LSTM(长短期记忆网络,Long Short-Term Memory)是一种特殊的循环神经网络(RNN),专门用于处理时间序列数据。由于其独特的结构设计,LSTM能够有效地捕捉时间序列中的长期依赖关系,这使得它在时间序列分析中表现出色。以下是LSTM如何进行时间序列分析的详细步骤和原理:
1. 时间序列问题的特点
时间序列数据是指按照时间顺序排列的数据点,例如股票价格、天气记录、传感器数据等。这类数据通常具有以下特点:
- 时间依赖性:当前时刻的数据可能与过去多个时刻的数据相关。
- 长期依赖性:某些模式可能跨越较长时间间隔。
- 噪声和非线性:时间序列数据可能包含噪声,并且变化规律可能是非线性的。
传统的统计方法(如ARIMA)难以处理复杂的非线性和长期依赖关系,而LSTM通过其门控机制能够很好地解决这些问题。
2. LSTM的核心结构
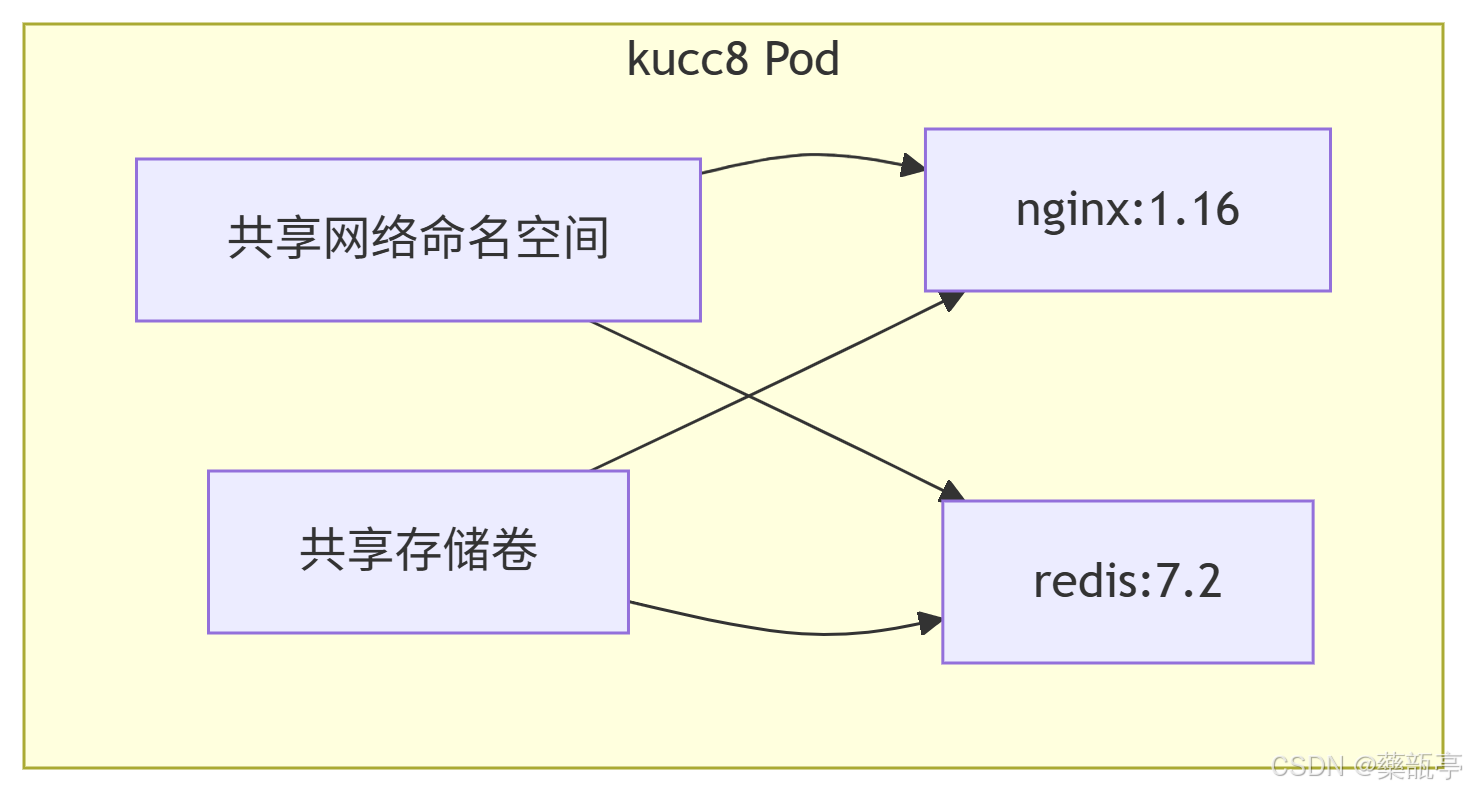
LSTM通过引入三个门控单元(输入门、遗忘门、输出门)以及一个细胞状态(cell state)来控制信息的流动。这些组件帮助LSTM在时间序列中保留长期依赖信息并过滤无关信息。
主要组成部分:
- 细胞状态(Cell State):贯穿整个时间序列,负责存储长期信息。
- 遗忘门(Forget Gate):决定哪些信息从细胞状态中丢弃。
- 输入门(Input Gate):决定哪些新信息需要被写入细胞状态。
- 输出门(Output Gate):决定细胞状态的哪部分将作为当前时刻的输出。
数学公式:
假设当前时刻为 t t t,输入为 x t x_t xt,隐藏状态为 h t h_t ht,细胞状态为 C t C_t Ct:
-
遗忘门:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
决定哪些信息从细胞状态中遗忘。 -
输入门:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
决定哪些新信息需要被添加到细胞状态中。 -
更新细胞状态:
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t Ct=ft⋅Ct−1+it⋅C~t -
输出门:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
h t = o t ⋅ tanh ( C t ) h_t = o_t \cdot \tanh(C_t) ht=ot⋅tanh(Ct)
决定当前时刻的输出。
3. LSTM在时间序列分析中的应用流程
以下是一个完整的基于 PyTorch 的 LSTM 时间序列分析案例。我们将使用一个简单的正弦波数据集,展示如何用 LSTM 模型进行时间序列预测。具体步骤如下:
- 生成时间序列数据:构造一个正弦波并添加噪声。
- 数据预处理:将时间序列转换为监督学习格式(输入为过去的若干时间步,输出为下一个时间步)。
- 构建 LSTM 模型:定义一个简单的 LSTM 网络。
- 训练模型:使用训练数据拟合模型。
- 预测与可视化:使用训练好的模型进行预测,并绘制结果。
以下是完整的 PyTorch 实现代码:
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# (1) 数据准备
# 生成正弦波数据并添加噪声
np.random.seed(42)
time_steps = 1000
original_sequence = np.sin(np.linspace(0, 100, time_steps)) + np.random.normal(0, 0.1, time_steps)
# 构造滑动窗口数据集
def create_dataset(sequence, look_back=1):
X, y = [], []
for i in range(len(sequence) - look_back):
X.append(sequence[i:i+look_back])
y.append(sequence[i+look_back])
return np.array(X), np.array(y)
look_back = 10 # 使用过去10个时间步预测下一个时间步
X, y = create_dataset(original_sequence, look_back)
X = torch.tensor(X, dtype=torch.float32).unsqueeze(-1) # 调整为LSTM输入格式 [样本数, 时间步, 特征数]
y = torch.tensor(y, dtype=torch.float32).unsqueeze(-1)
# 划分训练集和测试集
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# (2) 模型设计
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=50, output_size=1, num_layers=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
lstm_out, _ = self.lstm(x) # lstm_out: [batch_size, seq_len, hidden_size]
out = self.fc(lstm_out[:, -1, :]) # 取最后一个时间步的输出
return out
model = LSTMModel(input_size=1, hidden_size=50, output_size=1, num_layers=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# (3) 训练模型
epochs = 200
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch + 1) % 50 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# (4) 预测
model.eval()
predicted_sequence = []
current_input = X[0].unsqueeze(0) # 初始化输入
with torch.no_grad():
for i in range(len(X)):
next_value = model(current_input)[0] # 预测下一个值
predicted_sequence.append(next_value.item())
# 更新输入序列
current_input = torch.cat((current_input[:, 1:, :], next_value.unsqueeze(0).unsqueeze(0)), dim=1)
# (5) 可视化
plt.figure(figsize=(12, 6))
# 原始序列
plt.plot(original_sequence, label="Original Sequence", color="blue")
# LSTM生成的序列
plt.plot(np.arange(look_back, len(original_sequence)), predicted_sequence, label="LSTM Predicted Sequence", color="r")
plt.title("LSTM Time Series Prediction")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.legend()
# plt.show()
plt.savefig(f'pmi/images/LSTM_result.png')
代码解析
(1)数据准备
- 我们生成了一个正弦波,并向其添加了随机噪声。
- 使用
create_dataset函数将时间序列转换为监督学习格式。每个输入样本包含过去look_back个时间步的数据,目标值为下一个时间步的值。
(2)LSTM 模型
- 定义了一个简单的 LSTM 模型,包含以下组件:
- LSTM 层:用于捕捉时间序列中的依赖关系。
- 全连接层:将 LSTM 的输出映射到目标值。
(3)训练模型
- 使用均方误差(MSE)作为损失函数,Adam 作为优化器。
- 在每个 epoch 中,计算预测值与真实值之间的损失,并通过反向传播更新模型参数。
(4)预测
- 使用训练好的模型逐点生成预测序列。
- 每次预测后,将预测值加入输入序列,以便生成下一个时间步的预测。
(5)可视化
- 使用 Matplotlib 绘制原始序列和 LSTM 模型生成的预测序列,方便对比。
运行结果

4. LSTM在时间序列分析中的优势
- 长期依赖性:LSTM通过细胞状态和门控机制,能够捕捉时间序列中的长期依赖关系。
- 鲁棒性:对噪声和非线性模式具有较好的适应性。
- 灵活性:可以处理单变量或多变量时间序列数据。
5. 常见变体与改进
在实际应用中,LSTM可能会结合其他技术以提升性能:
- 双向LSTM(BiLSTM):同时考虑时间序列的前向和后向信息。
- 堆叠LSTM(Stacked LSTM):通过多层LSTM提取更深层次的特征。
- 注意力机制(Attention Mechanism):增强模型对重要时间步的关注。
总结
LSTM是时间序列分析的强大工具,其核心在于通过门控机制有效捕捉长期依赖关系。通过合理的数据预处理、模型设计和训练策略,LSTM可以广泛应用于股票预测、天气预报、设备故障检测等领域。如果您有具体的时间序列分析任务或数据,欢迎提供更多信息,我可以进一步为您设计解决方案!