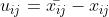在前两个版本中,我们实现了基础的客户端-服务端通信、连接池、序列化等关键模块。为了进一步提升吞吐量和并发性能,本版本新增了 异步发送机制 和 多路复用支持,旨在减少资源消耗、提升连接利用率。
代码地址:https://github.com/karatttt/MyRPC
版本三新增特性
异步发送机制实现
背景:
在同步RPC调用中,客户端每发送一次请求都需阻塞等待响应,这在网络抖动或响应较慢时会严重降低系统吞吐量。因此,本版本引入了 异步任务模型,支持超时重试、指数退避、完成回调等能力,确保在客户端请求失败后可以自动重试、不中断主逻辑。
实现思路:
- 实际上异步回调的功能很好实现,只需要将回调方法传入内部,当内部状态为成功或者完成的时候调用该callback方法即可。
- 而异步超时失败重试的机制实际上是让客户端的发送请求交由另一个协程来做,客户端可以先执行其他的逻辑再阻塞等待future的结果,或者设置一个回调方法,或者不关心回复。异步发送实际上就是牺牲了可靠性,而重试是为了尽量提高这个可靠性。超时重试这个可以通过在协程内通过计时器重试,如果超时则在同一个协程中再进行一次发送,直到重试到大于最大重试次数。但是这样会导致等待重试的协程数量太多,对于某一时间段网络出现抖动的情况,出现了大量的重试,就会导致协程数剧增的情况。
- 借鉴了RocketMQ的异步发送的机制,采用了一个协程统一管理需要重试的任务,并用一个延时队列来排序处理任务
Client的变动
为了区分同步发送,为异步增加了异步的proxy和异步的send方法
// 创建客户端代理
func NewHelloAsyncClientProxy(opts ...client.Option) HelloAsyncClientProxy {
return &HelloAsyncClientProxyImpl{
client: client.DefaultClient,
opts: opts,
}
}
// 实现HelloAsync方法
func (c *HelloAsyncClientProxyImpl) HelloAsync(ctx context.Context, req *HelloRequest, opts ...client.Option) (*internel.Future, *common.RPCError) {
msg := internel.NewMsg()
msg.WithServiceName("helloworld")
msg.WithMethodName("Hello")
ctx = context.WithValue(ctx, internel.ContextMsgKey, msg)
rsp := &HelloReply{}
// 这里需要将opts添加前面newProxy时传入的opts
newOpts := append(c.opts, opts...)
return c.client.InvokeAsync(ctx, req, rsp, newOpts...)
}
- 这里是rpc.go中新增的代理以及实现方法,还没有体现异步发送的逻辑,接下来看InvokeAsync
InvokeAsync
func (c *client) InvokeAsync(ctx context.Context, reqBody interface{}, rspBody interface{}, opt ...Option) (*internel.Future, *common.RPCError) {
future := internel.NewFuture()
opts := DefaultOptions
for _, o := range opt {
o(opts)
}
go func() {
var task *async.Task
if opts.Timeout > 0 {
// 有超时时间的情况下,无论是否进行重试,将任务提交给全局管理器
ctx, msg := internel.GetMessage(ctx)
task = &async.Task{
MethodName: msg.GetMethodName(),
Request: reqBody,
MaxRetries: opts.RetryTimes,
Timeout: opts.Timeout,
ExecuteFunc: c.makeRetryFunc(ctx, reqBody, rspBody, opts),
OnComplete: func(err error) {
// 最终结果回调到原始Future
if err != nil {
future.SetResult(nil, &common.RPCError{
Code: common.ErrCodeRetryFailed,
Message: err.Error(),
})
} else {
future.SetResult(rspBody, nil)
}
},
}
// 提交任务到全局管理器
task.Status = async.TaskStatusPending
future.Task = task
async.GetGlobalTaskManager().AddTask(task)
// 执行发送逻辑
err := opts.ClientTransport.Send(ctx, reqBody, rspBody, opts.ClientTransportOption)
if err == nil {
future.SetResult(rspBody, nil)
}
} else {
// 无超时时间的情况下,错误的话直接返回
err := opts.ClientTransport.Send(ctx, reqBody, rspBody, opts.ClientTransportOption)
if err == nil {
future.SetResult(rspBody, nil)
} else {
future.SetResult(nil, &common.RPCError{
Code: common.ErrCodeClient,
Message: err.Error(),
})
}
}
}()
return future, nil
}
- 我们先看看Future结构,再去理解上面的代码:
type Future struct {
mu sync.Mutex
done chan struct{}
result interface{}
err *common.RPCError
callbacks []func(interface{}, *common.RPCError)
Task *async.Task // 关联的异步任务
}
// SetResult 设置Future的结果
func (f *Future) SetResult(result interface{}, err *common.RPCError) {
f.mu.Lock()
defer f.mu.Unlock()
if f.isDone() {
return
}
f.result = result
f.Task.Status = async.TaskStatusCompleted
f.err = err
close(f.done)
// 执行所有注册的回调
for _, callback := range f.callbacks {
callback(result, err)
}
}
- 这个就是异步发送后返回的Future,result就是回包结果,callbacks就是客户端设置的回调方法,Task是后续添加到全局异步管理器的任务,后续再说
- 而这个SetResult就是在得到结果后设置future的result,并且调用所有注册的回调方法,并置Task.Status = async.TaskStatusCompleted,这个关于task的我们后面再说
- 接下来回到invokeAsync,对于没有设置超时时间的发送,我们直接在失败后返回客户端(客户端能够忍受异步的丢失,如果真的发生了长时间的阻塞,也不用担心这个协程不释放,因为我们的连接池会管理这个连接的生命周期),对于设置了超时时间的发送,我们需要在超时时间到达后进行重试,或者达到最大重试次数后进行失败反馈
- 这里就做了一个全局的管理器,先创建一个Task将其添加到manager中,再进行消息的正常发送。
TaskManager
// Task 表示一个异步任务
type Task struct {
MethodName string // 方法名
Request interface{} // 请求参数
RetryTimes int // 当前已重试次数
MaxRetries int // 最大重试次数
Timeout time.Duration // 单次任务超时时间
NextRetryAt time.Time // 下次重试时间(用于堆排序)
ExecuteFunc func() error // 重试时任务执行函数
Status TaskStatus // 状态字段
OnComplete func(error) // 最终完成回调
mu sync.Mutex // 保证状态变更的线程安全
}
// 扫描循环(核心逻辑)
func (tm *TaskManager) scanLoop() {
for {
select {
case <-tm.closeChan:
return
default:
tm.processTasks()
}
}
}
// 处理超时任务
func (tm *TaskManager) processTasks() {
tm.mu.Lock()
if tm.tasks.Len() == 0 {
tm.mu.Unlock()
// 无任务时休眠,直到被唤醒
select {
case <-tm.wakeChan:
case <-time.After(10 * time.Second): // 防止长期阻塞
}
return
}
// 检查堆顶任务是否超时
now := time.Now()
task := (*tm.tasks)[0]
if now.Before(task.NextRetryAt) {
// 未超时,休眠到最近任务到期
tm.mu.Unlock()
time.Sleep(task.NextRetryAt.Sub(now))
return
}
// 弹出超时任务
task = heap.Pop(tm.tasks).(*Task)
tm.mu.Unlock()
// 执行重试逻辑
go tm.retryTask(task)
}
// 重试任务
func (tm *TaskManager) retryTask(task *Task) {
task.mu.Lock()
// 检查状态:如果任务已结束,直接返回,不用再次入队列
if task.Status != TaskStatusPending {
task.mu.Unlock()
return
}
task.Status = TaskStatusRunning // 标记为执行中
task.mu.Unlock()
err := task.ExecuteFunc()
if err == nil {
task.OnComplete(nil)
return
}
// 检查是否达到最大重试次数
task.RetryTimes++
if task.RetryTimes > task.MaxRetries {
// 打印
fmt.Println("request retry times exceed max retry times")
task.OnComplete(err)
return
}
// 计算下次重试时间(如指数退避)
delay := time.Duration(math.Pow(2, float64(task.RetryTimes))) * time.Second
task.NextRetryAt = time.Now().Add(delay)
// 重新加入队列
// 打印重试次数
fmt.Println("request retry time : ", task.RetryTimes)
tm.mu.Lock()
heap.Push(tm.tasks, task)
task.Status = TaskStatusPending // 恢复状态
tm.mu.Unlock()
tm.notifyScanner()
}
- 以上是这个manager的关键代码,这个Task就是里面的元素,按照下一次重试时间排序放在manager的一个延时队列里面,优先处理目前需要重试的任务。task的ExecuteFunc我们在前面的方法中可以看到实际上就是retry发送,OnComplete就是将future的setResult使得客户端能得到反馈
- 循环执行processTasks,对于堆顶任务进行retry
- retry时先看这个task是不是已经执行成功了,是的话删除这个task,如果不是的话继续入队
- 这样就可以保证只有一个协程在管理所有的超时任务,避免了每一个超时任务都需要一个协程来等待重试。
多路复用
背景:
- 默认情况下,每个RPC调用使用一个连接,连接池虽然能缓解资源浪费,对于连接池中的每一个连接,实际上也是串行进行的,也就是说,如果前面的某一个连接处理时间太长,后续的请求只能等待该请求返回后才能复用该连接,也就是http1.1的队头阻塞问题。
- 为此,引入 多路复用协议 —— 即在一个TCP连接内支持多个“逻辑流”,每个流由 RequestID 唯一标识,从而支持多个请求同时复用一条连接。
实现思路:
我们之前的frame结构如下:
header := FrameHeader{
MagicNumber: MagicNumber,
Version: Version,
MessageType: MessageTypeRequest,
SequenceID: sequenceID,
ProtocolLength: uint32(len(protocolDataBytes)),
BodyLength: uint32(len(reqData)),
}
实际上已经有了SequenceID这个字段,也就是说,我们可以通过这个SequenceID,来区分同一个连接中的不同的流,也就是说,客户端在同一个连接中,发送了不同的SequenceID的消息,服务端并发处理这些消息,并且保留这个SequenceID返回客户端,客户端的多个流识别这个SequenceID并读取结果
MuxConn(多路复用连接)结构
// 实现net.Conn接口的结构体,保证适配连接池的get和put
// 实际上也是一个连接,只是多了reqID从而可以派生出多个流,区分达到多路复用的目的
type MuxConn struct {
conn net.Conn // 原始连接
pending map[uint32]*pendingRequest // 每一个reqID(流)对应的等待通道
closeChan chan struct{}
readerDone chan struct{}
writeLock sync.Mutex
reqIDCounter uint64 // 分配递增的请求ID
mu sync.RWMutex
}
type pendingRequest struct {
ch chan MuxFrame
timeout time.Time
}
func (mc *MuxConn) NextRequestID() uint64 {
return atomic.AddUint64(&mc.reqIDCounter, 1)
}
- 实际上这个MuxConn实现了net.Conn,也是一个连接,只是可以通过NextRequestID派生出多个流,并在这个conn上write特定reqID的请求
- 可以看到pending这个结构,是一个map,k是reqID,v是一个ch,为什么要设计一个这样的map?因为我们可能同时存在多路并发,不同的客户端的对于同一个conn的请求,我们需要设计一个特有的ch来读取对应的reqID的响应是否到达,如果某一个reqID的响应到达了,发送到对应的ch,从而对应的客户端得到响应。如果多个流直接并发读取tcp的响应,必然会导致reqID乱序现象
connPool的改动
之前的连接池只是正常获取一个连接,当该连接处理完被归还后才置为空闲状态。而对于多路复用显然不是这个规则,对于正在使用的连接,若没有达到最大可以接受的流的量,我们仍然可以接受从池中返回这个连接并使用
对于之前的获取连接的逻辑,我们一次对于多路复用加入以下分支:
// 1. 优先检查空闲连接
if len(p.idleConns) > 0 {
// 原逻辑。。。
// 多路复用处理
if p.isMux {
if muxConn, exists := p.muxConns[conn]; exists {
if p.streamCount[conn] < p.maxStreams {
p.streamCount[conn]++
MuxConn2SequenceIDMap[muxConn] = muxConn.NextRequestID()
return muxConn, nil
}
}
// 如果不是多路复用连接或已达最大流数,回退到普通连接
}
p.mu.Unlock()
return &pooledConnWrapper{conn, p}, nil
}
// 2. 检查是否可以创建新连接
if int(atomic.LoadInt32(&p.activeCount)) < p.maxActive {
// 原逻辑。。。
// 多路复用连接初始化
if p.isMux {
if p.muxConns == nil {
p.muxConns = make(map[*PooledConn]*mutilpath.MuxConn)
p.streamCount = make(map[*PooledConn]int)
}
muxConn := mutilpath.NewMuxConn(rawConn, 1000)
p.muxConns[pooledConn] = muxConn
p.streamCount[pooledConn] = 1 // 新连接默认1个流
MuxConn2SequenceIDMap[muxConn] = muxConn.NextRequestID()
return muxConn, nil
}
p.mu.Unlock()
return &pooledConnWrapper{pooledConn, p}, nil
}
// 3. 新增情况:无空闲且活跃连接达到最大数,检查活跃连接的多路复用能力(仅在多路复用模式下)
if p.isMux {
for pc, muxConn := range p.muxConns {
count := p.streamCount[pc]
if count < p.maxStreams {
p.streamCount[pc]++
atomic.AddInt32(&p.activeCount, 1)
pc.lastUsed = time.Now()
MuxConn2SequenceIDMap[muxConn] = muxConn.NextRequestID()
return p.muxConns[pc], nil
}
}
}
- 对于情况一,若是空闲连接当然直接使用,并增加流数量,并对该连接分配reqID,在MuxConn2SequenceIDMap结构中保存
- 对于情况二,无空闲连接,但是活跃连接数未满,创建新连接,增加流数量,并对该连接分配reqID,在MuxConn2SequenceIDMap结构中保存
- 对于情况三,无空闲连接且活跃连接数已经满,检查所有的活跃连接的流数量是否未满,并且返回未满的连接,分配新的流
- 对于Put逻辑,对应的应是归还流,当某个连接的流为0时,该连接为空闲状态,不再阐述
Send方法改动
之前的方法只需要send中正常序列化和编解码就可以,客户端发送完请求就阻塞(或者异步)等待响应,这里的多路复用模式则是在write前注册一个pendingRequest,监听特定的channel
// mux模式下,通过ch阻塞等待相应的流回包
muxConn, _ := conn.(*mutilpath.MuxConn)
seqID := msg.GetSequenceID()
ch := muxConn.RegisterPending(seqID)
defer muxConn.UnregisterPending(seqID)
// 写数据
err = c.tcpWriteFrame(ctx, conn, framedata)
if err != nil {
return &common.RPCError{
Code: common.ErrCodeNetwork,
Message: fmt.Sprintf("failed to write frame: %v", err),
}
}
// 读响应
select {
case frame := <-ch:
rspDataBuf = frame.Data
case <-ctx.Done():
return &common.RPCError{
Code: common.ErrCodeNetwork,
Message: fmt.Sprintf("failed to read frame: %v", err),
}
}
- 而客户端收到响应,路由到对应reqID的channel的逻辑在这里:
func (mc *MuxConn) readLoop() {
defer close(mc.readerDone)
for {
select {
case <-mc.closeChan:
return
default:
}
frame, err := codec.ReadFrame(mc.conn)
if err != nil {
// 协议错误处理
fmt.Println("读取帧错误:", err)
break
}
mc.dispatchFrame(frame)
}
}
func (mc *MuxConn) dispatchFrame(frame []byte) {
mc.mu.RLock()
// 截取流序号
sequenceID := binary.BigEndian.Uint32(frame[4:8])
pr, exists := mc.pending[uint32(sequenceID)]
mc.mu.RUnlock()
frameStruct := MuxFrame{
Data: frame,
}
if exists {
select {
case pr.ch <- frameStruct:
// 成功发送到等待通道
default:
// 通道已满,丢弃帧
fmt.Println("丢弃帧 %s:通道已满", frame)
}
} else {
// 直接丢弃或打印日志
fmt.Printf("收到未匹配的帧,sequenceID=%d,丢弃\n", sequenceID)
}
}
总结
在已有基础通信、连接池与序列化机制之上,通过引入异步发送机制与多路复用技术进一步提升RPC系统的吞吐量与并发性能,使得系统更加健壮。多路复用实际上也是http2.0实现的能力,这里相当于完成了http2.0的任务。以后的版本可以考虑对于性能再进行优化,如网络框架的改进以及更高效的数据结构的使用



![[Windows] 游戏常用运行库- Game Runtime Libraries Package(6.2.25.0409)](https://i-blog.csdnimg.cn/img_convert/55ca519964b01db8e0d3b2a1e7961c42.webp?x-oss-process=image/format,png)