地址:Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL

摘要
由于用户问题理解、数据库模式解析和 SQL 生成的复杂性,从用户自然语言问题生成准确 SQL(Text-to-SQL)仍是一项长期挑战。传统的 Text-to-SQL 系统结合人工设计和深度神经网络已取得显著进展,随后预训练语言模型(PLM)在该任务上也实现了有前景的结果。然而,随着现代数据库和用户问题日益复杂,参数规模有限的 PLM 常生成错误 SQL,这需要更精细的定制化优化方法,从而限制了基于 PLM 系统的应用。最近,大型语言模型(LLM)随着模型规模的增加,在自然语言理解方面展现出显著能力,因此集成基于 LLM 的解决方案可为 Text-to-SQL 研究带来独特的机遇、改进和解决方案。本综述全面回顾了现有基于 LLM 的 Text-to-SQL 研究,具体包括:简要概述 Text-to-SQL 的技术挑战和演变过程;介绍用于评估 Text-to-SQL 系统的数据集和指标;系统分析基于 LLM 的 Text-to-SQL 的最新进展;最后总结该领域的剩余挑战,并提出对未来研究方向的展望。
概括
1. 研究背景与意义
- 核心任务:Text-to-SQL 旨在将自然语言问题转换为可执行的 SQL 查询,作为数据库的自然语言接口(NLIDB),帮助非技术用户便捷访问结构化数据,提升人机交互效率。
- LLM 的价值:LLM 通过强大的语义解析能力和知识储备,可缓解传统模型在复杂语义理解和跨领域泛化上的不足,同时结合数据库内容可减少 LLM 的 “幻觉” 问题。
2. 技术演进历程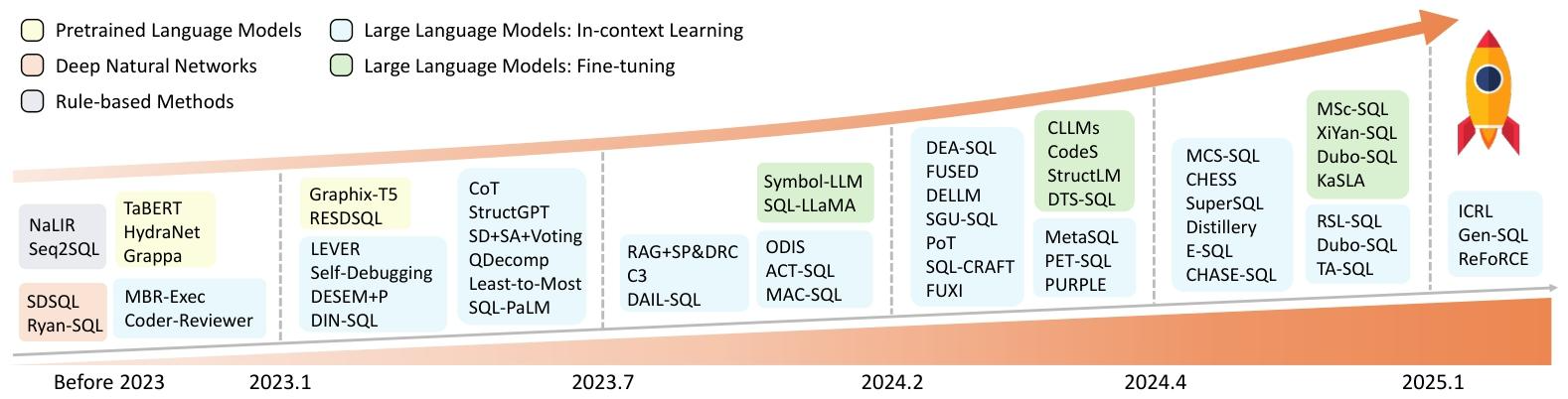
- 规则驱动阶段:早期依赖人工设计规则和模板,适用于简单场景,但难以处理复杂语义和模式变化。
- 深度学习阶段:基于序列到序列模型(如 LSTM、Transformer)和图神经网络(GNN),自动学习语义到 SQL 的映射,但存在语法错误和复杂操作生成困难。
- PLM 阶段:利用 BERT、RoBERTa 等预训练模型提升语义解析能力,引入模式感知编码优化数据库模式理解,但对复杂 SQL(如嵌套子查询)和跨领域泛化仍不足。
- LLM 阶段:通过上下文学习(ICL)和微调(FT)范式,结合思维链(CoT)、模式分解等技术,显著提升生成准确性,成为当前主流方向。
3. 关键挑战
- 语言复杂性与歧义性:自然语言的嵌套从句、指代消解等问题导致语义解析困难。
- 模式理解与表示:复杂数据库模式(多表关联、外键关系)的有效编码和匹配挑战。
- 复杂 SQL 操作生成:如窗口函数、外连接等低频操作的泛化能力不足。
- 跨领域泛化:不同领域的词汇、模式结构差异导致模型迁移能力弱。
- 计算效率与数据隐私:LLM 的高计算成本、长上下文处理限制,以及 API 调用中的数据泄露风险。
4. 未来研究方向
- 鲁棒性提升:针对真实场景中的噪声问题(如拼写错误、同义词),设计数据增强和抗干扰训练策略。
- 效率优化:通过模式过滤、模型压缩(如量化、剪枝)和本地部署,降低计算成本。
- 可解释性与隐私保护:结合注意力可视化、SHAP 值等技术提升模型透明度,探索联邦学习等隐私保护技术。
- 多模态与跨语言扩展:支持文本、图像等多模态输入,以及中文、越南语等跨语言场景。
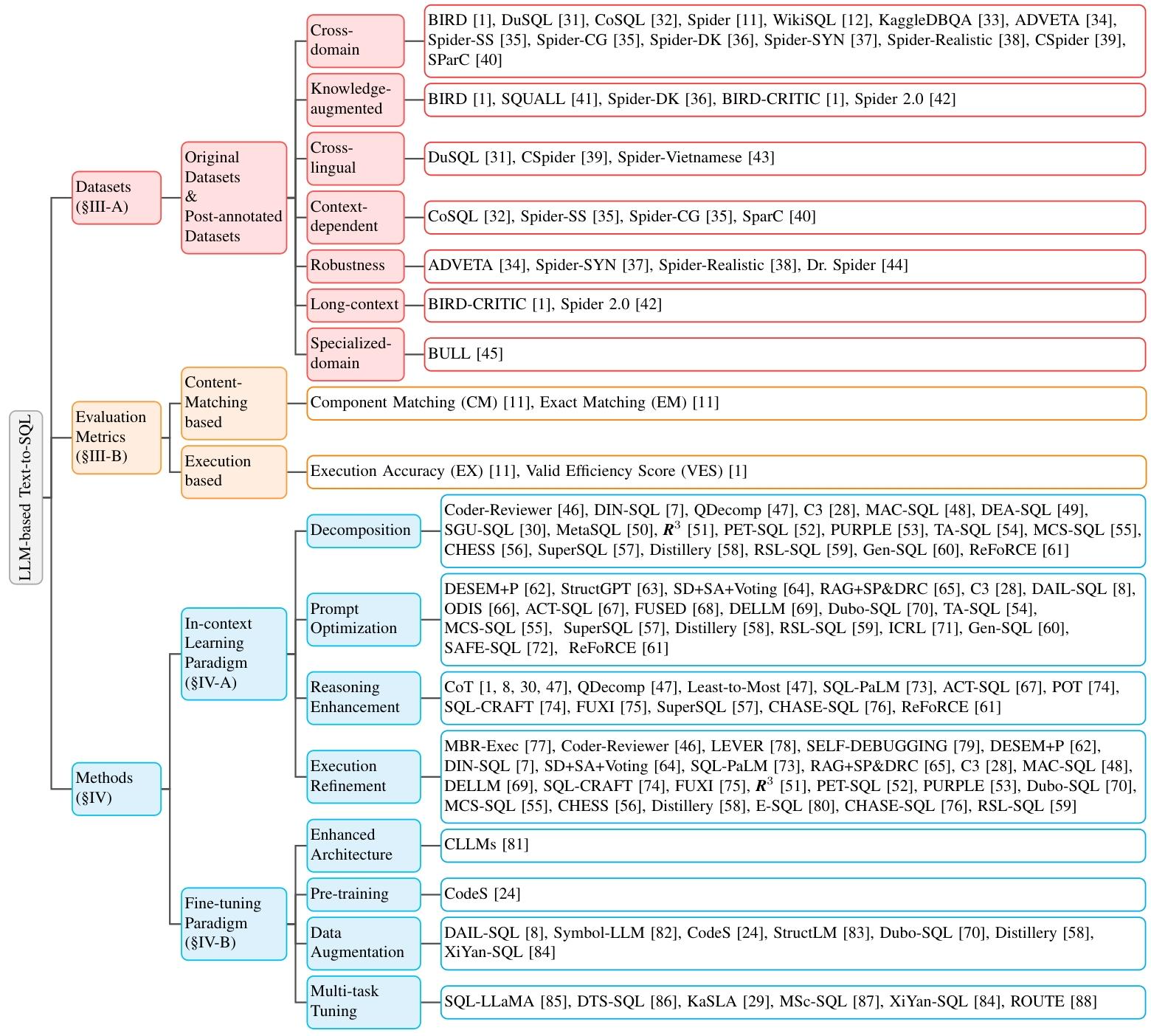
一、数据集
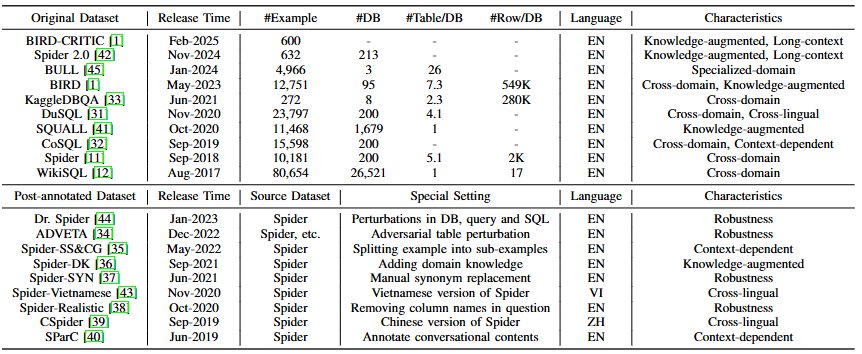
二、技术方法对比
1. 传统方法
| 方法 | 核心思想 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 规则驱动 | 人工设计规则和模板,通过语法匹配生成 SQL。 | 优点:语法准确率高,适合简单场景。 缺点:泛化能力差,无法处理复杂语义和跨领域问题,维护成本高。 | 在简单数据集(如早期 WikiSQL)表现稳定,但在复杂场景(如 Spider)中准确率低于 50%。 | CM、EM |
| 深度学习 | 使用序列到序列模型(LSTM/Transformer)或图神经网络(GNN)自动学习语义到 SQL 的映射。 | 优点:减少人工规则依赖,支持复杂语义解析。 缺点:易生成语法错误(如缺少 JOIN 子句),对低频 SQL 操作(如窗口函数)泛化能力弱。 | 在 Spider 数据集上 EX 约 60%-70%,但对嵌套查询处理不佳。 | EX、CM |
| 预训练语言模型(PLM) | 基于 BERT、RoBERTa 等预训练模型,结合模式感知编码优化数据库模式理解。 | 优点:语义解析能力强于传统深度学习,支持跨领域迁移。 缺点:参数规模有限,复杂场景下易出错,需大量微调数据。 | 在 Spider 数据集上 EX 提升至 75%-85%,但对多表关联和领域知识依赖场景仍不足。 | EX、EM |
2. 基于 LLM 的方法
(1)上下文学习(ICL)范式
| 子方法 | 核心策略 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 香草提示 | 零样本 / 少样本提示,直接拼接指令、问题和模式(如 SimpleDDL)。 | 优点:无需训练,快速部署。 缺点:零样本准确率低(如 ChatGPT 在 Spider 零样本 EX 约 50%),少样本依赖示例质量。 | 零样本 EX 约 40-60%,少样本(10-shot)EX 提升至 70-85%(如 GPT-4 在 BIRD 数据集)。 | EX、VES |
| 分解方法 | 将任务拆解为模式链接、SQL 生成、执行优化等阶段(如 DIN-SQL 的四阶段流水线)。 | 优点:降低复杂查询难度,提升逻辑连贯性。 缺点:多阶段流水线可能引入级联错误。 | 在 Spider 2.0 数据集上 EX 达 82%,优于单阶段模型。 | EX、CM |
| 提示优化 | 基于语义相似度 / 多样性选择少样本示例,过滤冗余模式(如 C3 的模式蒸馏)。 | 优点:减少输入冗余,提升示例相关性。 缺点:依赖高质量标注数据或外部检索工具。 | 在 ADVETA(对抗性数据集)上 EX 提升 15-20%,鲁棒性增强。 | EX、VES |
| 推理增强 | 通过思维链(CoT)或多路径推理引导 LLM 生成中间步骤(如 ACT-SQL 的自动 CoT 生成)。 | 优点:提升复杂查询的逻辑可解释性。 缺点:计算成本增加(如生成推理步骤耗时延长 2-3 倍)。 | 在 BIRD-CRITIC(长上下文数据集)上 EX 达 85%,优于无 CoT 基线。 | EX、EM |
| 执行优化 | 利用数据库执行结果反馈修正 SQL(如 Self-Debugging 的错误解释引导)。 | 优点:通过执行验证提升准确率。 缺点:依赖数据库实时访问,不适用于离线场景。 | 在 Spider-Realistic(缺失列名场景)上 EX 从 60% 提升至 80%。 | EX、VES |
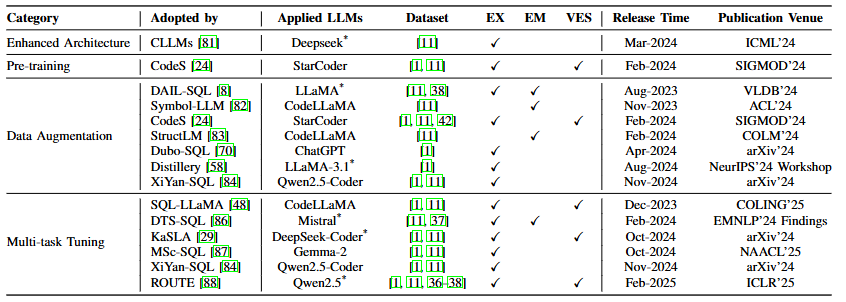
分解方法、
提示优化、
推理增强、
执行优化
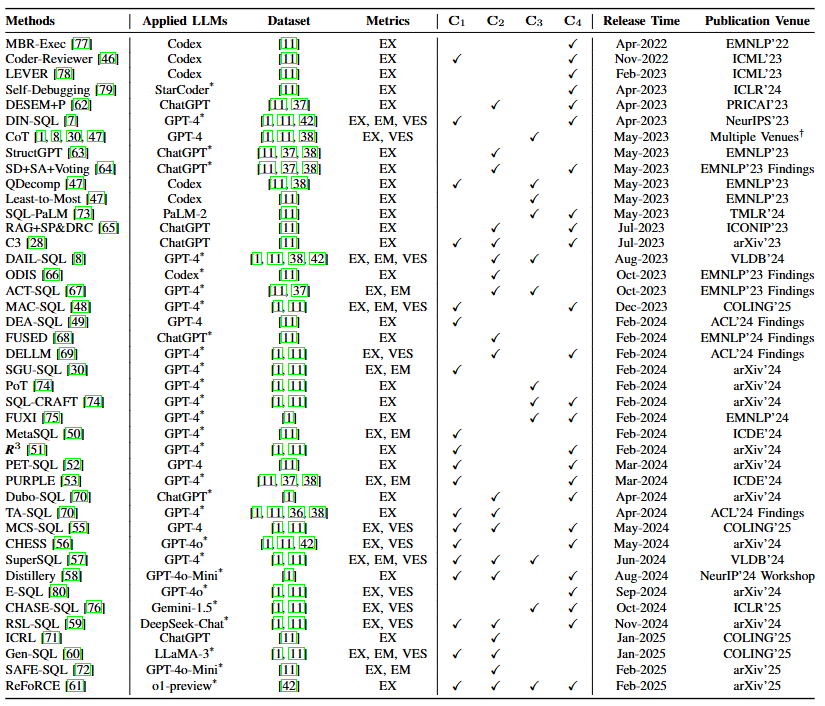
(2)微调(FT)范式
| 子方法 | 核心策略 | 优缺点 | 性能表现 | 评价指标 |
|---|---|---|---|---|
| 增强架构 | 设计专用解码模块加速 SQL 生成(如 CLLMs 的结构感知解码)。 | 优点:推理速度提升 30-50%,适合实时应用。 缺点:架构复杂度高,需定制开发。 | 在本地部署场景下延迟低于 100ms,EX 保持 80% 以上。 | EX、执行效率 |
| 预训练 | 在代码数据(如 StarCoder)上预训练,结合 SQL-specific 数据增强(如 CodeS 的三阶段预训练)。 | 优点:提升语法生成能力,减少 “幻觉”。 缺点:需大量计算资源(如训练成本是传统 PLM 的 5-10 倍)。 | 在 WikiSQL 数据集上 EX 达 90%,超越多数 ICL 方法。 | EX、EM |
| 数据增强 | 利用 ChatGPT 生成合成数据或骨架掩码增强多样性(如 SAFE-SQL 的自增强示例)。 | 优点:缓解数据稀缺问题,提升泛化能力。 缺点:合成数据可能引入偏差。 | 在低资源场景(如 1k 标注样本)下 EX 达 75%,优于基线。 | EX、数据效率 |
| 多任务调优 | 分阶段训练模式链接和 SQL 生成任务(如 DTS-SQL 的两阶段框架)。 | 优点:模块化训练提升跨领域能力。 缺点:训练流程复杂,需协调多任务平衡。 | 在跨领域数据集(如 CoSQL)上 EX 达 83%,优于单任务模型。 | EX、跨领域准确率 |
3. 传统方法 vs. LLM 方法
| 维度 | 传统方法 | LLM 方法 |
|---|---|---|
| 语义理解 | 依赖人工特征或浅层语义解析,歧义处理能力弱。 | 通过大规模预训练捕捉深层语义,CoT 等技术缓解歧义。 |
| 复杂操作支持 | 仅支持高频 SQL 语法,低频操作(如外连接)生成困难。 | 通过代码预训练和少样本示例,支持复杂操作(如窗口函数)。 |
| 跨领域泛化 | 需依赖领域特定微调,迁移成本高。 | ICL 范式通过少样本示例快速适应新领域(如 Spider-DK)。 |
| 计算成本 | 推理速度快,但训练需大量人工设计。 | ICL 依赖高成本 API 调用,FT 需大规模训练资源。 |
| 可解释性 | 规则或模型结构透明(如 GNN 的图节点注意力)。 | 黑箱模型,需依赖 SHAP/LIME 等后验解释工具。 |
三、评价指标总结
| 指标类型 | 指标名称 | 定义 | 适用场景 |
|---|---|---|---|
| 内容匹配 | 组件匹配(CM) | 计算 SELECT、WHERE 等 SQL 组件的 F1 分数,允许顺序无关匹配。 | 语法结构验证,不依赖数据库执行。 |
| 完全匹配(EM) | 预测 SQL 与真实 SQL 完全一致的比例。 | 严格语法正确性评估。 | |
| 执行结果 | 执行准确率(EX) | 执行预测 SQL 后,结果与真实结果一致的比例。 | 端到端功能验证,反映实际可用性。 |
| 有效效率分数(VES) | 结合执行结果正确性和效率(如执行时间)的综合指标,公式为 | 生产环境性能与准确性平衡评估。 |
四、性能对比与典型案例
| 方法 | 模型 | 数据集 | EX | EM | VES | 计算成本 |
|---|---|---|---|---|---|---|
| 规则驱动 | GRAPPA | Spider | 45% | 30% | - | 低(无训练成本) |
| 深度学习 | RyenSQL | Spider | 68% | 55% | - | 中(需 GPU 训练) |
| PLM | TaBERT | Spider | 78% | 65% | - | 中(预训练模型微调) |
| LLM-ICL | DIN-SQL (GPT-4) | BIRD | 89% | 82% | 0.85 | 高(API 调用成本) |
| LLM-FT | CodeS (StarCoder) | Spider 2.0 | 85% | 78% | 0.82 | 极高(三阶段预训练) |
五、未来趋势
- 混合架构:LLM + 传统符号系统(如规则引擎、知识库),平衡生成灵活性与逻辑严谨性(如 Tool-SQL 的检索器 + 检测器)。
- 自监督进化:利用无标注数据(如数据库日志)进行自训练,持续优化模型(如 Distillery 的失败案例迭代学习)。
- 边缘智能:针对本地化部署,开发轻量化模型(如量化 LLM)和增量更新策略(如在线学习适配新 Schema)。

![QT软件开发环境及简单图形的绘制-图形学(实验一)-[成信]](https://i-blog.csdnimg.cn/direct/27a173713d3843f69cb818e63e0ca36a.png)