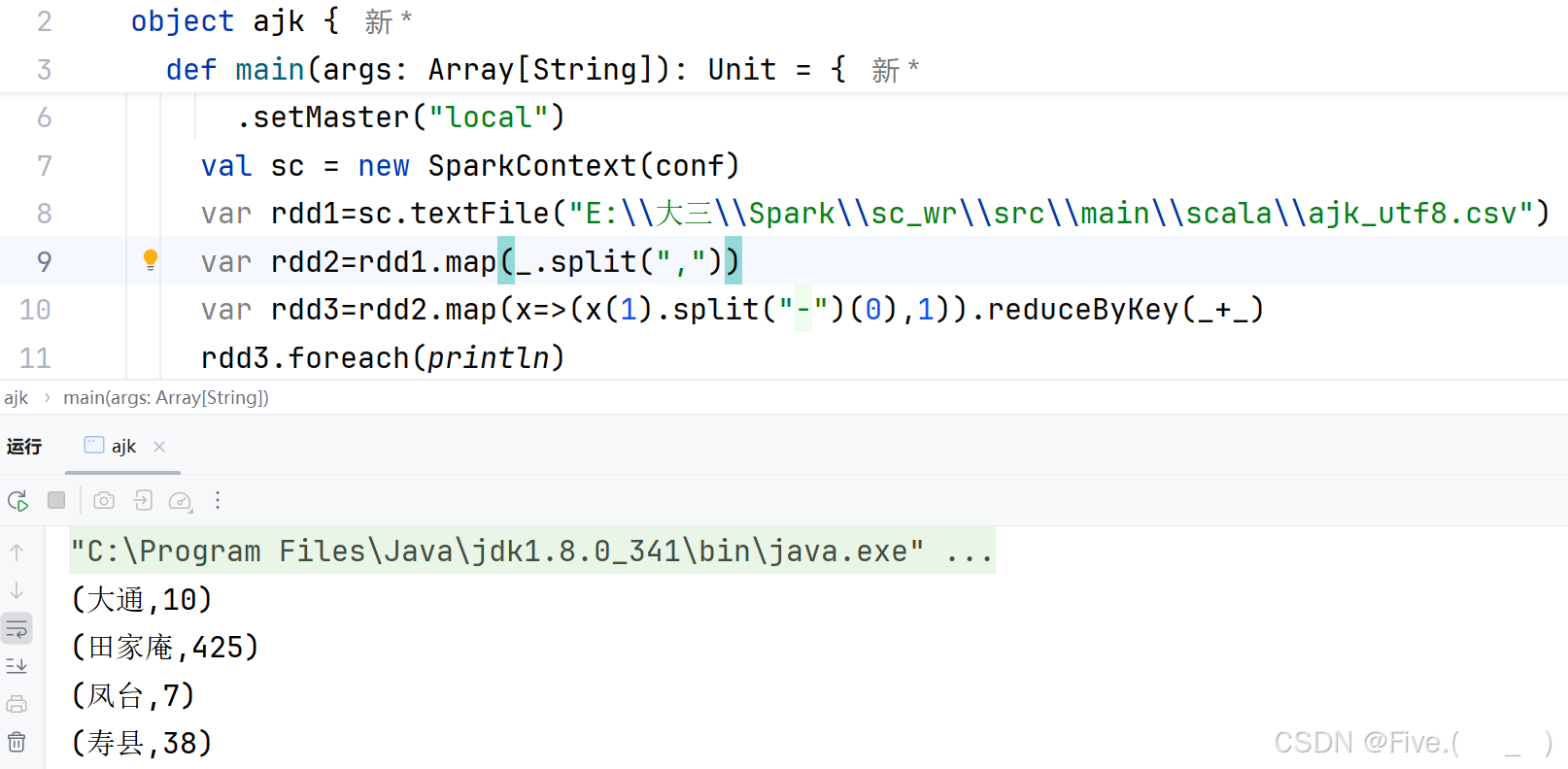
(4) (单选题)统计每个区、县的出租均价,请选择
A.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).toInt))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.sum/x._2.size)).foreach(println)
B.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(0).toInt))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.sum/x._2.size)).foreach(println)
C.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(0).toInt))
var rdd4=rdd3.reduceByKey(_+_)
rdd4.foreach(println)
D.var rdd3=rdd2.map(x=>(x(1).split("-")(0),x(2).split(" ")(1)))
//var rdd3=rdd2.map(x=>(x(0),1))
var rdd4=rdd3.groupByKey()
rdd4.map(x=>(x._1,x._2.avgvalue)).foreach(println)
正确答案是:B
解释:
- 从地址列(x(1))中提取区县信息:
x(1).split("-")(0) - 从租金列(x(2))中提取数字部分:
x(2).split(" ")(0).toInt - 使用
groupByKey()将相同区县的租金分组 - 计算平均值:
x._2.sum/x._2.size - 使用
foreach(println)打印结果
其他选项的问题:
- A选项直接将租金转为整数:
x(2).toInt,没有处理可能存在的单位(如"元") - C选项虽然处理了租金格式,但使用了
reduceByKey(_+)只计算总和,没有计算平均值 - D选项使用了错误的索引
split(" ")(1),并且avgvalue是不存在的方法
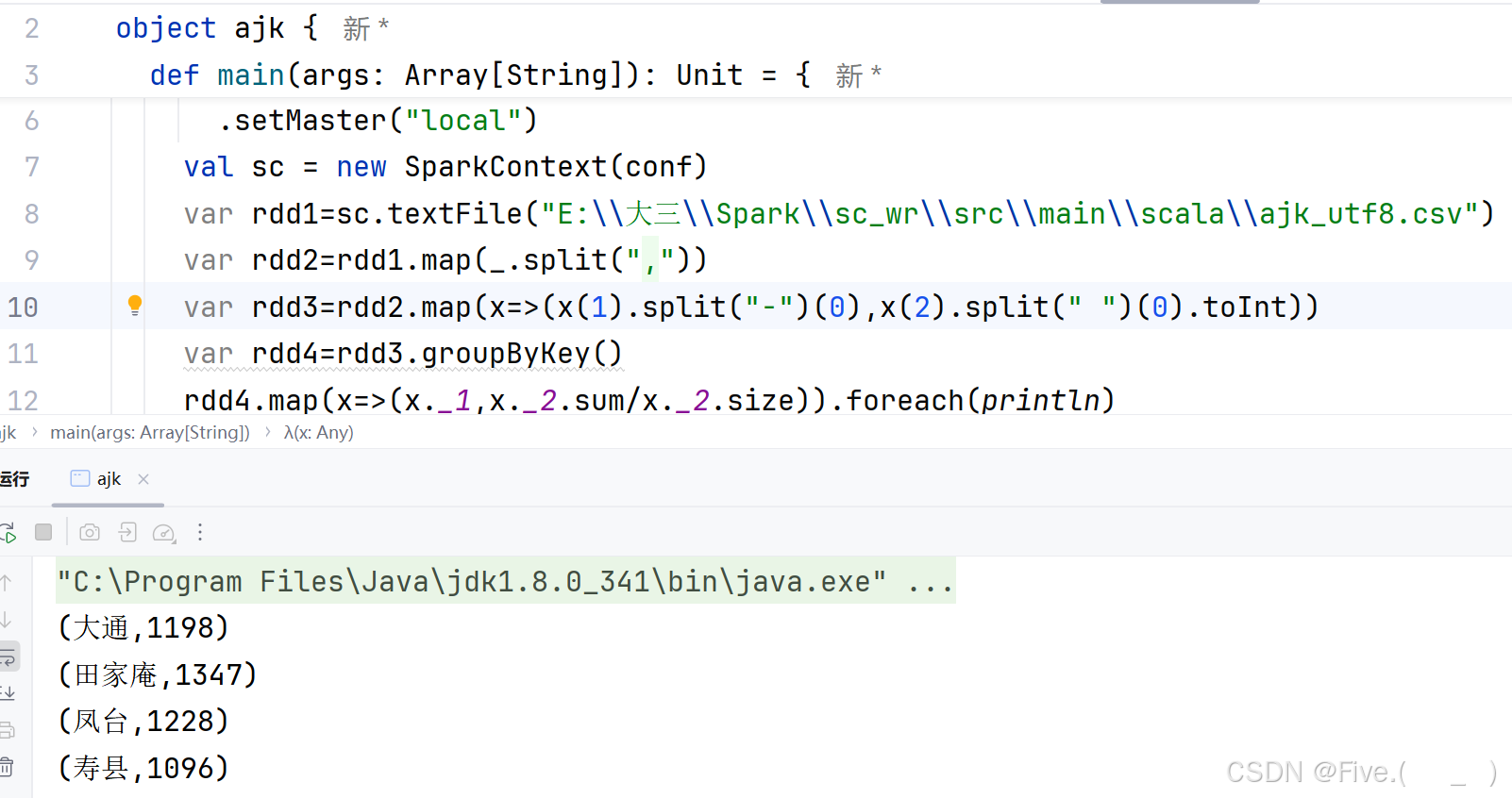
(5) (单选题)上一小题计算出各区县的出租均价是()
A.(大通,1198)
(田家庵,1347)
(凤台,1228)
(寿县,1096)
B.(大通,1098)
(田家庵,1347)
(凤台,1228)
(寿县,1016)
C.(大通,1198)
(田家庵,1447)
(凤台,1228)
(寿县,1196)
D.(大通,1298)
(田家庵,1447)
(凤台,1228)
(寿县,1026)
答案为A,运行结果看上方
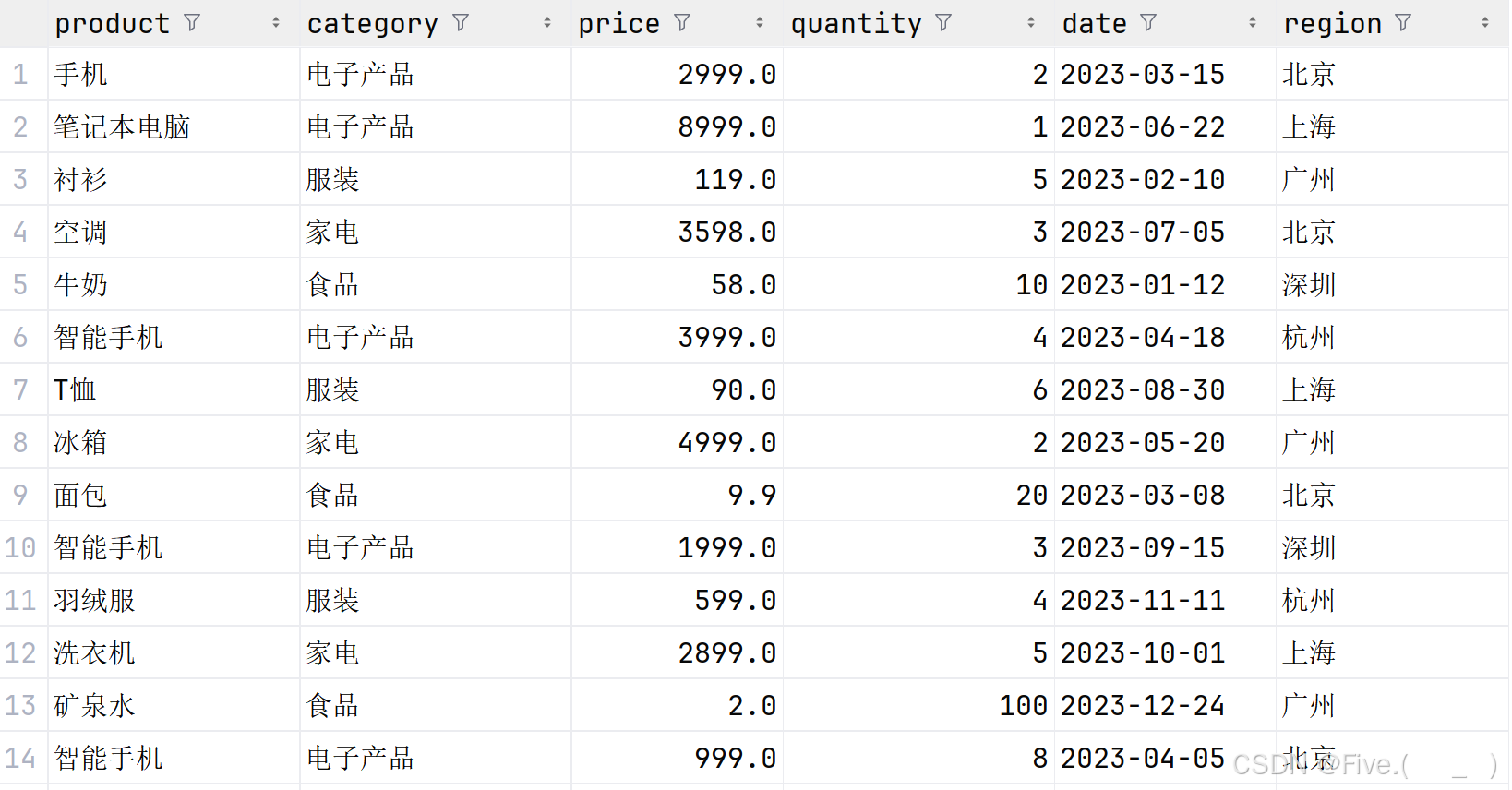
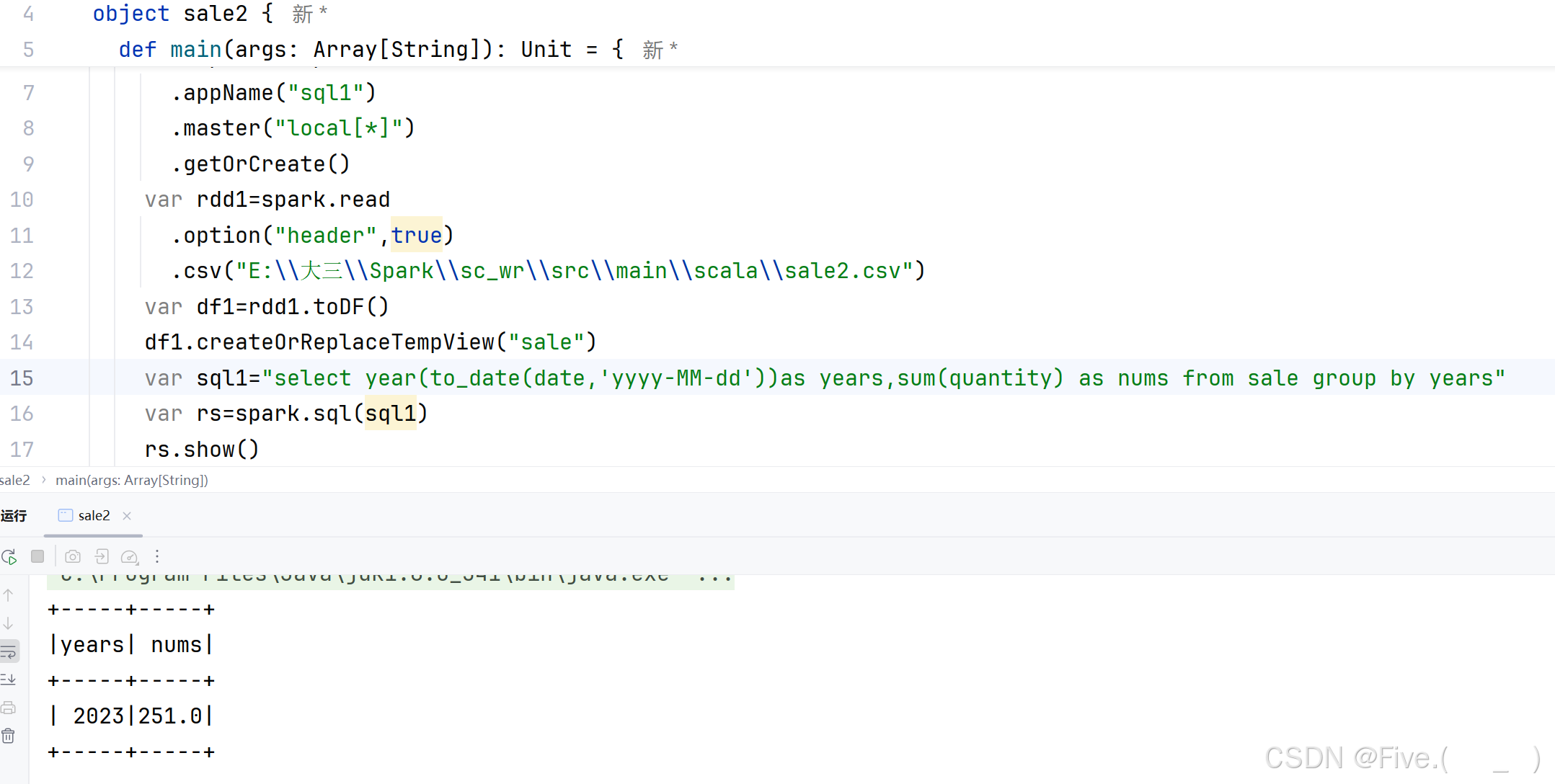
7. (阅读理解, 30.0 分)统计学习通--资料--data--sale2.csv.进行数据处理和分析。
var rdd1=spark.read
.option("header",true)
.csv("d:/sale2.csv")
var df1=rdd1.toDF()
df1.createOrReplaceTempView("sale")
var sql1=______________
var rs=spark.sql(sql1)
rs.show()
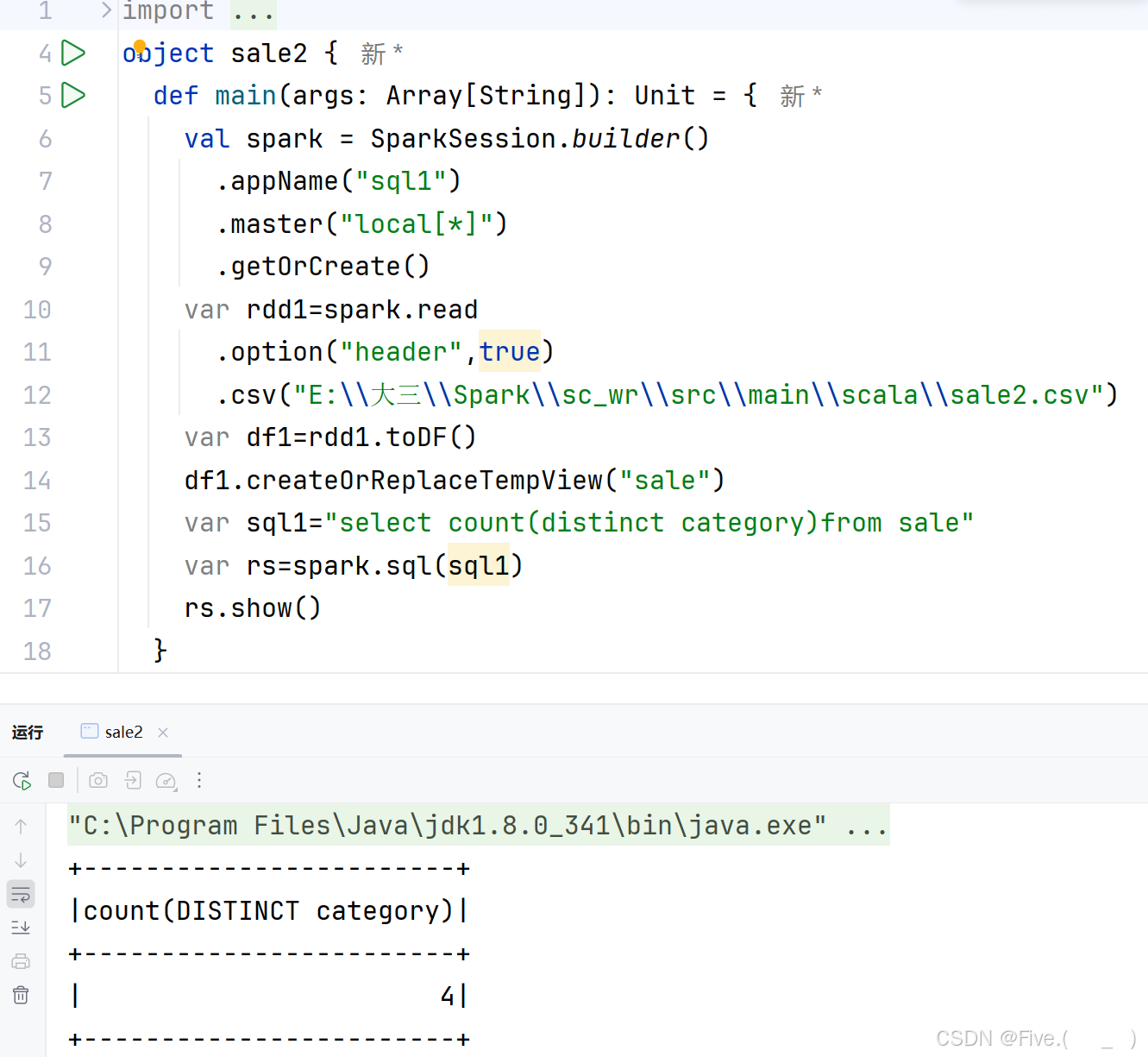
(1) (单选题)统计商品(product)有几个大类(category)。
A.select count(category) from sale
B.select count(distinct category) from sale
C.select sum(distinct category) from sale
D.select count(distinct product) from category
正确答案是:B
解释:
原因:
- 使用
distinct去重,统计唯一的大类 - 使用
count统计数量
其他选项的问题:
- A选项没有
distinct,会统计所有记录 - C选项使用
sum,对分类进行求和是错误的 - D选项语法错误,
category不是表名
(2) (单选题)统计在售商品销量。
A.select product,quantity from sale
B.select product,count(quantity) as salenum from sale group by product
C.select product,sum(product) as salenum from sale group by quantity
D.select product,sum(quantity) as salenum from sale group by product
正确答案是:D
解释:
原因:
- 使用
sum(quantity)计算每个商品的总销量 - 使用
group by product按商品分组 - 使用
as salenum给结果列命名
其他选项的问题:
- A选项只选择了商品和数量,没有聚合
- B选项使用
count,统计的是数量的记录数而不是总销量 - C选项
group by quantity是错误的分组方式,应该按商品分组
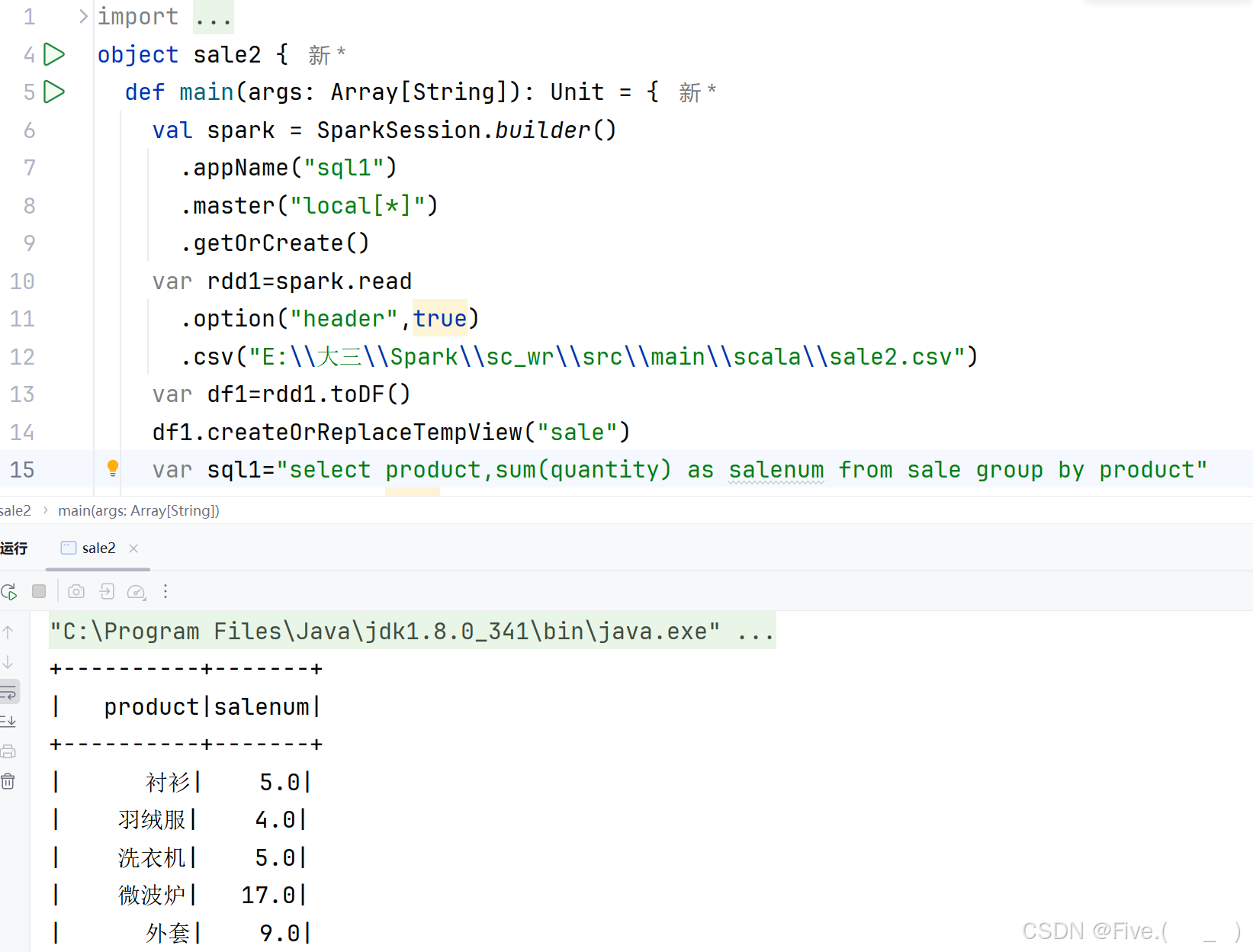
(3) (单选题)商品大类(category)销售数量排行,请选择
A.select category,count(quantity) as num_cate from sale group by category order by num_cate desc
B.select category,count(*) as num_cate from sale group by category order by num_cate
C.select category,sum(quantity) as num_cate from sale group by category order by num_cate desc
D.select category,sum(quantity) as num_cate from sale order by category group by num_cate desc
正确答案是:C
解释:
原因:
- 使用
sum(quantity)计算每个大类的总销量 - 使用
group by category按大类分组 - 使用
order by num_cate desc按销量降序排列 - 使用
as num_cate给结果列命名
其他选项的问题:
- A选项使用
count,统计的是数量的记录数而不是总销量 - B选项使用
count(*),统计的是记录数而不是销量 - D选项语法错误,
order by和group by的顺序错误
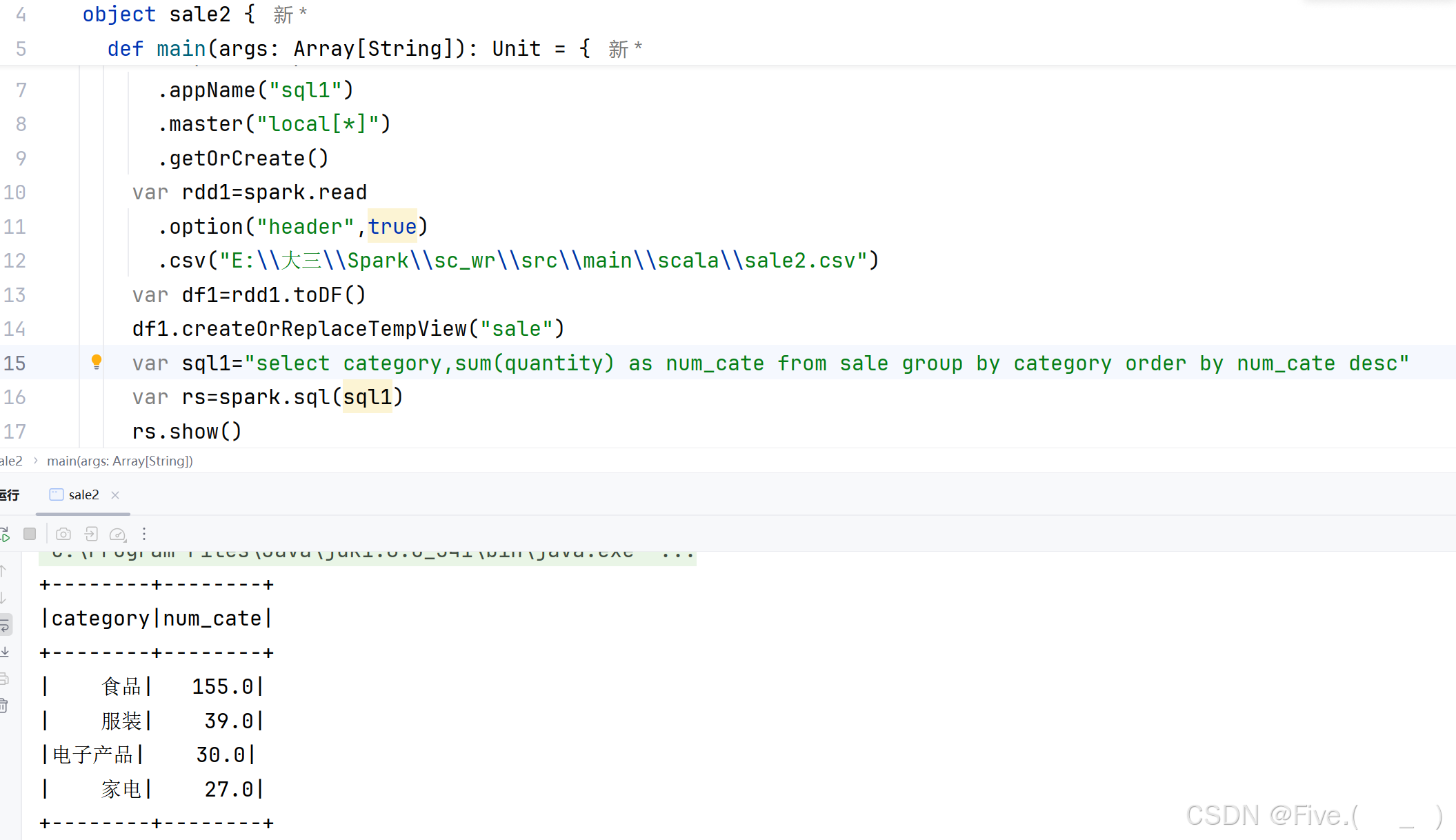
(4) (单选题)商品大类(category)营业金额,排行榜
A.select category,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
B.select quantity,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
C.select price,sum(price*quantity) as sum_cate from sale group by category order by sum_cate desc
D.select category,sum(price) as sum_cate from sale group by category order by sum_cate desc
正确答案是:A
解释:
原因:
- 使用
price*quantity计算每个商品的销售额 - 使用
sum计算每个大类的总销售额 - 使用
group by category按大类分组 - 使用
order by sum_cate desc按销售额降序排列 - 使用
as sum_cate给结果列命名
其他选项的问题:
- B选项使用
quantity分组,这是错误的,应该按category分组 - C选项使用
price分组,这是错误的,应该按category分组 - D选项只计算了价格总和,没有考虑数量,无法得到正确的销售额
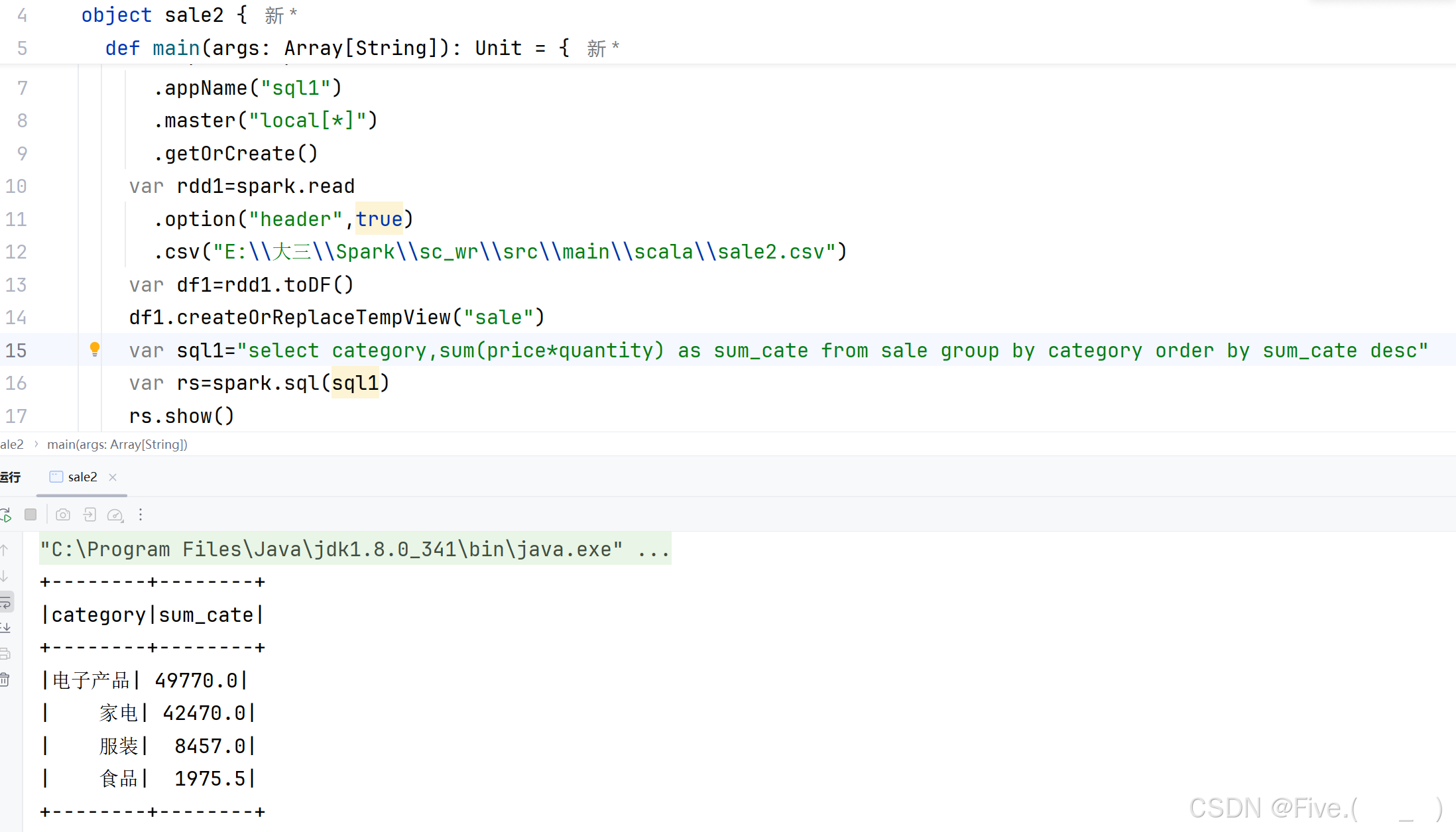
(5) (单选题)按季度顺序统计销售金额。
A var sql1="select quarter(to_date(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by quarters"
B var sql1="select quarter(to_date(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by sum_sale"
C var sql1="select quarter(to_timestamp(date,'yyyy-MM-dd'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by sum_sale desc"
D var sql1="select quarter(to_timestamp(date,'yyyy/MM/dd HH:mm:ss'))as quarters,sum(price*quantity)as sum_sale from sale group by quarters order by quarters"
正确答案是:A
解释:
原因:
- 使用
to_date将日期字符串转换为日期格式 - 使用
quarter函数提取季度 - 使用
sum(price*quantity)计算销售额 - 使用
group by quarters按季度分组 - 使用
order by quarters按季度顺序排序
其他选项的问题:
- B选项按销售额排序,不符合按季度顺序的要求
- C选项虽然按销售额降序排序,但不符合按季度顺序的要求
- D选项使用了错误的日期格式字符串
yyyy/MM/dd HH:mm:ss,而原始数据应该是yyyy-MM-dd格式
(6) (单选题)按年统计销售商品数量
A.var sql1="select year(to_date(date,'yyyy-MM-dd'))as years,sum(quantity) as nums from sale group by years"
B.var sql1="select month(to_date(date,'yyyy-MM-dd'))as years,sum(quantity) as nums from sale group by years"
C.var sql1="select year(to_date(date,'yyyy-MM'))as years,sum(quantity) as nums from sale group by nums"
D.var sql1="select year(to_date(date,'yyyy/MM'))as years,sum(quantity) as nums from sale group
正确答案是:A
解释:
原因:
- 使用
to_date将日期字符串转换为日期格式 - 使用
year函数提取年份 - 使用
sum(quantity)计算每年的销售数量 - 使用
group by years按年份分组
其他选项的问题:
- B选项使用
month提取月份,不符合按年统计的要求 - C选项按
nums分组,这是错误的,应该按years分组 - D选项缺少
by关键字,语法错误
8. (阅读理解, 20.0 分)读取学习通--资料--data--weather.csv
并进行数据处理与分析
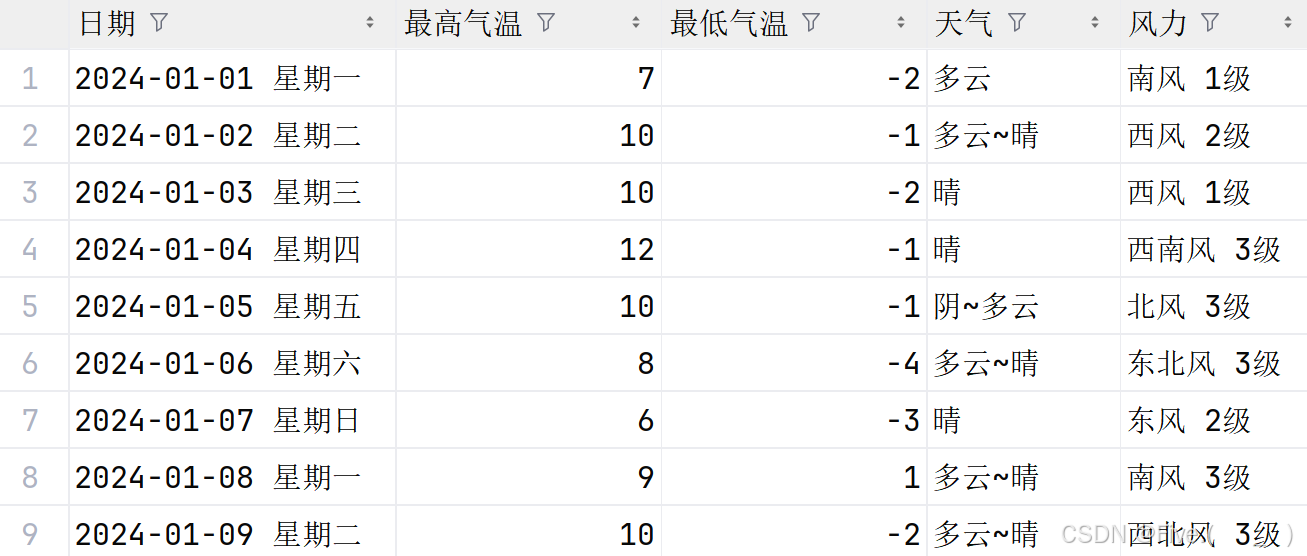
var rdd1=sc.textFile("d:/weather.csv")
var header=rdd1.first()
var data=rdd1.filter(_!=header)
var rdd2=data.map((_.split(",")))
(1) (单选题)统计出这一年中有多少雾霾天?
A.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.equals("雾霾"))
println(rdd3.count())
输出 结果:12
B.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.contains("雾霾"))
println(rdd3.count())
输出 结果:12
C.var rdd3=rdd2.map(x=>(x(3),1)).filter(_._1.contains("雾霾"))
println(rdd3.count())
输出 结果:11
D.var rdd3=rdd2.map(x=>(x(4),1)).filter(_._1.substring("雾霾"))
println(rdd3.count())
输出结果:11
正确答案:C
解释:
- 使用第四列(天气情况):
x(3) - 使用
contains("雾霾")来匹配包含"雾霾"的天气 - 最终统计结果是11天
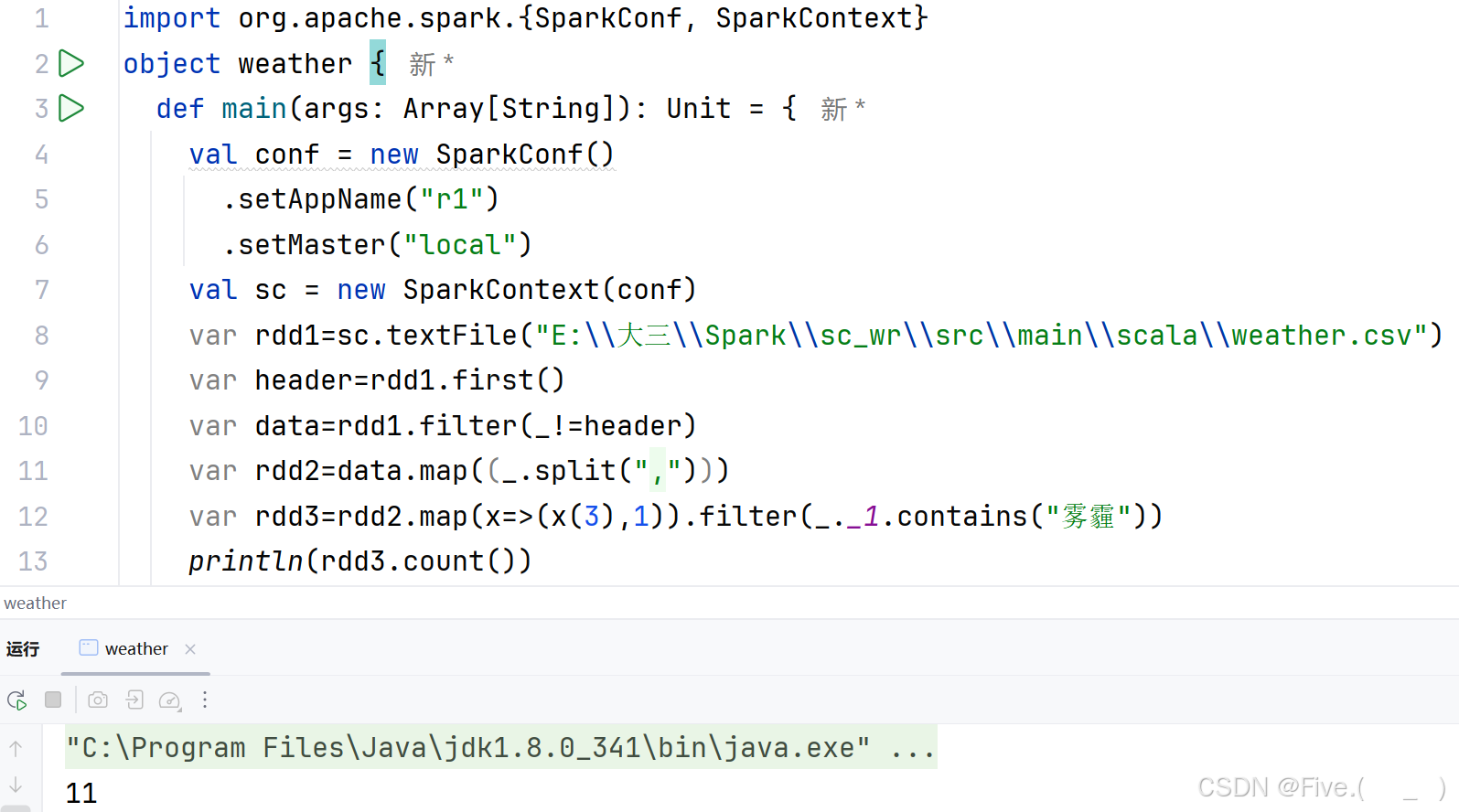
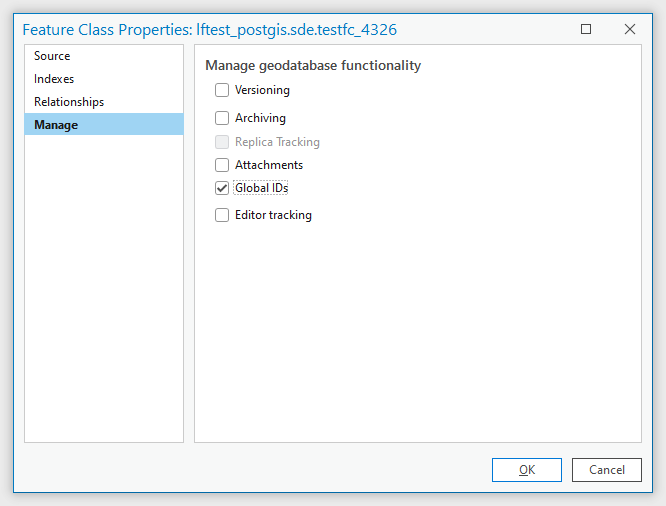
(2) (单选题)求出气温最低的10天。
A.var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortBy(_._2)
rdd3.take(10).foreach(println)
B.var rdd3=rdd2.map(x=>(x(0),x(2))).sortBy(_._2)
rdd3.take(10).foreach(println)
C.var rdd3=rdd2.map(x=>(x(0),x(1).toInt)).sortBy(_._2)
rdd3.take(10).foreach(println)
D.var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortByKey()
rdd3.take(10).foreach(println)
正确答案是:A
解释:
var rdd3=rdd2.map(x=>(x(0),x(2).toInt)).sortBy(_._2) rdd3.take(10).foreach(println)
原因:
- 使用
x(0)作为日期 - 使用
x(2)作为最低温度列 - 使用
toInt将温度转换为整数 - 使用
sortBy(_._2)按温度排序 - 使用
take(10)获取最低的10天
其他选项的问题:
- B选项没有转换温度为整数,字符串排序可能不正确
- C选项使用了
x(1),这是最高温度列而不是最低温度 - D选项使用了
sortByKey(),这会按日期排序而不是温度
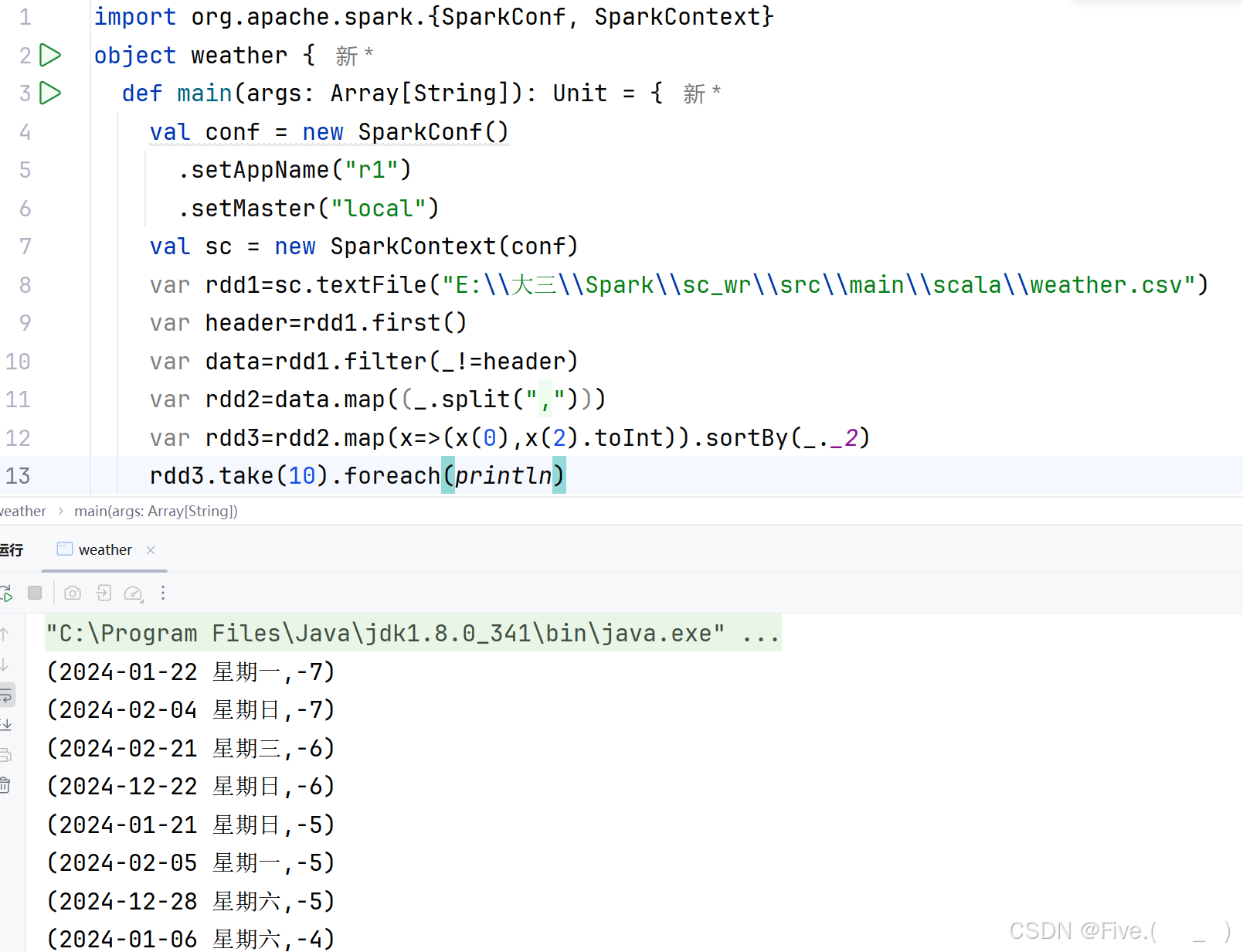
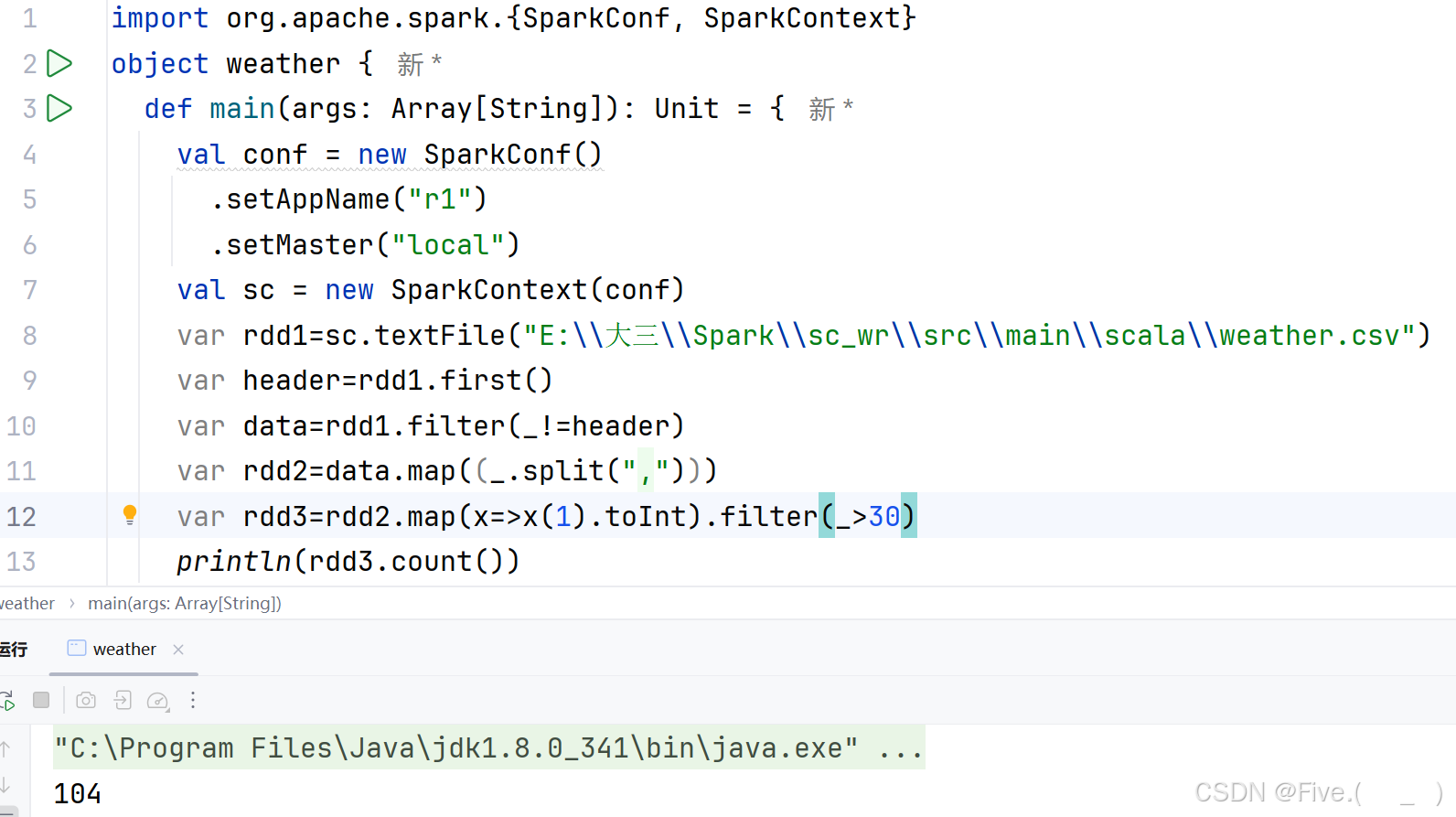
(3) (单选题)统计各种风向各多少天(例如:东风,20)
A.var rdd3=rdd2.map(x=>(x(4).split(" ")(0),1))
rdd3.groupByKey(_+_).foreach(println)
B.var rdd3=rdd2.map(x=>(x(4).split(" ")(0),1))
rdd3.reduceByKey(_+_).foreach(println)
C.var rdd3=rdd2.map(x=>(x(0),x(4).split(" ")(0)))
rdd3.reduceByKey(_+_).foreach(println)
D.var rdd3=rdd2.map(x=>(x(4),1))
rdd3.orderByKey(_+_).foreach(println)
正确答案是:B
解释:
- 使用
x(4)作为风向列 - 使用
split(" ")(0)提取风向(假设风向和风力是用空格分隔的) - 使用
reduceByKey(_+_)来统计每个风向出现的天数 - 使用
foreach(println)打印结果
其他选项的问题:
- A选项使用了
groupByKey(_+),语法错误,groupByKey后面不能直接加操作符 - C选项将日期作为key,映射关系错误
- D选项没有分割风向和风力,直接使用
x(4),并且使用了orderByKey,这是排序操作而不是统计
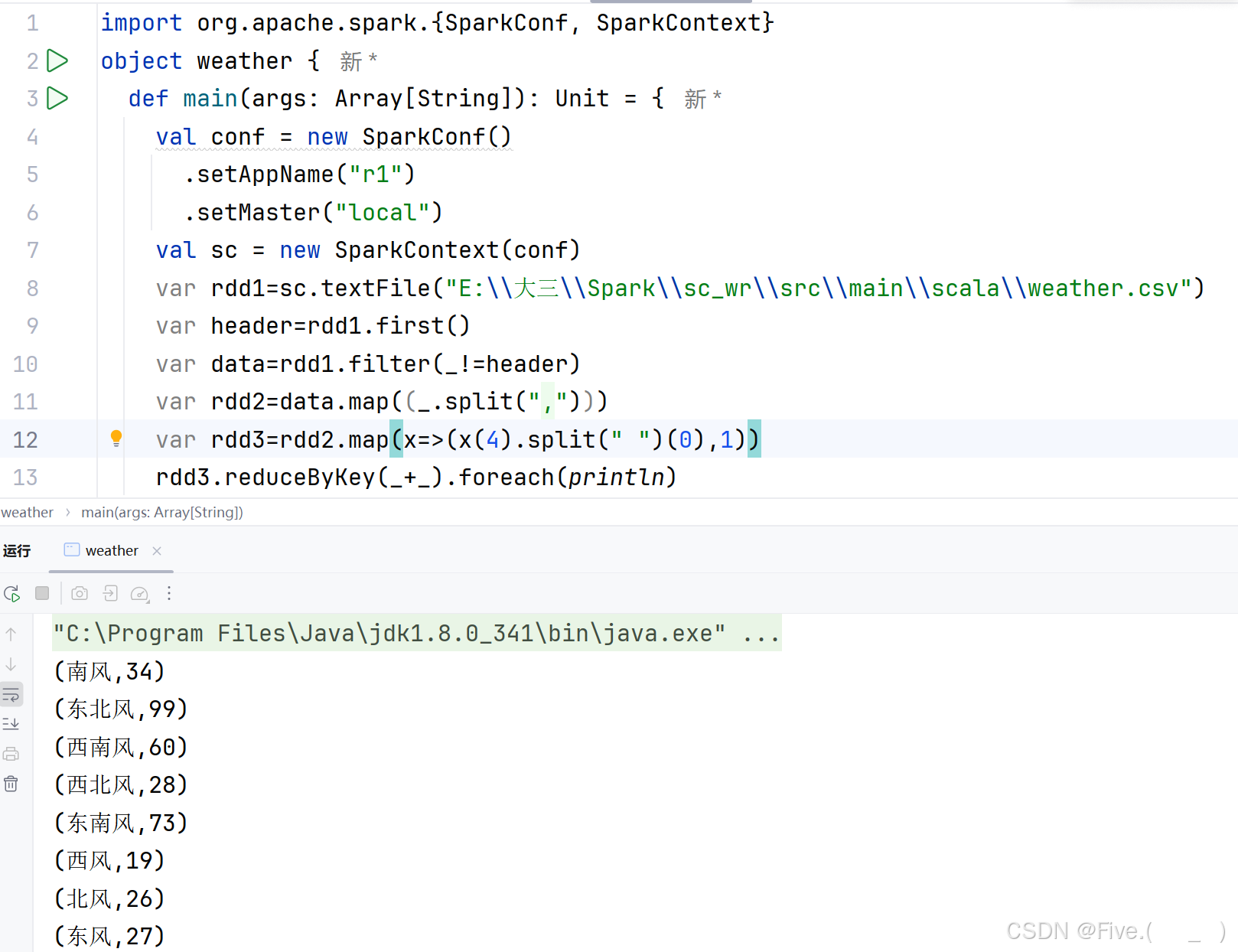
(4) (单选题)最高温度大于30的有多少天?
A.var rdd3=rdd2.map(x=>(x(1),1)).filter(_._1>30)
println(rdd3.count())
输出结果:105
B.var rdd3=rdd2.map(x=>x(1).toInt).filter(_>30)
println(rdd3.count())
输出结果:104
C.var rdd3=rdd2.map(x=>(x(1).toInt,1)).filter(_>30)
println(rdd3.count())
输出结果:105
D.var rdd3=rdd2.map(x=>(x(1).toInt,1)).reduce(_._1>30)
println(rdd3.count())
输出结果:104
正确答案是:B
解释:
原因:
- 直接映射温度列:
x(1) - 使用
toInt转换为整数 - 使用
filter(_>30)过滤大于30的温度 - 使用
count()统计结果
其他选项的问题:
- A选项没有转换温度为整数,直接比较字符串
- C选项虽然转换了温度,但过滤条件写错了,应该用
filter(_._1>30) - D选项使用了
reduce,语法错误,reduce用于聚合操作而不是过滤





![[蓝桥杯]模型染色](https://i-blog.csdnimg.cn/direct/c94cd8a9fe2f4a6da149d38c9e6767c5.png)