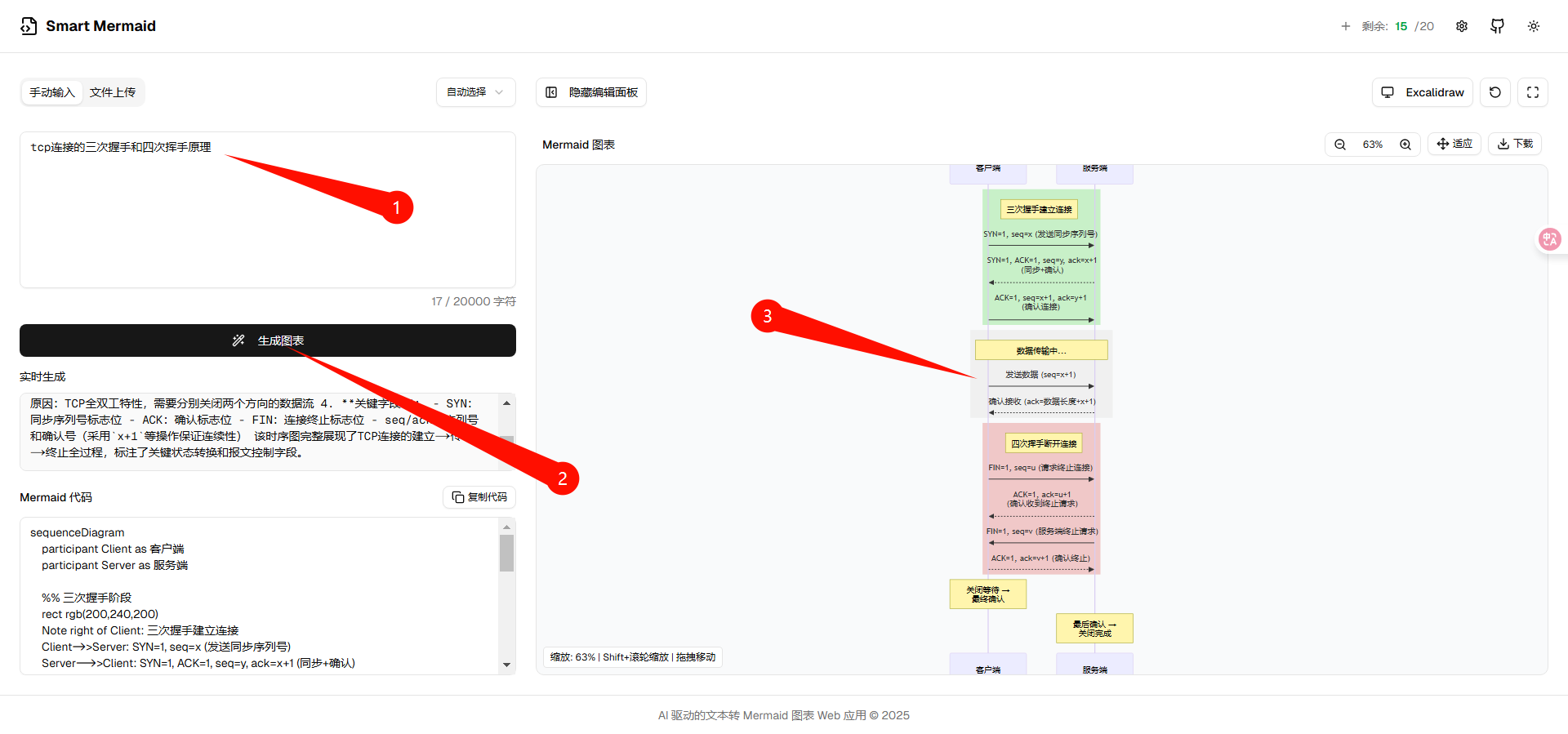
TensorFlow深度学习实战(19)——受限玻尔兹曼机
- 0. 前言
- 1. 受限玻尔兹曼机
- 1.1 受限玻尔兹曼机架构
- 1.2 受限玻尔兹曼机的数学原理
- 2. 使用受限玻尔兹曼机重建图像
- 3. 深度信念网络
- 小结
- 系列链接
0. 前言
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种无监督学习的概率图模型,用于学习数据的特征表示。它是由两层神经元组成的网络,其中一层是可见层 (visible layer),用于表示输入数据;另一层是隐层 (hidden layer),用于捕捉数据的潜在特征,而深度信念网络是堆叠的 RBM。本节中,将介绍 RBM 的基本原理,并使用 TensorFlow 实现 RBM 和深度信念网络用于重建图像。
1. 受限玻尔兹曼机
1.1 受限玻尔兹曼机架构
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种双层神经网络,一层称为可见层 (visible layer),另一层称为隐层 (hidden layer)。因为只有两层,因此称为浅层神经网络。RBM 最早由 Paul Smolensky 于 1986 年提出,后来由 Geoffrey Hinton 在 2006 年提出使用对比散度 (Contrastive Divergence, CD) 作为训练方法。所有可见层的神经元(称为可见单元,visible unit )都与隐层的所有神经元(称为隐单元,hidden unit )连接,但有一个限制——同一层中的神经元之间不能连接。RBM 中的所有神经元本质上都是二进制的,要么激活,要么不激活。
RBM 可以用于降维、特征提取和协同过滤。RBM 的训练可以分为三个部分:前向传递 (forward pass)、反向传递 (backward pass) 以及比较 (comparison)。
1.2 受限玻尔兹曼机的数学原理
接下来,我们从数学原理方面介绍 RBM,将 RBM 的操作分为两个过程:
前向传递: 可见单元
V
V
V 的信息通过权重
W
W
W 和偏置
c
c
c 传递到隐单元
h
0
h_0
h0。隐单元可能会激活或不激活,这取决于随机概率
σ
\sigma
σ,通常使用 sigmoid 函数:
ρ
(
v
0
∣
h
0
)
=
σ
(
V
T
W
+
c
)
\rho (v_0|h_0)=\sigma(V^TW+c)
ρ(v0∣h0)=σ(VTW+c)
反向传递: 隐单元的表示
h
0
h_0
h0 通过相同的权重
W
W
W,但使用不同的偏置
c
c
c,传递回可见单元,从而模型重建输入。同样,取决于随机概率
σ
\sigma
σ:
ρ
(
v
i
∣
h
0
)
=
σ
(
V
T
h
0
+
c
)
\rho(v_i|h_0)=\sigma(V^Th_0+c)
ρ(vi∣h0)=σ(VTh0+c)
重复执行以上两个过程
k
k
k 次,或者直到收敛。根据研究,
k
=
1
k=1
k=1 可以得到良好的结果,因此本节将
k
k
k 设置为
1
1
1。
可见向量
V
V
V 和隐向量
h
h
h 的联合能量表示如下:
E
(
v
,
h
)
=
−
b
T
V
−
c
T
h
−
V
T
W
h
E(v,h)=-b^TV-c^Th-V^TWh
E(v,h)=−bTV−cTh−VTWh
每个可见向量
V
V
V 还关联有自由能量:
F
(
v
)
=
−
b
T
V
−
∑
j
∈
h
i
d
d
e
n
l
o
g
(
1
+
e
x
p
(
c
j
+
V
T
W
)
)
F(v)=-b^TV-\sum_{j\in hidden}log(1+exp(c_j+V^TW))
F(v)=−bTV−j∈hidden∑log(1+exp(cj+VTW))
使用对比散度目标函数,即
M
e
a
n
(
F
(
V
o
r
i
g
i
n
a
l
)
)
−
M
e
a
n
(
F
(
V
r
e
c
o
n
s
t
r
u
c
t
e
d
)
)
Mean(F(V_{original})) - Mean(F(V_{reconstructed}))
Mean(F(Voriginal))−Mean(F(Vreconstructed)),权重的变化由下式表示:
d
W
=
η
[
(
V
T
h
)
i
n
p
u
t
−
(
V
T
h
)
r
e
c
o
n
s
t
r
u
c
t
e
d
]
dW=\eta[(V^Th)_{input}-(V^Th)_{reconstructed}]
dW=η[(VTh)input−(VTh)reconstructed]
其中,
η
\eta
η 是学习率,偏置
b
b
b 和
c
c
c 变化的表达式与此类似。
2. 使用受限玻尔兹曼机重建图像
接下来,使用 TensorFlow 构建一个受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 模型,用于重建 MNIST 手写数字图像。
(1) 导入 TensorFlow、NumPy 和 Matplotlib 库:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
(2) 定义 RBM 类。RBM 类的 __init__() 函数初始化可见层的神经元数量 input_size 和隐层的神经元数量 output_size,初始化隐层和可见层的权重和偏置,本节中将它们初始化为零。也可以尝试随机初始化:
#Class that defines the behavior of the RBM
class RBM(object):
def __init__(self, input_size, output_size, lr=1.0, batchsize=100):
"""
m: Number of neurons in visible layer
n: number of neurons in hidden layer
"""
#Defining the hyperparameters
self._input_size = input_size #Size of Visible
self._output_size = output_size #Size of outp
self.learning_rate = lr #The step used in gradient descent
self.batchsize = batchsize #The size of how much data will be used for training per sub iteration
#Initializing weights and biases as matrices full of zeroes
self.w = tf.zeros([input_size, output_size], np.float32) #Creates and initializes the weights with 0
self.hb = tf.zeros([output_size], np.float32) #Creates and initializes the hidden biases with 0
self.vb = tf.zeros([input_size], np.float32) #Creates and initializes the visible biases with 0
定义前向和反向传递方法:
#Forward Pass
def prob_h_given_v(self, visible, w, hb):
#Sigmoid
return tf.nn.sigmoid(tf.matmul(visible, w) + hb)
#Backward Pass
def prob_v_given_h(self, hidden, w, vb):
return tf.nn.sigmoid(tf.matmul(hidden, tf.transpose(w)) + vb)
创建生成随机二进制值的函数。这是因为隐层和可见层的单元更新是使用随机概率的,这取决于每个单元的输入(对于隐层)以及从上到下的反向输入(对于可见层):
#Generate the sample probability
def sample_prob(self, probs):
return tf.nn.relu(tf.sign(probs - tf.random.uniform(tf.shape(probs))))
定义函数重建输入数据:
def rbm_reconstruct(self,X):
h = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)
reconstruct = tf.nn.sigmoid(tf.matmul(h, tf.transpose(self.w)) + self.vb)
return reconstruct
定义 train() 函数用于训练 RBM。该函数计算对比散度的正梯度和负梯度,并使用权重更新公式来更新权重和偏置:
#Training method for the model
def train(self, X, epochs=10):
loss = []
for epoch in range(epochs):
#For each step/batch
for start, end in zip(range(0, len(X), self.batchsize),range(self.batchsize,len(X), self.batchsize)):
batch = X[start:end]
#Initialize with sample probabilities
h0 = self.sample_prob(self.prob_h_given_v(batch, self.w, self.hb))
v1 = self.sample_prob(self.prob_v_given_h(h0, self.w, self.vb))
h1 = self.prob_h_given_v(v1, self.w, self.hb)
#Create the Gradients
positive_grad = tf.matmul(tf.transpose(batch), h0)
negative_grad = tf.matmul(tf.transpose(v1), h1)
#Update learning rates
self.w = self.w + self.learning_rate *(positive_grad - negative_grad) / tf.dtypes.cast(tf.shape(batch)[0],tf.float32)
self.vb = self.vb + self.learning_rate * tf.reduce_mean(batch - v1, 0)
self.hb = self.hb + self.learning_rate * tf.reduce_mean(h0 - h1, 0)
#Find the error rate
err = tf.reduce_mean(tf.square(batch - v1))
print ('Epoch: %d' % epoch,'reconstruction error: %f' % err)
loss.append(err)
return loss
(3) 实例化一个 RBM 对象并在 MNIST 数据集上进行训练:
(train_data, _), (test_data, _) = tf.keras.datasets.mnist.load_data()
train_data = train_data/np.float32(255)
train_data = np.reshape(train_data, (train_data.shape[0], 784))
test_data = test_data/np.float32(255)
test_data = np.reshape(test_data, (test_data.shape[0], 784))
#Size of inputs is the number of inputs in the training set
input_size = train_data.shape[1]
rbm = RBM(input_size, 200)
err = rbm.train(train_data,50)
(4) 绘制学习曲线:
plt.plot(err)
plt.xlabel('epochs')
plt.ylabel('cost')
plt.show()

(5) 可视化重建图像:
out = rbm.rbm_reconstruct(test_data)
# Plotting original and reconstructed images
row, col = 2, 8
idx = np.random.randint(0, 100, row * col // 2)
f, axarr = plt.subplots(row, col, sharex=True, sharey=True, figsize=(20,4))
for fig, row in zip([test_data,out], axarr):
for i,ax in zip(idx,row):
ax.imshow(tf.reshape(fig[i],[28, 28]), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
重建图像如下所示:

第一行是输入的手写图像,第二行是重建的图像,可以看到这些图像与人类手写的数字非常相似。
3. 深度信念网络
我们已经了解了受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM),并知道如何使用对比散度进行训练,接下来,我们将介绍第一个成功的深度神经网络架构——深度信念网络 (Deep Belief Network, DBN)。DBN 架构在 2006 年由 Hinton 提出,在此模型之前,训练深度架构非常困难,不仅是由于计算资源有限,还因为梯度消失问题。在 DBN 中首次展示了如何通过贪婪的逐层训练来训练深度架构。
简单来说,DBN 只是堆叠的 RBM,每个 RBM 都使用对比散度单独训练。从训练第一个 RBM 层开始,训练完成后,训练第二个 RBM 层。第二个 RBM 的可见单元接收第一个 RBM 隐单元的输出作为输入数据。每次添加 RBM 层时重复以上过程。
(1) 堆叠 RBM 类。为了构建 DBN,需要在 RBM 类中定义一个额外的函数 rbm_output(),用于将前一 RBM 隐单元的输出传递到下一个 RBM 中:
class RBM(object):
def __init__(self, input_size, output_size, lr=1.0, batchsize=100):
"""
m: Number of neurons in visible layer
n: number of neurons in hidden layer
"""
#Defining the hyperparameters
self._input_size = input_size #Size of Visible
self._output_size = output_size #Size of outp
self.learning_rate = lr #The step used in gradient descent
self.batchsize = batchsize #The size of how much data will be used for training per sub iteration
#Initializing weights and biases as matrices full of zeroes
self.w = tf.zeros([input_size, output_size], np.float32) #Creates and initializes the weights with 0
self.hb = tf.zeros([output_size], np.float32) #Creates and initializes the hidden biases with 0
self.vb = tf.zeros([input_size], np.float32) #Creates and initializes the visible biases with 0
#Forward Pass
def prob_h_given_v(self, visible, w, hb):
#Sigmoid
return tf.nn.sigmoid(tf.matmul(visible, w) + hb)
#Backward Pass
def prob_v_given_h(self, hidden, w, vb):
return tf.nn.sigmoid(tf.matmul(hidden, tf.transpose(w)) + vb)
#Generate the sample probability
def sample_prob(self, probs):
return tf.nn.relu(tf.sign(probs - tf.random.uniform(tf.shape(probs))))
#Training method for the model
def train(self, X, epochs=10):
loss = []
for epoch in range(epochs):
#For each step/batch
for start, end in zip(range(0, len(X), self.batchsize),range(self.batchsize,len(X), self.batchsize)):
batch = X[start:end]
#Initialize with sample probabilities
h0 = self.sample_prob(self.prob_h_given_v(batch, self.w, self.hb))
v1 = self.sample_prob(self.prob_v_given_h(h0, self.w, self.vb))
h1 = self.prob_h_given_v(v1, self.w, self.hb)
#Create the Gradients
positive_grad = tf.matmul(tf.transpose(batch), h0)
negative_grad = tf.matmul(tf.transpose(v1), h1)
#Update learning rates
self.w = self.w + self.learning_rate *(positive_grad - negative_grad) / tf.dtypes.cast(tf.shape(batch)[0],tf.float32)
self.vb = self.vb + self.learning_rate * tf.reduce_mean(batch - v1, 0)
self.hb = self.hb + self.learning_rate * tf.reduce_mean(h0 - h1, 0)
#Find the error rate
err = tf.reduce_mean(tf.square(batch - v1))
print ('Epoch: %d' % epoch,'reconstruction error: %f' % err)
loss.append(err)
return loss
#Create expected output for our DBN
def rbm_output(self, X):
out = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)
return out
def rbm_reconstruct(self,X):
h = tf.nn.sigmoid(tf.matmul(X, self.w) + self.hb)
reconstruct = tf.nn.sigmoid(tf.matmul(h, tf.transpose(self.w)) + self.vb)
return reconstruct
(2) 使用 RBM 类创建一个堆叠的 RBM 结构,第一个 RBM 有 500 个隐单元,第二个有 200 个隐单元,第三个有 50 个隐单元:
RBM_hidden_sizes = [500, 200 , 50 ] #create 2 layers of RBM with size 400 and 100
#Since we are training, set input as training data
inpX = train_data
#Create list to hold our RBMs
rbm_list = []
#Size of inputs is the number of inputs in the training set
input_size = train_data.shape[1]
#For each RBM we want to generate
for i, size in enumerate(RBM_hidden_sizes):
print ('RBM: ',i,' ',input_size,'->', size)
rbm_list.append(RBM(input_size, size))
input_size = size
"""
RBM: 0 784 -> 500
RBM: 1 500 -> 200
RBM: 2 200 -> 50
"""
(3) 对于第一个 RBM,MNIST 数据作为输入。第一个 RBM 的输出作为输入传递到第二个 RBM,以此类推,通过连续的 RBM 层:
#For each RBM in our list
for rbm in rbm_list:
print ('Next RBM:')
#Train a new one
rbm.train(tf.cast(inpX,tf.float32))
#Return the output layer
inpX = rbm.rbm_output(inpX)
out = rbm_list[0].rbm_reconstruct(test_data)
# Plotting original and reconstructed images
row, col = 2, 8
idx = np.random.randint(0, 100, row * col // 2)
f, axarr = plt.subplots(row, col, sharex=True, sharey=True, figsize=(20,4))
for fig, row in zip([test_data,out], axarr):
for i,ax in zip(idx,row):
ax.imshow(tf.reshape(fig[i],[28, 28]), cmap='Greys_r')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
本节中,这三个堆叠的受限玻尔兹曼机以无监督学习方式进行训练。DBN 还可以通过监督学习进行训练,为此,需要对训练好的 RBM 的权重进行微调,并在最后添加一个全连接层。
小结
受限玻尔兹曼机 (Restricted Boltzmann Machine, RBM) 是一种强大的无监督学习模型,可以用于特征学习、数据降维、图像生成等任务。尽管其训练过程复杂且计算开销较大,但它为深度学习的发展奠定了基础,如深度信念网络 (Deep Belief Network, DBN)。
系列链接
TensorFlow深度学习实战(1)——神经网络与模型训练过程详解
TensorFlow深度学习实战(2)——使用TensorFlow构建神经网络
TensorFlow深度学习实战(3)——深度学习中常用激活函数详解
TensorFlow深度学习实战(4)——正则化技术详解
TensorFlow深度学习实战(5)——神经网络性能优化技术详解
TensorFlow深度学习实战(6)——回归分析详解
TensorFlow深度学习实战(7)——分类任务详解
TensorFlow深度学习实战(8)——卷积神经网络
TensorFlow深度学习实战(9)——构建VGG模型实现图像分类
TensorFlow深度学习实战(10)——迁移学习详解
TensorFlow深度学习实战(11)——风格迁移详解
TensorFlow深度学习实战(12)——词嵌入技术详解
TensorFlow深度学习实战(13)——神经嵌入详解
TensorFlow深度学习实战(14)——循环神经网络详解
TensorFlow深度学习实战(15)——编码器-解码器架构
TensorFlow深度学习实战(16)——注意力机制详解
TensorFlow深度学习实战(17)——主成分分析详解
TensorFlow深度学习实战(18)——K-means 聚类详解