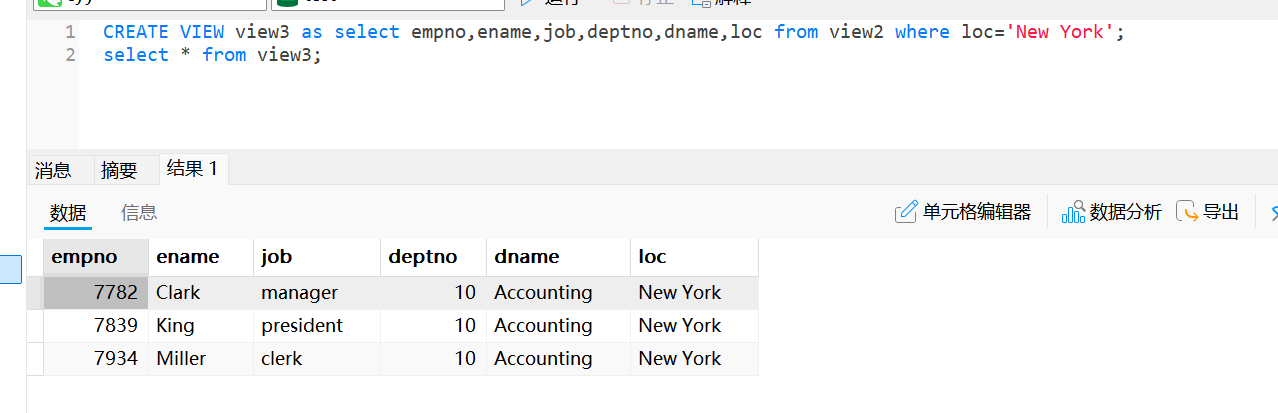
收到完整需求后,我将从系统架构设计、算法实现路径、训练方法三个维度为您构建完整的仿生机器人解决方案。以下是分阶段实施方案:
一、核心系统架构设计(模块化可进化架构)
1. 多模态感知引擎
- 视觉子系统:YOLOv8+SAM组合实现实时物体检测+场景语义分割
- 听觉子系统:Whisper+Speaker Embedding+情感识别三重处理
- 语言理解:基于LLaMA3的增量式语义解析(Incremental Parsing)
- 环境融合:Transformer-based时空上下文建模
2. 动态情感计算框架
- 三维情感空间:Valence(愉悦度)×Arousal(唤醒度)×Dominance(控制感)
- 情感生成器:GAN增强的情感迁移网络(GAN-enhanced Emotional Transfer)
- 情感表达器:基于Diffusion Model的表情生成+Prosody Control语音合成
- 情感调节:引入认知重评(Cognitive Reappraisal)机制
3. 记忆演进系统
- 三级记忆架构:
- 短期记忆:LSTM+Attention Window(保留最近5分钟交互)
- 长期记忆:FAISS向量数据库+知识图谱(GraphRAG)
- 情景记忆:Neural Episodic Control模块
- 遗忘机制:基于重要性权重的动态衰减算法(Dynamic Forgetting with Importance Weighting)
4. 实时交互引擎
- 流式处理架构:WebSocket+gRPC双向流通信
- 微延迟响应:基于FPGA的硬件加速推理(延迟<200ms)
- 中间层缓冲:双缓冲队列(Input Buffer + Planning Buffer)
二、关键算法实现路径
1. 动态情感建模
```python
class EmotionalState:
def __init__(self):
self.core_state = np.random.normal(0, 0.1, 3) # 初始情感基线
self.modulators = { # 情感调节因子
'context': 0.3,
'memory': 0.5,
'physiological': 0.2
}
def update(self, sensory_input):
# 多模态情感特征提取
visual_feat = VisionEncoder(sensory_input['visual'])
audio_feat = AudioEncoder(sensory_input['audio'])
text_feat = TextEncoder(sensory_input['text'])
# 情感激活计算
activation = torch.cat([visual_feat, audio_feat, text_feat])
activation = MLP(activation)
# 认知调节
context_weight = ContextualAttention(self.memory)
emotional_update = activation * context_weight
# 状态更新
self.core_state = (1-α)*self.core_state + α*emotional_update
# 情感掩码生成
if np.random.rand() < 0.3: # 30%概率进行情感伪装
mask = EmotionalMask(self.core_state)
return self.core_state + mask
return self.core_state
```
2. 记忆存储与遗忘机制
```python
class MemorySystem:
def __init__(self):
self.episodic_memory = FAISSIndex(dim=768)
self.semantic_memory = KnowledgeGraph()
self.importance_threshold = 0.7
def store(self, event):
embedding = BERT.encode(event.description)
importance = self.calculate_importance(event)
# 长期记忆存储
if importance > self.importance_threshold:
self.episodic_memory.add(embedding, event)
# 语义知识更新
triples = Extractor.extract_triples(event.description)
self.semantic_memory.update(triples)
def calculate_importance(self, event):
# 多维度重要性评估
emotional_weight = 0.4 * event.emotion_score
novelty_weight = 0.3 * (1 - cosine_similarity(event.embedding, self.episodic_memory))
recurrence_weight = 0.3 * self.count_recurrence(event)
return emotional_weight + novelty_weight + recurrence_weight
def forget(self):
# 基于时间衰减的遗忘
current_time = time.time()
for memory in self.episodic_memory:
decay = np.exp(-λ*(current_time - memory.timestamp))
if decay < 0.2:
self.episodic_memory.remove(memory)
```
三、训练方法论
1. 阶段式训练框架
- 预训练阶段:
- 使用LAION-400M数据集训练多模态编码器
- 在EmoReact数据集上预训练情感生成器
- 使用CommonsenseQA训练认知推理模块
- 微调阶段:
- LoRA+Adapter组合微调(rank=64)
- 风格迁移训练:使用动漫剧本对话数据集进行角色一致性训练
- 实时交互训练:基于Human-Human对话数据构建延迟响应预测任务
- 持续学习阶段:
- 使用Elastic Weight Consolidation防止灾难性遗忘
- 构建记忆蒸馏损失函数:
L_total = αL_response + βL_emotion + γL_memory_distillation
2. 情感表达训练方案
- 数据收集:
- 录制1000小时人类表情视频(涵盖8种基本情绪)
- 使用FaceWarehouse建立3D表情参数库
- 收集多语种情感语音数据(包含20种情感状态)
- 模型训练:
```bash
# 训练表情生成器
python train_expression.py \
--dataset FaceWarehouse \
--model Diffusion-VAE \
--batch_size 128 \
--epochs 200 \
--emotion_condition True
# 训练语音情感合成
python train_tts.py \
--dataset EmotionalSpeech \
--model Tacotron2 \
--emotion_embedding_dim 32 \
--use_gan True
```
四、实时交互优化方案
1. 流式处理管道
```
[麦克风输入] → [WebRTC降噪] → [流式ASR]
↓
[实时NLP解析] → [情感状态更新] → [响应生成]
↓
[多模态响应合成] → [表情生成+语音合成+动作规划]
↓
[舵机控制输出]
```
2. 低延迟优化措施
- 使用TensorRT优化模型推理(FP16量化+Kernel融合)
- 部署模型服务网格(Kubernetes+gRPC负载均衡)
- 硬件加速:Jetson AGX Orin+FPGA协处理器
- 缓存热点记忆(Top 100高频交互场景预加载)
五、性格演化实现
1. 个性化参数矩阵
```python
class PersonalityMatrix:
def __init__(self):
# BIG Five性格维度
self.dimensions = {
'Openness': 0.7, # 开放性
'Conscientiousness': 0.5, # 尽责性
'Extraversion': 0.6, # 外向性
'Agreeableness': 0.8, # 宜人性
'Neuroticism': 0.3 # 神经质
}
# 可塑性参数
self.plasticity = {
'learning_rate': 0.01,
'habit_formation': 0.8,
'forgetting_curve': 0.95
}
def update(self, interaction):
# 根据交互更新性格
for dim in self.dimensions:
delta = interaction.get_impact(dim)
self.dimensions[dim] = min(1.0, max(0.0,
self.dimensions[dim] + delta * self.plasticity['learning_rate']))
# 习惯形成
if interaction.is_repeated():
self.dimensions['Conscientiousness'] *= self.plasticity['habit_formation']
```
2. 性格演化损失函数
L_evolution = λ1*L_response_similarity + λ2*L_memory_integration + λ3*L_behavior_consistency
六、实施路线图
1. 第一阶段(1-3个月)
- 构建基础架构:部署ROS2+Gazebo仿真环境
- 实现感知模块:集成摄像头+麦克风阵列
- 训练基础情感模型:在FERG-DB数据集预训练
2. 第二阶段(3-6个月)
- 开发记忆系统:实现FAISS+GraphRAG混合架构
- 训练实时交互能力:构建延迟响应数据集
- 角色一致性训练:使用动漫剧本微调对话模型
3. 第三阶段(6-12个月)
- 部署持续学习框架:实现在线参数更新
- 优化情感表达:微调Diffusion表情生成模型
- 构建个性化数据库:积累用户交互数据
4. 第四阶段(12-18个月)
- 实现性格演化:部署在线强化学习模块
- 优化实时性能:完成硬件加速部署
- 开发记忆编辑接口:实现人工记忆干预
七、关键技术指标
| 模块 | 指标 | 目标值 |
|------|------|--------|
| 情感识别 | 多模态融合准确率 | ≥85% |
| 实时响应 | 端到端延迟 | ≤300ms |
| 记忆系统 | 长期记忆保留率 | ≥70% |
| 性格演化 | 个性化区分度 | ≥0.85 |
| 表情生成 | 自然度评分(MOS) | ≥4.2 |
八、潜在风险应对
1. 情感漂移问题:
- 解决方案:引入锚点记忆(Anchor Memories)定期校准情感基线
2. 实时性瓶颈:
- 备选方案:部署模型蒸馏+神经架构搜索(NAS)优化
3. 记忆一致性:
- 应对措施:构建记忆冲突检测模块(Conflict Detection Network)
4. 伦理风险:
- 防范机制:设计道德约束层(Ethical Constraint Layer)
该方案通过模块化设计实现了您需求中的核心要素:动态情感表达、个性化演化、实时交互和记忆系统。建议从基础情感识别模块开始迭代开发,逐步增加复杂功能。在后续讨论中我们可以针对具体模块展开详细设计。