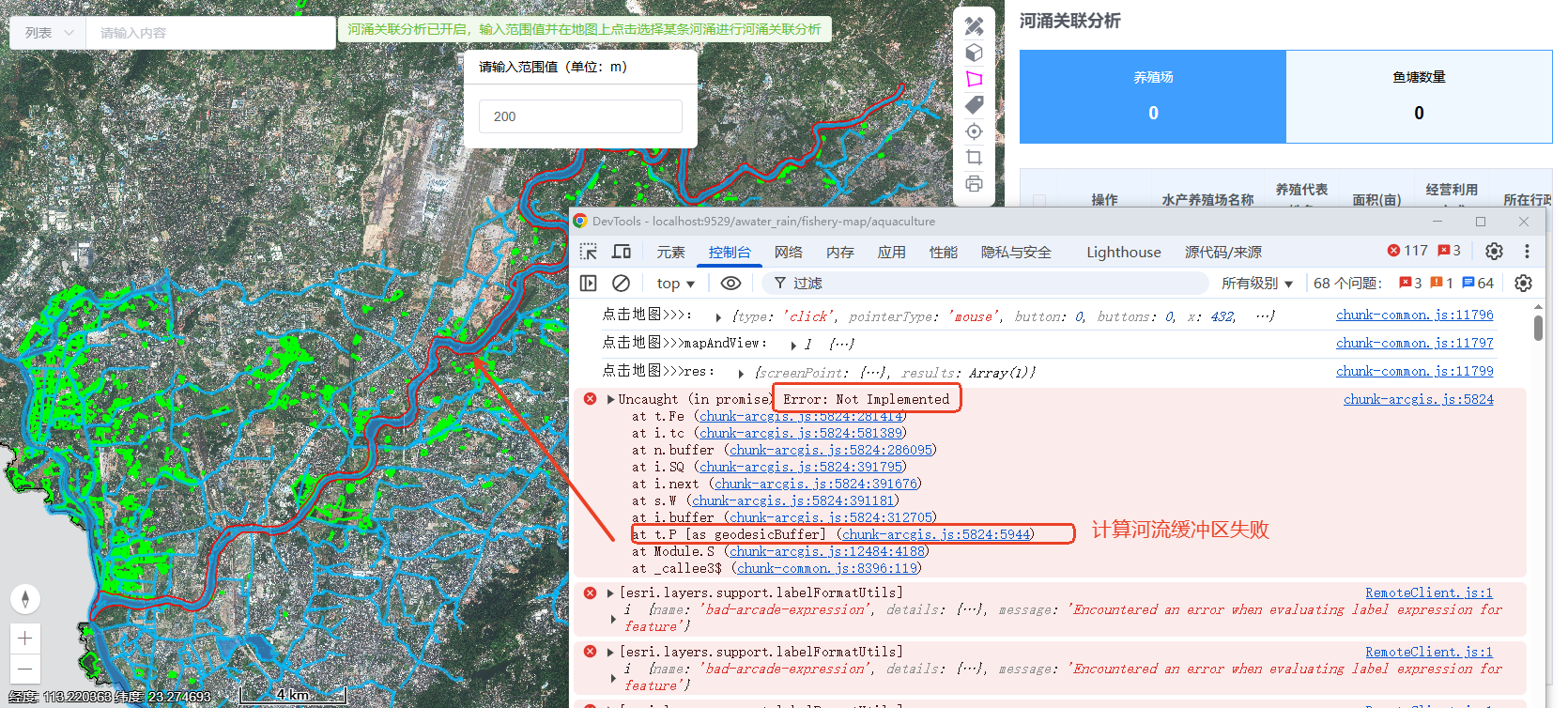
在芯片设计领域,总线架构如同城市交通网,决定了数据流的通行效率。随着AI芯片、车载芯片等复杂场景的爆发式增长,传统总线架构正面临前所未有的挑战。本文将深入解析两大主流互连架构——Crossbar与NoC的优劣,揭示芯片"交通网络"的进化密码。
一、总线架构的演进史
从AMBA总线家族的迭代可见芯片互连技术的进化轨迹:
APB总线:低速外设的"乡间小道",采用两级状态机设计,适合UART、I2C等简单外设。
AHB总线:高性能的"城市快速路",支持多主设备仲裁和突发传输,但全局时钟同步带来功耗瓶颈。
AXI总线:立体交通枢纽,5个独立通道(读写地址/数据/响应)实现流水线操作,吞吐量较AHB提升3倍以上。
Crossbar矩阵:早期的"立交桥"方案,通过M×N交叉开关实现多主多从并行通信,成为中小规模SoC的主流选择。
二、Crossbar架构:简单高效的十字路口
工作原理
如同十字路口的交通灯,Crossbar通过仲裁器动态分配通道。以ARM NIC-400为例,每个主设备(CPU/DMA)通过独立通道连接从设备,实现多路并行传输。
核心优势
超低延迟:组合逻辑路径短,典型延迟仅1-2个时钟周期
确定性时序:固定优先级或轮询仲裁机制保证实时性
高带宽利用:支持Outstanding传输,理论带宽=主设备数×单通道带宽
致命缺陷
指数级布线膨胀:M主×N从设备需要M×N条物理连线,28nm工艺下16×16 Crossbar占芯面积达0.8mm²
时钟树挑战:全局同步设计导致时钟偏差(Skew)随规模扩大急剧上升
扩展天花板:经验公式显示主从设备乘积超过256时时序难以收敛

三、NoC架构:片上互联网的崛起
设计哲学
借鉴TCP/IP网络分层思想,将数据打包传输。每个IP核通过网络接口(NI)连接路由器,形成2D Mesh/环型等拓扑结构。
技术突破
异步时钟域:局部同步(GALS)设计降低动态功耗,实测比Crossbar节能40%
QoS保障:通过虚拟通道+优先级调度,可为AI计算分配专属带宽
容错机制:XY维序路由算法避免死锁,支持链路故障重路由
典型方案对比
| 指标 | ARM CMN-600 | Arteris FlexNOC |
|---|---|---|
| 拓扑结构 | 2D Mesh | 可定制拓扑 |
| 最大节点数 | 256 | 1024 |
| 延迟(Hops) | 5 cycles/hop | 3 cycles/hop |
| 带宽密度 | 512Gb/s/mm²@7nm | 768Gb/s/mm²@7nm |
应用痛点
设计复杂度:需协同优化路由算法、流控协议、物理布局
面积开销:路由器逻辑占NoC总面积60%以上,64节点Mesh面积超2mm²
验证挑战:需构建UVM+FPGA混合验证平台,开发周期增加3-6个月

四、架构选型决策树
典型场景案例
智能座舱芯片:选用Crossbar+NoC混合架构,CPU集群用CMN-600 Mesh,外设通过NIC-500 Crossbar接入
AI训练芯片:全NoC设计,采用3D Torus拓扑实现4096个计算核互连
IoT终端芯片:精简版AXI Crossbar,主从设备控制在8×8以内
五、未来演进方向
光电混合NoC:TSMC已展示硅光互连技术,光链路延迟降低至ps级

AI驱动设计:谷歌利用强化学习优化NoC布线,拥塞率降低27%
Chiplet集成:UCIe标准推动跨die NoC互联,实现芯粒间TB级带宽
结语
在这场芯片"交通网络"的进化竞赛中,Crossbar与NoC并非取代关系,而是走向协同融合。正如城市需要立交桥与地铁网络共存,未来芯片将呈现层次化互连架构,让数据洪流在确定性与灵活性之间找到最佳平衡。