引言
作者在前面写了很多并发编程知识深度探索系列文章,反馈得知友友们收获颇丰,同时我也了解到友友们也有了对知识如何应用感到很模糊的问题。所以作者就打算写一个实战系列文章,让友友们切身感受一下怎么应用知识。话不多说,开始吧!
在当今数据驱动的时代,数据库作为应用程序的核心组成部分,其连接的高效管理直接影响着系统的性能与稳定性。尤其是在高并发场景下,频繁创建和销毁数据库连接会带来巨大的资源开销,严重制约系统的响应速度和吞吐量。数据库连接池技术应运而生,通过预先创建并管理一定数量的连接,实现连接的复用,极大提升了资源利用效率。本文将通过一个基于 Java 的示例,深入剖析如何运用 CountDownLatch、等待超时模式与动态代理等技术,构建线程安全的数据库连接池,为高并发环境下的资源管理提供清晰的实践路径与解决方案。
实战前置知识
1.CountDownLatch
CountDownLatch 是 JUC 中的一个同步工具类,用于协调多个线程之间的同步,确保主线程在多个子线程完成任务后继续执行。下面这篇博客文章也有讲过《并发工具类》CountDownLatch 并发编程:各种锁机制、锁区别、并发工具类深刻总结-CSDN博客
CountDownLatch 它的核心思想是通过一个倒计时计数器来控制多个线程的执行顺序。
class CountDownLatchExample { public static void main(String[] args) throws InterruptedException { int threadCount = 3; CountDownLatch latch = new CountDownLatch(threadCount); for (int i = 0; i < threadCount; i++) { new Thread(() -> { try { Thread.sleep((long) (Math.random() * 1000)); // 模拟任务执行 System.out.println(Thread.currentThread().getName() + " 执行完毕"); } catch (InterruptedException e) { e.printStackTrace(); } finally { latch.countDown(); // 线程完成后,计数器 -1 } }).start(); } latch.await(); // 主线程等待 System.out.println("所有子线程执行完毕,主线程继续执行"); } }在使用的时候,我们需要先初始化一个 CountDownLatch 对象,指定一个计数器的初始值,表示需要等待的线程数量。然后在每个子线程执行完任务后,调用
countDown()方法,计数器减 1。接着主线程调用await()方法进入阻塞状态,直到计数器为 0,也就是所有子线程都执行完任务后,主线程才会继续执行。例如《秦二爷:王者荣耀等待玩家确认》例子。
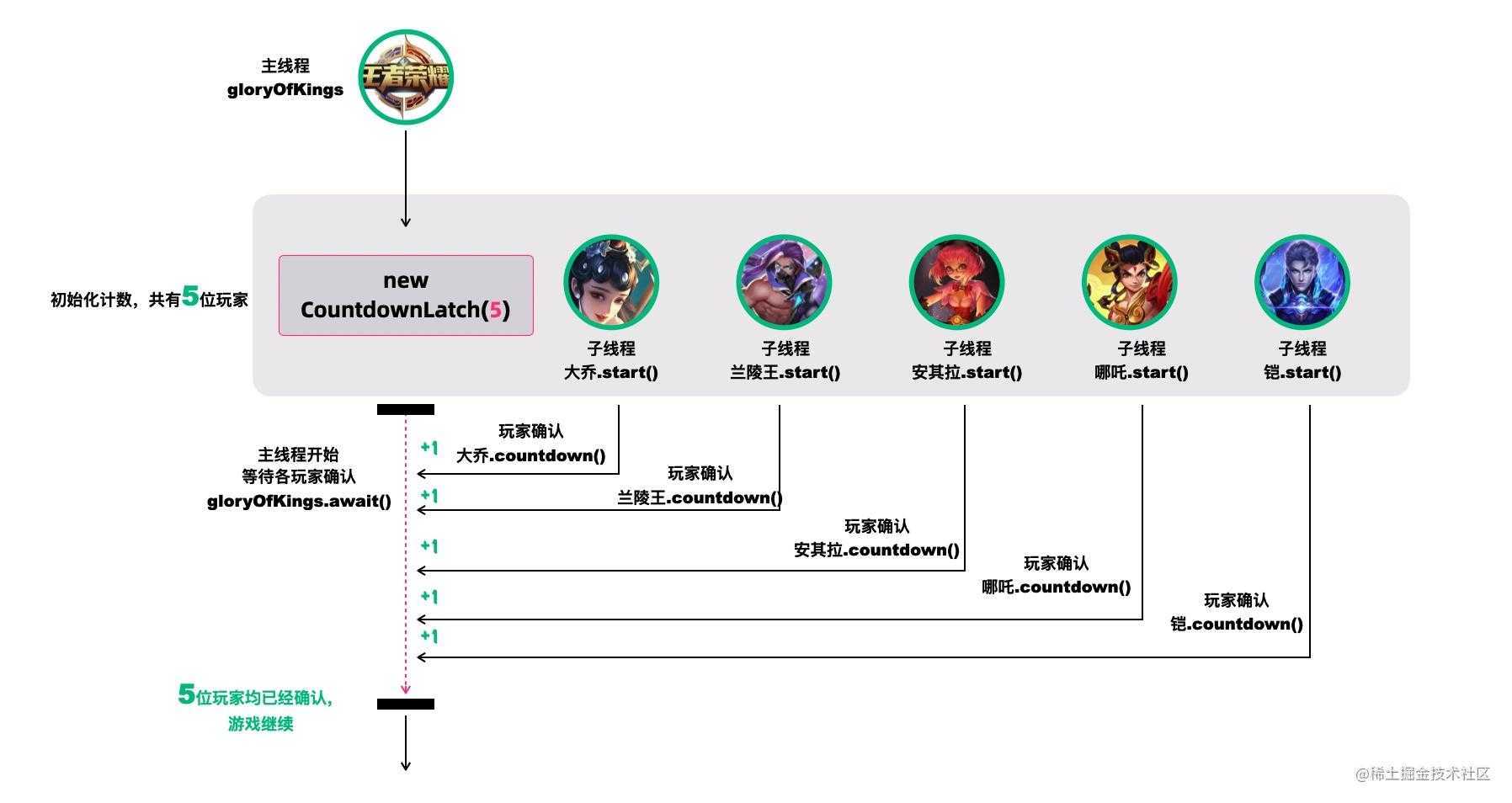
以王者荣耀为例,我们来创建五个线程,分别代表大乔、兰陵王、安其拉、哪吒和铠。每个玩家都调用
countDown()方法,表示已就位。主线程调用await()方法,等待所有玩家就位。
2.等待超时模式
2.1等待/通知模式的经典范式
等待/通知的经典范式,该范式分为两部分,分别针对等待方(消费者)和通知方(生产者)。
等待方遵循如下原则。
- 获取对象的锁。
- 如果条件不满足,那么调用对象的 wait()方法,被通知后仍要检查条件
- 条件满足则执行对应的逻辑。
对应的伪代码如下。
synchronized (对象) { while (条件步满足) { 对象.wait(); } 对应的处理逻辑 }通知方遵循如下原则。
- 获得对象的锁。
- 改变条件。
- 通知所有等待在对象上的线程。
对应的伪代码如下
synchronized(对象) { 改变条件 对象.notifyAll(); }
2.2等待超时模式
开发人员经常会遇到这样的方法调用场景:调用一个方法时等待一段时间(一般来说是给定一个时间段),如果该方法能够在给定的时间段得到结果,那么立刻将结果返回,反之超时返回默认结果。
前面介绍了等待/通知的经典范式,即加锁、条件循环和处理逻辑3个步骤,但这种范式无法做到超时等待。要想支持超时等待,只需要对经典范式做非常小的改动,改动内容如下所示。
假设超时时间段是T,那么可以推断出在当前时间now+T之后就会超时。定义如下变量口。
- 等待持续时间:REMAINING=T。
- 超时时间:FUTURE=now+T。
这时仅需要执行 wait(REMAINING),在 wait(REMAINING)返回后将执行REMAINING=FUTURE-NOW。如果REMAINING小于或等于0,表示已经超时,直接退出,否则将继续执行 wait(REMAINING)。
上述描述等待超时模式的伪代码如下。//对当前对象加锁 public synchronized Object get(long mills) throws InterruptedException { long future = System.currentTimeMillis() + mills; long remaining = mills; //超时大于0并且result返回值不满足要求 while ((result == null) && remaining > 0) { wait(remaining); remaining = future - System.currentTimeMillis(); } return result; }可以看出,等待超时模式就是在等待/通知的经典范式的基础上增加了超时控制,这使得该模式相比原有范式更具灵活性,因为即使方法的执行时间过长,也不会“永久”阻塞调用者,而是会按照调用者的要求“按时”返回。
实战开始—>数据库连接池示例
我们使用等待超时模式来构造一个简单的数据库连接池,模拟从连接池中获取、使用和释放连接的过程,而客户端获取连接的过程被设定为等待超时的模式,也就是在1000ms内如果无法获取到可用连接,将会返回给客户端一个null。设定连接池的大小为10个,然后通过调节客户端的线程数来模拟无法获取连接的场景。
首先看一下连接池的定义。它通过构造函数初始化连接的最大上限,通过一个双向队列来维护连接,调用着需要先调用fetchConnection(long)方法来指定在多少ms内超时获取连接、当连接使用完成后,需要调用releaseConnection(Conneetion)方法将连接放回线程池。
示例代码如下
public class ConnectionPool {
private LinkedList<Connection> pool = new LinkedList<Connection>();
public ConnectionPool(int initialSize) {
if (initialSize <= 0) throw new IllegalArgumentException();
for (int i = 0; i < initialSize; i++) {
pool.addLast(ConnectionDriver.createConnection());
}
}
public void releaseConnection(Connection connection) {
if (connection != null) {
synchronized (pool) {
pool.addLast(connection);
pool.notifyAll();
}
}
}
public Connection fetchConnection(long mills) throws InterruptedException {
synchronized (pool) {
if (mills <= 0) {
while (pool.isEmpty()) {
pool.wait();
}
return pool.removeFirst();
} else {
long future = System.currentTimeMillis() + mills;
long remaining = mills;
while (pool.isEmpty() && remaining > 0) {
pool.wait(remaining);
remaining = future - System.currentTimeMillis();
}
Connection result = null;
if (!pool.isEmpty()) {
result = pool.removeFirst();
}
return result;
}
}
}
}
由于java.sql.Connection是一个接口,最终的实现是由数据库驱动提供方来实现的,考虑到这只是个示例,我们通过动态代理构造了一个Connection,该Connection的代理实现仅仅是在commitO)方法调用时休眠100ms,示例如下。
public class ConnectionDriver {
static class ConnectionHandler implements InvocationHandler {
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals("commit")) {
TimeUnit.MILLISECONDS.sleep(100);
}
return null;
}
}
public static final Connection createConnection() {
return (Connection) Proxy.newProxyInstance(
ConnectionDriver.class.getClassLoader(),
new Class<?>[] { Connection.class },
new ConnectionHandler()
);
}
}
下面通过一个示例来测试简易数据库连接池的工作情况。模拟客户端ConnectionRunner获取、使用、释放连接的过程,当它使用时将会增加获取到的连接的数量,反之,将会增加未获取到的连接的数量,示例如下。
public class ConnectionPoolTest {
static ConnectionPool pool = new ConnectionPool(10);
static CountDownLatch start = new CountDownLatch(1);
static CountDownLatch end;
public static void main(String[] args) throws Exception {
int threadCount = 10;
end = new CountDownLatch(threadCount);
int count = 20;
AtomicInteger got = new AtomicInteger();
AtomicInteger notGot = new AtomicInteger();
for (int i = 0; i < threadCount; i++) {
Thread thread = new Thread(new ConnectionRunner(count, got, notGot), "ConnectionRunnerThread");
thread.start();
}
start.countDown();
end.await();
System.out.println("total invoke: " + (threadCount * count));
System.out.println("got connection: " + got);
System.out.println("not got connection " + notGot);
}
static class ConnectionRunner implements Runnable {
int count;
AtomicInteger got;
AtomicInteger notGot;
public ConnectionRunner(int count, AtomicInteger got, AtomicInteger notGot) {
this.count = count;
this.got = got;
this.notGot = notGot;
}
public void run() {
try {
start.await();
} catch (Exception ex) {
}
while (count > 0) {
try {
Connection connection = pool.fetchConnection(1000);
if (connection != null) {
try {
connection.createStatement();
connection.commit();
} finally {
pool.releaseConnection(connection);
got.incrementAndGet();
}
} else {
notGot.incrementAndGet();
}
} catch (Exception ex) {
} finally {
count--;
}
}
end.countDown();
}
}
}
上述示例中使用了CountDownLatch来确保ConnectionRunnerThread能够同时开始执并且在全部结束之后,才使main线程从等待状态中返回。当前设定的场景是10个线同时运行来获取连接池(10个连接)中的连接,通过调节线程数量来观察未获取到的连的情况。线程数量、总获取次数、获取到的数量、未获取到的数量以及未获取到的比率如表所示。不同电脑机器实际输出可能与此表不同。
| 线程数量 | 总获取次数 | 获取到的数量 | 未获取到的数量 | 未获取到的比率 |
| 10 | 200 | 200 | 0 | 0% |
| 20 | 400 | 387 | 13 | 3.25% |
| 30 | 600 | 542 | 58 | 9.67% |
| 40 | 800 | 700 | 100 | 12.5% |
| 50 | 1000 | 828 | 172 | 17.2% |
从表中的数据统计可以看出,在资源一定的情况下(连接池中的10个连接),随着客户端线程的逐步增加,客户端出现超时无法获取连接的比率不断升高。虽然客户端线程在这种超时获取的模式下会出现连接无法获取的情况,但是它能够保证客户端线程不会一直挂在连接获取的操作上,而是“按时”返回,并告知客户端连接获取出现问题,这是系统的一种自我保护机制。数据库连接池的设计也可以复用到其他的资源获取场景,针对昂贵资源(比如数据库连接)的获取都应该进行超时限制。






![[项目总结] 基于Docker与Nginx对项目进行部署](https://i-blog.csdnimg.cn/direct/6b5052373d614e808bf978ad806d818c.png)