1.什么是短链
短链接(Short URL) 是通过算法将长 URL 压缩成简短字符串的技术方案。例如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,用户点击短链时会自动重定向到原始长链接。其核心价值在于通过 空间压缩 和 统一管理 解决长链接在传播中的实际问题。
2.为什么需要短链
2.1 突破字符限制
例如微博,Twitter等平台对内容长度严格要求(如微博140字),长链接会占用大量文本空间。
2.2 降低短信成本
短信按长度计费,长链接可能导致单条短信拆分为多条,同时使用短链可将短信长度减少50%以上,降低发送成本
2.3 精准统计
每次短链跳转需经过服务器(基于302临时重定向),可记录点击时间,地域,来源等数据,用于数据分析
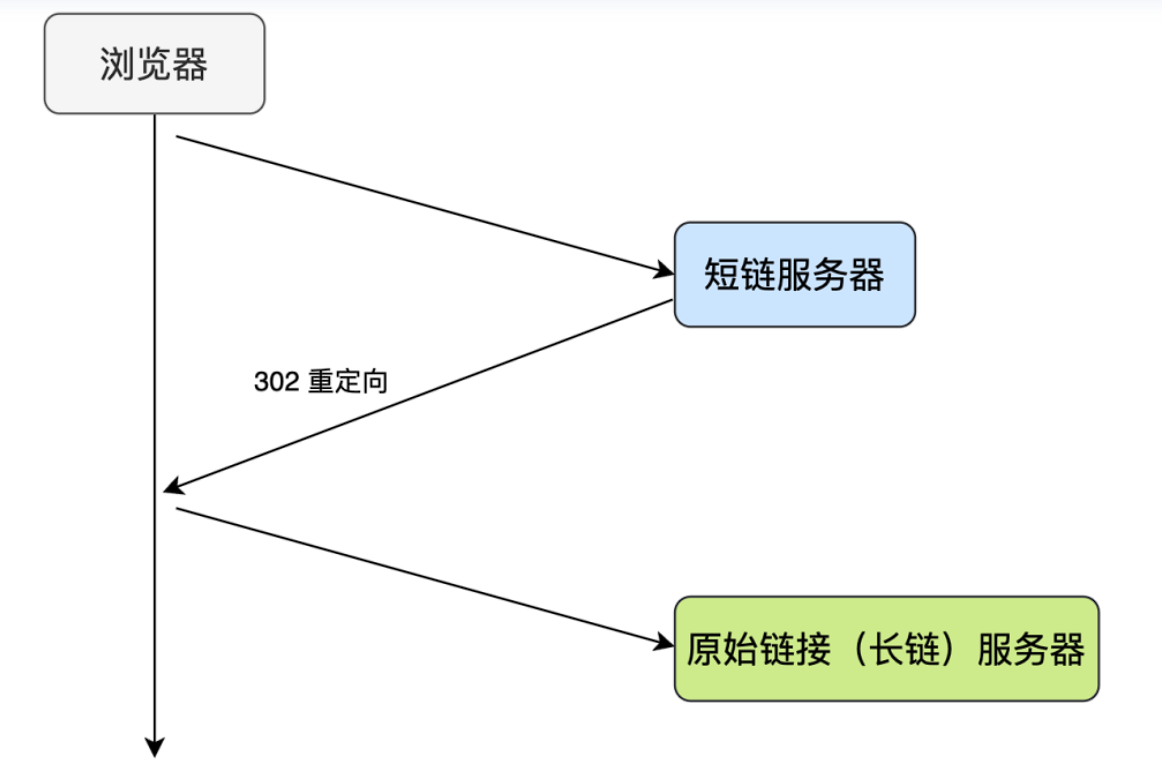
3.短链跳转原理
- 用户点击短链 ---> 浏览器向短链服务器发送请求
- 服务器响应 : 返回302 Found状态码 + Location 头部 (包含原始长链接)
- 浏览器二次请求:根据Location 跳转至长链接,获取最终长度
为什么选择302不选择301
| 特性 | 301 永久重定向 | 302 临时重定向 |
| 缓存策略 | 浏览器永久缓存短链-长链映射 | 每次请求需回源服务器(可配置弱缓存) |
| 数据统计 | 无法追踪后续点击(依赖缓存) | 可精准统计每次点击 |
| 适用场景 | 永久不变的资源(如文件迁移) | 需动态统计的短链(如营销链接) |
结论:短链服务必须使用302 ,否则会因浏览器缓存导致点击数据丢失,影响业务分析
4.短链生成技术
4.1哈希算法(适合海量数据场景)
核心流程
- 长链--->哈希值:使用MurmurHash 算法(非加密型哈希,速度快,冲突率低)生成32位或128位哈希值
- 进制转换:将十进制哈希值转换为62进制(使用字符0-9a-zA-Z,共62个字符),缩短长度
- 拼接域名:生成短链 http://sourl.cn/xxx
优化
- 数据库唯一索引:为短链字段添加唯一索引,插入时利用数据库特性自动判重
- 流程:生成短链--->尝试插入数据库--->若报唯一冲突,则重新哈希
- 布隆过滤器优化:提前将已生成的短链存入布隆过滤器,新短链生成时先过滤,减少90%以上的数据库查询
- 优势:空间复杂度低(100万条数据仅需 1MB内存),查询时间O(1)
4.2 ID 自增生成器(适合有序场景)
核心流程
- 维护自增 ID :使用数据库自增字段或分布式 ID 生成器(如雪花算法)生成1,2,3....序列
- 进制转换:将 ID 转换为 62 进制,拼接域名生成短链
优化
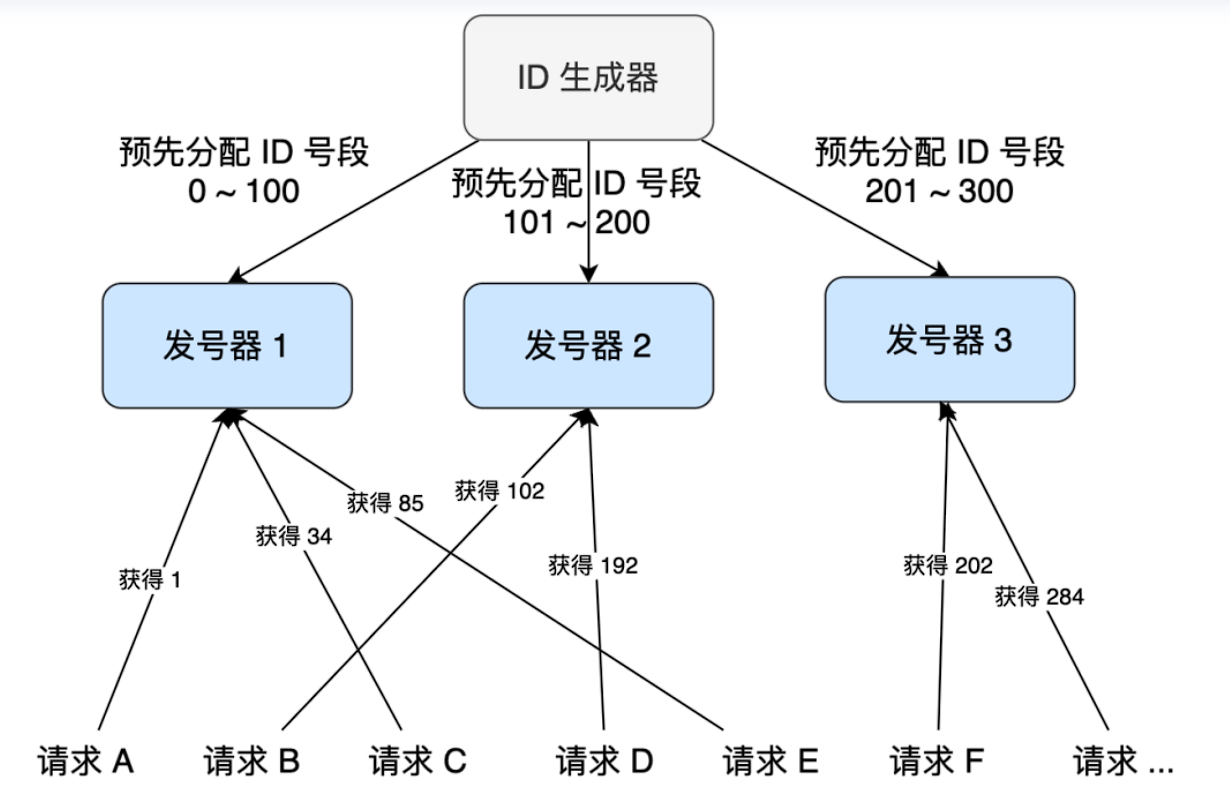
- 多发号器架构:主服务器预分配 ID 段,各发号器无锁并发生成ID
- 重复长链处理: 对长链做 MD5 哈希,存入数据库并建立唯一索引,确保相同长链生成同一短链。
5.进阶优化
5.1缓存策略
短链--->长链映射缓存:使用redis存储热点短链,减少数据库压力
弱缓存机制:对302响应添加 Cache-control:max-age=60,允许浏览器缓存1分钟,降低回源压力
5.2高可用设计
分布式架构:短链服务,数据库,缓存均采用集群部署,避免单点故障
异步写入:将短链---长链映射写入操作异步化,提升接口吞吐量
5.3安全
URL 过滤:生成短链前校验长链合法性,防止恶意链接接入
权限控制:对管理后台添加认证,避免未授权用户生成短链
6.总结
| 哈希算法方案 | ID 自增方案 | |
| 短链长度 | 固定长度(取决于哈希值进制) | 随 ID 增长可能变长 |
| 冲突处理 | 依赖哈希算法与数据库 / 布隆过滤器 | 天然无冲突(ID 唯一) |
| 并发性能 | 高(无锁计算) | 需解决 ID 生成器的并发瓶颈 |
| 重复长链 | 可通过索引实现唯一映射 | 需额外查询逻辑 |
短链设计本质是在 空间压缩、性能、数据唯一性 之间寻找平衡点。实际应用中,可结合业务规模选择方案:小型系统优先 ID 自增,海量数据场景则推荐哈希算法 + 布隆过滤器 + 分布式缓存的组合架构。通过合理的技术选型与优化,短链服务可支撑亿级点击量,成为现代互联网业务的基础设施之一。