背景需求:
今天春游,上海海昌公园。路上保健老师收到前几天幼儿的屈光视力检查单PDF。

她说:所有孩子的通知都做在一个PDF里,我没法单独发给班主任。你有什么办法拆开来?

我说:“没问题,问deep seek,它会写拆分代码。
过了一会儿保健老师与保健所联系,决定保健所打印这些胆子。
“那你就不用做了!”
讨论时,保健老师感叹:有145个孩子,这么多屈光有问题!信息化时代下,幼儿的远端视力越来越差了。
但是我没有作过PDF拆分,还是试了一下
设计过程:
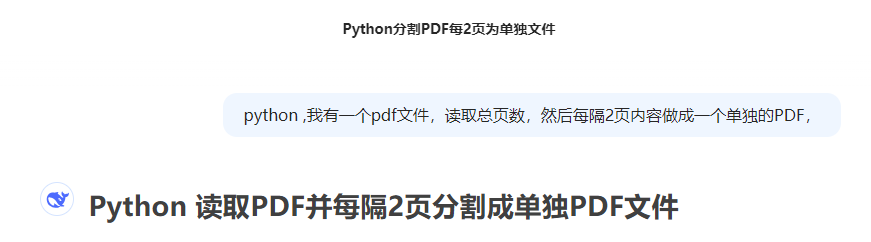
PDF拆分成2页一个PDF
 代码展示
代码展示
'''
屈光PDF按照2张一份,拆分成多个编号
deepseek 阿夏
20250527
'''
from PyPDF2 import PdfReader, PdfWriter
import os
def split_pdf_every_2_pages(input_pdf_path, output_folder):
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 读取PDF文件
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
print(f"总页数: {total_pages}")
# 计算需要分割的文件数量
num_files = (total_pages + 1) // 2
for i in range(num_files):
writer = PdfWriter()
# 计算当前文件的起始和结束页码
start_page = i * 2
end_page = min(start_page + 2, total_pages)
# 添加页面到新PDF
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
# 生成输出文件名
output_filename = os.path.join(output_folder, f"{i+1:003}_P{start_page+1}-P{end_page}.pdf")
# 写入新PDF文件
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
# 使用示例
path=r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf =path + r"\复诊通知XXXx.pdf" # 替换为你的PDF文件路径
output_dir = path + r"\拆分文件" # 输出文件夹
os.makedirs(output_dir,exist_ok=True)
split_pdf_every_2_pages(input_pdf, output_dir)
顺利实现两页一份PDF
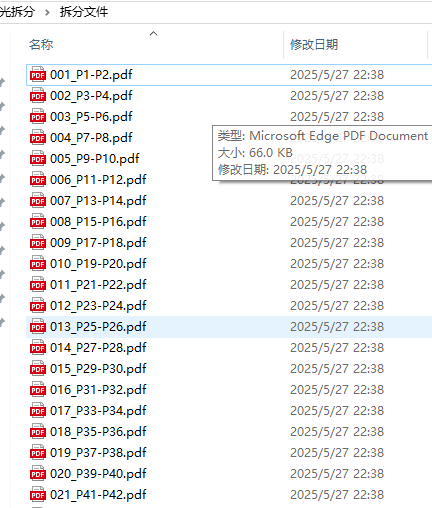
但是我还希望提取姓名、年级、班级号,作为文件名。
经过反复测试后,我发现姓名固定在第6行,年级固定在第7行,但是班级号的位置是不确定,可能在68,69和某些不确定的行上。
deepseek晚上总是容易断网,所以改用了星火讯飞写
 代码展示:
代码展示:
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名
deepseek 阿夏
20250527
'''
import fitz # PyMuPDF
import os
import re
import pandas as pd # 确保已安装pandas库
from PyPDF2 import PdfReader, PdfWriter
def chinese_to_digit(chinese_num):
"""
将中文数字转换为阿拉伯数字。
支持一到十的转换。
"""
chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}
return chinese_dict.get(chinese_num, chinese_num)
def extract_student_info(input_pdf_path, target_pages):
"""
动态提取学生姓名、年级和班级信息。
:param input_pdf_path: PDF文件路径
:param target_pages: 需要处理的页面列表(例如,单数页)
:return: 包含学生信息的字典列表
"""
doc = fitz.open(input_pdf_path)
results = []
# 定义匹配“X班”的正则表达式,X为阿拉伯数字或中文数字,可能带括号
class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?') # 根据实际格式调整括号和数字类型
for page_num in target_pages:
page = doc.load_page(page_num - 1) # fitz的页码从0开始
text = page.get_text("text")
lines = [line.strip() for line in text.split('\n') if line.strip()]
# 初始化变量
name = None
grade = None
classes = []
# 从第6行和第7行提取姓名和年级
if len(lines) >= 6:
name = lines[5].strip() # 第6行(索引5)
if len(lines) >= 7:
grade = lines[6].strip() # 第7行(索引6)
# 遍历所有行查找班级信息
for line in lines:
matches = class_pattern.findall(line)
for match in matches:
# 将中文数字转换为阿拉伯数字
converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])
class_name = converted_match # match 已经是字符串,无需调用 group()
if class_name not in classes:
classes.append(class_name)
# 将提取的信息添加到结果中
if name and grade:
result = {
"page_num": page_num,
"name": name,
"grade": grade[0],
"class": classes
}
results.append(result)
else:
print(f"第{page_num}页缺少必要的信息。")
return results
def convert_students_info(students):
"""
将学生信息转换为 "大7班_陈宇阳" 格式的字符串列表。
:param students: 包含学生信息的字典列表
:return: 格式化后的字符串列表
"""
formatted_list = []
for student in students:
grade = student.get('grade', '')
class_list = student.get('class', [])
name = student.get('name', '')
class_str = ''.join(class_list)
formatted_str = f"{grade}{class_str}班_{name}"
formatted_list.append(formatted_str)
return formatted_list
def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):
"""
将PDF每两页分割成一个新的PDF文件,并使用formatted_names列表中的名称命名文件。
:param input_pdf_path: 输入PDF文件路径
:param output_folder: 输出文件夹路径
:param formatted_names: 用于命名的文件名列表
:return: None
"""
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 读取PDF文件
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
print(f"总页数: {total_pages}")
# 计算需要分割的文件数量
num_files = (total_pages + 1) // 2
print(f"需要创建的文件数量: {num_files}")
# 确保formatted_names的长度足够
if len(formatted_names) < num_files:
print("警告: formatted_names列表长度小于需要创建的文件数量。多余的文件将使用默认命名。")
for i in range(num_files):
writer = PdfWriter()
# 计算当前文件的起始和结束页码
start_page = i * 2
end_page = min(start_page + 2, total_pages)
# 添加页面到新PDF
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
# 获取对应的文件名,如果不足则使用默认命名
if i < len(formatted_names):
filename = f"{formatted_names[i]}.pdf"
else:
filename = f"{i+1:003}_P{start_page+1}-P{end_page}.pdf"
# 生成输出文件路径
output_filename = os.path.join(output_folder, filename)
# 写入新PDF文件
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
def main():
# 设置PDF文件路径
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf = os.path.join(path, "复诊通知XXXX.pdf")
output_dir = os.path.join(path, "拆分文件") # 输出文件夹
os.makedirs(output_dir, exist_ok=True)
# 获取所有单数页(假设页码从1开始)
doc = fitz.open(input_pdf)
all_pages = list(range(1, len(doc) + 1))
odd_pages = [p for p in all_pages if p % 2 != 0]
print(f"处理的单数页: {odd_pages}")
# 提取内容
students_info = extract_student_info(input_pdf, odd_pages)
print(f"提取到的学生信息数量: {len(students_info)}")
# 转换并打印格式化后的列表
formatted_list = convert_students_info(students_info)
print("格式化后的学生列表:")
for item in formatted_list:
print(item)
# 分割PDF并使用formatted_list命名文件
split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)
print("PDF分割完成。")
if __name__ == "__main__":
main()
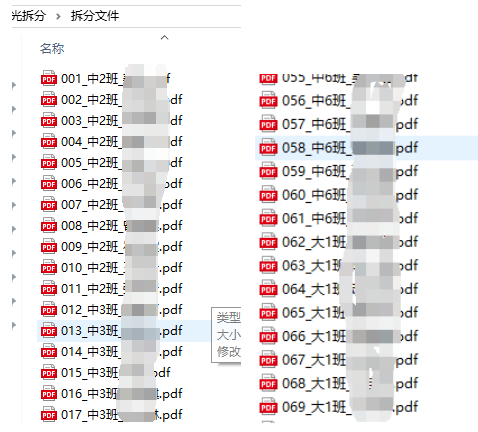
结果展示
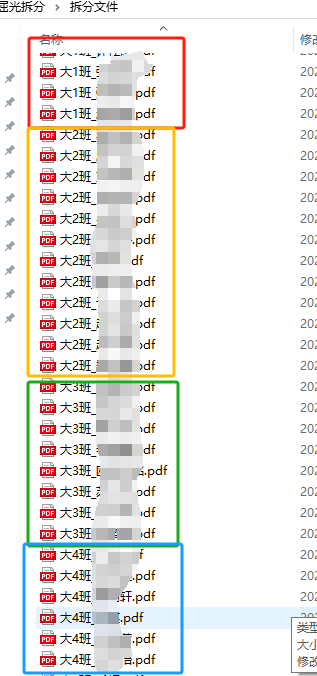
感觉必须添加序号(数据编码)
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
deepseek 阿夏
20250527
'''
# 导入必要的依赖项
import os
from fpdf import FPDF
import re
import pandas as pd # 确保已安装pandas库
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
def chinese_to_digit(chinese_num):
"""
将中文数字转换为阿拉伯数字。
支持一到十的转换。
"""
chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}
return chinese_dict.get(chinese_num, chinese_num)
def extract_student_info(input_pdf_path, target_pages):
"""
动态提取学生姓名、年级和班级信息。
:param input_pdf_path: PDF文件路径
:param target_pages: 需要处理的页面列表(例如,单数页)
:return: 包含学生信息的字典列表
"""
doc = fitz.open(input_pdf_path)
results = []
# 定义匹配“X班”的正则表达式,X为阿拉伯数字或中文数字,可能带括号
class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?') # 根据实际格式调整括号和数字类型
for page_num in target_pages:
page = doc.load_page(page_num - 1) # fitz的页码从0开始
text = page.get_text("text")
lines = [line.strip() for line in text.split('\n') if line.strip()]
# 初始化变量
name = None
grade = None
classes = []
# 从第6行和第7行提取姓名和年级
if len(lines) >= 6:
name = lines[5].strip() # 第6行(索引5)
if len(lines) >= 7:
grade = lines[6].strip() # 第7行(索引6)
# 遍历所有行查找班级信息
for line in lines:
matches = class_pattern.findall(line)
for match in matches:
# 将中文数字转换为阿拉伯数字
converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])
class_name = converted_match # match 已经是字符串,无需调用 group()
if class_name not in classes:
classes.append(class_name)
# 将提取的信息添加到结果中
if name and grade:
result = {
"page_num": page_num,
"name": name,
"grade": grade[0],
"class": classes
}
results.append(result)
else:
print(f"第{page_num}页缺少必要的信息。")
return results
def convert_students_info(students):
"""
将学生信息转换为 "大7班_陈宇阳" 格式的字符串列表。
:param students: 包含学生信息的字典列表
:return: 格式化后的字符串列表
"""
formatted_list = []
for student in students:
grade = student.get('grade', '')
class_list = student.get('class', [])
name = student.get('name', '')
class_str = ''.join(class_list)
formatted_str = f"{grade}{class_str}班_{name}"
formatted_list.append(formatted_str)
return formatted_list
def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):
"""
将PDF每两页分割成一个新的PDF文件,并使用formatted_names列表中的名称命名文件。
同时在文件名前添加三位数的序号前缀。
:param input_pdf_path: 输入PDF文件路径
:param output_folder: 输出文件夹路径
:param formatted_names: 用于命名的文件名列表
:return: None
"""
# 创建输出文件夹(如果不存在)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 读取PDF文件
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
print(f"总页数: {total_pages}")
# 计算需要分割的文件数量
num_files = (total_pages + 1) // 2
print(f"需要创建的文件数量: {num_files}")
# 确保formatted_names的长度足够
if len(formatted_names) < num_files:
print("警告: formatted_names列表长度小于需要创建的文件数量。多余的文件将使用默认命名。")
for i in range(num_files):
writer = PdfWriter()
# 计算当前文件的起始和结束页码
start_page = i * 2
end_page = min(start_page + 2, total_pages)
# 添加页面到新PDF
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
# 获取对应的文件名,如果不足则使用默认命名
if i < len(formatted_names):
base_filename = formatted_names[i]
else:
base_filename = f"P{start_page+1}-P{end_page}"
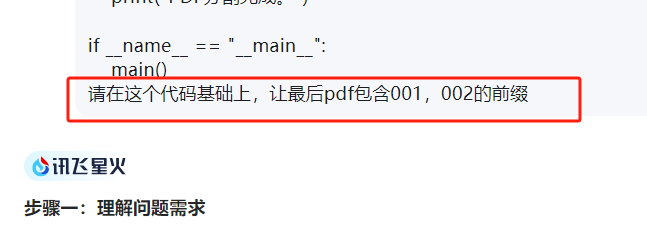
# 添加三位数的序号前缀
numbered_filename = f"{i+1:03}_{base_filename}_202505屈光复查通知.pdf"
# 生成输出文件路径
output_filename = os.path.join(output_folder, numbered_filename)
# 写入新PDF文件
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
def main():
# 设置PDF文件路径
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf = os.path.join(path, "复诊通知XXXX.pdf")
output_dir = os.path.join(path, "拆分文件") # 输出文件夹
os.makedirs(output_dir, exist_ok=True)
# 获取所有单数页(假设页码从1开始)
doc = fitz.open(input_pdf)
all_pages = list(range(1, len(doc) + 1))
odd_pages = [p for p in all_pages if p % 2 != 0]
print(f"处理的单数页: {odd_pages}")
# 提取内容
students_info = extract_student_info(input_pdf, odd_pages)
print(f"提取到的学生信息数量: {len(students_info)}")
# 转换并打印格式化后的列表
formatted_list = convert_students_info(students_info)
print("格式化后的学生列表:")
for item in formatted_list:
print(item)
# 分割PDF并使用formatted_list命名文件,同时在文件名前添加序号前缀
split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)
print("PDF分割完成。")
if __name__ == "__main__":
main()
按照先中班、后大班的顺序
为了明确文件内容,再添加了一个说明
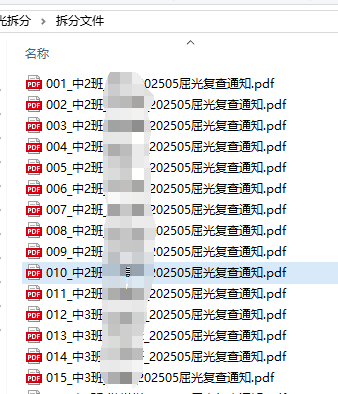
最后是把所有PDF按班级合并文件夹,打包
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)、
按班级分别保存,并打包,便于发送
deepseek 阿夏
20250527
'''
、
import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
def chinese_to_digit(chinese_num):
"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""
chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}
return chinese_dict.get(chinese_num, chinese_num)
def extract_student_info(input_pdf_path, target_pages):
"""从PDF中提取学生信息(姓名、年级、班级)"""
doc = fitz.open(input_pdf_path)
results = []
class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')
for page_num in target_pages:
page = doc.load_page(page_num - 1)
text = page.get_text("text")
lines = [line.strip() for line in text.split('\n') if line.strip()]
name = lines[5].strip() if len(lines) >= 6 else None
grade = lines[6].strip() if len(lines) >= 7 else None
classes = []
for line in lines:
matches = class_pattern.findall(line)
for match in matches:
converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])
if converted_match not in classes:
classes.append(converted_match)
if name and grade:
results.append({
"page_num": page_num,
"name": name,
"grade": grade[0],
"class": classes
})
else:
print(f"第{page_num}页缺少必要的信息。")
return results
def convert_students_info(students):
"""格式化学生信息为'大7班_陈宇阳'格式"""
return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]
def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):
"""将PDF每两页分割成单独文件"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
num_files = (total_pages + 1) // 2
for i in range(num_files):
writer = PdfWriter()
start_page = i * 2
end_page = min(start_page + 2, total_pages)
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"
output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
def classify_pdfs_by_class(source_folder):
"""将PDF文件按班级分类到不同文件夹"""
pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]
if not pdf_files:
print(f"在文件夹 {source_folder} 中没有找到PDF文件")
return
class_stats = {}
for pdf_file in pdf_files:
match = re.search(r'(中\d+班|大\d+班)', pdf_file)
if match:
class_name = match.group(1)
class_folder = os.path.join(source_folder, class_name)
os.makedirs(class_folder, exist_ok=True)
src_path = os.path.join(source_folder, pdf_file)
dest_path = os.path.join(class_folder, pdf_file)
shutil.move(src_path, dest_path)
print(f"移动文件: {pdf_file} -> {class_folder}")
class_stats[class_name] = class_stats.get(class_name, 0) + 1
else:
print(f"无法从文件名 {pdf_file} 中提取班级信息")
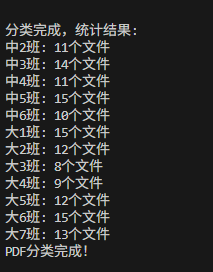
print("\n分类完成,统计结果:")
for class_name, count in class_stats.items():
print(f"{class_name}: {count}个文件")
return class_stats.keys()
def zip_class_folders(source_folder, class_folders):
"""将班级文件夹打包为ZIP压缩包"""
print("\n=== 开始打包班级文件夹 ===")
for folder_name in class_folders:
folder_path = os.path.join(source_folder, folder_name)
zip_path = os.path.join(source_folder, f"{folder_name}.zip")
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, folder_path)
zipf.write(file_path, arcname)
print(f"已创建压缩包: {zip_path}")
def main():
# 设置路径
base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf = os.path.join(base_path, "复诊通知XXXX.pdf")
output_dir = os.path.join(base_path, "拆分文件")
# 第一步:拆分PDF
print("=== 开始拆分PDF ===")
os.makedirs(output_dir, exist_ok=True)
doc = fitz.open(input_pdf)
odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]
students_info = extract_student_info(input_pdf, odd_pages)
formatted_list = convert_students_info(students_info)
split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)
print("PDF拆分完成!\n")
# 第二步:分类PDF
print("=== 开始分类PDF ===")
class_folders = classify_pdfs_by_class(output_dir)
print("PDF分类完成!")
# 第三步:打包文件夹
zip_class_folders(output_dir, class_folders)
if __name__ == "__main__":
main()

我看到终端显示了每个班级有几份,我还想标明文件内容是“屈光复查”
最终代码
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
按照班级转移PDF,班级文件名包括人数、屈光
deepseek 阿夏
20250527
'''
import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
def chinese_to_digit(chinese_num):
"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""
chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}
return chinese_dict.get(chinese_num, chinese_num)
def extract_student_info(input_pdf_path, target_pages):
"""从PDF中提取学生信息(姓名、年级、班级)"""
doc = fitz.open(input_pdf_path)
results = []
class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')
for page_num in target_pages:
page = doc.load_page(page_num - 1)
text = page.get_text("text")
lines = [line.strip() for line in text.split('\n') if line.strip()]
name = lines[5].strip() if len(lines) >= 6 else None
grade = lines[6].strip() if len(lines) >= 7 else None
classes = []
for line in lines:
matches = class_pattern.findall(line)
for match in matches:
converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])
if converted_match not in classes:
classes.append(converted_match)
if name and grade:
results.append({
"page_num": page_num,
"name": name,
"grade": grade[0],
"class": classes
})
else:
print(f"第{page_num}页缺少必要的信息。")
return results
def convert_students_info(students):
"""格式化学生信息为'大7班_陈宇阳'格式"""
return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]
def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):
"""将PDF每两页分割成单独文件"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
num_files = (total_pages + 1) // 2
for i in range(num_files):
writer = PdfWriter()
start_page = i * 2
end_page = min(start_page + 2, total_pages)
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"
output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
def classify_pdfs_by_class(source_folder):
"""将PDF文件按班级分类到不同文件夹,并在文件夹名中加入人数统计"""
pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]
if not pdf_files:
print(f"在文件夹 {source_folder} 中没有找到PDF文件")
return
class_stats = {}
# 第一次遍历:统计每个班级的人数
for pdf_file in pdf_files:
match = re.search(r'(中\d+班|大\d+班)', pdf_file)
if match:
class_name = match.group(1)
class_stats[class_name] = class_stats.get(class_name, 0) + 1
# 第二次遍历:移动文件到带人数的文件夹
for pdf_file in pdf_files:
match = re.search(r'(中\d+班|大\d+班)', pdf_file)
if match:
class_name = match.group(1)
count = class_stats[class_name]
new_folder_name = f"{class_name}_{count}人_屈光复查202505"
class_folder = os.path.join(source_folder, new_folder_name)
os.makedirs(class_folder, exist_ok=True)
src_path = os.path.join(source_folder, pdf_file)
dest_path = os.path.join(class_folder, pdf_file)
shutil.move(src_path, dest_path)
print(f"移动文件: {pdf_file} -> {new_folder_name}")
print("\n分类完成,统计结果:")
for class_name, count in class_stats.items():
print(f"{class_name}: {count}个文件")
# 返回带人数的文件夹名列表
return [f"{k}({v}人)" for k, v in class_stats.items()]
def zip_class_folders(source_folder, class_folders):
"""将班级文件夹打包为ZIP压缩包"""
print("\n=== 开始打包班级文件夹 ===")
for folder_name in class_folders:
folder_path = os.path.join(source_folder, folder_name)
zip_path = os.path.join(source_folder, f"{folder_name}_屈光复查202505.zip")
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, folder_path)
zipf.write(file_path, arcname)
print(f"已创建压缩包: {zip_path}")
def main():
# 设置路径
base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf = os.path.join(base_path, "复诊通知XXXX.pdf")
output_dir = os.path.join(base_path, "拆分文件")
# 第一步:拆分PDF
print("=== 开始拆分PDF ===")
os.makedirs(output_dir, exist_ok=True)
doc = fitz.open(input_pdf)
odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]
students_info = extract_student_info(input_pdf, odd_pages)
formatted_list = convert_students_info(students_info)
split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)
print("PDF拆分完成!\n")
# 第二步:分类PDF
print("=== 开始分类PDF ===")
class_folders = classify_pdfs_by_class(output_dir)
print("PDF分类完成!")
# 第三步:打包文件夹
zip_class_folders(output_dir, class_folders)
if __name__ == "__main__":
main()
转发给保健老师:
20250529
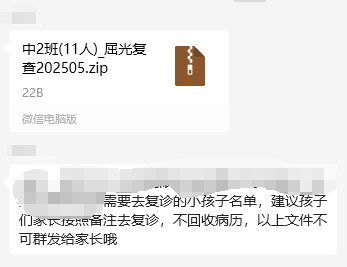
本来说是社区保健所打印通知,但是今天保健老师还是群发了各班PDF名单
很开心你,代码还是用上了。
但是转发时,我发现还要解压缩好麻烦啊,就准备上电脑再操作。
不一会儿,保健老师又发了单独的PDF
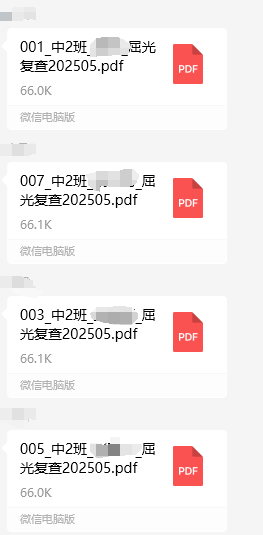
但是我发现发送编号不是按顺序的,而是跳着的,而且少了010、009,还以为是保健老师判定这两个孩子不同复查。
午餐时,保健老师打电话,说
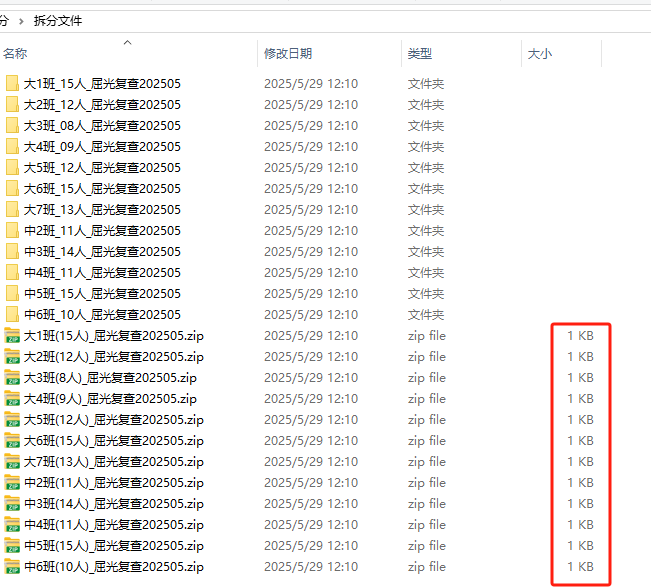
1、班主任发现:原来的rar文件是空包。
我一看打包zip真的是空的
2、我只能发送单独PDF,结果一次只能9份,你们班缺了2个人是谁?
微信一次发送文件最多9个。以那一份先发全为准,所以不是按编号展示出来的。如果数量多,倒数第一个发(先显示),前8个发,所以就是倒数第2、3个不显示(1-11,就是9和10不显示)
问deep seek为什么是空白。
更新代码
'''
屈光PDF按照2张一份,拆分成多个。提取单数页上的姓名(6)年级(7),班级(68、69或不确定的位置)
将大班七班改成大7班。做成文件名、有编号(先中班、再大班)
按照班级转移PDF,班级文件名包括人数、屈光
deepseek 阿夏
20250527
'''
import os
import re
import shutil
import zipfile
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
def chinese_to_digit(chinese_num):
"""将中文数字转换为阿拉伯数字。支持一到十的转换。"""
chinese_dict = {'一': 1, '二': 2, '三': 3, '四': 4,
'五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10}
return chinese_dict.get(chinese_num, chinese_num)
def extract_student_info(input_pdf_path, target_pages):
"""从PDF中提取学生信息(姓名、年级、班级)"""
doc = fitz.open(input_pdf_path)
results = []
class_pattern = re.compile(r'[((]?(\d+|[一二三四五六七八九十]+)班[))]?')
for page_num in target_pages:
page = doc.load_page(page_num - 1)
text = page.get_text("text")
lines = [line.strip() for line in text.split('\n') if line.strip()]
name = lines[5].strip() if len(lines) >= 6 else None
grade = lines[6].strip() if len(lines) >= 7 else None
classes = []
for line in lines:
matches = class_pattern.findall(line)
for match in matches:
converted_match = ''.join([str(chinese_to_digit(char)) if char in '一二三四五六七八九十' else char for char in match])
if converted_match not in classes:
classes.append(converted_match)
if name and grade:
results.append({
"page_num": page_num,
"name": name,
"grade": grade[0],
"class": classes
})
else:
print(f"第{page_num}页缺少必要的信息。")
return results
def convert_students_info(students):
"""格式化学生信息为'大7班_陈宇阳'格式"""
return [f"{s['grade']}{''.join(s['class'])}班_{s['name']}" for s in students]
def split_pdf_every_2_pages(input_pdf_path, output_folder, formatted_names):
"""将PDF每两页分割成单独文件"""
if not os.path.exists(output_folder):
os.makedirs(output_folder)
reader = PdfReader(input_pdf_path)
total_pages = len(reader.pages)
num_files = (total_pages + 1) // 2
for i in range(num_files):
writer = PdfWriter()
start_page = i * 2
end_page = min(start_page + 2, total_pages)
for page_num in range(start_page, end_page):
writer.add_page(reader.pages[page_num])
base_filename = formatted_names[i] if i < len(formatted_names) else f"P{start_page+1}-P{end_page}"
output_filename = os.path.join(output_folder, f"{i+1:03}_{base_filename}_屈光复查202505.pdf")
with open(output_filename, "wb") as out:
writer.write(out)
print(f"已创建: {output_filename}")
def classify_pdfs_by_class(source_folder):
"""将PDF文件按班级分类到不同文件夹,并在文件夹名中加入人数统计"""
pdf_files = [f for f in os.listdir(source_folder) if f.lower().endswith('.pdf')]
if not pdf_files:
print(f"在文件夹 {source_folder} 中没有找到PDF文件")
return []
class_stats = {}
# 第一次遍历:统计每个班级的人数
for pdf_file in pdf_files:
match = re.search(r'(中\d+班|大\d+班)', pdf_file)
if match:
class_name = match.group(1)
class_stats[class_name] = class_stats.get(class_name, 0) + 1
# 第二次遍历:移动文件到带人数的文件夹
created_folders = []
for pdf_file in pdf_files:
match = re.search(r'(中\d+班|大\d+班)', pdf_file)
if match:
class_name = match.group(1)
count = class_stats[class_name]
new_folder_name = f"{class_name}_{count:02}人_屈光复查202505"
class_folder = os.path.join(source_folder, new_folder_name)
if new_folder_name not in created_folders:
os.makedirs(class_folder, exist_ok=True)
created_folders.append(new_folder_name)
src_path = os.path.join(source_folder, pdf_file)
dest_path = os.path.join(class_folder, pdf_file)
shutil.move(src_path, dest_path)
print(f"移动文件: {pdf_file} -> {new_folder_name}")
print("\n分类完成,统计结果:")
for class_name, count in class_stats.items():
print(f"{class_name}: {count}个文件")
# 返回实际创建的文件夹路径列表
return [os.path.join(source_folder, f"{k}_{v:02}人_屈光复查202505") for k, v in class_stats.items()]
def zip_class_folders(source_folder, class_folders):
"""将班级文件夹打包为ZIP压缩包"""
print("\n=== 开始打包班级文件夹 ===")
for folder_path in class_folders:
folder_name = os.path.basename(folder_path)
zip_path = os.path.join(source_folder, f"{folder_name}.zip")
with zipfile.ZipFile(zip_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, folder_path)
zipf.write(file_path, arcname)
print(f"已创建压缩包: {zip_path}")
def main():
# 设置路径
base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250527视力复诊屈光拆分'
input_pdf = os.path.join(base_path, "复诊通知景谷二幼.pdf")
output_dir = os.path.join(base_path, "03打包发给班主任")
# 第一步:拆分PDF
print("=== 开始拆分PDF ===")
os.makedirs(output_dir, exist_ok=True)
doc = fitz.open(input_pdf)
odd_pages = [p for p in range(1, len(doc) + 1) if p % 2 != 0]
students_info = extract_student_info(input_pdf, odd_pages)
formatted_list = convert_students_info(students_info)
split_pdf_every_2_pages(input_pdf, output_dir, formatted_list)
print("PDF拆分完成!\n")
# 第二步:分类PDF
print("=== 开始分类PDF ===")
class_folders = classify_pdfs_by_class(output_dir)
print("PDF分类完成!")
# 第三步:打包文件夹
zip_class_folders(output_dir, class_folders)
if __name__ == "__main__":
main()
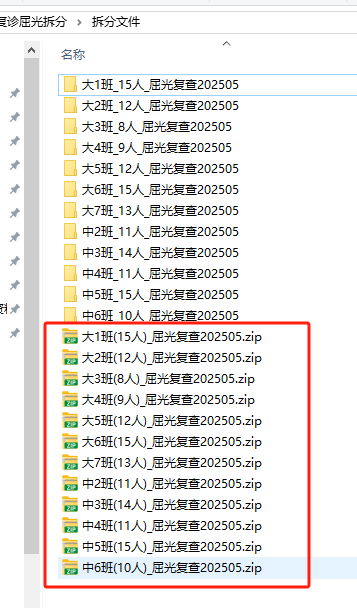
结果:打包文件有大小了
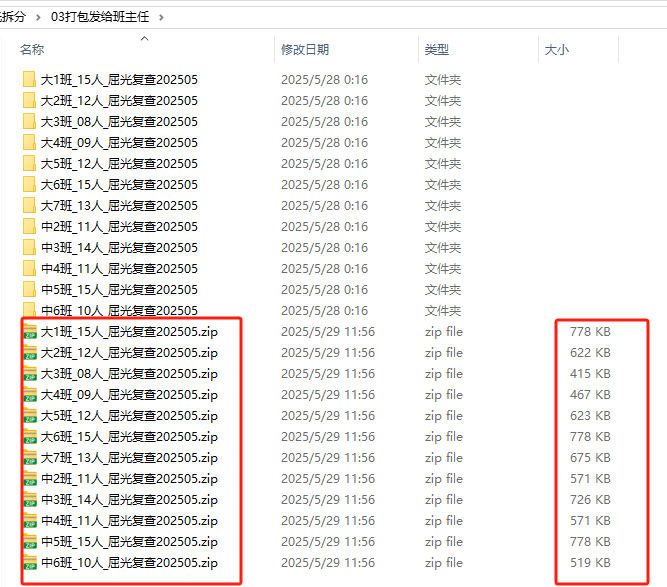
虽然打包发送每条PDF都有,更方便更完整
但是老师可能更喜欢单独PDF,便于转发。
可是保健老师转发又涉及一次只能9条。真是头疼。