一、JPA
以下是对 JPA(Java Persistence API) 的深入详解,适用于具备一定 Java EE / Jakarta EE 背景的开发者,尤其是对数据持久化机制感兴趣的人员。
1、什么是 JPA?
Java Persistence API(JPA) 是 Java EE / Jakarta EE 标准中的一种 ORM(对象关系映射) 规范,它定义了一组用于管理 Java 对象与关系数据库之间映射关系的接口。
JPA 本身是一个规范,它不提供实现。常见的 JPA 实现包括:
-
Hibernate(最流行,也是 JPA 的参考实现)
-
EclipseLink(前身是 Oracle 的 TopLink)
-
OpenJPA(Apache 项目)
2、核心概念
1. 实体类(Entity)
-
使用
@Entity注解标识,是 JPA 管理的 POJO。 -
每个实体类对应数据库中的一张表。
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "username", nullable = false, unique = true)
private String username;
@Column(name = "email")
private String email;
// getters and setters
}
2. 主键(@Id, @GeneratedValue)
-
@Id:标注实体类的主键字段。 -
@GeneratedValue:指定主键的生成策略(如自增、序列等)。
主键生成策略包括:
-
AUTO: 自动选择策略(由 JPA 提供者决定) -
IDENTITY: 数据库自增 -
SEQUENCE: 使用数据库序列(Oracle、PostgreSQL等) -
TABLE: 使用表记录主键值(适用于无序列的数据库)
3. 实体管理器(EntityManager)
用于管理实体生命周期,包括:
-
新增(
persist()) -
查询(
find()、createQuery()) -
更新(
merge()) -
删除(
remove())
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
User user = new User();
user.setUsername("admin");
em.persist(user); // 新增
em.getTransaction().commit();
em.close();
4. 查询语言(JPQL / Criteria API)
JPQL(Java Persistence Query Language)
类似 SQL,但面向的是实体类和属性,而不是表和字段。
List<User> users = em.createQuery("SELECT u FROM User u WHERE u.username = :name", User.class)
.setParameter("name", "admin")
.getResultList();
Criteria API
以面向对象的方式构造查询,适合动态条件构建。
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery<User> query = cb.createQuery(User.class);
Root<User> root = query.from(User.class);
query.select(root).where(cb.equal(root.get("username"), "admin"));
List<User> users = em.createQuery(query).getResultList();
5. 映射关系
一对一
@OneToOne
@JoinColumn(name = "profile_id")
private UserProfile profile;
一对多 / 多对一
@OneToMany(mappedBy = "user")
private List<Order> orders;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
多对多
@ManyToMany
@JoinTable(name = "user_roles",
joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "role_id"))
private List<Role> roles;
3、生命周期与状态转换
实体对象有以下几种状态:
| 状态 | 说明 |
|---|---|
| New | 新建对象,尚未与数据库绑定 |
| Managed | 与数据库中的一条记录关联 |
| Detached | 曾经被管理,现在被 EntityManager 分离 |
| Removed | 被标记为删除状态,事务提交后会被删除 |
4、事务管理(与 WAS 等容器的集成)
-
在 WAS 或 Spring 容器中,JPA 通常与事务管理器集成,配合
@Transactional注解使用。 -
在 Java EE 中,通过
@PersistenceContext注入EntityManager,自动绑定事务上下文。
@PersistenceContext
private EntityManager em;
@Transactional
public void createUser(User user) {
em.persist(user);
}
5、JPA 的优缺点
优点:
-
屏蔽数据库差异(可移植性高)
-
面向对象设计更自然,代码结构清晰
-
适合中大型应用的数据持久化层
缺点:
-
性能开销高于 JDBC(尤其在极限性能需求下)
-
学习曲线相对较高,特别是复杂关联映射和懒加载问题
-
与底层数据库调优结合不紧密
6、在企业级系统(如 BAW/WAS)中的应用场景
-
配合 EJB 或 Spring 服务层进行持久化操作
-
实现业务对象和数据库映射,提高业务逻辑的抽象度
-
利用 JPA 实现可扩展、维护性强的业务系统数据访问层
二、例子
下面是在 IBM BAW(Business Automation Workflow) 中使用 JPA(Java Persistence API)的实际应用,尤其是结合 Java 集成服务(Java Integration Service) 的使用场景,包括:
-
BAW 中使用 JPA 的典型场景
-
实践:创建基于 JPA 的 Java 集成服务
-
项目结构与配置详解
-
示例代码
-
事务管理与注意事项
1、BAW 中使用 JPA 的典型场景
在 IBM BAW 中,你可能会通过 Java 集成服务访问数据库以实现以下需求:
-
将流程变量保存为数据库记录(如表单数据、审批记录)
-
从数据库读取外部业务数据作为决策依据
-
持久化非流程类数据,如日志记录、审计信息、业务统计
如果你希望使用 ORM 的方式优雅地操作数据库,而不是 JDBC,那么就可以集成 JPA。
2、实践:使用 Java 集成服务调用 JPA
假设场景:
流程审批结束后,将审批结果(如 流程ID、审批人、审批意见、时间戳)持久化存储到业务数据库的 APPROVAL_LOG 表中。
3、工程结构与配置(外部项目)
你需要在 Process Designer 中的 Java 集成服务中引用一个外部构建的 JAR 包,该 JAR 是使用 Maven 或 Gradle 构建的 JPA 项目:
src/main/java
├── com.example.baw.jpa
│ ├── ApprovalLog.java # 实体类
│ ├── ApprovalLogService.java # 业务类
│ └── JpaUtil.java # 实用工具类(EntityManager 工厂)
resources
└── META-INF/persistence.xml # JPA 配置
4、关键代码说明
1. 实体类(ApprovalLog.java)
@Entity
@Table(name = "APPROVAL_LOG")
public class ApprovalLog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String processId;
private String approver;
private String comment;
@Temporal(TemporalType.TIMESTAMP)
private Date timestamp;
// getters & setters
}
2. persistence.xml(位于 META-INF)
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence"
version="2.1">
<persistence-unit name="baw-approval-unit">
<class>com.example.baw.jpa.ApprovalLog</class>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/bawdb"/>
<property name="javax.persistence.jdbc.user" value="bawuser"/>
<property name="javax.persistence.jdbc.password" value="bawpass"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL8Dialect"/>
<property name="hibernate.show_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
3. EntityManager 工具类(JpaUtil.java)
public class JpaUtil {
private static final EntityManagerFactory emf =
Persistence.createEntityManagerFactory("baw-approval-unit");
public static EntityManager getEntityManager() {
return emf.createEntityManager();
}
}
4. 服务类(ApprovalLogService.java)
public class ApprovalLogService {
public void saveApprovalLog(String processId, String approver, String comment) {
EntityManager em = JpaUtil.getEntityManager();
try {
em.getTransaction().begin();
ApprovalLog log = new ApprovalLog();
log.setProcessId(processId);
log.setApprover(approver);
log.setComment(comment);
log.setTimestamp(new Date());
em.persist(log);
em.getTransaction().commit();
} catch (Exception e) {
em.getTransaction().rollback();
throw new RuntimeException("Failed to save approval log", e);
} finally {
em.close();
}
}
}
5、在 BAW 中集成使用
步骤:
-
使用 Maven 打包为 JAR:
mvn clean install -
将生成的
baw-jpa-approval.jar添加到 BAW 的 Process Designer 的 Java 集成服务 的类路径中 -
在 Java 集成服务中调用:
ApprovalLogService service = new ApprovalLogService();
service.saveApprovalLog(
tw.local.processId,
tw.local.currentUser,
tw.local.approvalComment
);
将流程变量映射到调用参数,实现数据落库。
6、事务管理与注意事项
1. 事务必须在 Java 代码中开启/提交
因为 Java 集成服务并不自动管理事务,所以你必须显式调用 begin() 和 commit()。
2. 数据源配置
你可以通过以下两种方式指定数据源:
-
在
persistence.xml中配置 JDBC 连接信息(如上所示) -
使用 BAW / WAS 中配置的 JNDI 数据源(推荐生产使用)
<property name="javax.persistence.nonJtaDataSource" value="jdbc/YourDataSource"/>
并在 WAS 中配置该 JNDI 数据源。
7、小结
| 项目 | 说明 |
|---|---|
| 实体类定义 | @Entity 注解类映射数据库表 |
| JPA 配置位置 | META-INF/persistence.xml |
| 数据源推荐 | 使用 JNDI 引用 WAS 中配置的数据源 |
| 调用方式 | Java 集成服务中直接 new 调用 |
| 事务控制 | 代码中显式开启/提交事务 |
三、示例:部署到 BAW 的 Process Server
将使用 JPA 实现的持久化逻辑部署到 IBM BAW Process Server,一般通过打包为 JAR 并让 Java 集成服务 或 自定义服务调用。下面是一个完整部署过程的详细讲解:
1、目标
将一个使用 JPA 的 Java 模块(如 ApprovalLogService)部署到 BAW 流程服务中,并能在 Java 集成服务中调用。
2、部署结构总览
你需要准备以下几个部分:
-
JAR 包(含实体类、JPA 工具类、服务类)
-
数据源配置(WAS 控制台中配置 JNDI 数据源)
-
JPA 配置文件(
META-INF/persistence.xml) -
Java 集成服务(在 Process Designer 中编写,调用你的服务类)
-
流程变量映射与测试
3、步骤详解
1. 创建并打包 JAR 文件
推荐使用 Maven:
mvn clean package
确保 target/your-module.jar 中包含:
-
实体类(
@Entity) -
persistence.xml -
所有依赖类(如
ApprovalLogService.java、JpaUtil.java)
如果使用 Hibernate,请确认将其依赖(hibernate-core 等)也打包进来(可选用 shaded jar 或部署额外依赖)。
2. 上传 JAR 到 BAW 运行环境
你可以通过以下几种方式部署 JAR:
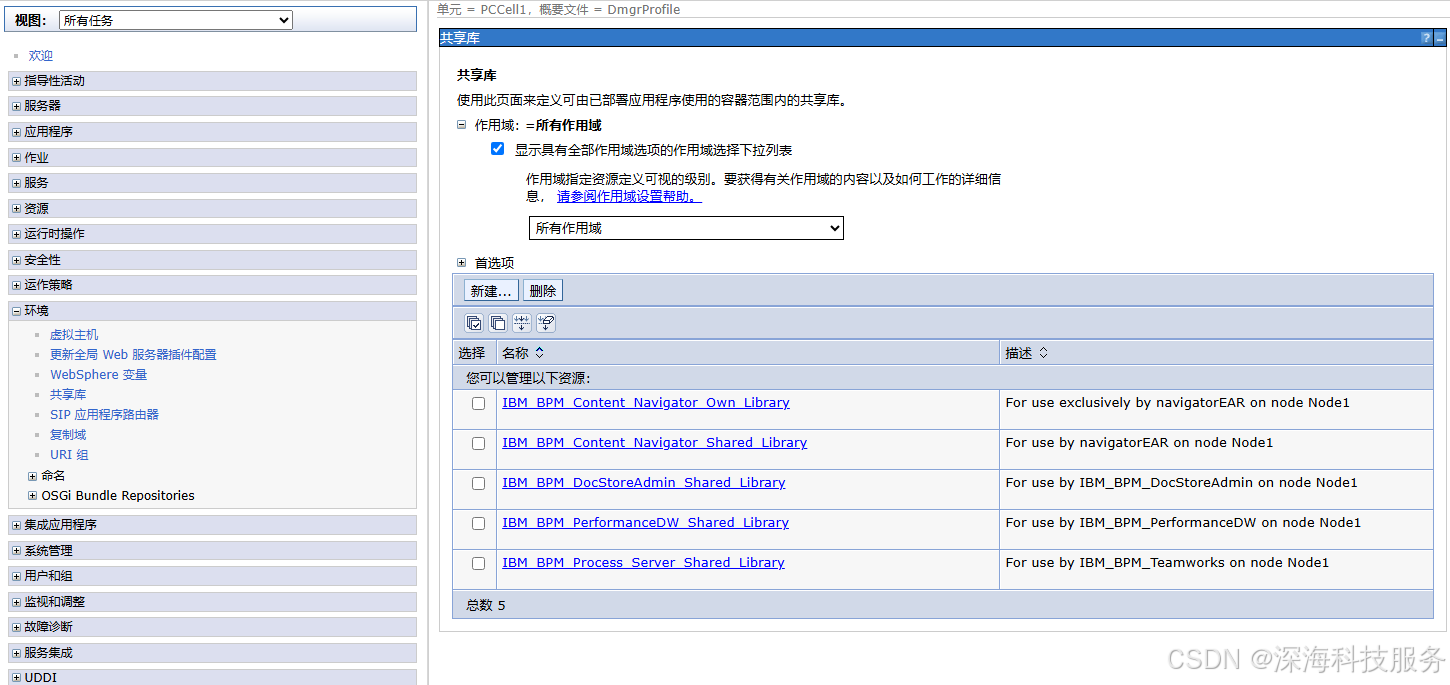
方法一:WAS 共享库方式(推荐)
-
打开 WebSphere Application Server 控制台
-
进入:环境 > 共享库
-
创建新的共享库,例如
baw-jpa-lib-
指定
Classpath为你的 JAR 包路径,例如:/opt/IBM/Jars/baw-jpa-approval.jar
-
-
进入
应用程序服务器 > server1 > Java 和进程管理 > 类装入器-
将刚创建的共享库添加为
共享库引用
-
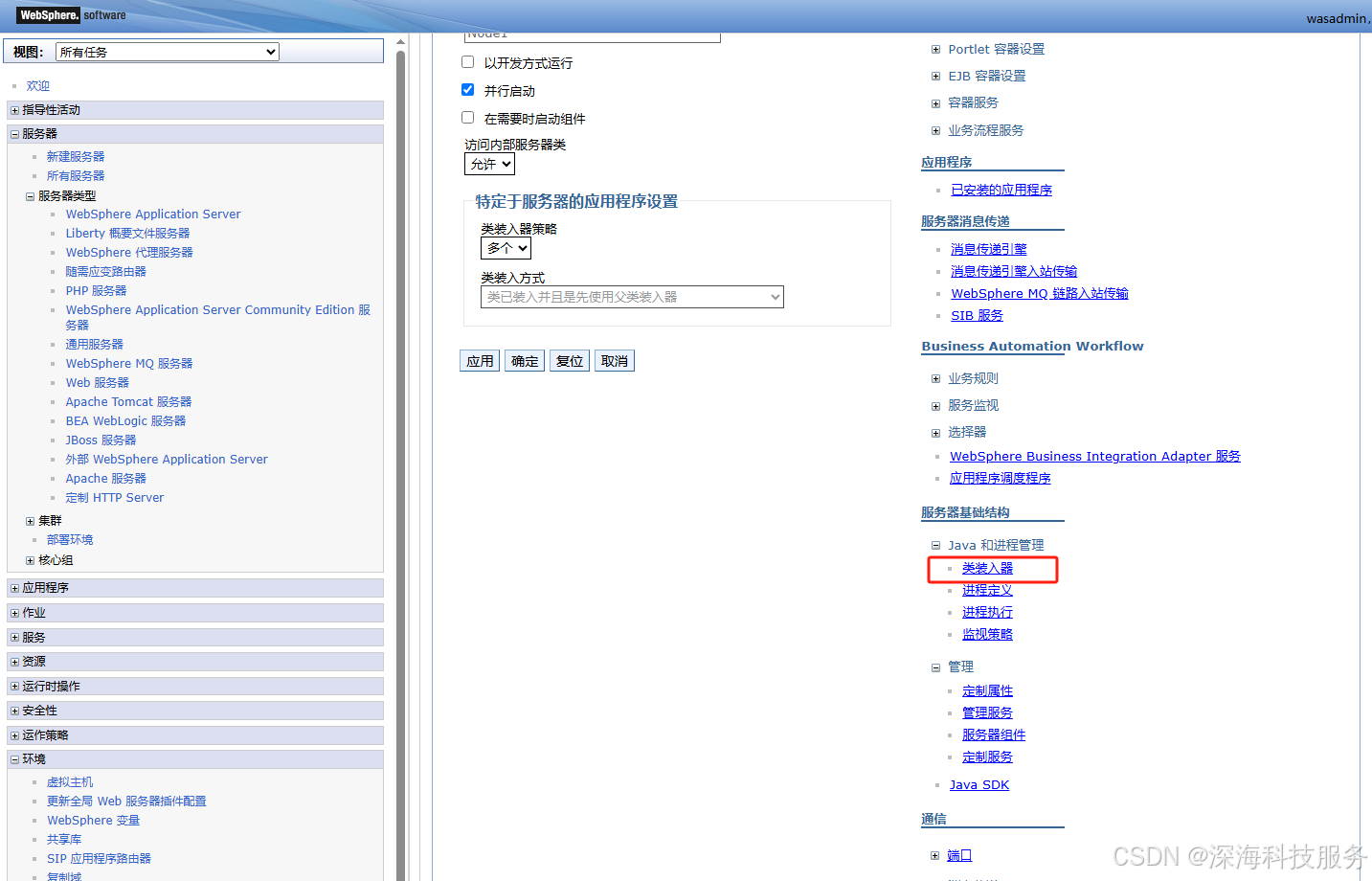
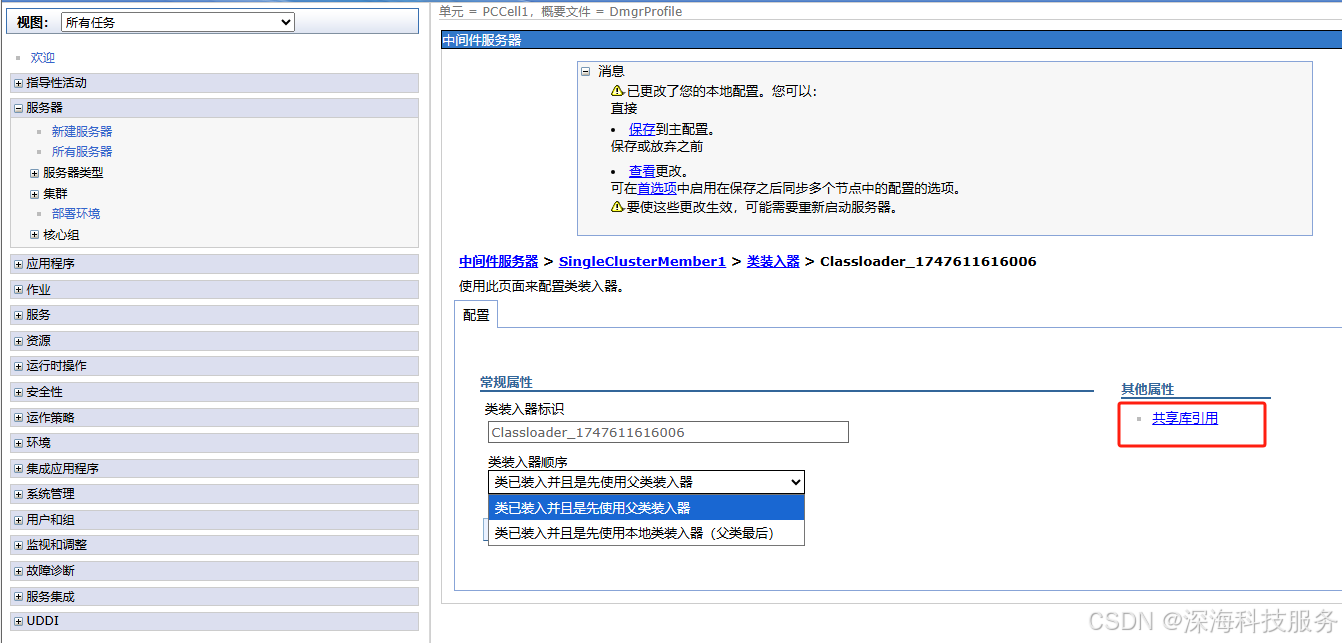
-
编辑类装入器设置:
-
选择“类装入器”
-
类型建议选择:服务器级别(如已有项,点击进入即可)
-
-
找到“共享库引用(Shared Library References)”
-
点击“新建”,绑定你刚刚创建的
JPA-Library共享库 -
保存并同步配置
-
重启服务器(server1)
方法二:直接打包进 Process App(不推荐)
你也可以在 Process Designer 中通过 Manage Toolkit Dependencies → Add External JAR 来导入 JAR。
在流程设计中调用
步骤一:创建一个新的 Toolkit(如果尚未创建)
-
打开 IBM Process Designer。
-
在“工具包”视图中点击“新建”按钮。
-
填写 Toolkit 名称,例如:
CustomJavaLibToolkit -
勾选你想支持的依赖类型(如集成服务、业务对象等),点击“完成”。
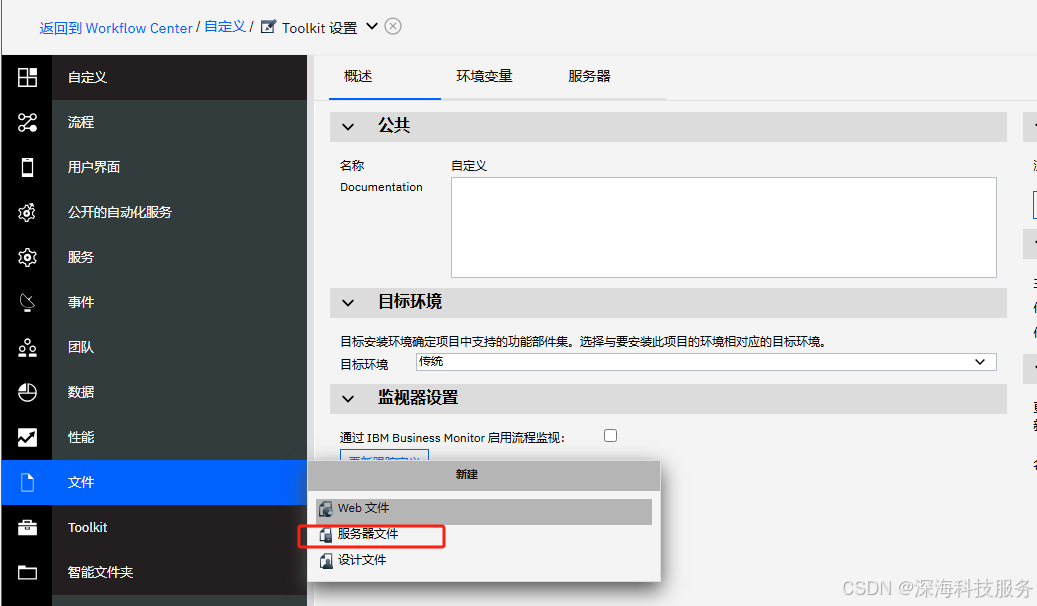
步骤二:导入 JAR 到服务器文件(Server File)
-
打开你刚创建的 Toolkit。
-
在左侧导航栏选择:
实现 (Implementation)>文件 (Files)。 -
点击“新建” > 选择“服务器文件 (Server File)”
-
上传你的 JAR 文件(例如
my-jpa-lib.jar) -
上传成功后,保存并发布(Snapshot)Toolkit。
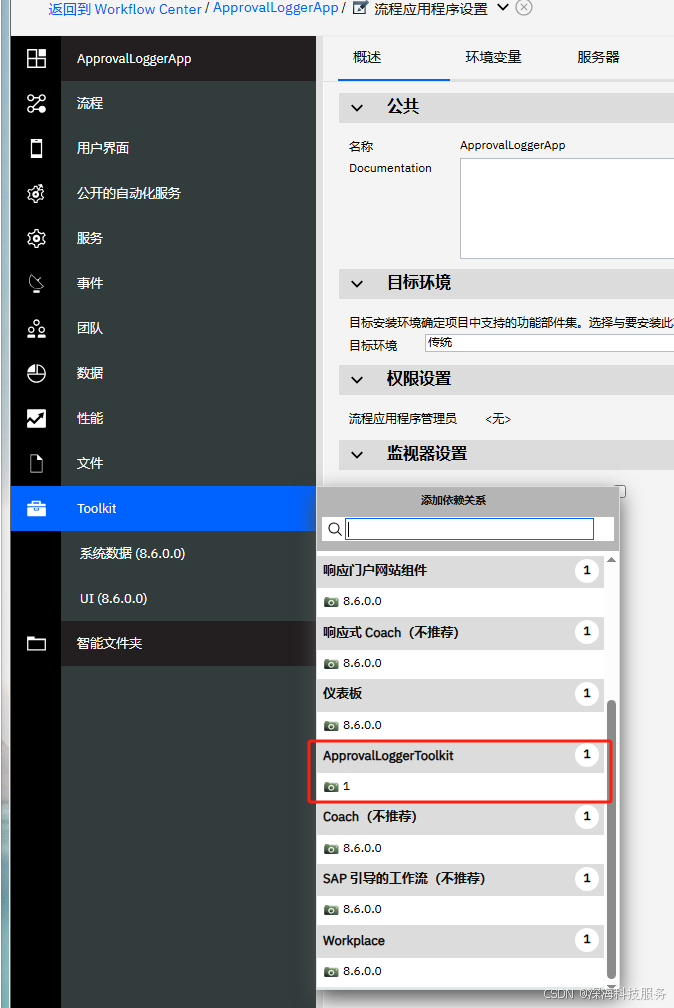
步骤三:在你的 Process App 中引用这个 Toolkit
-
打开目标流程应用(Process App)。
-
在“依赖项”中添加你刚刚创建的
CustomJavaLibToolkit。 -
保存并同步。
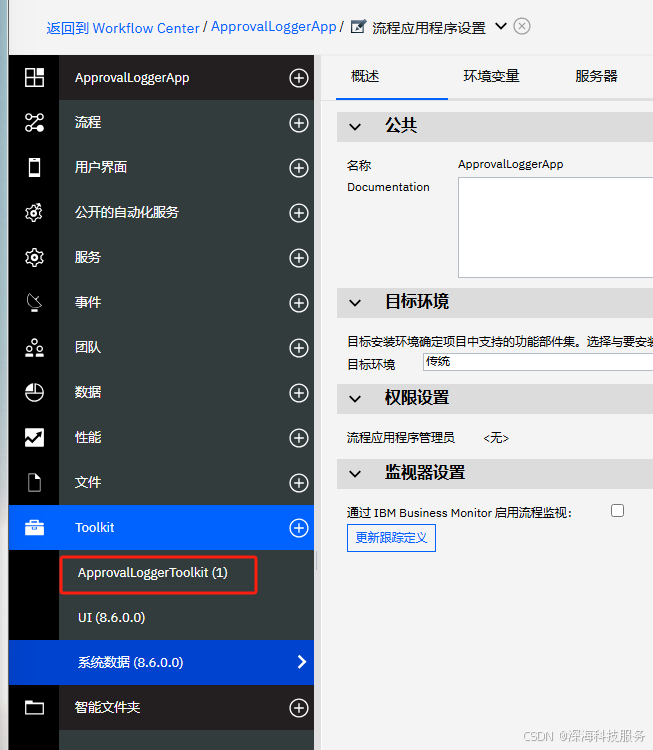
步骤四:在 Java 集成服务中调用 JAR 中的类
-
新建或打开一个 Java 集成服务。
-
在
Java 代码区域中,你就可以直接导入并使用 JAR 中的类了:
import com.example.util.MyHelper;
MyHelper h = new MyHelper();
h.doSomething();
注意事项:
| 项目 | 说明 |
|---|---|
| 类可见性 | 上传的 JAR 会添加到 classpath,Java 服务中可直接调用 |
| 不能用于 BPD 脚本任务 | BPD 的脚本任务只能运行 JavaScript,无法引用 JAR |
| 避免类冲突 | 确保上传的 JAR 不与 BAW 内置库冲突(如 slf4j、commons) |
| JAR 尽量瘦身 | 保持 JAR 小巧、只放你自定义的逻辑类或 DAO 等 |
示例使用场景
比如你要在审批节点中记录一条操作日志到数据库:
ApprovalLogger logger = new ApprovalLogger();
logger.log("User123", "审批通过", "2025-05-18");
其中 ApprovalLogger 类已打包在你上传的 my-baw-utils.jar 中。
3. 配置 JNDI 数据源(推荐)
若你在 persistence.xml 中使用的是:
<property name="javax.persistence.nonJtaDataSource" value="jdbc/bawDS"/>
那你需要在 WAS 控制台中创建名为 jdbc/bawDS 的数据源:
-
资源 > JDBC > 数据源
-
点击新建,填写:
-
JNDI 名称:
jdbc/bawDS -
选择合适的 JDBC 提供程序(如 MySQL 或 Oracle)
-
配置数据库连接信息、驱动、测试连接
-
若使用硬编码的
jdbc:mysql://...方式,可在persistence.xml中直接提供连接参数,但 不推荐用于生产。
4. 使用 Java 集成服务调用
在 Process Designer 中:
-
创建 Java Integration Service
-
在 Java 代码中导入服务类并调用:
import com.example.baw.jpa.ApprovalLogService;
ApprovalLogService service = new ApprovalLogService();
service.saveApprovalLog(
tw.local.processId,
tw.local.approver,
tw.local.comment
);
Java 服务中访问的类必须能在类加载器中加载到 —— 所以共享库配置必须生效。
5. 流程变量映射与测试
确保在流程模型中设置了以下变量,并绑定到 Java 服务的输入:
| 变量名 | 类型 |
|---|---|
| processId | String |
| approver | String |
| comment | String |
通过 Web Process Designer 运行流程,流程结束后,在数据库中应能看到持久化的记录。
4、调试与问题排查
| 问题 | 原因 |
|---|---|
ClassNotFoundException | JAR 未添加到共享库或类加载器不正确 |
NoPersistenceUnitException | persistence.xml 配置路径或名称不正确 |
| 无法连接数据库 | 数据源 JNDI 错误或未启用 |
| Hibernate 抛出 dialect 不支持错误 | 缺少 Hibernate 配置或使用了错误版本 |
javax.persistence.TransactionRequiredException | 未正确开启事务 |
5、小结
| 项目 | 操作 |
|---|---|
| JAR 部署 | 使用 WAS 的共享库 |
| 数据库连接 | 使用 JNDI 数据源 jdbc/xxx |
| 流程中调用服务 | Java 集成服务调用你编写的 JPA 服务类 |
| 类加载 | 类必须加载到正确的类加载器 |