目录
第 3 章 线性表
3.1 线性表的基本概念
3.1.1 线性表的定义
3.1.2 线性表的基本操作
3.1.3 线性表的分类
3.1.4 习题精编
3.2 线性表的顺序存储
3.2.1 顺序表的定义
3.2.2 顺序表基本操作的实现
1.顺序表初始化
2.顺序表求表长
3.顺序表按位查找
4.顺序表按值查找
5.顺序表遍历输出
6.顺序表插入元素
7.顺序表删除元素
8. 顺序表清空
9. 顺序表判空
3.2.3 习题精编
3.2.4 真题演练
3.3 线性表的链式存储
3.3.1 单链表的定义
3.3.2 单链表基本操作的实现
1. 单链表初始化
2. 单链表求表长
3. 单链表按序号查找
4. 单链表按值查找
5. 单链表遍历输出
6. 单链表插入元素
7. 单链表删除元素
8. 单链表置空
9. 单链表判空
10. 静态链表
3.3.3 单链表的一些其他算法
1. 头插法和尾插法建立单链表
2. 原地倒置单链表
3. 双指针遍历单链表
3.3.4 双链表的定义
3.3.5 双链表基本操作的实现
1. 双链表的插入操作
2. 双链表的删除操作
3.3.6 循环链表的定义
3.3.7 习题精编
3.3.8 真题演练
3.4 章末总结
第 3 章 线性表
【考纲内容】
1.线性表的基本概念
2.线性表的实现
(1) 顺序存储;(2) 链式存储
3.线性表的应用
【考情统计】
年份
单选题
综合题
总分值
考点
2009
0
1
15
双指针遍历单链表
2010
0
1
13
倒置数组
2011
0
1
15
寻找数组中位数
2012
0
1
15
单链表遍历操作
2013
1
2
25
线性表的顺序表示、线性表的链式表示
2014
0
0
0
未考查
2015
0
1
15
单链表遍历操作
2016
2
0
4
单链表插入操作、双循环链表删除操作
2017
0
0
0
未考查
2018
0
1
13
数组最小未出现正整数
2019
0
1
13
倒置重排单链表
2020
0
1
15
三元组的最短距离
2021
1
0
2
单循环链表删除操作
2022
0
0
0
未考察
2023
1
0
2
双链表操作
2024
1
0
2
单链表操作
【考点解读】
本章内容作为后一章节的基础,主要考查对算法操作的理解。要求考生熟练掌握线性表的结构,积累算法思想。考生需要牢记本章节中线性表的结构以及相应的各种操作。对于 408 算法题,在时间有限的情况下,需要对算法思想与代码可执行性进行取舍,算法思想具有更高的优先级,建议考生在算法题作答中将更多精力放在描述算法的思想与过程上。
另外,从考情统计表中可以看出,在早些年的 408 考试中,经常在本章出算法大题。近些年(2021 - 2024)408 算法大都集中在树和图章节。但本章出算法大题的概率依然很高,建议考生认真对待本书第 9 章专项练习章节的习题。
【复习建议】
本章要注意理解和掌握各种线性表的结构与操作实现。主要掌握以下知识点:
1.掌握线性表的顺序存储和链式存储,以及各自的特点。
2.掌握顺序表各种操作的实现,理解时间复杂度的计算过程。
3.掌握各类链表的插入删除操作,理解时间复杂度的计算过程。
4.掌握链表的其他算法,如倒置链表、快慢指针法等,学会熟练运用。
3.1 线性表的基本概念
3.1.1 线性表的定义
线性表(Linear List)是具有相同特性的数据元素的一个有限序列。线性表长度 n 指序列中元素的个数。当 n 为 0 时,称为空表。
3.线性表是具有 n 个 ( ) 的有限序列。
A. 表元素
B. 数据元素
C. 数据项
D. 信息项3.【参考答案】 B
【解析】 同上一题解析可得答案。2.线性表是一个 ( )。
A. 有限序列,可以为空
B. 有限序列,不能为空
C. 无限序列,可以为空
D. 无限序列,不能为空2.【参考答案】 A
【解析】 由线性表概念可得,线性表是n(n≥0)个具有相同特性的数据元素的有限序列。线性表 L 通常表示为:
L=(a0,a1,⋯,ai,ai+1,⋯,an−1)其中:a0称为表头元素,an−1称为表尾元素。对于元素ai(0<i<n−1),它有唯一的前驱ai−1,唯一的后继ai+1。而对于元素a0和an−1较为特殊。表头元素a0,没有前驱,只有后续。表尾元素an−1,没有后继,只有前驱。
1.在线性表中,除开始元素外,每个元素 (),除结束元素外,每个元素 ()。
A. 只有唯一的前驱
B. 只有唯一的后继
C. 不止一个前驱
D. 不止一个后继1.【参考答案】 A、B
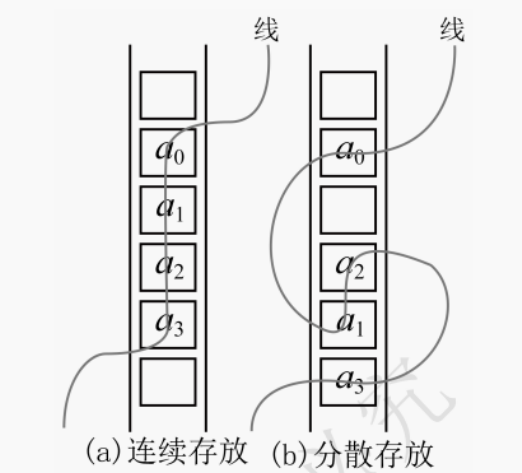
【解析】 此题为线性表概念的考查,除第一个元素外,每一个元素有且仅有一个直接前驱。除最后一个元素外,每一个元素有且仅有一个直接后继。如图 3.1 所示,线性表是一种逻辑结构,表示逻辑上存在一一对应的先后关系。可以理解为:逻辑上把所有数据用一根线串起来,再存储到物理空间中。
3.1.2 线性表的基本操作
此处罗列线性表的一些基本操作,后续会对这些操作的具体实现方式进行讲解。线性表的基本操作的 C 语言声明如下:
// 1. 初始化,构造一个空的线性表 void initialize(List &L); // 2. 求表长,获得L中实际存储的元素个数 int listLength(const List &L); // 3. 按序号查找,获得第i个数据元素的值,查找失败则返回ERROR_ELEM // ERROR_ELEM是宏定义设置的特殊值(如设置成-1),专门表示错误 ElemType getElem(const List &L, int i); // 4. 按值查找,获得第一个等于e的元素位置 int locateElem(const List &L, ElemType e); // 5. 遍历输出,输出L中所有元素 void listVisit(const List &L); // 6. 插入元素,在L中第i个位置插入新的元素e bool listInsert(List &L, int i, ElemType e); // 7. 删除元素,删除L中的第i个数据元素 bool listDelete(List &L, int i, ElemType e); // 8. 置空,将L重置为空表 void clearList(List &L); // 9. 判空,判断L是否为空表 bool listEmpty(const List &L);以上基本操作都是线性表的逻辑功能,即函数声明。具体函数定义取决于线性表的存储结构,将在后面的小节中给出。当需要修改传入的参数 L 时,函数形参类型用 List&(也可使用 List * 进行间接修改,但其实现过程繁琐),当不需要修改传入的参数 L 时,可以使用 List。具体原因在本书第 1.5.4 小节(第 11 页)有介绍。
说明:上述代码中的 List 代表线性表这种逻辑结构,具体的物理存储结构可以选择顺序表(SqList)或者链表(LinkList)。ElemType 泛指数据类型,具体可以是 int,float 等。
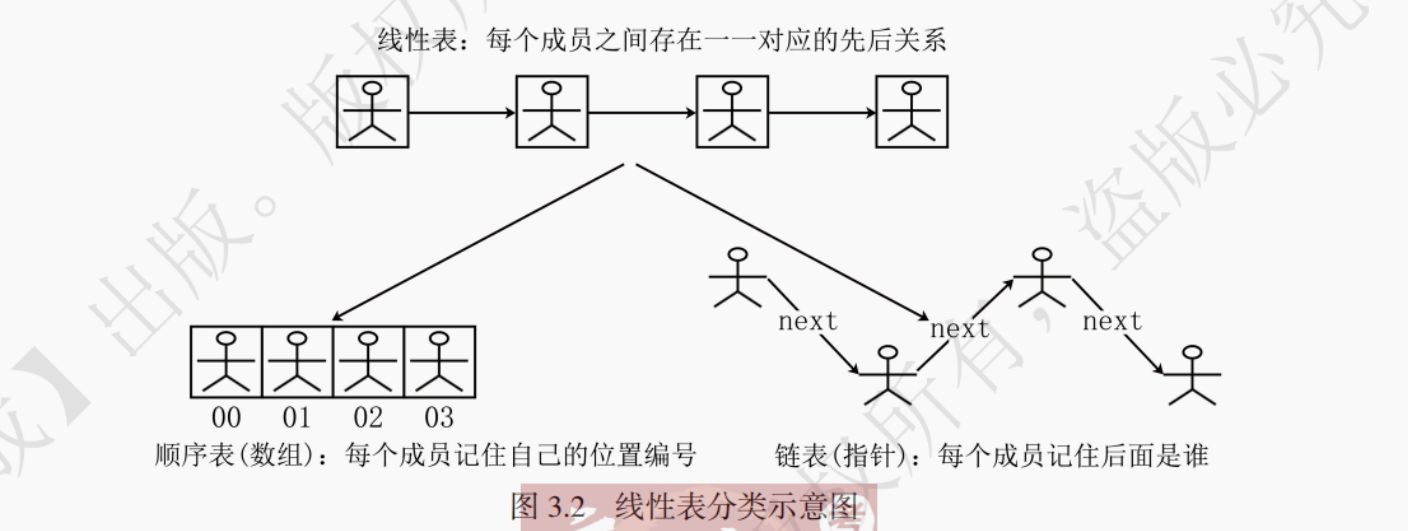
3.1.3 线性表的分类
如图 3.2 所示,线性表是逻辑结构,规定了数据之间的关系,但不关心这些数据关系是如何实现的。根据数据关系的具体实现形式,线性表可分为顺序表和链表。顺序表和链表属于物理结构。可以把线性表类比成 C 语言的函数声明:规定了函数有哪些功能。把顺序表和链表类比成函数的具体实现:可以用 for 循环去实现这些功能,也可以用 while 循环去实现这些功能。
在将线性表存储到具体的存储设备上时,线性表的每一个数据元素对应一个存储结点(简称,结点),每个结点即一个逻辑上的存储单元。各种线性表的结点可抽象为图 3.3 的形式。
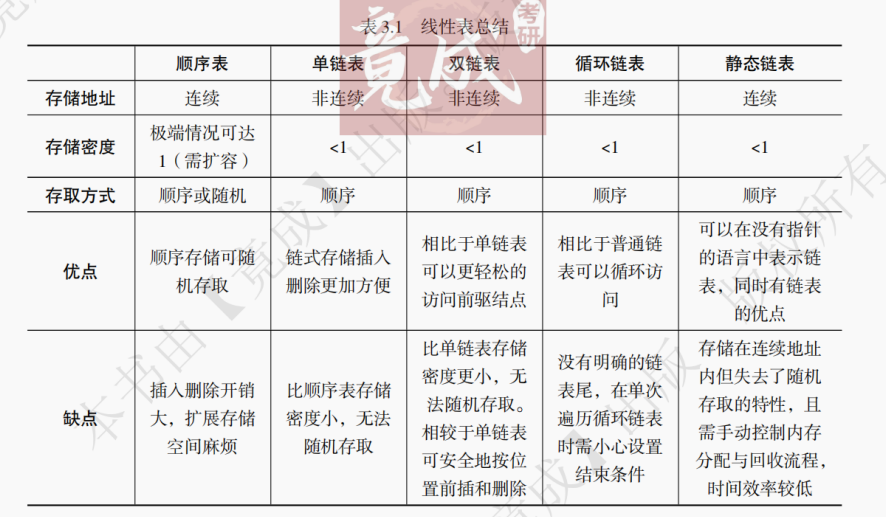
与链表相比,顺序表有以下特点:
(1) 支持随机存取:即知道下标就能取得其中的元素,可在 O (1) 时间内找到第 i 个元素。顺序表中的数据是连续存放的,因此只要知道顺序表中首个元素的地址,那么后面的第 i 个数据元素的地址就可以用 “首地址 + i×单个数据所占内存大小” 的方式计算出来。1.线性表的顺序存储结构是一种 ( ) 的存储结构。
A. 随机存取
B. 散列存取
C. 索引存取
D. 顺序存取1.【参考答案】 A
【解析】 线性表的顺序存储结构便是顺序表,同时顺序表是一种支持随机存取的存储结构。散列存取将在后面学习散列表时了解,索引存取是指通过查索引表进行索引。顺序存取是指可以从首元素开始遍历至需要存取的元素,因此顺序存储的线性表也是满足顺序存取的,但不能说这种存储结构就是顺序存取的存储结构,注意链表也是可以顺序存储的。(2) 存储密度高:每个结点只存储数据元素本身。而在链式存储的方法中,每个结点除了存储数据元素还要存储指针,相较而言,顺序表的存储密度较高,空间利用率比较高。
(3) 插入删除开销大:顺序表插入需要逐个后移元素。而链表由指针标识元素顺序,只需要改变指针指向就可以做到插入删除元素。注意:以上特点需要着重区分与掌握,考生可以在学完整章后再回顾,以加深理解。
【例 3.1】(多选) 以下关于顺序存储与链式存储的描述中,错误的是 ( )。
A. 顺序存储结构优于链式存储结构
B. 随机存取就是指每次存取都要遍历整个表
C. 链式存储的存储密度大于 1
D. 顺序存储结构和链式存储结构都可以进行顺序存取解析:选 ABC,顺序存储和链式存储没有优劣之分,只有适合与否。随机存取是指可以通过下标直接获得存储的值,链式存储由于结点中有指针,因此存储密度小于 1。顺序存取是指可以从首元素开始遍历至需要存取的元素,因此 D 正确。
3.1.4 习题精编
1.在线性表中,除开始元素外,每个元素 (),除结束元素外,每个元素 ()。
A. 只有唯一的前驱
B. 只有唯一的后继
C. 不止一个前驱
D. 不止一个后继1.【参考答案】 A、B
【解析】 此题为线性表概念的考查,除第一个元素外,每一个元素有且仅有一个直接前驱。除最后一个元素外,每一个元素有且仅有一个直接后继。2.线性表是一个 ( )。
A. 有限序列,可以为空
B. 有限序列,不能为空
C. 无限序列,可以为空
D. 无限序列,不能为空2.【参考答案】 A
【解析】 由线性表概念可得,线性表是n(n≥0)个具有相同特性的数据元素的有限序列。3.线性表是具有 n 个 ( ) 的有限序列。
A. 表元素
B. 数据元素
C. 数据项
D. 信息项3.【参考答案】 B
【解析】 同上一题解析可得答案。4.以下关于链式存储结构的叙述中,正确的是 ( )。
A. 存储密度大于顺序存储结构
B. 逻辑上相邻的结点物理上不必相邻
C. 支持随机访问
D. 插入删除不方便,需要移动结点4.【参考答案】 B
【解析】 链式存储由于需要在结点中存储指针,存储密度(结点中数据本身的存储量与结点的存储总量的比值)小于 1,低于顺序存储结构,故 A 错。链式存储中逻辑上相邻的结点物理上不必相邻,因此不支持随机访问,故 C 错。链式存储插入时不需要移动结点,只需要改变结点中指针的指向,故 D 错。3.2 线性表的顺序存储
3.2.1 顺序表的定义
顺序表(Sequential List)通常用数组来实现,指把线性表中的所有元素,按照其逻辑顺序,依次存储到计算机存储器的一块连续存储空间中。
假设存储含有n个元素的顺序表,L0代表第一个数据元素的地址,其中每个元素占用c个地址的存储空间(C 语言中,可使用 sizeof 运算符将数据类型的具体值c计算出来)。顺序表的存储地址与存储空间的对应关系如图 3.5 所示:
观察图 3.5 中数据的存储状态,可以发现顺序表存储数据的方式与编程语言中的数组非常接近。408 考试对 “线性表的顺序表示” 这个知识点的考查方式也以数组上的各种算法操作为主。
2.(多选) 一个顺序表占用存储空间的大小与 ( ) 有关。
A. 表容量 capacity
B. 单个元素的长度
C. 表中元素数量
D. 元素的物理位置2.【参考答案】 A、B
【解析】 顺序表占用空间大小等于 capacity× 单个元素的长度,因为顺序表的空间是提前分配的,因此表中元素数量的多少不会影响存储空间,元素的物理位置也不会影响总空间的大小。提示:由于 C 语言数组下标从 0 开始,为了统一说法,本章所述线性表的首位元素被称为 “第 0 个元素”。但要注意真题中首位元素的下标需根据具体问题具体分析。
使用顺序表存储数据时,还需要实时记录表的长度,也就是表中存储数据元素的个数,即图 3.5 中的 length 变量。
顺序表有静态分配和动态分配两种实现方式。静态分配实现代码如下:
#define MAX_SIZE 100 // 定义顺序表最大长度 typedef struct { ElemType data[MAX_SIZE]; // 存放顺序表中的元素 int length; // 顺序表当前存放的元素的个数,即表长 int capacity; // 记录顺序表预分配的存储容量,即最多可存放的元素个数 } SqList;在静态分配时,数组的存储空间已经固定,如果空间占满再加入新的数据就会产生溢出。而动态分配可以在运行过程中动态分配存储空间,以满足存储空间动态扩展的需求。动态分配实现代码如下:
typedef struct { ElemType *data; // 声明动态分配数组的指针 int length; // 顺序表当前存放的元素的个数,即表长 int capacity; // 记录顺序表预分配的存储容量,即最多可存放的元素个数 } SqList;当分配的空间存满数据之后,可以在内存的另一处申请一个更大的空间,将原顺序表中的元素全部拷贝到刚申请的空间,并修改 capacity 值,最后将指针指向该空间首地址。
3.2.2 顺序表基本操作的实现
本小节将按照上一节中的线性表操作声明,依次给出顺序表基本操作的 C 语言实现方式。本节是需要重点学习的部分,希望考生多加思考,模拟代码的执行过程。
注意:本节只介绍顺序表的基本操作及其考查方式,相关综合题见本书专项练习章节。
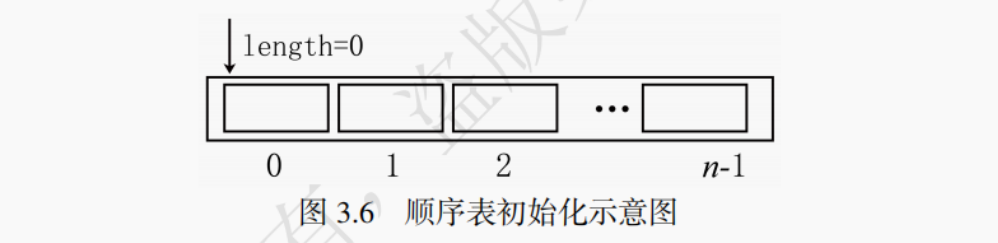
1.顺序表初始化
顺序表的初始化主要是对存储空间的申请与相关变量的初始化,如图 3.6 所示。
因为静态分配中数组的存储空间已经在结构体定义中声明了存储空间的申请,所以只有动态分配形式需要显式申请动态存储空间。顺序表的初始化主要是对 length 变量和 capacity 变量的初始化,对应的 C 语言实现代码如下:
void initialize(SqList &L) { // 静态分配初始化,数组空间此时已分配完成 L.length = 0; L.capacity = MAX_SIZE; } void initialize(SqList &L) { // 动态分配初始化 // 显式地申请存放顺序表的元素的数组,此情况MAX_SIZE由程序输入决定 L.data = (ElemType*)malloc(sizeof(ElemType) * MAX_SIZE); L.length = 0; // 空表表长为0 L.capacity = MAX_SIZE; } SqList L; initialize(L); // 调用初始化函数2.顺序表求表长
顺序表当前的表长由结构体中的 length 变量记录,length 会在每次插入和删除操作时被更改。实现代码如下:
// 返回表长 int listLength(const SqList &L) { // 使用常引用避免不必要的隐式拷贝,效率高 return L.length; }3.顺序表按位查找
顺序表支持随机存取,按位查找就是根据下标直接访问对应位置的元素。实现代码如下:
ElemType getElem(const SqList &L, int i) { // i是所需查找的第i个位置的元素 if (i >= 0 && i < L.length) { // 判断给定的i是否在可达范围内 return L.data[i]; // 返回此处的值 } return -1; // 否则查找的下标越界,访问的值没有意义,返回错误标志-1 }顺序表支持随机访问(如上述代码第 3 行所示),根据数组下标 i(首元素地址加上偏移量i×sizeof(ElemType))可以直接计算出第 i 个元素的位置,因此查找的时间复杂度为 O (1)。
3.在n个结点的线性表的数组实现中,算法的时间复杂性是 O (1) 的操作是 ( )。
A. 访问第i(1≤i≤n)个结点和求第i(2≤i≤n)个结点的直接前驱
B. 在第i(1≤i≤n)个结点后插入一个新结点
C. 删除第i(1≤i≤n)个结点
D. 以上都不对3.【参考答案】 A
【解析】 顺序表支持随机访问,因此访问任意位置元素的时间复杂度都是 O (1),直接前驱只需要访问i−1的位置。顺序表插入与删除结点需要进行元素的移动,因此操作复杂度为 O (n),故 B、C 错。提示:代码中 if 语句的判断被称为 “边界条件检查”,是为了保证函数可以正常运行,避免访问超出表长的内存位置,这和操作系统中页访问越界判断的逻辑是相同的。
4.顺序表按值查找
在顺序表中以类似穷举的方式从头到尾遍历,并判断是否为目标元素。若找到了则返回目标元素的位置,否则返回 -1。实现代码如下:
int locateElem(SqList L, ElemType e) { // e是要查找的元素的值 for (int k = 0; k < L.length; ++k) if (L.data[k] == e) return k; return -1; // 循环内未返回,说明查找失败 }根据查找元素的位置,将所需要的时间成本分为如下几种情况:
最好情况:查找元素的位置在顺序表的表头,则只需要比较一次,时间复杂度是 O (1);
最坏情况:查找元素的位置在顺序表的表尾,则需要比较n次,时间复杂度是 O (n);
平均情况:查找元素的位置在顺序表的中间位置,设pi=1/n代表该结点在第i个位置的概率,则在长度为n的顺序表中查找结点时,平均比较次数可用如下公式表示:
由此可得,顺序表查找算法的平均时间复杂度是 O (n)。5.顺序表遍历输出
类似于顺序表中的按值查找,顺序表的遍历输出只需要把判断语句改成输出语句即可实现。代码如下:
void listVisit(const SqList &L) { for (int k = 0; k < L.length; ++k) // 需要实现其他功能只需改写输出语句即可 printf("%d ", L.data[k]); // 设ElemType为int,格式化输出为%d }6.顺序表插入元素
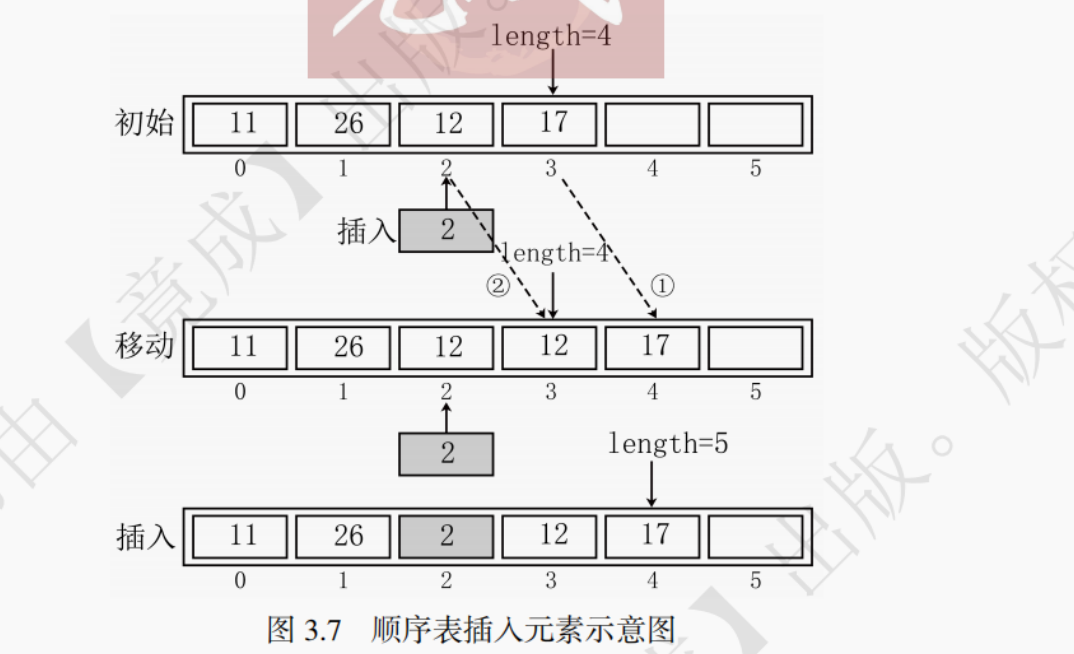
可将顺序表看作图书馆的书架,将插入操作类比为书架上放书的过程,当需要插入一本书时,可以把后面的书依次往后移动一个单位,再将这本书插入。可参考图 3.7 来理解顺序表元素插入的过程:
(1) 将要插入位置的元素以及后续的全部元素,整体向后移动一个位置。
(2) 将要插入的元素放在移动出来的空位上。
(3) 将线性表长度 length 加 1。按照上述过程,就实现了顺序表中元素的插入,代码实现如下:
// 第i个位置 插入元素的值为e bool listInsert(SqList &L, int i, ElemType e) { // i的合法范围为[0, L.length],先判断是否越界 // 本例定义L.length存放元素,插入的最后一个位置是数组尾部 if (i < 0 || i > L.length) return false; if (L.length >= L.capacity) { // 若顺序表已满 return false; // 则插入失败 // 若采用动态分配,则可以调用分配空间的函数进行扩展 // expandList(L); } for (int k = L.length; k > i; --k) // 从最后一个到第i个元素依次后移 L.data[k] = L.data[k - 1]; L.data[i] = e; // 第i个位置插入e L.length++; // 实际长度加1 return true; }提示:还记得动态分配存储空间可以扩展吗?当顺序表已满时,若存储空间是动态分配,则可以在扩展空间之后继续进行插入(如代码行号 9)。
根据插入位置的不同,顺序表插入元素所需要的时间成本如下几种情况:
·最好情况:插入位置在顺序表的表尾,作为顺序表的最后一个元素,那么不会执行后移语句,时间复杂度是 O (1);
·最坏情况:插入位置在顺序表的表头,那么后续所有元素都要进行后移操作,后移语句执行n次,时间复杂度是 O (n);
·平均情况:插入位置在顺序表的中间位置。设pi表示在第i个位置上插入一个结点的概率,那么pi=1/n,所以在具有n个结点的顺序表中插入结点时所需要移动的平均次数可以表示为:
因此,顺序表插入元素的平均时间复杂度是 O (n)。6.向一个有n个元素的顺序表中插入一个新元素,平均要移动 ( ) 个元素。
A. 1
B. 0
C. n/2
D. (n−1)/26.【参考答案】 C
【解析】 在第 1 个位置插入元素时,需要移动n个元素,在最后一个位置插入元素时,需要移动 0 个元素,因此平均需要移动[n+(n−1)+⋯+1+0]/(n+1)=n/2个元素。4.采用动态分配存储空间的顺序表,若已存放n个元素并存满存储空间,需要再存放m个元素,此时申请空间成功是说明线性表至少有 ( ) 个地址连续可分配的空闲空间。
A. m
B. m−n
C. n+m
D. n4.【参考答案】 C
【解析】 因为存储空间已满,要额外存放m个元素则至少需要m+n个地址连续的空间。申请新空间成功后,将原本的n个元素复制到新空间并存放后续m个元素。因此选 C。7.顺序表删除元素
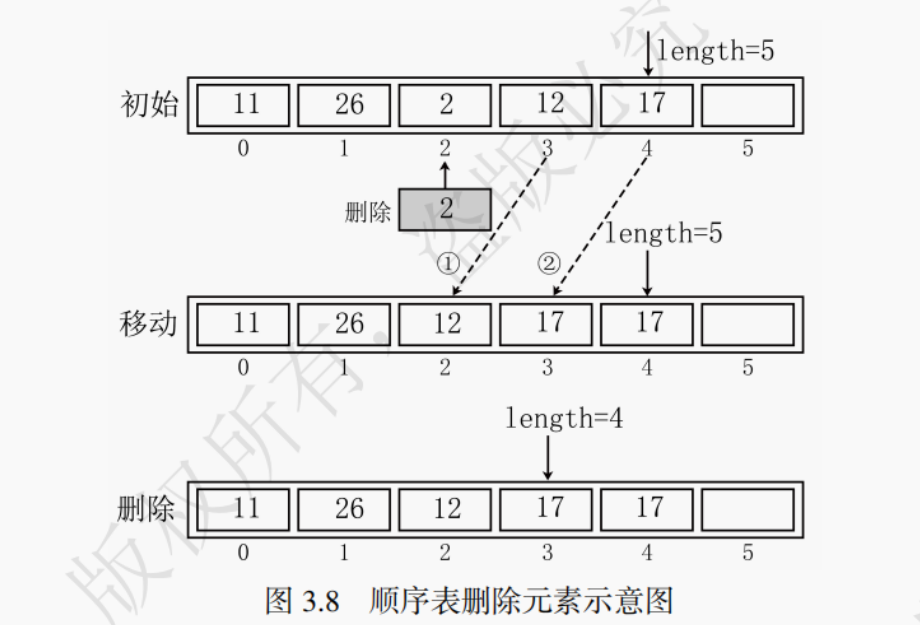
顺序表的元素删除相当于元素插入的逆过程,假设要删除第i个元素,需要将其后续元素整体向前移动一个单位,实现代码如下:
// 删除第i个位置的元素,用e记录被删除元素的值 // 成功返回true,否则返回false bool listDelete(SqList &L, int i, ElemType &e) { // 注意此处大于等于,这里设置length的位置是没有元素的 if (i < 0 || i >= L.length) return false; // i不合法,删除失败 e = L.data[i]; // 第i个位置的元素赋值给变量e for (int k = i + 1; k < L.length; ++k) // 从第i + 1个到最后一个元素依次前移 L.data[k - 1] = L.data[k]; L.length--; return true; }
在线性表中删除元素 2 的过程如图 3.8 所示。线性表初始长度 length 等于 5,将后续元素 12、17 整体向前移动一个单位,线性表长度 length 的值减 1 (length 等于 4)。虽然 4 号位置依然存放着 17,但线性表是逻辑存储空间,访问时由于 length 等于 4,在逻辑上无法访问 4 号位置的 17。
顺序表删除算法时间成本的计算方法如下:
·最好情况:删除位置在顺序表的表尾,即作为顺序表的最后一个元素,则不会执行前移语句,只需要线性表的长度进行减一操作即可,时间复杂度是 O (1);
·最坏情况:删除位置在顺序表的表头,则后续所有元素都要进行前移操作,前移语句执行n−1次,时间复杂度是 O (n);
·平均情况:删除位置在顺序表的中间位置,用pi=1/n表示在第i个位置上删除结点的概率,则在长度为n的顺序表中删除结点时,所需移动的平均次数可用如下公式表示:
因此,顺序表删除元素的平均时间复杂度是 O (n)。5.对于长度为n的顺序表,删除其中任何一个位置元素的概率相等。则删除一个元素时,平均需要移动 ( ) 个元素。
A. (n+1)/2
B. n/2
C. (n−1)/2
D. (n−2)/25.【参考答案】 C
【解析】 删除第 1 个元素时,需要移动n−1个元素,删除第 2 个元素时,需要移动n−2个元素,因此平均需要移动[(n−1)+(n−2)+⋯+1+0]/n=(n−1)/2个元素。8. 顺序表清空
顺序表的清空指将 length 置为 0,使得在逻辑上无法访问线性表中的其他元素。实现代码如下:
void clearList(SqList &L) { L.length = 0; }9. 顺序表判空
由数据表的置空操作可知,顺序表的判空实际就是判断 length 变量的值,当 length 为 0 时则顺序表为空。实现代码如下:
bool listEmpty(const SqList &L) { if (L.length == 0) return true; return false; }提示:本节对各个操作的时间复杂度进行了详细的讲解,在本章的后续小节中,各操作时间复杂度的运算方法和本节给出的基本相同,因此后续小节不进行详细计算。
3.2.3 习题精编
1.线性表的顺序存储结构是一种 ( ) 的存储结构。
A. 随机存取
B. 散列存取
C. 索引存取
D. 顺序存取1.【参考答案】 A
【解析】 线性表的顺序存储结构便是顺序表,同时顺序表是一种支持随机存取的存储结构。散列存取将在后面学习散列表时了解,索引存取是指通过查索引表进行索引。顺序存取是指可以从首元素开始遍历至需要存取的元素,因此顺序存储的线性表也是满足顺序存取的,但不能说这种存储结构就是顺序存取的存储结构,注意链表也是可以顺序存储的。2.(多选) 一个顺序表占用存储空间的大小与 ( ) 有关。
A. 表容量 capacity
B. 单个元素的长度
C. 表中元素数量
D. 元素的物理位置2.【参考答案】 A、B
【解析】 顺序表占用空间大小等于 capacity× 单个元素的长度,因为顺序表的空间是提前分配的,因此表中元素数量的多少不会影响存储空间,元素的物理位置也不会影响总空间的大小。3.在n个结点的线性表的数组实现中,算法的时间复杂性是 O (1) 的操作是 ( )。
A. 访问第i(1≤i≤n)个结点和求第i(2≤i≤n)个结点的直接前驱
B. 在第i(1≤i≤n)个结点后插入一个新结点
C. 删除第i(1≤i≤n)个结点
D. 以上都不对3.【参考答案】 A
【解析】 顺序表支持随机访问,因此访问任意位置元素的时间复杂度都是 O (1),直接前驱只需要访问i−1的位置。顺序表插入与删除结点需要进行元素的移动,因此操作复杂度为 O (n),故 B、C 错。4.采用动态分配存储空间的顺序表,若已存放n个元素并存满存储空间,需要再存放m个元素,此时申请空间成功是说明线性表至少有 ( ) 个地址连续可分配的空闲空间。
A. m
B. m−n
C. n+m
D. n4.【参考答案】 C
【解析】 因为存储空间已满,要额外存放m个元素则至少需要m+n个地址连续的空间。申请新空间成功后,将原本的n个元素复制到新空间并存放后续m个元素。因此选 C。5.对于长度为n的顺序表,删除其中任何一个位置元素的概率相等。则删除一个元素时,平均需要移动 ( ) 个元素。
A. (n+1)/2
B. n/2
C. (n−1)/2
D. (n−2)/25.【参考答案】 C
【解析】 删除第 1 个元素时,需要移动n−1个元素,删除第 2 个元素时,需要移动n−2个元素,因此平均需要移动[(n−1)+(n−2)+⋯+1+0]/n=(n−1)/2个元素。6.向一个有n个元素的顺序表中插入一个新元素,平均要移动 ( ) 个元素。
A. 1
B. 0
C. n/2
D. (n−1)/26.【参考答案】 C
【解析】 在第 1 个位置插入元素时,需要移动n个元素,在最后一个位置插入元素时,需要移动 0 个元素,因此平均需要移动[n+(n−1)+⋯+1+0]/(n+1)=n/2个元素。3.2.4 真题演练
7.【2010】设将n(n>1)个整数存放到一维数组R中。试设计一个在时间和空间两方面都尽可能高效的算法。将R中保存的序列循环左移p(0<p<n)个位置,即将R中的数据由(X0,X1,⋯,Xn−1)变换为(Xp,Xp+1,⋯,Xn−1,X0,X1,⋯,Xp−1)。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键之处给出注释;
(3) 说明你所设计算法的时间复杂度和空间复杂度。7.【参考答案】
(1) 可以先将(X0,X1,⋯,Xn−1)倒置,变为(Xn−1,Xn−2,⋯,X0),之后找到Xp的位置,分别将两边倒置,即(Xn−1,Xn−2,⋯,Xp)倒置变为(Xp,Xp+1,⋯,Xn−1),(Xp−1,Xp−2,⋯,X0)倒置变为(X0,X1,⋯,Xp−1),经过两次倒置就能达成目的。
(2) 代码实现如下:// start和end表示需要倒置的开始位置和结束位置 void reverse(int R[], int start, int end) { int temp; // 作为交换的临时变量 // 将首尾位置的元素交换 for (int i = 0; i < (end - start + 1)/2; i++) { temp = R[start + i]; R[start + i] = R[end - i]; R[end - i] = temp; } } void move(int R[], int p, int n) { reverse(R, 0, n - 1); reverse(R, 0, n - p - 1); reverse(R, n - p, n - 1); }(3) 时间复杂度为 O (n),空间复杂度为 O (1)。
8.【2011】一个长度为L(L≥1)的升序序列S,处在第⌊L/2⌋个位置的数称为S中位数。例如,若序列S1=(11,13,15,17,19),则S1的中位数是 15。两个序列的中位数是含它们所有元素的升序序列的中位数。例如,若S2=(2,4,6,8,20),则S1和S2的中位数是 11。现有两个等长的升序序列A和B。试设计一个在时间和空间两方面都尽可能高效的算法,找出两个序列A和B的中位数。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键处给出注释;
(3) 说明你所设计算法的时间复杂度和空间复杂度。8. 【参考答案】
(1) 先分别求出A和B的中位数,设为m1和m2。(1)若m1=m2,则m1或m2即为所求;(2)若m1<m2,令A为A中较大的一半,令B为B中较小的一半;(3)若m1>m2,令B为B中较大的一半,令A为A中较小的一半。重复过程,直到m1=m2或两个序列中只含一个元素时为止,较小者即为所求。
(2) 代码实现如下:int middle(int A[], int B[], int n) { // 分别是本轮搜索中A、B的起始位置和结束位置 int start1 = 0, end1 = n - 1, start2 = 0, end2 = n - 1; int m1, m2; // 本轮搜索中A、B的中位数 // 直到一个数组被遍历完 while (start1 != end1 || start2 != end2) { m1 = (start1 + end1)/2, m2 = (start2 + end2)/2; if (A[m1] == B[m2]) {return A[m1];} // 满足情况(1) else if (A[m1] < B[m2]) { // 满足情况(2) // 考虑奇偶为保证子数组元素个数相同 if ((start1 + end1) % 2 == 0) { start1 = m1; end2 = m2; } else { start1 = m1 + 1; end2 = m2; } } else { // A[m1] > B[m2],满足情况(3) // 考虑奇偶为保证子数组元素个数相同 if ((start1 + end1) % 2 == 0) { end1 = m1; start2 = m2; } else { end1 = m1; start2 = m2 + 1; } } } // 返回较小的 return A[start1] < B[start2] ? A[start1] : B[start2]; }9.【2013】已知一个整数序列A=(a0,a1,a2,⋯,an−1),其中0≤ai<n(0≤i<n)。若存在ap1=ap2=⋯=apm=x且m>n/2(0≤pk<n,1≤k≤m),则称x为A的主元素。例如A=(0,5,5,3,5,7,5,5),则 5 为主元素;又如A=(0,5,5,3,5,1,5,7),则A中没有主元素。假设A中的n个元素保存在一个一维数组中,请设计一个尽可能高效的算法,找出A的主元素。若存在主元素,则输出该元素;否则输出 -1。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 或 Java 语言描述算法,关键之处给出注释;
(3) 说明你所设计算法的时间复杂度和空间复杂度。(3) 时间复杂度为 O (logn),空间复杂度 O (1)。
9. 【参考答案】
(1) 定义变量 majorElem 暂存主元素,变量 count 记录 majorElem 出现次数。遍历序列,每当遍历到下一个元素 cur 时,若 cur = majorElem,则将 count 加一;若 cur≠majorElem,则将 count 减一;若 count 为 0,则将下一个遇到的不等于 majorElem 的 cur 赋值给 majorElem,令 count 为 1,也就是更换了扫描到当前位置的候选主元素,直至遍历完整个序列。由于主元素需要总数大于n/2,此时再遍历一次数组,统计 majorElem 出现的次数,判断其是否为主元素。
(2) 代码实现如下:int findMajorElem(int A[], int n) { int majorElem = A[0], count = 1; // 初始化时令候选主元素先为数组的首元素 for (int i = 1; i < n; i++) { if (A[i] == majorElem) { //若相等则count加一 count++; } else { count--; if (count == 0) { //若不相等,则判断count是否为0 majorElem = A[i]; count = 1; } } } if (count <= 0) { //若count小于等于0说明不可能有主元素 return -1; } count = 0; for (int i = 0; i < n; i++) { //统计候选主元素个数 if (A[i] == majorElem) { count++; } } if (count > n/2) { return majorElem; } else { return -1; } }(3) 时间复杂度为 O (n),空间复杂度为 O (1)。
【真题出处】LeetCode 上有道类似的题,与此题稍有不同,感兴趣的考生可以动手练习下:. - 力扣(LeetCode)- element/description/
10.【2018】给定一个含n(n≥1)个整数的数组,请设计一个在时间上尽可能高效的算法,找出数组中未出现的最小正整数。例如,数组{−5,3,2,3}中未出现的最小正整数是 1;数组{1,2,3}中未出现的最小正整数是 4。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释;
(3) 说明你所设计算法的时间复杂度和空间复杂度。10. 【参考答案】
(1) 由于含n个整数的数组中最小未出现的正整数不会超过n+1,只需要用一个辅助数组S[n+2]记录k是否出现过即可,S[k]=1表示k在原数组中出现过,S[k]=0表示未出现过。遍历完原数组后只需再次遍历S查找最小未出现整数即可。
(2) 代码实现如下:int findMissMin(int A[], const int n) { int S[n + 2] = {0}, i; // 辅助数组 // 记录A中元素是否出现过 for (i = 0; i < n; ++i) { if (A[i]>0 && A[i]<=n) { S[A[i]] = 1; } } // 从1开始遍历是因为0不是正整数 for (i = 1; i <= n + 1; ++i) { if (S[i] == 0) { break; } } return i; }(3) 算法的时间复杂度为 O (n),空间复杂度为 O (n)。
11.【2020】定义三元组(a,b,c)(a,b,c均为整数)的距离D=∣a−b∣+∣b−c∣+∣c−a∣。给定 3 个非空整数集合S1,S2,S3,按升序分别存储在 3 个数组中。请设计一个尽可能高效的算法,计算并输出所有可能的三元组(a,b,c)(a∈S1,b∈S2,c∈S3)中的最小距离。例如S1=(−1,0,9),S2=(−25,−10,10,11),S3=(2,9,17,30,41),则最小距离为 2,相应的三元组为(9,10,9)。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释;
(3) 说明你所设计算法的时间复杂度和空间复杂度。11. 【参考答案】
(1) 使用 minDis 记录当前的最小距离,由于 S1,S2,S3 按升序排列,遍历三个数组,计算当前三元组(A[i],B[j],C[k])的距离d。若d<minDis,令minDis=d,将(A[i],B[j],C[k])中最小的数的下标加一,重复之前步骤直到遍历结束。
(2) 代码实现如下:int findMin(int A[], int n, int B[], int m, int C[], int p) { int i = 0, j = 0, k = 0, d, minDis = INT_MAX; // 初始min赋一个最大值 while (i < n && j < m && k < p) { d = fabs(A[i] - B[j]) + fabs(B[j] - C[k]) + fabs(A[i] - C[k]); minDis = d < minDis ? d : minDis; // 动态更新minDis if (A[i] == min({A[i], B[j], C[k]})) { ++i; } else if (B[j] == min({A[i], B[j], C[k]})) { ++j; } else { ++k; } } return minDis; }(3) 设n为三个数组中元素数量的总和,时间复杂度为 O (n),空间复杂度为 O (1)。
3.3 线性表的链式存储
顺序表需要占用一块连续的存储空间,通过元素间的物理存储位置来体现相邻元素之间的逻辑关系,存储空间利用率较低。而线性表的链式表示不需要逻辑上相邻的元素在物理上也相邻,而是由指针来体现相邻元素之间的逻辑关系,能提高存储空间的利用率。
3.3.1 单链表的定义
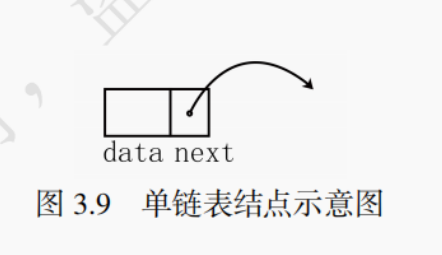
链表(Linked List)通常用指针来实现,指每个存储结点包含指针域和数据域。数据域存放数据元素本身的信息,指针域存放表示数据元素间逻辑关系的信息 ³。与顺序表不同,链表不限制数据的物理存储分布,即使用链表存储的数据元素,其存储位置是随机的。按照链表中指针域的数量可分为:单链表、双链表、循环单链表、循环双链表等。
如图 3.9 所示,每一个结点只含有一个指针域的链表称为单链表。双链表、循环单链表、循环双链表等都是基于单链表进行扩充。
由于单链表结点间存在链接关系,因此每一个结点根据其指针域都能找到其直接后继,从而只要知道第一个结点的位置,就能顺序查找到所有结点。通常,用头指针L(有时也用head表示头指针),指出链表的起始位置。链表的最后一个结点的指针域指向NULL。
说明:在本书的示意图中都用∧表示空指针NULL。
要注意链表头结点与首结点概念的区别,如图 3.10 所示:头结点一般不存储数据(也可存储链表的长度信息),为了方便实现单链表的相关操作,可以将其放在单链表的第一个位置。首结点是指真正存放元素的起始结点(例如a0),尾结点是单链表最后的结点。链表中有头结点时,头指针指向头结点;反之,若链表中没有头结点,则头指针指向首结点。
提示:引入头结点是为了在链表首结点上的操作与其他结点一致,下文的代码讲解将会详细解释这一点。
3.单链表中,增加一个头结点的目的是 ( )。
A. 使单链表至少有一个结点
B. 标识表中首结点的位置
C. 方便运算的实现
D. 说明单链表是线性表的链式存储3.【参考答案】 C
【解析】 头结点是为了操作的统一、方便而设计的。单链表可以为空,故 A 错。没有头结点也可用头指针标识首结点,故 B 错。单链表是不是链式存储和有无头结点没有关系,故 D 错。单链表结点的 C 语言代码如下:
typedef struct LinkNode { ElemType data; // 代表数据域 struct LinkNode *next; // 代表指针域,指向直接后继元素 } LinkNode, *LinkList; // 结构别名注意:①next是一个指针,指向后继结点的地址;②LinkList与LinkNode∗是等价的:通常用LinkList表示单链表的头指针,LinkNode∗表示单链表结点的指针变量;③单链表是由头指针唯一确定,因此单链表可以用头指针的名字来命名。若头指针名是L,则简称该链表为表L。
3.3.2 单链表基本操作的实现
本节将详细给出单链表中各个基本操作的代码,各位考生需充分理解每行代码的含义,手动模拟代码的执行步骤。但不需要死记硬背,需要结合具体的题目多练习,并能够在具体的题目中灵活运用。学完本节内容,建议考生将本书专项练习章节链表这一小节(第 443 页)的习题做一遍。
1. 单链表初始化
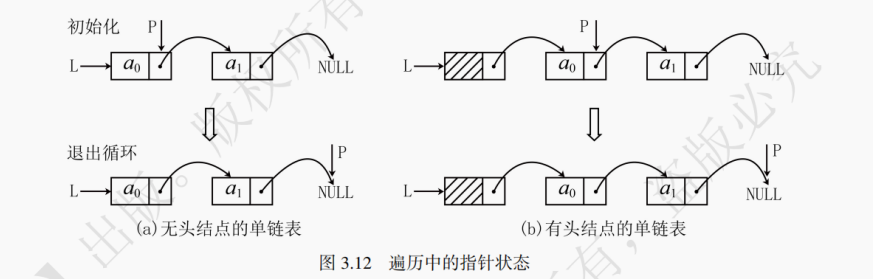
如图 3.11 所示,无头结点和有头结点的单链表的初始状态是不同的。
有头结点和无头结点的单链表初始化代码如下:
注意:头结点一般不记录任何数据,但这里用其来记录单链表的长度,在后续的单链表求表长时便会提到这种方式的好处。// 有头结点的单链表初始化 void initialize(LinkList &p) { p = (LinkNode*)malloc(sizeof(LinkNode)); // 创建头结点 p->next = NULL; // 初始为空链表 p->data = 0; // 记录链表长度 } // 无头结点的单链表初始化 void initialize(LinkList &p) { p = NULL; // 直接指向NULL,初始为空链表 } // 显式调用初始化函数 LinkList p; initialize(p);对于一个有头结点的空单链表,若变量p为指针,∗p则表示结点本身,也就是 LinkNode 结构体。若要访问∗p这个结点的内部元素data和next,可以采用(∗p).data和(∗p).next的方式。
说明:(∗p).data和(∗p).next,加上括号是因为成员运算符 “.” 比指针运算符 “*” 的优先级要高,就像乘法和加法在不加括号的情况下乘法会先计算一样。
相对于上述用法,当p为指针时,指向运算−>更常用:p−>data和(∗p).data所表达的含义是完全相同的。通过(∗p).next可以得到指向下一个结点的指针,因此(∗(∗p).next).data就是下一个结点中存放的数据,可以简化为p−>next−>data,而(∗(∗p).next).next可以简化为p−>next−>next,其代表指向p结点的下下一个结点的指针。
提示:结构体成员运算符 (.) 和指向运算符 (−>) 的区别:成员运算符 (.) 左边的操作数是一个普通的结构体变量,而指向运算符 (−>) 左边是一个指向结构体的指针。
在本章之后的讲解中,若没有特别指出,指向p结点的指针将直接用p结点来描述,采用这种方式更简便。也可以将NULL视为一个结点,这有助于理解后面的操作,空链表就是以NULL为首结点的链表。
2. 单链表求表长
在单链表中,若没有使用变量记录单链表的长度,如以下代码所示,若要获得单链表的长度则需要遍历整个单链表。
int listLength(LinkList L) { // 在初始化的时候要将p指针指向首结点(可能是NULL) // LinkNode *p = L; // 无头结点的情况 LinkNode *p = L->next; // 有头结点的情况 int k; for (k = 0; p != NULL; ++k) // 当结点为NULL时退出循环 p = p->next; return k; // 退出循环时这就是表长 }
该操作的时间复杂度很好理解,循环遍历整个单链表,其时间复杂度为 O (n)。但对于有头结点的单链表而言,如果使用头结点中的数据域记录单链表的长度,便能以 O (1) 的时间复杂度获得单链表的长度,只需要在每次插入和删除元素时维护长度变量即可。
3. 单链表按序号查找
单链表的按序号查找与顺序表的按序号查找不同,由于单链表不支持随机存取,所以只能从头结点开始遍历,直到找到目标结点,该操作的平均时间复杂度为 O (n)。代码实现如下:
LinkNode* getElem(LinkList L, int k) { // LinkNode *p = L; // 无头结点的情况 LinkNode *p = L->next; // 有头结点的情况 for (int i = 0; i < k && p != NULL; i++) { p = p->next; } // 若p为NULL,说明输入的k超过链表的长度,查找失败 if (p == NULL) { return ERROR_ELEM; } // ERROR_ELEM表示结果没有意义 return p; }【提示】对于链表而言,若要获取该结点里面的数据 (p−>data),而不是整个结点,此时可以返回 (p−>data)。
2.将长度为 n 的单向链表链接在长度为 m 的单向链表之后的算法时间复杂度为 ( )。
A. O (1)
B. O (n)
C. O (m)
D. O (m + n)2.【参考答案】 C
【解析】 需要找到长度为 m 的链表的尾结点再将链表接上,找到尾结点的复杂度为 O (m),接上的耗时为 O (1),因此复杂度为 O (m)。4. 单链表按值查找
单链表按值查找和顺序表的按值查找相似,都需要遍历每个结点进行比较,其平均时间复杂度为 O (n)。代码实现如下:
int locateElem(LinkList L, ElemType e) { LinkNode* p = L->next; // 有头结点的情况。若无头结点,则:LinkNode* p = L; for (int k = 0; p != NULL; ++k) { // 直到找到链表结尾再停止 if (p->data == e) { return k; } // 也可以返回结点本身而不是其位置 p = p->next; } return -1; // 说明没有找到 }5. 单链表遍历输出
遍历输出是单链表基本操作中较为简单的操作,408 考试一般不会直接考查,但遍历操作在各种算法的实现中都会有所体现。代码实现如下:
void listVisit(LinkList L) { // LinkNode *p = L; // 无头结点的情况 LinkNode *p = L->next; // 有头结点的情况 for (; p != NULL; p = p->next) { //这里假设ElemType为int。具体应用时根据实际情况修改输出数据类型 printf("%d ", p->data); } }6.将两个长度为 n 的有序链表归并成一个有序表,最少比较 ( ) 次。
A. n
B. 2n - 1
C. 2n
D. n - 16.【参考答案】 A
【解析】 因为两个链表都是有序的,当一个链表遍历到结尾时只需将没遍历完的接在后面即可。假设链表 A 中的所有元素都小于链表 B 中的元素,则将链表 A 中的每个元素和 B 的第一个元素比较,只需比较 n 次便可将 A 中元素遍历完,剩下只需将 B 接在 A 的后面即可。6. 单链表插入元素
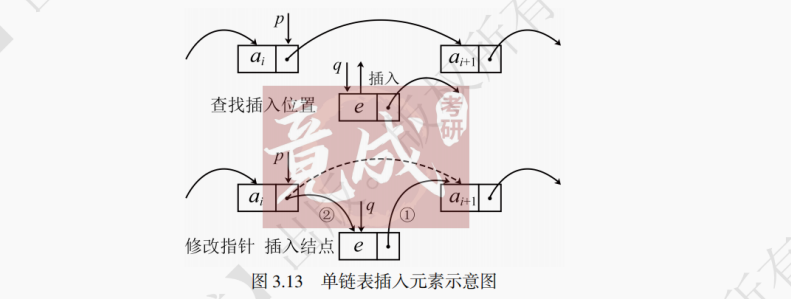
如图 3.13 所示,在两个相邻结点ai和ai+1之间插入新结点e的步骤如下:
(1) 找到结点ai,将结点ai的地址赋值给变量p。
(2) 将新结点e的地址赋值给变量q,让变量q的next指针指向结点ai+1 (p−>next指向ai+1)。
(3) 将变量p的next指针指向变量q。
需要注意的是,在有头结点和没有头结点的链表的首位置插入元素是有区别的。
9.在一个单链表中,已知 q 指向结点是 p 指向结点的前驱结点,若在 q 指向结点和 p 指向结点之间插入 s 指向结点,则需执行 ( )。
A. s->next=p->next; p->next=s;
B. q->next=s; s->next=p;
C. p->next=s->next; s->next=p;
D. p->next=s; s->next=q;9.【参考答案】 B
【解析】 本题考查单链表的插入操作,只需注意在插入操作时不要让链表 “断开” 即可。1.在一个单链表中,若 p 所指的结点不是最后一个结点,在 p 之后插入 s 所指的结点,则需要执行 ( )。
A. s->next=p; p->next=s;
B. p->next=s; s->next=p;
C. p=s; s->next=p->next;
D. s->next=p->next; p->next=s;1.【参考答案】 D
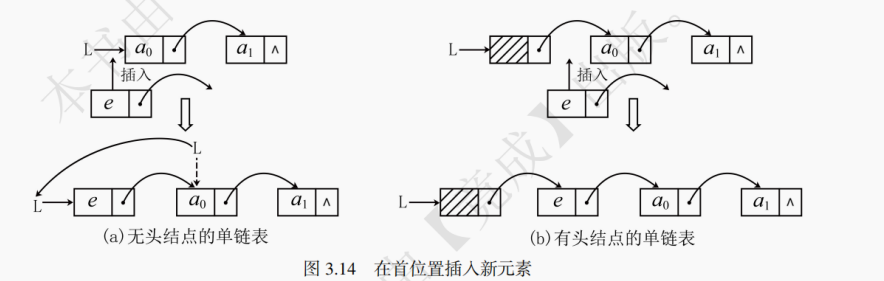
【解析】 为了防止链表 “断开”,应先执行 s->next=p->next; 让 p 的后继结点成为 s 的后继结点,再执行 p->next=s; 让 s 成为 p 的后继结点。如图 3.14 所示,如果链表有头结点,在 “首位置” 插入结点的过程与在链表 “中间” 插入结点的过程相同。而对于没有头结点的单链表而言,在首位置插入结点需要特殊处理,因为在无头结点链表的首位置插入结点会导致链表的头指针发生变化(如图 3.14-(a) 中的虚线部分)。
单链表插入元素的代码如下:
// 有头结点的单链表插入 bool listInsert(LinkList L, int i, ElemType e) { LinkNode *p = L->next; for (int j = 0; j < i; ++j) { p = p->next; // 循环找到插入位置 if (p == NULL) return false; // 插入位置错误 } LinkNode *q = (LinkNode*)malloc(sizeof(LinkNode)); q->data = e; // 新结点数据域赋值 q->next = p->next; // 先赋值新结点的next指针 p->next = q; // 再赋值前一个结点的next指针 return true; } // 无头结点的单链表插入 bool listInsert(LinkList L, int i, ElemType e) { LinkNode *p = L; // 相同的查找第i个结点位置流程,相同的新结点q赋值数值e,略 if (i == 0) { // 若在首位置插入结点则头指针会发生变化 q->next = p; L = q; // 头指针指向q } else { // 其他情况同有头结点的一样 q->next = p->next; p->next = q; } return true; }有头结点和无头结点的单链表在插入前要先通过 for 循环找到待插入位置的前一个结点(前驱),例如在第 0 个位置插入结点则要找第 - 1 个结点。可以将头结点理解为第 - 1 个结点,因为在逻辑上,头结点处于首结点的前驱位置。而无头结点只能找到第 0 个结点,对于这种情况,需要修改循环初始条件,参考上述第 18 - 20 行代码。
单链表按序号插入元素的开销都集中在遍历查找i−1个结点上,算法的平均时间复杂度为 O (n)。
5.将一个元素插入长度为 n 的有序单链表中,如果插入元素之后,单链表仍保持有序,则该插入操作的时间复杂度为 ( )。
A. O (1)
B. O (n²)
C. O (logn)
D. O (n)5.【参考答案】 D
【解析】 在单链表有序的情况下,假设以 p 指针作为遍历搜索的指针,只要搜索到某结点 p 满足 “新元素的值被夹在 p 和 p->next 之间”,就可以将新元素插到这之间,因此只需要一次遍历就可完成,操作复杂度为 O (n)。注意:实际的链表操作大多是在给定的结点(也就是传入LinkNode∗,而不是下标i)后插入新元素,相当于直接给出了待插入位置p,省去遍历的开销,该操作的时间复杂度为 O (1)。
此外,若在给定的结点前插入元素,则可以先将元素插入给定结点的后方,再交换两个结点的数据域,同样有 O (1) 的时间复杂度。
同理,若删除给定的结点元素(非链表尾结点),则可先将该结点的下一个结点元素值复制到本结点,然后直接删除下一个结点即可,此时的时间复杂度是 O (1)。但待删除结点是链表尾结点时,next指针为NULL,必须常规地删除该结点:需要重新遍历链表寻找倒数第二个结点,然后将倒数第二个结点的next指针置空,达到删除的效果。
思考:为什么要先操作新结点的next指针,如果先操作p的next指针会怎么样?
在单链表插入元素时,需要先操作新结点 q 的 next 指针,再操作 p 的 next 指针。这是为了防止链表在插入过程中出现 “断开” 或丢失后续结点的情况。
假设现在要在结点 p 之后插入新结点 q ,若先操作 p 的 next 指针,即执行 p->next = q; ,此时 p 的 next 指针指向了新结点 q , q 的 next 指针还未进行初始化,它的值是不确定的(一般是一个随机值)。接下来再执行 q->next = p->next; ,由于 p->next 已经指向了 q ,所以 q->next 会再次指向 q 自身,这样就会导致链表后续的结点无法访问,链表出现 “断开” 的情况。
而先操作新结点 q 的 next 指针,即执行 q->next = p->next; ,可以保证新结点 q 的 next 指针指向 p 的原后继结点,这样就不会丢失链表后续的结点。然后再执行 p->next = q; ,将 p 的 next 指针指向新结点 q ,完成插入操作,链表仍然保持连续,后续的结点可以正常访问。
例如,有一个链表 A -> B -> C ,现在要在结点 A 之后插入新结点 D 。如果先执行 A->next = D; ,此时链表变为 A -> D , D 的 next 指针未初始化。接着执行 D->next = A->next; , D 的 next 指针会再次指向 D 自身,链表变为 A -> D -> D ,结点 B 和 C 就无法访问了。而如果先执行 D->next = A->next; ,此时 D 的 next 指针指向 B ,链表变为 A -> B ( D 的 next 指向 B )。再执行 A->next = D; ,链表变为 A -> D -> B -> C ,插入操作成功完成,链表仍然保持连续。
因此,在单链表插入元素时,必须先操作新结点的 next 指针,再操作 p 的 next 指针,以确保链表的连续性和正确性。
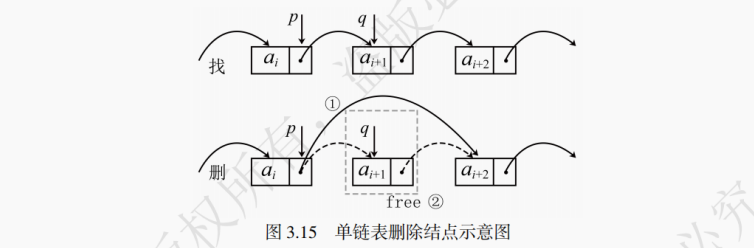
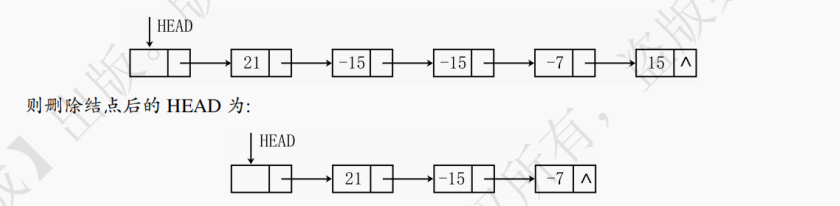
7. 单链表删除元素
在无头结点的单链表中删除首结点的操作是和其他结点不同的,此处给出的是删除中间结点的步骤。如图 3.15 所示,ai、ai+1、ai+2是三个彼此相邻的结点,要删除ai+1,操作步骤如下:
(1) 找到要删除的结点ai+1,将ai+1赋值给变量q。将ai+1的前驱结点ai,赋值给变量p。
(2) 将找到的前驱结点ai的next指针指向要删除结点的后继结点ai+2。
(3) 释放被删除结点ai+1的空间。
单链表删除元素的平均时间复杂度为 O (n)。
思考:为什么第一步不找要删除的结点,而是找了前一个结点?
在单链表中删除结点时,需要修改被删除结点前驱结点的 `next` 指针,使其指向被删除结点的后继结点,从而将被删除结点从链表中 “摘除”。如果直接找到要删除的结点,由于单链表的结点中只保存了后继结点的指针,无法直接获取到前驱结点的指针,也就无法修改前驱结点的 `next` 指针。而先找到前驱结点,就可以很方便地通过前驱结点的 `next` 指针来操作,实现删除结点的功能。例如,有链表 `A -> B -> C` ,要删除结点 `B` ,如果只找到 `B` ,无法直接修改 `A` 的 `next` 指针;但如果先找到 `A` ,就可以通过 `A->next = B->next` ,将 `A` 的 `next` 指针指向 `C` ,完成对 `B` 的删除。
单链表删除元素的代码如下:
// 有头结点的单链表删除 bool listDelete(LinkList &L, int i, ElemType &e) { // 获取第i - 1个结点的位置,此处getElem的返回值为结点的指针 LinkNode *p = getElem(L, i - 1); // 若getElem返回的是最后一个结点,表示要删除最后一个结点的后继结点,则返回错误 if (p->next == NULL) return false; // 删除位置错误 LinkNode *q = p->next; // 指向要被删除的结点 e = q->data; p->next = q->next; free(q); return true; } // 无头结点的单链表删除 bool listDelete(LinkList &L, int i, ElemType &e) { LinkNode *p = L; // 相同的查找第i - 1个结点位置流程,略 // 删除位置错误 if (i != 0 && p->next == NULL) return false; // 如果是删除首结点则头指针将会发生变化 if (i == 0) { L = p->next; // 头指针指向p的next结点 e = p->data; free(p); } else { // 其他情况同有头结点的一样 LinkNode *q = p->next; // 指向要被删除的结点 e = q->data; p->next = q->next; free(q); } return true; }思考:为什么在无头结点的程序中第 27 行,if 判断相比于有头结点的第 10 行需要加上一个条件?(模拟删除只有一个结点的无头结点单链表时会发生的情况)
在有头结点的单链表中,头结点始终存在,删除操作时判断 `p->next == NULL` 就可以确定是否要删除最后一个结点的后继结点(因为头结点的存在,`p` 不可能为空)。而在无头结点的单链表中,链表可能为空,或者只有一个结点。当链表只有一个结点时,若要删除该结点(即 `i == 0` 时),如果只判断 `p->next == NULL` ,就无法区分是链表本身为空(此时 `p == NULL` )还是只有一个结点的情况。加上 `i != 0` 这个条件,就可以在 `i != 0` 且 `p->next == NULL` 时,确定是要删除最后一个结点的后继结点(此时删除位置错误);而当 `i == 0` 时,单独处理删除首结点的情况,因为删除首结点会导致头指针发生变化。例如,对于只有一个结点的无头结点单链表 `A` ,当要删除这个结点( `i == 0` )时,如果不加上 `i != 0` 这个条件,`p->next == NULL` 会被误判为删除位置错误,而实际上是可以删除的,只是需要修改头指针。加上这个条件后,就可以正确处理这种情况了。
提示:在单链表中,插入和删除第i个结点时,都需要通过循环找到第i−1个结点,因此两个操作在循环部分是相同的。而在题目中有可能会将第i−1个结点的指针p直接给出,这样就省去了循环查找第i−1个结点的过程,插入 / 删除的时间复杂度就变为了 O (1)。
7.在一个单链表中,若 p 所指的结点不是最后一个结点,删除 p 之后结点,则执行 ( )。
A. p->next=p;
B. p->next->next=p->next;
C. p->next->next=p;
D. p->next=p->next->next;7.【参考答案】 D
【解析】 删除 p 之后结点,因题中没有 free 的要求,只需将 p 的 next 指针指向其后继结点的 next 指针即可,因此执行 “p->next=p->next->next;”。8. 单链表置空
思考:单链表的空表是什么样?可以通过 initList 来获得一个空表吗?
对于单链表,只要将其首结点变为NULL,它便是一个空表。但在实际运用中,还需要注意的是要将之前分配的所有结点空间释放,以防止内存泄漏。该算法的时间复杂度为 O (n),其开销在于循环遍历释放结点空间。代码实现如下:
void clearList(LinkList &L) { // LinkNode *p = L; // 没有头结点 LinkNode *p = L->next; // 有头结点 while (p != NULL) { LinkNode *temp = p->next; // 临时指针保存p的next结点 free(p); // 释放p结点 p = temp; // p指向p的next结点 } L->next = NULL; // 有头结点 // L = NULL; // 没有头结点 }要用临时指针保存p结点的next结点是因为p结点的空间被释放后,就无法通过p−>next的形式访问下一个结点了,单链表就 “断” 了。
注意:此处带头结点的单链表可以不传指针,这是因为头指针没有发生变化,无需进行修改。
9. 单链表判空
类似于单链表置空操作,单链表判空只需要判断首结点是否为NULL即可,该算法时间复杂度为 O (1)。实现代码如下:
bool listEmpty(LinkList L) { // LinkNode *p = L; // 没有头结点 LinkNode *p = L->next; // 有头结点 if (p == NULL) return true; return false; }提示:算法的时间复杂度不用死记硬背,两段功能相同的代码可能因为一些细小的不同,导致时间复杂度发生巨大的变化,只有弄清楚每个算法的开销在哪几条语句上,才能举一反三。比如在本节中某些算法的时间复杂度为 O (n) 的 “罪魁祸首” 就是循环,因为要通过循环遍历找到所需的结点。但如果题目给出了该结点,就省去了循环遍历找到结点的开销,因此时间复杂度变为 O (1)。
思考:在没有指针类型的编程语言中,要怎么表示链表呢?
10. 静态链表
线性链表也可以用数组来描述,并称其为静态链表,主要在没有指针类型的程序设计语言中使用。
(1) 首先,静态链表在分配内存空间时会申请一块地址连续的存储空间;
(2) 其次,静态链表是没有指针的,它使用游标(后继结点的数组下标)来充当指针。静态链表的代码实现如下:
typedef struct { ElemType data; // 数据域 int cur; // 游标 } StaticList[MAX_SIZE];静态链表将单链表中的指针换成了一个 “假指针”,即游标,用 “假指针” 记录数组下标,从而起到代替指针的作用。不足之处在于 “假指针” 没有指向内存空间的能力,所以只能将数据存放在 “假指针” 能够 “指向” 的数组空间里。
3.3.3 单链表的一些其他算法
除了上面介绍的一些基本算法,单链表还有一些常用算法,如头插法、尾插法、原地倒置、双指针遍历等。它们在考试中也经常出现,本节将会挑选一部分进行讲解。本节是对上节基本操作的运用与拓展,提供了链表相关算法大题的一些解题思路,具体算法大题的练习见本书的专项练习章节。
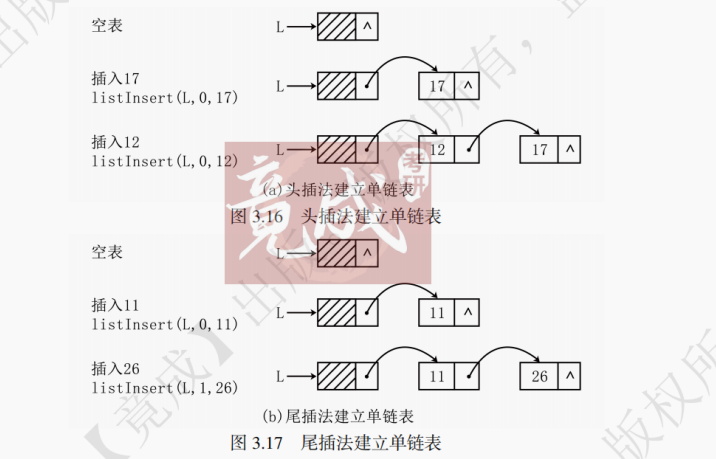
1. 头插法和尾插法建立单链表
如图 3.16、图 3.17 所示,头插法与尾插法的区别在于新元素的插入位置,头插法将新元素插入链表的头部,而尾插法将新元素插入链表的尾部。头插法还可以用来实现链表的倒置,在遍历原链表的同时采用头插法,将访问到的元素插入新的链表中,这样获得的链表就是原链表的倒置。
头插法每次插入元素的时间复杂度为 O (1),因为在第一个位置插入不需要使用 for 循环,减少了查找元素的开销。而尾插法每次插入元素的时间复杂度 O (n),因为每次都需要遍历找到最后一个元素,再进行插入。
头插法调用本章第一节中声明的listInsert(L,0,e)即可,表示在链表L的首位置插入元素e。尾插法需要用变量i记录链表的长度,调用listInsert(L,i,e),每次在链表的第i个位置插入元素e。
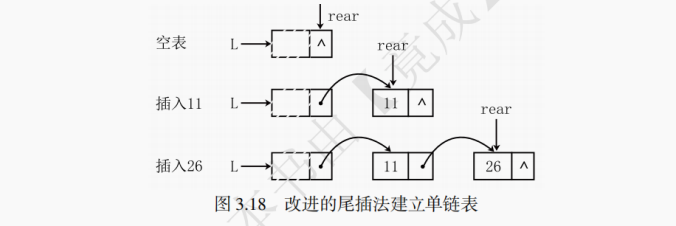
尾插法还有改进版本。如图 3.18 所示,用一个指针rear永远指向链表的最后一个元素,这样省去了查找尾部元素的时间开销(因为尾插法每次都在尾部插入元素),每次插入的时间复杂度也变为了 O (1)。
注意:如果采取尾指针的形式,每次插入一个元素,尾指针都要发生变化。
4.在一个有尾指针的无头结点单链表上,则下列与表长有关的操作是 ( )。
A. 删除头指针所指的元素
B. 删除尾指针所指的元素
C. 在单链表第一个元素前插入一个元素
D. 在单链表最后一个元素后插入一个元素4.【参考答案】 B
【解析】 和表长有关的操作是需要遍历整表的,删除头指针所指的元素不需要,故 A 错。在单链表第一个元素前插入也不需要,故 C 错,这两个操作都可以通过头指针很简单的完成。在单链表最后一个元素后插入元素也可通过尾指针完成,故 D 错。但删除尾指针所指的元素需要将尾指针移至前驱结点上,在单链表上只能通过遍历整表的方式获得结点的前驱结点,因此 B 与表长有关。2. 原地倒置单链表
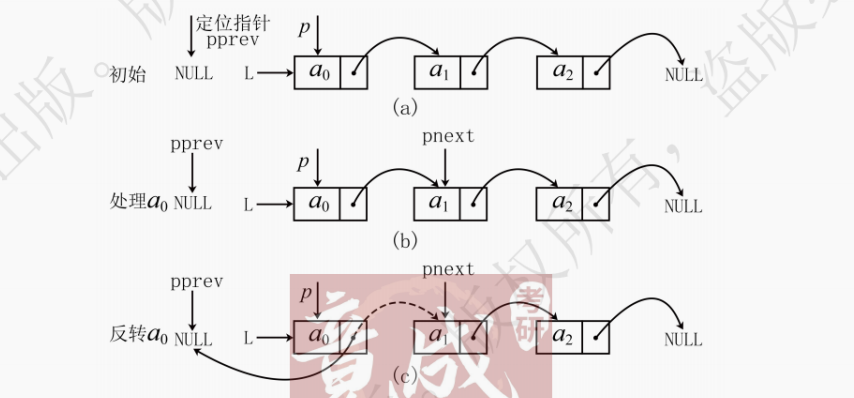
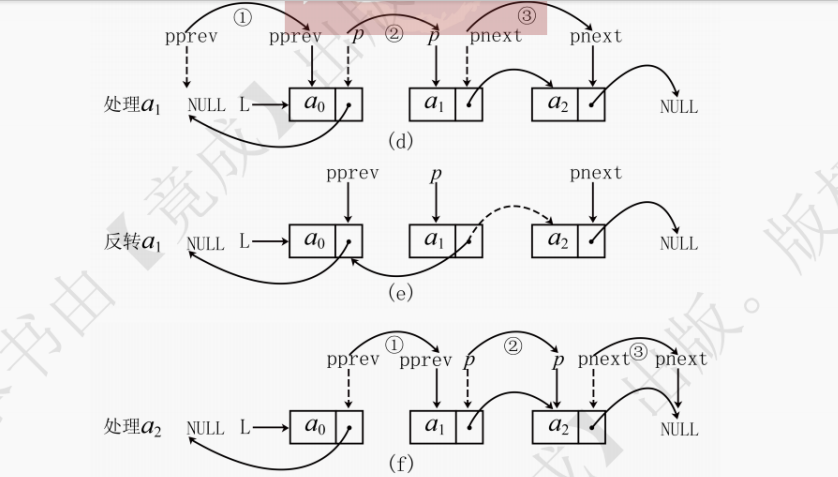
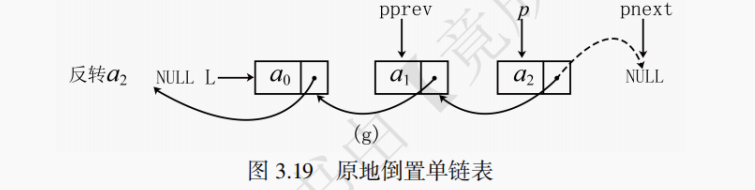
若要按照an,an−1,⋯,a0的顺序访问单链表,最原始的方法是每次访问都从头结点开始遍历,然而这种方法的时间复杂度会达到O(n^2)。为了减少时间开销,其中一种思路是原地倒置单链表,其时间复杂度为O(n)。
如图 3.19 所示,可以通过一次遍历完成倒置,不需要任何额外空间用于存放临时数据。建议先看代码然后结合图片进行理解。
倒置单链表代码实现如下:
// 考虑单链表L没有头结点 void listReverse(LinkList &L) { // p记录当前处理的结点,pnext为其后继结点,pprev指向p的前一个结点 // pprev等价于已翻转好的部分的链表头结点,即翻转前链表的最后一个结点 LinkNode *p = L, *pprev = NULL, *pnext = NULL; // 空链表或只有一个结点无需操作,直接返回 if (p==NULL || p->next==NULL) return; while (p != NULL) { // 当前处理结点为空说明处理完毕 pnext = p->next; // 更新下一个结点,如上图b // 等价于将p->next指针指向已翻转好的链表的头pprev,即翻转p p->next = pprev; // 将p指向前一个结点,等价于翻转,如上图c // 此时已翻转的部分的头结点pprev可以更新 pprev = p; // 处理下个结点前,pprev记录当前结点,如上图d(1) // 当前结点倒置后就无法访问下一个结点了,所以用pnext赋值下个结点的指针 p = pnext; // 当前待处理结点变成下个结点,如上图d(2) // 此时已经完成对一个结点的翻转即所有操作 } // 跳出循环时,p==NULL,pprev即是未翻转前链表的最后一个结点 L = pprev; // 更改头指针指向 }也可以用递归来实现单链表的倒置,代码实现如下:
// 考虑单链表L没有头结点 LinkList listReverse(LinkList L) { LinkNode *p = L; if (p==NULL || p->next==NULL) return p; //否则继续递归处理下一个结点 LinkNode *pnext = listReverse(p->next); //改变p的下一个结点next指向,链表逆转变 p->next->next = p; //改变p的next指向 p->next = NULL; return pnext; }注意:对于有头结点的情况,还需注意在链表倒置后,将头结点接回链表的头部。
3. 双指针遍历单链表
对于某些问题,使用双指针可以显著提高效率。双指针有以下几种经典用法:①找到链表倒数第k个结点;②找到链表中间的结点;③判断链表是否有环。下面介绍这 3 类问题的解法。
针对第一类问题,如果采用单指针的方法遍历,第一次遍历获得链表的长度,第二次遍历找到倒数第k个结点,需要遍历两次链表。如果采用双指针的方法遍历,只遍历了一次链表就能达到目的:在第一个指针到达正数第k个结点时,派出第二个指针,让两个指针始终保持着k的距离。那么当第一个指针到达链表末尾时,第二个指针正好指在倒数第k个结点上。如图 3.20 所示,要查找单链表倒数第 3 个结点,可以让p指针到达a2时,让q指针从头出发,p、q同步移动,当p指针到达单链表末尾时,q指针刚好指向单链表的倒数第 3 个结点。
// 考虑无头结点的单链表 LinkNode *findKFromLast(LinkList L, int k) { LinkNode *p = L, *q = L; int count = 0; // 记录第一个指针走了多久 for (; p != NULL; p = p->next) { if (count < k) count++; else q = q->next; // 当p走到第k个结点时,q开始运动 } if (count < k) return 0; // 说明链表长度小于k return q; }在解决查找链表中间结点的问题之前,首先介绍 “快慢指针” 的概念:有p、q两个指向链表结点的指针,p每走两步,q走一步,当p到达链表末尾时q正好指在链表的中间结点,如此便解决了第二类问题。判断链表是否有环也可以使用快慢指针,当链表有环的时候,必能使得快慢指针在O(n)的时间复杂度内相遇。
用快慢指针判断单链表是否有环的代码实现如下:
// 考虑无头结点的链表 bool hasRing(LinkList L) { ListNode *fast = L, *slow = L; // 遍历整个链表 while (fast != NULL && fast->next != NULL) { fast = fast->next->next; slow = slow->next; if (fast == slow) return true; } return false; }思考:如果不使用快慢指针法,如何判断链表是否有环?如何找到链表环的入口呢?
#include <stdio.h> #include <stdlib.h> // 定义链表节点结构体 typedef struct ListNode { int val; struct ListNode *next; } ListNode; // 不使用快慢指针法判断链表是否有环并找到环的入口 ListNode* detectCycle(ListNode* head) { ListNode* cur = head; // 采用数组模拟哈希表,这里假设链表节点地址范围可映射到数组下标范围 // 实际应用中可能需要更复杂的哈希表实现 ListNode* hashTable[10000] = {NULL}; int index = 0; while (cur != NULL) { // 检查当前节点是否已经在哈希表中 for (int i = 0; i < index; i++) { if (hashTable[i] == cur) { // 存在环,找到环的入口 ListNode* entry = head; ListNode* found = cur; while (entry != found) { entry = entry->next; found = found->next; } return entry; } } // 将当前节点加入哈希表 hashTable[index] = cur; index++; cur = cur->next; } // 链表无环 return NULL; } // 测试代码 int main() { // 创建链表 1 -> 2 -> 3 -> 4 -> 5 -> 2(环的入口为 2) ListNode* head = (ListNode*)malloc(sizeof(ListNode)); head->val = 1; ListNode* node2 = (ListNode*)malloc(sizeof(ListNode)); node2->val = 2; ListNode* node3 = (ListNode*)malloc(sizeof(ListNode)); node3->val = 3; ListNode* node4 = (ListNode*)malloc(sizeof(ListNode)); node4->val = 4; ListNode* node5 = (ListNode*)malloc(sizeof(ListNode)); node5->val = 5; head->next = node2; node2->next = node3; node3->next = node4; node4->next = node5; node5->next = node2; ListNode* cycleEntry = detectCycle(head); if (cycleEntry != NULL) { printf("链表有环,环的入口节点值为: %d\n", cycleEntry->val); } else { printf("链表无环\n"); } // 释放链表内存 free(head); free(node2); free(node3); free(node4); free(node5); return 0; }上述代码实现了不使用快慢指针,通过哈希表的方式判断链表是否有环并找到环的入口。
detectCycle函数中,用一个数组模拟哈希表来存储已经访问过的链表节点,在遍历链表的过程中检查节点是否已经在哈希表中,若存在则说明有环并进一步找到环的入口;若遍历完链表都未发现重复节点,则说明链表无环。在main函数中构造了一个有环链表进行测试,并在最后释放了链表占用的内存。3.3.4 双链表的定义
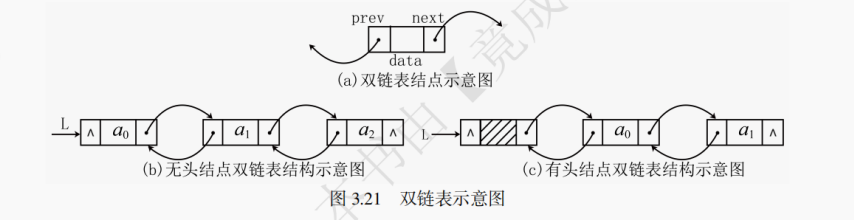
双链表也属于链表的一种。双链表有两个指针域:next指针指向其后继结点的地址,prev指针指向其前驱结点的地址。双链表结点的定义代码如下:
typedef struct DLinkNode { ElemType data; struct DLinkNode *prev, *next; } DLinkNode, *DLinkList;在双链表中,每个结点包含三个部分:
(1) 指向当前结点前驱结点的指针;
(2) 当前结点存储数据的数据域;
(3) 指向当前结点后继结点的指针。双链表示意图如图 3.21 所示。在遍历双向链表时,从任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。双链表可以解决单链表在反向遍历上的不足。
3.3.5 双链表基本操作的实现
本节主要给出双链表部分基本操作的核心代码,而边界条件判断、初始赋值和如何返回等代码略去。略去部分的实现思路与前文大致相同,考生可以对比学习。
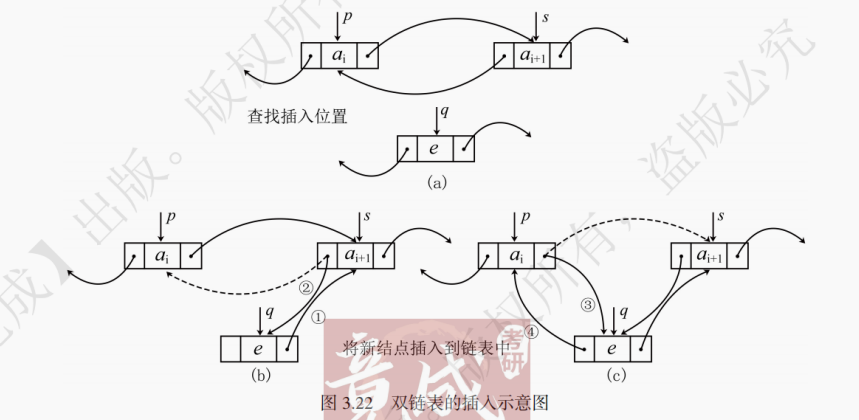
1. 双链表的插入操作
在对双链表进行插入操作时,要确保赋值的顺序不会使双链表 “断开”。双链表插入的示意图如图 3.22 所示。
双链表插入代码如下:
// 在双链表p结点之后插入q结点 // 第一种插入方法 ① q->next = p->next; ② p->next->prev = q; // 将p结点原后继结点的prev指针指向q ③ p->next = q; ④ q->prev = p; // 第二种插入方法 DlinkNode *s = p->next; // 引入s结点,用来表示p的后继结点 ① q->next = s; ② s->prev = q; ③ p->next = q; ④ q->prev = p;在编写代码时,建议考生采用第二种方法进行赋值,用s记录了插入前p的后继结点,以保证双链表不会断开,同时省去了p−>next−>prev这种不易理解的语句。图 3.22 中的步骤②到步骤④,与第二种插入方式的实现代码相对应,请考生仔细体会。
2. 双链表的删除操作
双链表的删除操作比插入操作更简单一些,这里给出两种写法,分别是不引入s结点和引入s结点的写法:
// 删除q结点,不引入s结点 // 第一种删除方法 p->next = q->next; q->next->prev = p; free(q); //释放q节点的内存 // 第二种删除方法,引入s结点 DlinkNode *s = q->next; // 引入s结点,用来表示q的后一个结点 p->next = s; s->prev = p; free(q);除了上面给出的两种双链表的操作算法之外,考生也可以尝试写出其他各种操作算法的核心代码,加深理解。
3.3.6 循环链表的定义
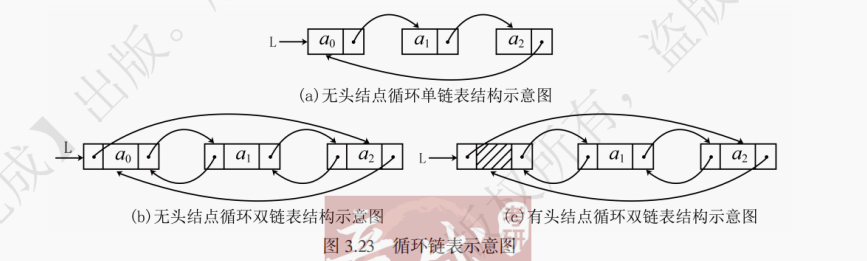
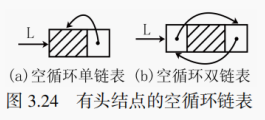
循环链表是另一种形式的链式存储结构。相比于之前所讲的单链表和双链表,它的特点是表中最后一个结点的指针指向头结点,整个链表形成一个环。如图 3.23 所示:
为什么要引入循环链表?试想在扑克牌中采用链表的形式记录每位玩家,若采用单链表,则每当所有玩家经过一轮出牌之后,需要重新将指针指向链表的头结点,这就需要多一个表尾判断的操作。若采用循环链表,将链表的最后一位指向链表头,便可以按单纯访问后继结点的方式对所有玩家进行无限循环遍历。引入循环链表就是为了解决那些本质是循环的问题。在操作系统中,分时操作系统为了给每位用户分时提供服务,也可以采用循环链表来维护所有的用户。不论从哪个用户开始,都可以通过循环遍历找到所有的用户,为其提供服务。对于单链表,访问头结点的时间复杂度是 O (1),而访问最后一个结点的时间复杂度是 O (n)。循环单链表将单链表的最后一个结点接到了头结点上,此时可以使用尾指针 rear 来代表循环单链表。考虑无头结点的循环单链表,用尾指针代表循环单链表既能以 O (1) 的时间复杂度访问最后的结点(rear),也能以 O (1) 的复杂度访问其首结点(rear->next)。
循环链表的插入和删除与普通链表区别不大,但是在头尾处进行插入删除操作时要注意维护循环链表循环的特性。如果循环链表有尾指针,删除尾指针所指向的结点时,要注意维护尾指针,即将其重新指向表尾结点。
【例 3.2】已知头指针 h 指向一个带头结点的非空循环双链表,结点结构 (prev | data | next),其中 next 是指向直接后继结点的指针,prev 是指向直接前驱结点的指针,p 是尾指针(其 next 指向头结点 h),q 是临时指针。现在要删除该链表的首元素正确的语句序列是 ( )。
A. h->next=h->next->next; h->next->next->prev=h; if (p==q) p=h; free (q);
B. h->next=h->next->next; h->next->prev=h; q=h->next->prev; if (p==q) p=h; free (q);
C. q=h->next; h->next=q->next; h->next->prev=h; if (p!=q) p=h; free (q);
D. q=h->next; h->next=q->next; q->next->prev=h; if (p==q) p=h; free (q);解析:选 D,首先用 q 记录要被删除的结点,采用和双链表一样的删除方式进行删除,由于这个循环双链表有尾指针,若该链表只有一个元素,则在删除该元素时尾指针也会被删除,所以需要判断被删除元素是不是尾指针所指元素,若是则将尾指针指向前一个结点也就是头结点。A 选项第二步往后多走了一个结点,B 选项第三步赋值时被删除结点已经与原链表断开了。
对于有头结点的循环单链表,只要 L->next == L 即为空链表。
对于有头结点的循环双链表,除了可以使用 L->next == L 判空,满足 L->prev == L 的循环双链表同样也是空链表。
16.带头结点的双循环链表 L 如果为空,则需要满足的条件为 ( )。
A. L->prev==L&&L->next==NULL
B. L->prev==L&&L->next==L
C. L->prev==NULL&&L->next==NULL
D. L->prev==NULL&&L->next==L16.【参考答案】 B
【解析】 带头结点的空循环双链表的 next 指针和 prev 指针都是指向头结点本身的,因此选 B。21.设 p 指向非空单循环链表(带头结点)的终端结点,则 p 满足 ( )。
A. p->next == L
B. p->next == NULL
C. p->next->next == L
D. p->next == L && p != L21.【参考答案】 D
【解析】 p 指向终端结点,则 p->next==L,又因为链表非空,则 p!=L,选 D。思考:对于没有头结点的循环单链表,判空条件是什么呢?
对于没有头结点的循环单链表,判空条件是 rear == NULL。
因为在没有头结点的循环单链表中,使用尾指针 rear 来代表循环单链表,当链表为空时,链表中不存在任何节点,那么尾指针 rear 自然也就没有指向任何节点,即 rear 的值为 NULL。 当 rear != NULL 时,说明链表中至少存在一个节点,此时尾指针 rear 指向链表的最后一个节点,且该节点的 next 指针指向链表的第一个节点(因为是循环单链表)。
提示:本节在讲解单链表的代码中,详细给出了各种边界条件的判断,并解释了每一条语句的作用,目的是让考生对链表的各种状态有所了解。考生应模拟运行本章各操作中给出的代码,并尝试自己进行默写。当在题目中遇到判断空表、插入删除操作与计算时间复杂度等问题时,尝试画图模拟是一个好方法。
3.3.7 习题精编
1.在一个单链表中,若 p 所指的结点不是最后一个结点,在 p 之后插入 s 所指的结点,则需要执行 ( )。
A. s->next=p; p->next=s;
B. p->next=s; s->next=p;
C. p=s; s->next=p->next;
D. s->next=p->next; p->next=s;1.【参考答案】 D
【解析】 为了防止链表 “断开”,应先执行 s->next=p->next; 让 p 的后继结点成为 s 的后继结点,再执行 p->next=s; 让 s 成为 p 的后继结点。2.将长度为 n 的单向链表链接在长度为 m 的单向链表之后的算法时间复杂度为 ( )。
A. O (1)
B. O (n)
C. O (m)
D. O (m + n)2.【参考答案】 C
【解析】 需要找到长度为 m 的链表的尾结点再将链表接上,找到尾结点的复杂度为 O (m),接上的耗时为 O (1),因此复杂度为 O (m)。3.单链表中,增加一个头结点的目的是 ( )。
A. 使单链表至少有一个结点
B. 标识表中首结点的位置
C. 方便运算的实现
D. 说明单链表是线性表的链式存储3.【参考答案】 C
【解析】 头结点是为了操作的统一、方便而设计的。单链表可以为空,故 A 错。没有头结点也可用头指针标识首结点,故 B 错。单链表是不是链式存储和有无头结点没有关系,故 D 错。4.在一个有尾指针的无头结点单链表上,则下列与表长有关的操作是 ( )。
A. 删除头指针所指的元素
B. 删除尾指针所指的元素
C. 在单链表第一个元素前插入一个元素
D. 在单链表最后一个元素后插入一个元素4.【参考答案】 B
【解析】 和表长有关的操作是需要遍历整表的,删除头指针所指的元素不需要,故 A 错。在单链表第一个元素前插入也不需要,故 C 错,这两个操作都可以通过头指针很简单的完成。在单链表最后一个元素后插入元素也可通过尾指针完成,故 D 错。但删除尾指针所指的元素需要将尾指针移至前驱结点上,在单链表上只能通过遍历整表的方式获得结点的前驱结点,因此 B 与表长有关。5.将一个元素插入长度为 n 的有序单链表中,如果插入元素之后,单链表仍保持有序,则该插入操作的时间复杂度为 ( )。
A. O (1)
B. O (n²)
C. O (logn)
D. O (n)5.【参考答案】 D
【解析】 在单链表有序的情况下,假设以 p 指针作为遍历搜索的指针,只要搜索到某结点 p 满足 “新元素的值被夹在 p 和 p->next 之间”,就可以将新元素插到这之间,因此只需要一次遍历就可完成,操作复杂度为 O (n)。6.将两个长度为 n 的有序链表归并成一个有序表,最少比较 ( ) 次。
A. n
B. 2n - 1
C. 2n
D. n - 16.【参考答案】 A
【解析】 因为两个链表都是有序的,当一个链表遍历到结尾时只需将没遍历完的接在后面即可。假设链表 A 中的所有元素都小于链表 B 中的元素,则将链表 A 中的每个元素和 B 的第一个元素比较,只需比较 n 次便可将 A 中元素遍历完,剩下只需将 B 接在 A 的后面即可。7.在一个单链表中,若 p 所指的结点不是最后一个结点,删除 p 之后结点,则执行 ( )。
A. p->next=p;
B. p->next->next=p->next;
C. p->next->next=p;
D. p->next=p->next->next;7.【参考答案】 D
【解析】 删除 p 之后结点,因题中没有 free 的要求,只需将 p 的 next 指针指向其后继结点的 next 指针即可,因此执行 “p->next=p->next->next;”。8.h 为不带头结点的单链表。在 h 的表头上插入一个新结点 t 的语句是 ( )。
A. t->next=h; h=t;
B. h=t; t->next=h;
C. t->next=h->next; h=t;
D. h=t; t->next=h->next;8.【参考答案】 A
【解析】 本题考查不带头结点的单链表插入首元素,要注意改变 h 的指向,因此先插入:执行 “t->next=h;”,再改变头指针指向:执行 “h=t;”。9.在一个单链表中,已知 q 指向结点是 p 指向结点的前驱结点,若在 q 指向结点和 p 指向结点之间插入 s 指向结点,则需执行 ( )。
A. s->next=p->next; p->next=s;
B. q->next=s; s->next=p;
C. p->next=s->next; s->next=p;
D. p->next=s; s->next=q;9.【参考答案】 B
【解析】 本题考查单链表的插入操作,只需注意在插入操作时不要让链表 “断开” 即可。10.在一个单链表中,已知指针 p 指向其中某个结点,若在该结点前插入一个由指针 s 指向的结点,则需执行 ( )。
A. s->next=p->next; p->next=s;
B. p->next=s; s->next=p;
C. r=p->next; p->next=s; s->next=r;
D. 仅靠已知条件无法实现10.【参考答案】 D
【解析】 选项 A、C 都是后插,而 B 让链表 “断开”,相当于互相成为后继,因此选 D。但此题是有完成方法的,只需插入结点之后将数据域的内容交换即可,即 s->next=p->next; p->next=s; swap (s->data, p->data); 这样便可以造成前插 s 的 “假象”。11.对于没有尾指针的单链表,将 n 个元素采用头插法建立单链表的时间复杂度为 (),采用尾插法建立单链表的时间复杂度为 ()。
A. O (1)
B. O (nlogn)
C. O (n)
D. O (n²)11.【参考答案】 C、D
【解析】 因为每次插入都要遍历找到尾结点,没有尾指针的单链表头插法建立的复杂度为 n×O (1)=O (n),尾插法建立的复杂度为 O (n²)。12.双链表相比于单链表 ( )。
A. 插入删除操作更简单
B. 不需要尾指针
C. 访问邻结点更灵活
D. 支持随机访问12.【参考答案】 C
【解析】 双链表相比于单链表的优点在于结点间有指向双方的指针,因此可以方便地访问左右相邻结点。13.在双链表中,将 s 指向的结点插入到 p 结点之前,需要完成操作为 ( )。
A. p->prev->next=s; s->next=p; s->prev=p->prev; p->prev=s;
B. p->next=s; s->prev=p; p->next->prev=s; s->next=p->next;
C. s->next=p; p->next=s; s->prev=p->next; p->next=s;
D. s->next=p->next; p->next->prev=s; p->next=s; s->prev=p;13.【参考答案】 A
【解析】 双链表的前插法只需注意不让链表 “断开” 即可。A 正确。B、C、D 中都有 “p->next=s;”,是后插法,将 s 插入 p 的前面无需修改 p 的 next 指针,错误。14.在双链表中,删除 p 指针所指结点的操作为 ( )。
A. p->prev->next=p->next; p->next->prev=p->prev;
B. p->prev->next=p->next; p->next->prev=p->next;
C. p->next=p->next->prev; p->prev=p->prev->next;
D. p->prev->next=p->next; p->next->prev=p->prev->next;14.【参考答案】 A
【解析】 双链表的删除较为简单,只需改变两个指针即可,前驱结点的 next 指针和后继结点的 prev 指针。15.在一个双链表中,在 p 指针所指的结点之后插入 s 指针所指结点的操作为 ( )。
A. p->next=s; s->prev=p; s->next=p->next; p->next->prev=s;
B. s->prev=p; p->next=s; s->next=p->next; s->next=p->next; p->next->prev=s;
C. s->prev=p; p->next=s; p->next->prev=s; s->next=p->next;
D. s->next=p->next; p->next->prev=s; p->next=s; s->prev=p;15.【参考答案】 D
【解析】 双链表的后插法只需注意不让链表 “断开” 即可。A、B、C 中在没有将 p 的后继结点和 s 联系上之前执行了 p->next=s; 断开了链表。只有 D 正确。16.带头结点的双循环链表 L 如果为空,则需要满足的条件为 ( )。
A. L->prev==L&&L->next==NULL
B. L->prev==L&&L->next==L
C. L->prev==NULL&&L->next==NULL
D. L->prev==NULL&&L->next==L16.【参考答案】 B
【解析】 带头结点的空循环双链表的 next 指针和 prev 指针都是指向头结点本身的,因此选 B。17.(多选) 某线性表用带头结点的循环单链表存储,头指针为 head,当 head->next->next->next == head 成立时,线性表长度可能是 ( )。
A. 0
B. 1
C. 2
D. 317.【参考答案】 A、C
【解析】 假设该链表只有头结点,则 head->next==head,循环带入,满足条件。若有 1 个结点,则 head->next->next==head,不满足条件。若有 2 个结点,则 head->next->next->next==head,满足条件。再多结点的情况就不满足了。18.设单循环链表中结点的结构为 (data, next),且 rear 是指向非空的带头结点的单循环链表的尾结点的指针。若要删除链表的第一个结点,正确的操作是 ( )。
A. s=rear; rear=rear->next; free (s);
B. rear=rear->next; free (s);
C. rear=rear->next->next; free (s);
D. s=rear->next->next; rear->next->next=s->next; free (s);18.【参考答案】 D
【解析】 删除带头结点单循环链表的第一个结点需要改变头结点的 next 指针,此题选项中没有头指针,因此通过 rear->next 作为头指针,D 选项中采用 s 表示要被删除的结点,将头结点的 next 指针(rear->next->next)指向 s 的后继结点(s->next)。但实际情况还需要注意 rear 指针是否与 s 指针指向同一个结点(即单链表中只有一个结点),此时 free (s) 时会让 rear 指针与链表 “断开”。此时需要在 free (s) 之前加入判断 if (s==rear) rear=rear->next; 将尾指针指向头结点(此时链表中只有头结点)。19.若某种用链表实现的数据结构只在第一个元素前插入元素和删除最后一个元素,以下哪种链表最适合实现该数据结构 ( )。
A. 只带队首指针的非循环双链表
B. 只带队首指针的循环双链表
C. 只带队尾指针的循环双链表
D. 只带队尾指针的循环单链表19.【参考答案】 C
【解析】 首先要能以 O (1) 的时间复杂度访问链表的头结点和尾结点,排除 A 选项;若删除最后一个元素,则需要修改倒数第二个元素的 next 指针,D 选项无法在 O (1) 的时间内完成该操作;结合本题的要求,C 选项比 B 选项的操作更少一些。题目要求选最适合的,故选 C。20.若一个带头结点的链表经常在末尾进行插入删除操作,要求尽量不引入额外的变量,则应该选用 ( )。
A. 不带尾指针的双循环链表
B. 不带尾指针的单循环链表
C. 带尾指针的单循环链表
D. 带尾指针的双循环链表20.【参考答案】 A
【解析】 若经常在末尾进行插入删除,则只需访问尾结点以及其前驱结点(因删除尾结点需改变其前驱结点的 next 指针),则排除单循环链表 B、C。不带尾指针的双循环链表通过 L->pre 的方式以 O (1) 的时间复杂度就能访问尾结点及其前驱结点,虽然带尾指针的双循环链表也可实现,但题目要求尽量不引入额外变量,故选 A。21.设 p 指向非空单循环链表(带头结点)的终端结点,则 p 满足 ( )。
A. p->next == L
B. p->next == NULL
C. p->next->next == L
D. p->next == L && p != L21.【参考答案】 D
【解析】 p 指向终端结点,则 p->next==L,又因为链表非空,则 p!=L,选 D。22.(多选) 以下选项正确的是 ( )。
A. 静态链表既有顺序存储的优点,又有动态链表的优点,所以,它存取表中第 i 个元素的时间与 i 无关
B. 静态链表中能容纳的元素个数在表定义时就确定了,在后续操作中不能增加
C. 静态链表与动态链表在元素的插入、删除上类似,不需要做元素的移动
D. 静态链表相比于动态链表有可能浪费较多存储空间22.【参考答案】 B、C、D
【解析】 静态链表仍然是链表,虽然物理存储空间是顺序的,但元素存储不是顺序的,需要查表按照链接顺序访问,因此不支持随机存取,而插入删除都不需要做元素的移动,A 错误,C 正确。静态链表的存储空间是一次性申请的,因此容纳的元素个数在定义时就确定了,但因为并不是每个空间都存储了元素,可能会造成存储空间的浪费,B、D 正确。23.设线性表中有 n 个元素,( ) 选择在单链表上执行相比顺序表更好。
A. 删除所有值为 e 的元素
B. 在最后一个元素后面插入新元素 e
C. 顺序输出线性表
D. 交换第 i 个元素和第 j 个元素的值23.【参考答案】 A
【解析】 在最后一个元素后面插入新元素 e,对于线性表而言不需要移动元素,操作复杂度为 O (1),而对于单链表而言,想要在最后插入新元素,需要遍历找到表尾元素,时间复杂度为 O (n),故 B 错。顺序输出需要遍历整个线性表,因此对于单链表和顺序表而言操作复杂度都是 O (n),故 C 错。而顺序表每删除一个元素,平均时间复杂度都为 O (n),删除所有值为 e 的元素十分消耗时间,而对于单链表而言只需要一次遍历即可删除所有的值为 e 的元素,时间复杂度为 O (n),故 A 正确。交换第 i 和第 j 个元素只需要定位到这两个元素,将结点里的内容进行交换即可,因顺序表支持随机访问,定位速度快于链表,因此 D 错。24.下面关于线性表的叙述中,不正确的是 ( )。
I. 线性表在链式存储时,查找第 i 个元素的时间同 i 的值成正比
II. 线性表在链式存储时,查找第 i 个元素的时间同 i 的值无关
III. 线性表在顺序存储时,查找第 i 个元素的时间同 i 的值成正比
IV. 线性表在顺序存储时,查找第 i 个元素的时间同 i 的值无关
A. I、II
B. II、III
C. III、IV
D. I、IV24.【参考答案】 B
【解析】 线性表在链式存储时,查找第 i 个元素的时间同 i 的值成正比。线性表在顺序存储时,查找第 i 个元素的时间同 i 的值无关。因此选 B。25.已知一个带头结点的单链表中存储的均为正整数,每个正整数均不大于 N,链表中结点结构如下:|data|next| ,链表头结点指针为 head。设计一个尽可能高效的算法,将 head 指向链表中出现次数最多的元素(不考虑出现次数最多的元素有多个的情况)。
(1) 描述算法的基本设计思想。
(2) 根据算法设计思想采用 C/C++ 语言实现算法,关键之处给出注释。
(3) 分析你所实现的算法的时间复杂度和空间复杂度。25.【参考答案】
(1) 设置一个辅助数组 A [N] 并初始化为 0,遍历链表中的元素,对于每个元素若其值为 n,则将元素 A [n - 1]++ 用于记录元素 n 出现的次数,链表遍历结束后再找出数组 A 中最大的数,其下标加一即为出现次数最多的元素的值,在链表中找到该值第一次出现的位置,将 head 指向该位置即可。
(2) 解答如下:typedef struct link { int data; struct link *next; } Link; void newList(Link *head, int N) { int *A = (int *)malloc(sizeof(int) * N); memset(A, 0, sizeof(int) * N); Link *h = head -> next; while (h) { // 统计每个元素出现次数 A[h->data - 1]++; h = h->next; } int max = 0; for (int i = 0; i < N; ++i) { //找到出现次数最多的元素 if (A[i] > max) { max = A[i]; num = i; } } h = head; //将头指针指向出现次数最多的元素第一次出现的位置 while (h->data != num + 1) { h = h->next; } head = h; free(A); }(3) 时间复杂度:遍历链表与辅助数组的时间复杂度都为 O (N),总时间复杂度为 O (N),空间复杂度:空间复杂度由辅助数组决定,为 O (N)。
3.3.8 真题演练
26.【2013】已知两个长度分别为 m 和 n 的升序链表,若将它们合并为一个长度为 m + n 的降序链表,则最坏情况下的时间复杂度是 ( )。
A. O (n)
B. O (mn)
C. O (min (m, n))
D. O (max (m, n))26. 【参考答案】 D
【解析】此题为错题,按照出题人的本意应有以下解法,由于两个链表都是升序链表,每次比较从两链表中取出一个结点进行插入,当一个链表遍历结束之后将另一个链表直接接到后面即可,最坏情况下需要将更长的链表遍历完,因此时间复杂度为 O (max (m, n))。而此题需注意到,由升序链表合并成为降序需要采用头插法,每次将两链表比较结果较小的插入链表中,当一个链表遍历完无法直接将链表接上,需要逐个遍历剩下的结点,一一按照头插法插入,故最好和最坏时间复杂度都为 O (m + n)。
27.【2016】已知表头元素为 c 的单链表在内存中的存储状态如下表所示。
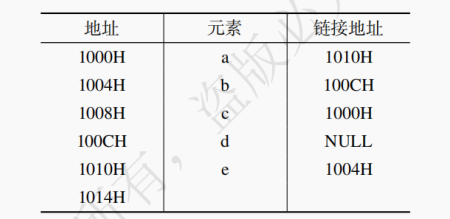
现将 f 存放于 1014H 处并插入到单链表中,若 f 在逻辑上位于 a 和 e 之间,则 a, e, f 的 “链接地址” 依次是 ( )。
A. 1010H,1014H,1004H
B. 1010H,1004H,1014H
C. 1014H,1010H,1004H
D. 1014H,1004H,1010H27.【参考答案】 D
【解析】 将 f 插到 a, e 之间,则 a 的 next 指针指向 f,f 的 next 指针指向 e,f 存在 1014H 处,因此选 D。28.已知一个带有表头结点的双向循环链表 L,结点结构为:prev | data | next ,其中 prev 和 next 分别是指向其直接前驱和直接后继结点的指针。现要删除指针 p 所指的结点,正确的语句序列是 ( )。
A. p->next->prev=p->prev; p->prev->next=p->prev; free (p)
B. p->next->prev=p->next; p->prev->next=p->next; free (p)
C. p->next->prev=p->next; p->prev->next=p->prev; free (p)
D. p->next->prev=p->prev; p->prev->next=p->next; free (p)28.【参考答案】 D
【解析】 删除 p 指针所指的结点,需要改变 p 的前驱结点的 next 指针和 p 后继结点的 prev 指针,将 p->prev->next 指向 p->next 结点,p->next->prev 指向 p->prev 结点,同时要保证链表不能 “断开”,因此选 D。29.【2021】已知头指针 h 指向一个带头结点的非空单循环链表,结点结构为:data | next 。其中 next 是指向直接后继结点的指针,p 是尾指针,q 是临时指针。现要删除该链表的第一个元素,正确的语句序列是 ( )。
A. h -> next = h -> next -> next; q = h -> next; free (q);
B. q = h -> next; h -> next = h -> next -> next; free (q);
C. q = h -> next; h -> next = q -> next; if (p != q) p = h; free (q);
D. q = h -> next; h -> next = q -> next; if (p == q) p = h; free (q);29.【参考答案】 D
【解析】 除了需要删除第一个元素以外,还需注意尾指针是否指向被删除的结点,也就是判断若删去的结点是尾指针指向的 p == q,此时单链表只有一个结点(第一个元素是最后一个元素),则将尾指针移至头指针的位置 p = h。30.【2009】已知一个带有表头结点的单链表,结点结构为:data | link 。假设该链表只给出了头指针 list。在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第 k 个位置上的结点(k 为正整数)。若查找成功,算法输出该结点的 data 域的值,并返回 1;否则,只返回 0。要求:
(1) 描述算法的基本设计思想。
(2) 描述算法的详细实现步骤。
(3) 根据设计思想和实现步骤,采用程序设计语言描述算法(使用 C 或 C++ 或 Java 语言实现),关键之处请给出简要注释。30.【参考答案】
(1) 本题采用双指针遍历法。定义两指针 p 和 q,p 从头开始遍历链表,当 p 指针移动到第 k 个结点时,q 指针开始移动;这样当 p 指针遍历完时,q 指针正好指向倒数第 k 个结点。
(2) 算法步骤如下:
(a) 初始化 p,q = list,count = 0;
(b) p = p->next,count++,若 p 为空,则转向步骤 (f);
(c) 若 count < k,则转向步骤 (b),否则转向步骤 (d);
(d) p = p->next,q = q->next;
(e) 若 p 为空,则转向步骤 (f),否则转向步骤 (d);
(f) 若 count == k,输出 q->data,返回 1,否则返回 0。
(3) 代码实现如下:typedef struct LinkNode { ElemType data; LinkNode *link; } LinkNode, *LinkList; int findK(LinkList L, int k) { LinkNode *p = L->link, *q = L->link; int count = 0; for (; p!= NULL; p = p->link) { (count < k)? (++count) : (q = q->link); } if (count < k) { return 0; } else { cout << q->data; return 1; } }若算法采用一遍扫描就能得到正确结果,给 15 分;若采用两遍或多遍扫描,结果正确,最高 10 分。若实现算法的空间复杂度大于 O (k),但结果正确,最高给 10 分。
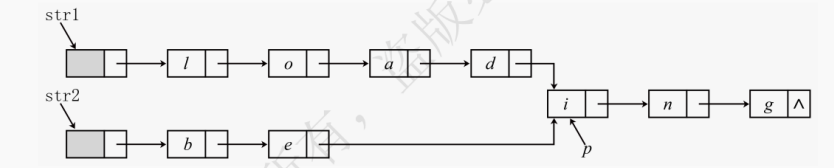
31.【2012】假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,则可共享相同的后缀存储空间,例如,“loading” 和 “being” 的存储映像如下图所示。设 str1 和 str2 分别指向两个单词所在单链表的头结点,链表结点结构为:data | next 。请设计一个时间上尽可能高效的算法,找出由 str1 和 str2 所指向两个链表共同后缀的起始位置(如图中字符 i 所在结点的位置 p)。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释;
(3) 说明你所设计算法的时间复杂度。
31.【参考答案】
(1) 分别求出两链表 str1 和 str2 的长度 m, n,不妨设 m > n,令 k = m - n 表示链表长度差,取两个指针 p、q 分别指向两链表的头结点,令 p 先向前遍历 k 个结点,之后使 p 和 q 同步向前,当 p 和 q 相遇时即指向了共同后缀的起始位置。
(2) 代码实现如下:int getLen(LinkList L) { int count = 0; LinkNode *cur = L->next; for (; cur!= NULL; cur = cur->next) ++count; return count; } LinkNode *findCommon(LinkList str1, LinkList str2) { int len1 = getLen(str1), len2 = getLen(str2); LinkNode *p = str1->next, *q = str2->next; for (; len1 > len2; --len1) p = p->next; // 此时str1更长 for (; len1 < len2; --len1) q = q->next; // 此时str2更长 // 同时向后遍历,直到遍历完或指向相同结点 while (p!=NULL && q!=NULL && p->next!=q->next) { p = p->next; q = q->next; } return p->next; }(3) 时间复杂度为 O (max (len1, len2))。
32.【2015】用单链表保存 m 个整数,结点的结构为:data | link ,且 | data|≤n(n 为正整数)。现要求设计一个时间复杂度尽可能高效的算法,对于链表中 data 的绝对值相等的结点,仅保留第一次出现的结点而删除其余绝对值相等的结点。例如,若给定的单链表 HEAD 如下:
要求:
(1) 给出算法的基本设计思想。
(2) 使用 C 或 C++ 语言,给出单链表结点的数据类型定义;
(3) 根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释。
(4) 说明你所设计算法的时间复杂度和空间复杂度。32.【参考答案】
(1) 可以使用空间换时间,用辅助数组 A 记录已经出现过的元素,A [2]=1 表示绝对值为 2 的数已经出现过了,A [3]=0 表示绝对值为 3 的数还没有出现。这样就可以一边遍历一边判断之前是否出现过绝对值相等的结点了。
(2) C++ 单链表数据结构定义如下:typedef struct LinkNode { ElemType data; LinkNode *link; } LinkNode, *LinkList;(3) 代码实现如下:
void delSameAbs(LinkList L, int n) { int A[n+1] = { 0 }; // 辅助数组 // 由于要删除结点需要前驱结点的指针,每次判断需要判断p->link // abs()是C语言中的求绝对值函数 for (LinkNode *p = L; p->link!= NULL; p = p->link) { if (A[abs(p->link->data)] == 1) { LinkNode *temp = p->link; p->link = temp->link; free(temp); } else { A[abs(p->link->data)] = 1; // 标记为已出现 } } }(4) 时间复杂度为 O (m),空间复杂度为 O (n)。
33.【2019】设线性表 L = (a1, a2, a3, …, an - 2, an - 1, an) 采用带头结点的单链表保存,链表中结点定义如下:
typedef struct node { int data; struct node *next; } NODE;请设计一个空间复杂度为 O (1) 且时间上尽可能高效的算法,重新排列 L 中的各结点,得到线性表 L' = (a1, an, a2, an - 1, a3, an - 2, …)。要求:
(1) 给出算法的基本设计思想;
(2) 根据设计思想,采用 C 或 C++ 语言描述算法,关键之处给出注释;
(3) 说明你所设计的算法的时间复杂度。33.【参考答案】
(1) 先用快慢指针法找到链表的中间结点(快慢指针在竞成《数据结构考研复习全书》中有介绍),再将链表的后半部分原地倒置,之后从头部和中间依次各取一个结点交错插入重排。
(2) 代码实现如下:void change(NODE *L) { NODE *p = L, *q = L,*r; // 1、用快慢指针法找到中间结点:p每走一步,q走两步 while (q->next!= NULL) { p = p->next; // p走一步 q = q->next; if (q->next!= NULL) { q = q->next; // p每走一步,q走两步 } } // while循环结束时,p指向中间结点,q指向尾结点 // 2、倒置后半链表 q=p->next; //结点q设置为后半段的首结点 p->next=NULL; while (q->next!= NULL) { r = q->next; q->next = p->next; p->next = q; q = r; } // 3、从头部和中间依次各取一个结点交错插入重排 NODE *s = L->next; // s指向首结点 q = p->next; // q指向当前的中间结点 p->next = NULL; while (q!= NULL) { // 交错插入 r = q->next; q->next = s->next; s->next = q; s = q->next; q = r; } }(3) 算法的时间复杂度为 O (n)。
【提示】若考生想不出来最优解,可以尝试暴力解拿到大部分分数。遍历链表,从头结点开始从前往后遍历,以当前结点为头并不断对后面的结点使用头插法,直到最后一个结点。当前结点走到最后一个位置时,得到的新链表即为所求链表。这种方法每一轮遍历可以确定一个结点的最终位置,总共遍历 n 轮,每轮的时间复杂度为 O (n),故算法的时间复杂度为 O (n²)。
【真题出处】LeetCode 上有道类似的题,与此题稍有不同,感兴趣的读者可以动手练习下:143. 重排链表 - 力扣(LeetCode)3.4 章末总结
从逻辑结构、物理结构、操作和应用这四个方面对线性表涉及的知识点进行串联和总结:
(1) 线性表的逻辑结构为线性结构:除第一个元素外,每一个元素有且仅有一个直接前驱;除最后一个元素外,每一个元素有且仅有一个直接后继。排队时的队伍、字母表的排列顺序等,都可以被视作线性表。
(2) 采用顺序存储结构的线性表被称为顺序表,特点是逻辑上相邻的数据元素,物理上也是相邻的,因此顺序表支持随机存取。在顺序表的操作中,比较重要的是查找、插入与删除这三种操作,对这三种操作的代码实现以及时间复杂度的计算过程需要非常熟练。
(3) 采用链式存储的线性表称为链表。链表可以用一组任意的存储单元存储线性表的数据元素,由于结点在物理地址上并不相邻,想要找到后继结点的存储位置就要靠指针来指示。根据链表中指针个数、指针指向以及指针连接方式的不同又将链表分为了单链表、双链表和循环链表。
(4) 链表中的插入删除操作需要熟练掌握,尤其是循环链表的插入与删除。在考虑链表的插入删除操作时,需要仔细的安排每一次指针赋值的顺序,不要让链表断开,或者让指针指向错误的位置。
(5) 顺序表支持随机访问,因此需要随机访问的场景选择顺序表。链表在插入时时间复杂度更低,因此当题目中要求的数据结构需要经常执行插入删除操时选择链表。如果链表的插入操作集中在链表尾部,可以考虑添加尾指针以减少遍历时的时间开销。
数据结构第3章 线性表 (竟成)
news2026/4/15 13:10:11


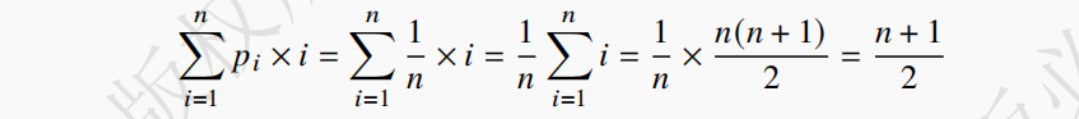
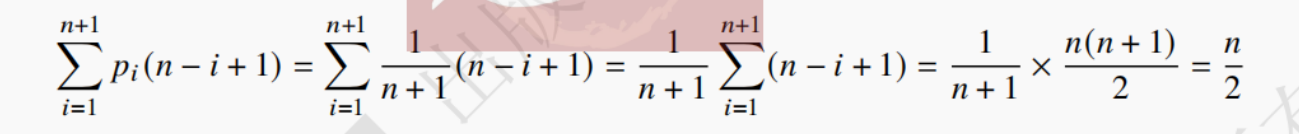
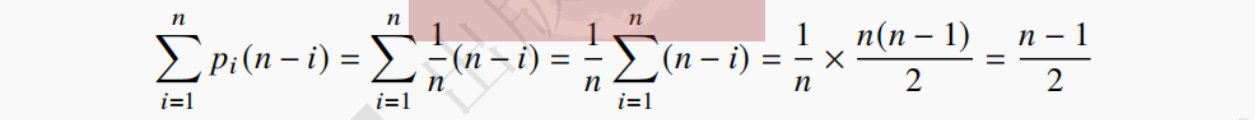



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2387249.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

JAVA面试复习知识点
面试中遇到的题目,记录复习(持续更新) Java基础 1.String的最大长度 https://www.cnblogs.com/wupeixuan/p/12187756.html 2.集合 Collection接口的实现: List接口:ArraryList、LinkedList、Vector Set接口:…

项目中的流程管理之Power相关流程管理
一、低功耗设计架构规划(Power Plan) 低功耗设计的起点是架构级的电源策略规划,主要包括: 电源域划分 基于功能模块的活跃度划分多电压域(Multi-VDD),非关键模块采用低电压…
SLOT:测试时样本专属语言模型优化,让大模型推理更精准!
SLOT:测试时样本专属语言模型优化,让大模型推理更精准!
大语言模型(LLM)在复杂指令处理上常显不足,本文提出SLOT方法,通过轻量级测试时优化,让模型更贴合单个提示。实验显示&#x…
《计算机组成原理》第 10 章 - 控制单元的设计
目录 10.1 组合逻辑设计
10.1.1 组合逻辑控制单元框图
10.1.2 微操作的节拍安排
10.1.3 组合逻辑设计步骤
10.2 微程序设计
10.2.1 微程序设计思想的产生
10.2.2 微程序控制单元框图及工作原理
10.2.3 微指令的编码方式
1. 直接编码(水平型)
2.…
【数据结构与算法】模拟
成熟不是为了走向复杂,而是为了抵达天真;不是为了变得深沉,而是为了保持清醒。 前言 这是我自己刷算法题的第五篇博客总结。 上一期笔记是关于前缀和算法: 【数据结构与算法】前缀和-CSDN博客https://blog.csdn.net/hsy1603914691…
PyTorch入门-torchvision
torchvision
torchvision 是 PyTorch 的一个重要扩展库,专门针对计算机视觉任务设计。它提供了丰富的预训练模型、常用数据集、图像变换工具和计算机视觉组件,大大简化了视觉相关深度学习项目的开发流程。
我们可以在Pytorch的官网找到torchvision的文…

18、Python字符串全解析:Unicode支持、三种创建方式与长度计算实战
适合人群:零基础自学者 | 编程小白快速入门 阅读时长:约6分钟 文章目录 一、问题:Python的字符串是什么?1、例子1:多语言支持演示2、例子2:字符串不可变性验证3、答案:(1)…
5月27日复盘-Transformer介绍
5月27日复盘
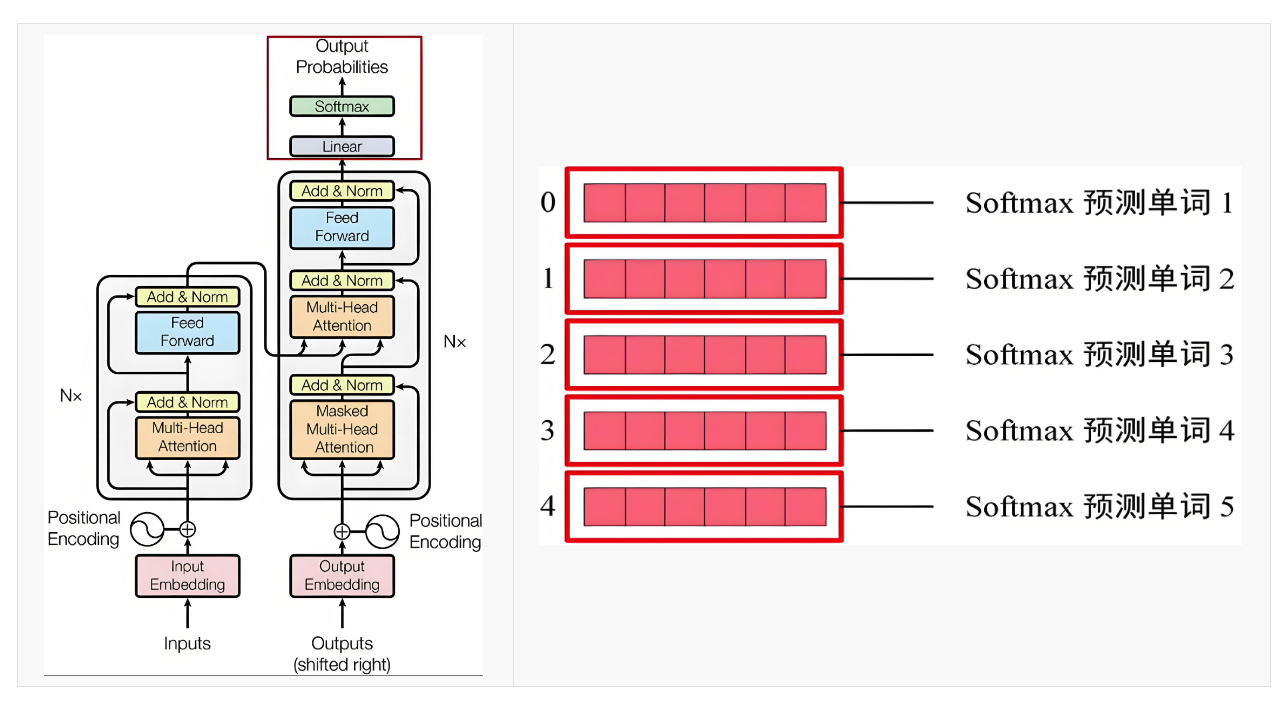
二、层归一化
层归一化,Layer Normalization。
Layer Normalizatioh和Batch Normalization都是用来规范化中间特征分布,稳定和加速神经网络训练的,但它们在处理方式、应用场景和结构上有本质区别。
1. 核心区别
特征BatchNo…

MyBatis-Plus一站式增强组件MyBatis-Plus-kit(更新2.0版本):零Controller也能生成API?
MyBatis-Plus-Kit
🚀 MyBatis-Plus-Kit 是基于MyBatis-Plus的增强组件,专注于提升开发效率,支持零侵入、即插即用的能力扩展。它聚焦于 免写 Controller、代码一键生成、通用响应封装 等核心场景,让您只需专注业务建模࿰…
实时数仓flick+clickhouse启动命令
1、启动zookeeper zk.sh start
2、启动DFS,Hadoop集群 start-dfs.sh
3、启动yarn start-yarn.sh
4、启动kafka 启动Kafka集群 bin/kafka-server-start.sh -daemon config/server.properties
查看Kafka topic 列表 bin/kafka-topics.sh --bootstrap-server local…

【Git】Commit Hash vs Change-Id
文章目录 1、Commit 号2、Change-Id 号3、区别与联系4、实际场景示例5、为什么需要两者?6、总结附录——Gerrit 在 Git 和代码审查工具(如 Gerrit)中,Commit 号(Commit Hash) 和 Change-Id 号 是两个不同的…
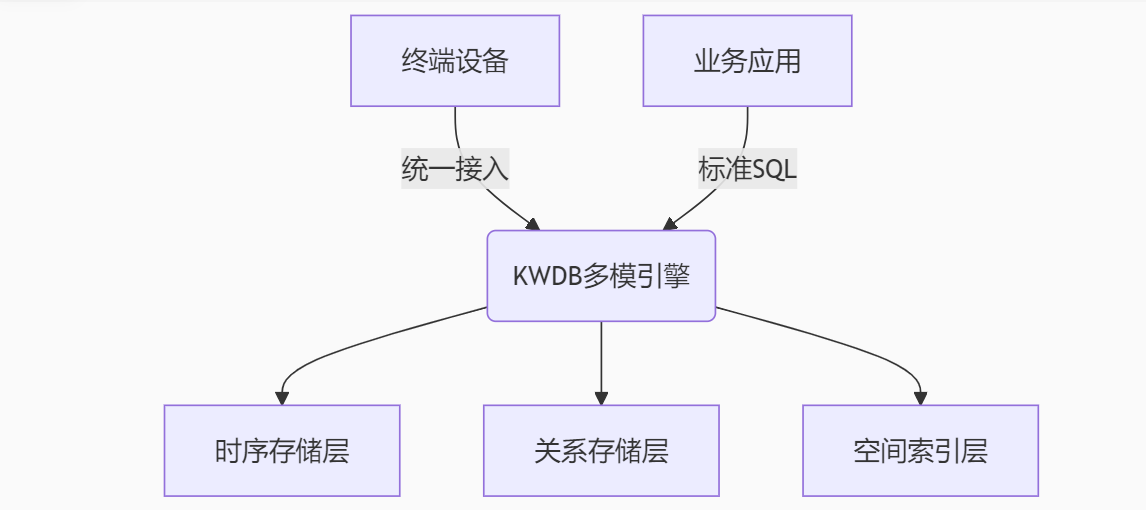
【KWDB创作者计划】_KWDB分布式多模数据库智能交通应用——高并发时序处理与多模数据融合实践
导读:本文主要探讨了基于KWDB的分布式多模数据库智能交通应用场景,进行了高并发时序处理与多模数据融合实践方向的思考。探索智慧交通领域的数据实时处理与存储资源利用方面的建设思路。
本文目录
一、智能交通数据架构革命
1.1 传统架构瓶颈
…

Java集合框架与三层架构实战指南:从基础到企业级应用
一、集合框架深度解析
1. List集合的武林争霸
ArrayList: 数组结构:内存连续,查询效率O(1) 扩容机制:默认扩容1.5倍(源码示例) private void grow(int minCapacity) {int oldCapacity elementData.len…

6个月Python学习计划 Day 2 - 条件判断、用户输入、格式化输出
6个月Python学习计划:从入门到AI实战(前端开发者进阶指南) Python 基础入门 & 开发环境搭建
🎯 今日目标
学会使用 input() 获取用户输入掌握 if/else/elif 条件判断语法熟悉格式化输出方式:f-string、format() …
目标检测 TaskAlignedAssigner 原理
文章目录 TaskAlignedAssigner 原理和代码使用示例 TaskAlignedAssigner 原理和代码
原理主要是结合预测的分类分数和边界框与真实标注的信息,找出与真实目标最匹配的锚点,为这些锚点分配对应的目标标签、边界框和分数。
TaskAlignedAssigner 是目标检…

游戏:元梦之星游戏开发代码(谢苏)
《元梦之星》是一款轻松社交派对游戏,玩家们可以化身星宝,体验纯粹的游玩乐趣,收获简单的快乐。无论i人e人,都能轻松找到属于自己的社交方式。 《元梦之星》的快乐,可以是闯关夺冠时的激动,谁是狼人推理的巧妙,峡谷3V3打赢团战的爽感。也可以是星梦广场开…
TCP协议原理与Java编程实战:从连接建立到断开的完整解析
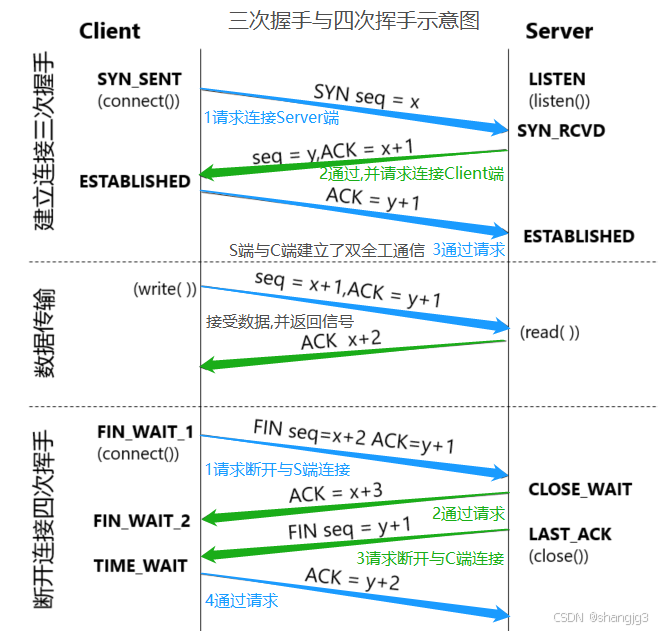
1.TCP协议核心:面向连接的可靠通信基石 TCP(Transmission Control Protocol,传输控制协议)是互联网的“可靠信使”,属于传输层协议,其核心在于面向连接和可靠传输。它通过严谨的握手机制与数据控制逻辑&am…

鸿蒙仓颉开发语言实战教程:实现商城应用详情页
昨天有朋友提到鸿蒙既然有了ArkTs开发语言,为什么还需要仓颉开发语言。其实这个不难理解,安卓有Java和Kotlin,iOS先后推出了Objective-C和Swift,鸿蒙有两种开发语言也就不奇怪了。而且仓颉是比ArkTs更加灵活的语言,虽然…
GitAny - 無需登入的 GitHub 最新倉庫檢索工具
地址:https://github.com/MartinxMax/gitany
GitAny - 無需登入的 GitHub 專案搜尋工具
GitAny 是一款基於 Python 的工具,允許你在無需登入的情況下搜尋當天最新的 GitHub 專案。它支援模糊搜尋、條件篩選以及倉庫資料的視覺化分析。 安裝依賴
$ pip…

在飞牛nas系统上部署gitlab
在飞牛nas系统上部署gitlab需要使用docker进行部署,如下将介绍详细的部署流程。 文章目录 1. docker镜像2. 拉取镜像3. 运行容器4. 运行和访问gitlab5. 一些小配置5.1 url问题5.2 ssh端口5.3 其他配置 1. docker镜像
首先需要找一个gitlab的docker镜像地址&#x…