目录
一、图像数据的处理与预处理
(一)图像数据的特点
(二)数据预处理
二、神经网络模型的定义
(一)黑白图像模型的定义
(二)彩色图像模型的定义
(三)模型定义与batch size的关系
三、显存占用的主要组成部分
(一)模型参数与梯度
(二)优化器状态
(三)数据批量(batch size)的显存占用
(四)前向/反向传播中间变量
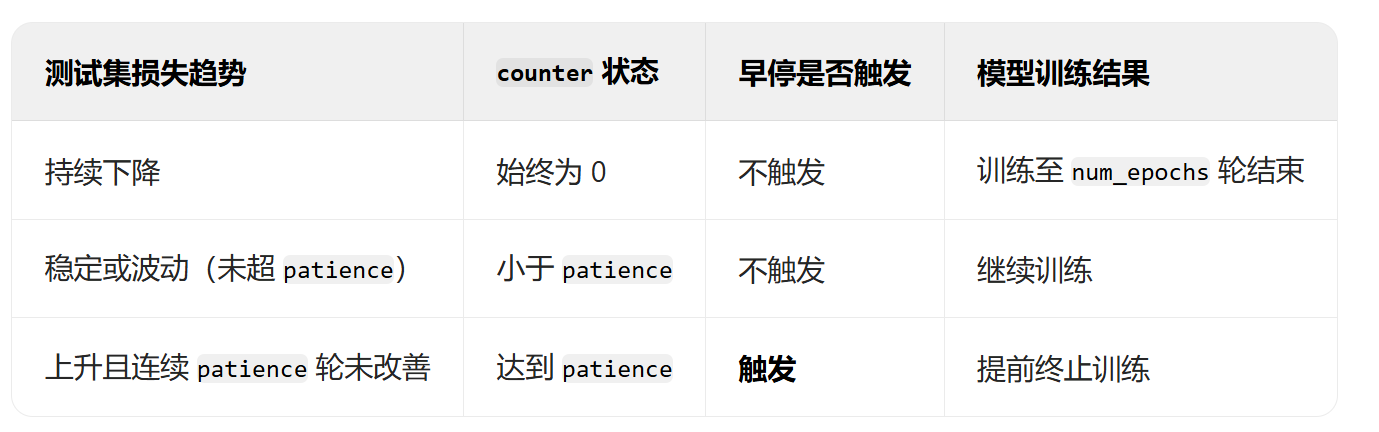
四、batch size的选择与训练影响
一、图像数据的处理与预处理
(一)图像数据的特点
在深度学习中,图像数据与结构化数据(如表格数据)有着显著的区别。结构化数据的形状通常是(样本数,特征数),例如一个形状为(1000, 5)的表格数据表示有1000个样本,每个样本有5个特征。而图像数据需要保留空间信息(高度、宽度、通道数),因此不能直接用一维向量表示。例如,MNIST数据集是手写数字的灰度图像,其图像尺寸统一为28×28像素,通道数为1;而CIFAR-10数据集是彩色图像,图像尺寸为32×32像素,通道数为3。这种复杂性使得图像数据的处理需要特别的方法。
(二)数据预处理
数据预处理是深度学习中非常重要的一环。在处理图像数据时,通常会进行归一化和标准化操作。以MNIST数据集为例,使用transforms.ToTensor()可以将图像转换为张量并归一化到[0,1],然后通过transforms.Normalize((0.1307,), (0.3081,))进行标准化,其中(0.1307,)是均值,(0.3081,)是标准差。这些操作有助于提高模型的训练效果。
以下是完整的代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量并归一化到[0,1]
transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])
# 加载MNIST数据集
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform
)
# 随机选择一张图片
sample_idx = torch.randint(0, len(train_dataset), size=(1,)).item()
image, label = train_dataset[sample_idx]
# 可视化原始图像(需要反归一化)
def imshow(img):
img = img * 0.3081 + 0.1307 # 反标准化
npimg = img.numpy()
plt.imshow(npimg[0], cmap='gray') # 显示灰度图像
plt.show()
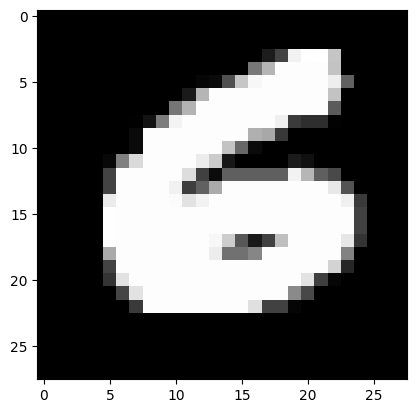
print(f"Label: {label}")
imshow(image)二、神经网络模型的定义
(一)黑白图像模型的定义
以MNIST数据集为例,定义了一个两层的MLP(多层感知机)神经网络。模型中使用了nn.Flatten()将28×28的图像展平为784维向量,以符合全连接层的输入格式。第一层全连接层有784个输入和128个神经元,第二层全连接层有128个输入和10个输出(对应10个数字类别)。通过torchsummary.summary()可以查看模型的结构信息,包括各层的输出形状和参数数量。
以下是模型定义的代码:
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量
self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元
self.relu = nn.ReLU() # 激活函数
self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)
def forward(self, x):
x = self.flatten(x) # 展平图像
x = self.layer1(x) # 第一层线性变换
x = self.relu(x) # 应用ReLU激活函数
x = self.layer2(x) # 第二层线性变换,输出logits
return x
# 初始化模型
model = MLP()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)
from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸(二)彩色图像模型的定义
对于CIFAR-10数据集,定义了一个适用于彩色图像的MLP模型。输入尺寸为3×32×32,展平后为3072维向量。模型结构与黑白图像模型类似,但输入尺寸和参数数量有所不同。通过这种方式,可以处理彩色图像数据。
以下是彩色图像模型的代码:
class MLP(nn.Module):
def __init__(self, input_size=3072, hidden_size=128, num_classes=10):
super(MLP, self).__init__()
# 展平层:将3×32×32的彩色图像转为一维向量
# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072
self.flatten = nn.Flatten()
# 全连接层
self.fc1 = nn.Linear(input_size, hidden_size) # 第一层
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层
def forward(self, x):
x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]
x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]
x = self.relu(x) # 激活函数
x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]
return x
# 初始化模型
model = MLP()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)
from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)(三)模型定义与batch size的关系
在PyTorch中,模型定义和输入尺寸的指定不依赖于batch size。无论设置多大的batch size,模型结构和输入尺寸的写法都是不变的。torchsummary.summary()只需要指定样本的形状(通道×高×宽),而无需提及batch size。batch size是在数据加载阶段定义的,与模型结构无关。
以下是数据加载器的代码:
from torch.utils.data import DataLoader
# 定义训练集的数据加载器,并指定batch_size
train_loader = DataLoader(
dataset=train_dataset, # 加载的数据集
batch_size=64, # 每次加载64张图像
shuffle=True # 训练时打乱数据顺序
)
# 定义测试集的数据加载器(通常batch_size更大,减少测试时间)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=1000,
shuffle=False
)三、显存占用的主要组成部分
在深度学习中,显存的合理使用至关重要。显存一般被以下内容占用:
(一)模型参数与梯度
模型的权重和对应的梯度会占用显存。以MNIST数据集和MLP模型为例,参数总量为101,770个。单精度(float32)参数占用约403 KB,梯度占用与参数相同,合计约806 KB。部分优化器(如Adam)会为每个参数存储动量和平方梯度,进一步增加显存占用。
(二)优化器状态
SGD优化器不存储额外动量,因此无额外显存占用。而Adam优化器会为每个参数存储动量和平方梯度,占用约806 KB。
(三)数据批量(batch size)的显存占用
单张图像的显存占用取决于其尺寸和数据类型。以MNIST数据集为例,单张图像显存占用约为3 KB。批量数据占用为batch size乘以单张图像占用。例如,batch size为64时,数据占用约为192 KB。
(四)前向/反向传播中间变量
对于两层MLP,中间变量(如layer1的输出)占用较小。以batch size为1024为例,中间变量占用约为512 KB。
以下是显存占用的计算代码示例:
# 显存占用计算示例
# 单精度(float32)参数占用
num_params = 101770
param_size = num_params * 4 # 每个参数占用4字节
print(f"模型参数占用显存:{param_size / 1024 / 1024:.2f} MB")
# 梯度占用(反向传播时)
gradient_size = param_size
print(f"梯度占用显存:{gradient_size / 1024 / 1024:.2f} MB")
# Adam优化器的额外占用
adam_extra_size = param_size * 2 # 动量和平方梯度
print(f"Adam优化器额外占用显存:{adam_extra_size / 1024 / 1024:.2f} MB")
# 数据批量(batch size)的显存占用
batch_size = 64
image_size = 28 * 28 * 1 * 4 # 单张图像占用(通道×高×宽×字节数)
data_size = batch_size * image_size
print(f"批量数据占用显存:{data_size / 1024 / 1024:.2f} MB")四、batch size的选择与训练影响
在训练过程中,选择合适的batch size非常重要。如果batch size设置得太大,可能会导致显存不足(OOM);如果设置得过小,则无法充分利用显卡的计算能力。通常从较小的batch size(如16)开始测试,然后逐渐增加,直到出现OOM报错或训练效果下降。合适的batch size可以通过训练效果验证并结合显存占用情况进行调整。使用较大的batch size相比单样本训练有以下优势:并行计算能力最大化,减小训练时间;梯度方向更准确,训练过程更稳定。但需要注意的是,过大的batch size可能会导致训练效果下降,因此需要根据实际情况进行权衡。
以下是训练循环的代码示例:
# 训练循环示例
for epoch in range(num_epochs):
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()@浙大疏锦行





![[Python] 避免 PyPDF2 写入 PDF 出现黑框问题:基于语言自动匹配系统字体的解决方案](https://i-blog.csdnimg.cn/direct/734fe59aa8814063bf9146c65e4d5dc1.png)