1. 引言
1.1 研究背景与意义
随着互联网的快速发展,网络上的数据量呈爆炸式增长。爬虫作为一种自动获取网络信息的工具,在数据挖掘、信息检索、舆情分析等领域有着广泛的应用。传统的同步爬虫在面对大量 URL 时效率低下,无法充分利用现代计算机的多核资源和网络带宽。而异步编程模型能够在不创建大量线程的情况下处理大量并发请求,显著提高爬虫的性能。
1.2 研究目标
本文的研究目标是设计并实现一个基于 Aiohttp 的高性能异步爬虫系统,该系统应具备以下特点:
- 高并发处理能力,能够高效处理大量 URL 请求
- 模块化设计,便于功能扩展和维护
- 灵活的策略配置,支持自定义过滤规则
- 完善的异常处理和日志记录机制
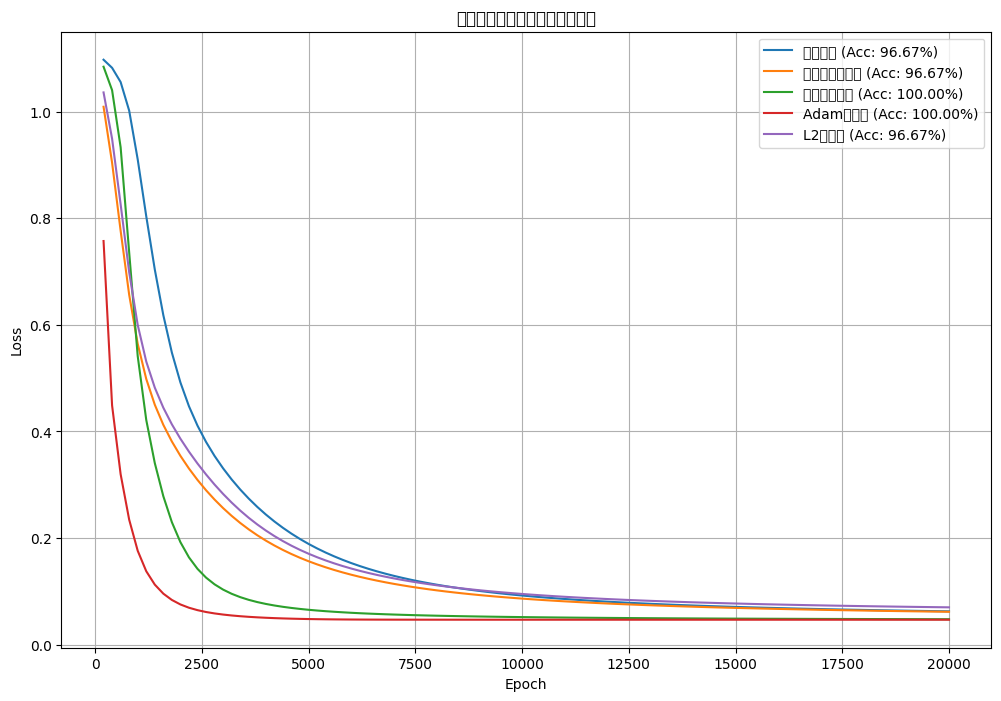
![[神经网络]使用olivettiface数据集进行训练并优化,观察对比loss结果](https://i-blog.csdnimg.cn/direct/d3f9b3ecf99f4846a6417d79091f3908.png#pic_center)