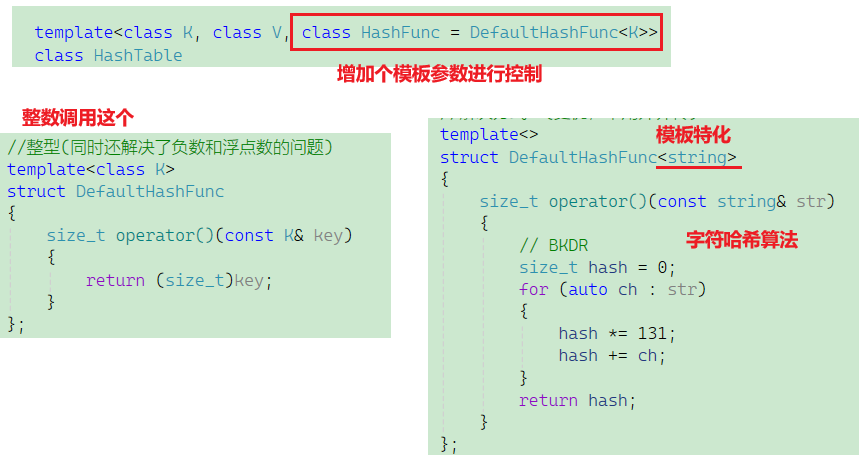
以下是针对爬虫工具链的详细分类解析,涵盖静态页面、动态渲染和框架开发三大场景的技术选型与核心特性:
🧩 一、静态页面抓取(HTML结构固定)
工具组合:Requests + BeautifulSoup
适用场景:目标数据直接存在于HTML源码中,无需执行JavaScript
import requests
from bs4 import BeautifulSoup
url = "http://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取标题(CSS选择器示例)
title = soup.select_one('h1.main-title').text
工具特点:
| 工具 | 角色 | 核心能力 |
|---|---|---|
| Requests | 网络请求库 | 发送HTTP请求,管理Cookies/Headers |
| BeautifulSoup | HTML解析库 | 支持XPath/CSS选择器,树状结构解析 |
优势:轻量级、学习成本低,适合90%的静态网站
局限:无法处理JavaScript动态生成的内容
🌐 二、动态页面抓取(需渲染JS)
工具组合:Selenium 或 Playwright
适用场景:数据通过Ajax/JS动态加载(如瀑布流、点击展开内容)
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://dynamic-site.com")
driver.implicitly_wait(5) # 等待JS执行
# 模拟点击“加载更多”按钮
button = driver.find_element_by_css_selector('.load-more')
button.click()
# 获取渲染后的HTML
html = driver.page_source
工具对比:
| 特性 | Selenium | Playwright (微软开源) |
|---|---|---|
| 浏览器支持 | Chrome/Firefox/Safari | 跨浏览器(Chromium/WebKit/Firefox) |
| 执行速度 | 较慢 | 快30%+(优化无头模式) |
| 自动化能力 | 基础交互 | 更强(自动等待元素/文件下载) |
| 代码示例 | find_element_by_xpath() | page.locator("text=Submit").click() |
关键技巧:
- 使用
WebDriverWait显式等待元素出现 - 设置无头模式节省资源:
options.add_argument("--headless")
🚀 三、框架级开发(大型爬虫项目)
工具:Scrapy(异步框架)
适用场景:分布式爬虫、数据清洗管道、自动规避反爬
import scrapy
class BookSpider(scrapy.Spider):
name = 'book_spider'
start_urls = ['http://books.toscrape.com']
def parse(self, response):
for book in response.css('article.product_pod'):
yield {
'title': book.css('h3 a::attr(title)').get(),
'price': book.css('p.price_color::text').get()[1:] # 清洗价格符号
}
# 自动处理分页
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
Scrapy核心组件:
| 组件 | 作用 |
|---|---|
| Spiders | 定义爬取逻辑(初始URL、数据解析规则) |
| Item Pipelines | 数据清洗/存储(如去重、保存到数据库) |
| Middlewares | 处理请求/响应(代理IP、User-Agent轮换) |
| Scheduler | 任务队列管理(优先级/去重调度) |
优势:
✅ 内置并发控制(异步IO)
✅ 自动遵循robots.txt
✅ 扩展性强(支持Redis分布式爬虫)
🔧 四、场景化工具选择指南
| 需求场景 | 推荐工具 | 原因 |
|---|---|---|
| 快速抓取静态表格 | Requests + Pandas(pd.read_html) | 1行代码解析HTML表格 |
| 模拟登录复杂网站 | Selenium + Browser Cookie | 可视化操作绕过验证码 |
| 海量数据分布式采集 | Scrapy + Scrapy-Redis | 支持集群部署,千万级数据吞吐 |
| 逆向JavaScript加密接口 | Playwright + Pyppeteer | 拦截网络请求,直接获取API数据 |
避坑提示:
- 动态页面优先尝试直接调用隐藏API(通过浏览器开发者工具抓XHR请求)
- 反爬严格时,在Scrapy中集成
scrapy-splash或scrapy-playwright组件- 遵守道德规范:添加
DOWNLOAD_DELAY(如2秒/请求),避免拖垮目标服务器
掌握这三类工具链,可应对从简单数据采集到企业级爬虫系统的全场景需求。