CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
- CUDA的设备,流处理器,核,线程块(threadblock),线程,网格(gridDim),块(block)和多gpu设备同步数据概念
- 前言
- 一、介绍CUDA编程的并行原理,了解线程、线程块、网格等概念,了解CUDA的同步机制
- blockSize(线程块尺寸)
- gridSize(网格尺寸)
- 二、CUDA流的应用:CUDASTREAM,CUDA流的使用、同步,用CUDA流完成矩阵运算
- 1 流Streams在GPU上按顺序的操作
- 2 多GPU 编码
- 总结
前言
SIMT和SIMD
CUDA执行的是SIMT架构(单指令多线程架构),SIMT和SIMD(Single Instruction, Multiple Data)类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行官单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。
一、介绍CUDA编程的并行原理,了解线程、线程块、网格等概念,了解CUDA的同步机制
基于硬件的支持,通过cuda来实现对底层GPU的调用,关于这部分内容,首先需要熟悉一些关键名词。
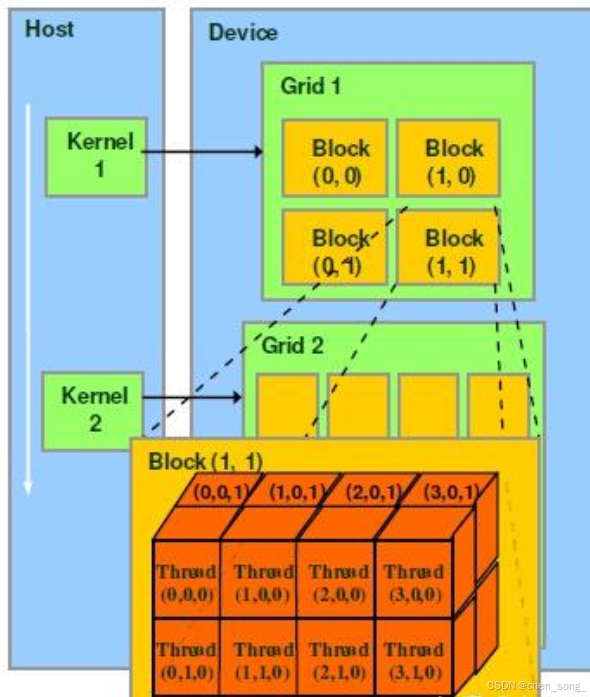
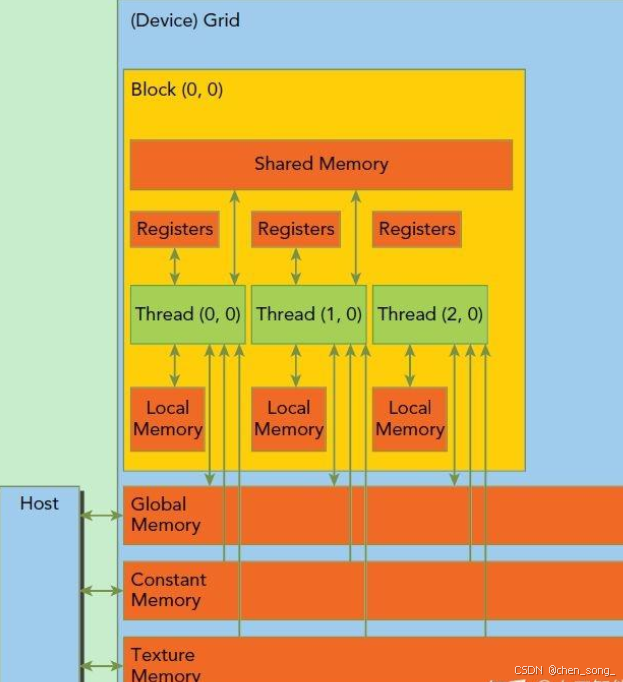
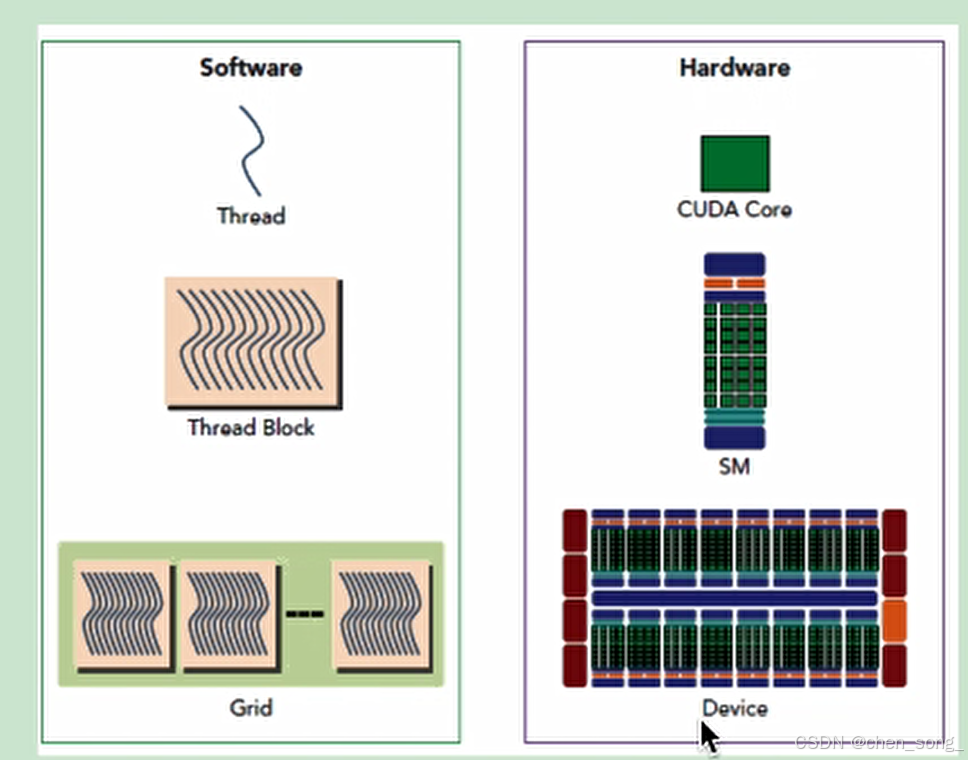
thread:一个CUDA的并行程序会被以许多个thread来执行,每个thread都有自己的register 和 local memory 的空间。
block:数个thread会组成一个block,同一个block中的thread可以同步运行,他们通过shared memory来进行通信。
grid:多个block则会再构成grid,每个grid会有自己的global memory、constant memory 和 texture memory。
warp:warp是SM的基本执行单元,一个block里面的线程,通过warp进行调用,使用SIMT模式。如A100机器,每个warp可以执行32个thread。
....
// 2D
int thread = 16;
int grid = (numRows()*numCols() + thread - 1)/ (thread * thread);
const dim3 blockSize(thread, thread);
const dim3 gridSize(grid);
rgba_to_greyscale<<<gridSize, blockSize>>>(d_rgbaImage, d_greyImage, numRows(), numCols());
.....
blockSize(线程块尺寸)
类型为dim3,表示每个线程块包含的线程数量13
在示例中dim3 blockSize(thread, thread)创建了二维线程块,每块包含thread×thread个线程5
每个线程块最大线程数限制为102457
同一线程块内的线程可通过共享内存通信
gridSize(网格尺寸)
类型为dim3,表示网格中包含的线程块数量
在示例中dim3 gridSize(grid)创建了一维网格,包含grid个线程块3
最大网格维度为65535(x/y/z方向)
执行配置<<<gridSize, blockSize>>>
该语法指定核函数启动时的并行执行结构35
总线程数 = gridSize.x * gridSize.y * gridSize.z * blockSize.x * blockSize.y * blockSize.z13
二、CUDA流的应用:CUDASTREAM,CUDA流的使用、同步,用CUDA流完成矩阵运算
1 流Streams在GPU上按顺序的操作
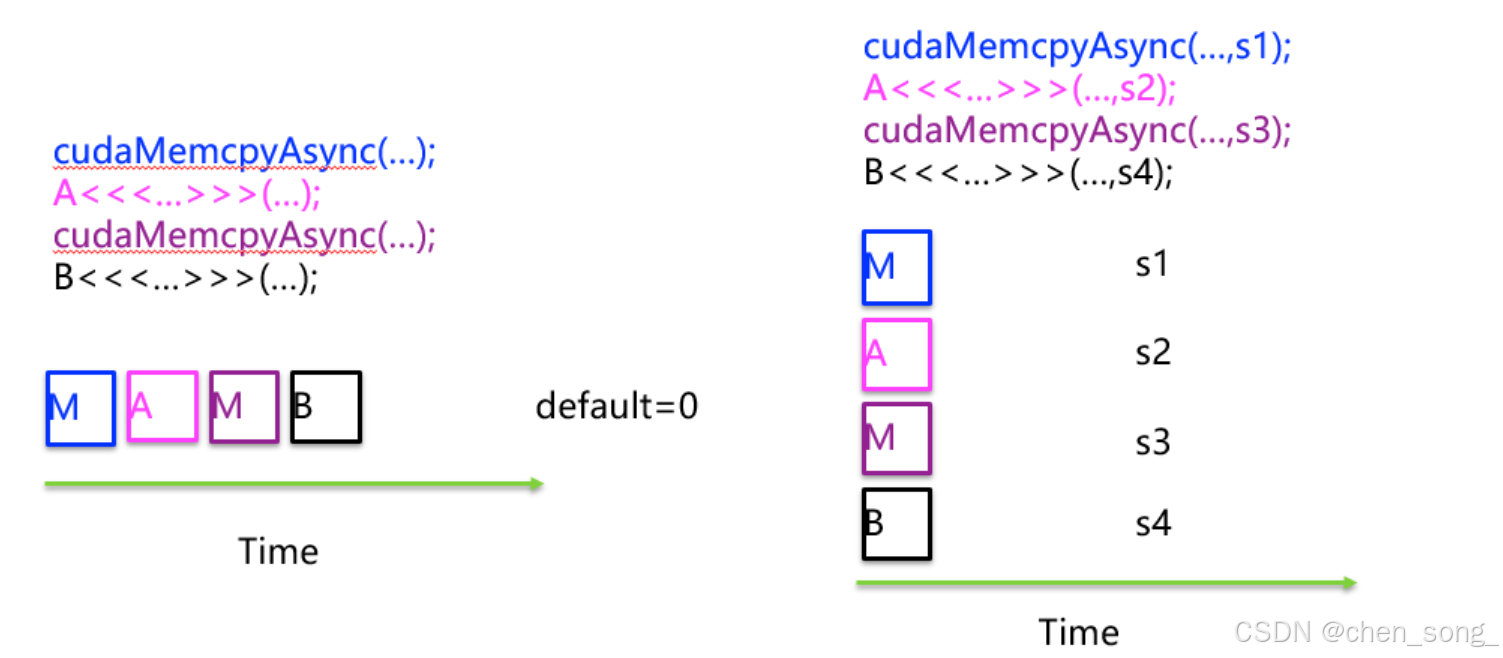
- 定义流
- 创建流
- 使用流
- 销毁流
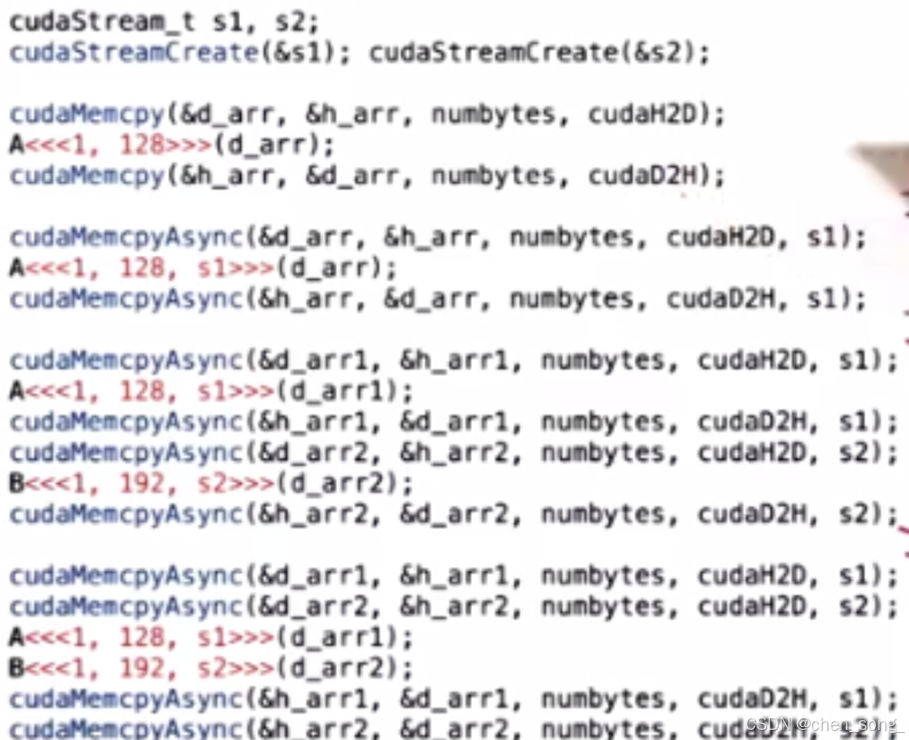
//1. 定义流
cudaStream_t s1;
//2. 创建流
cudaStreamCreate(&s1);
//3. 使用流
cudaMemcpyAsync(...., s1);
//4. 销毁流
cudaStreamDestroy(s1);
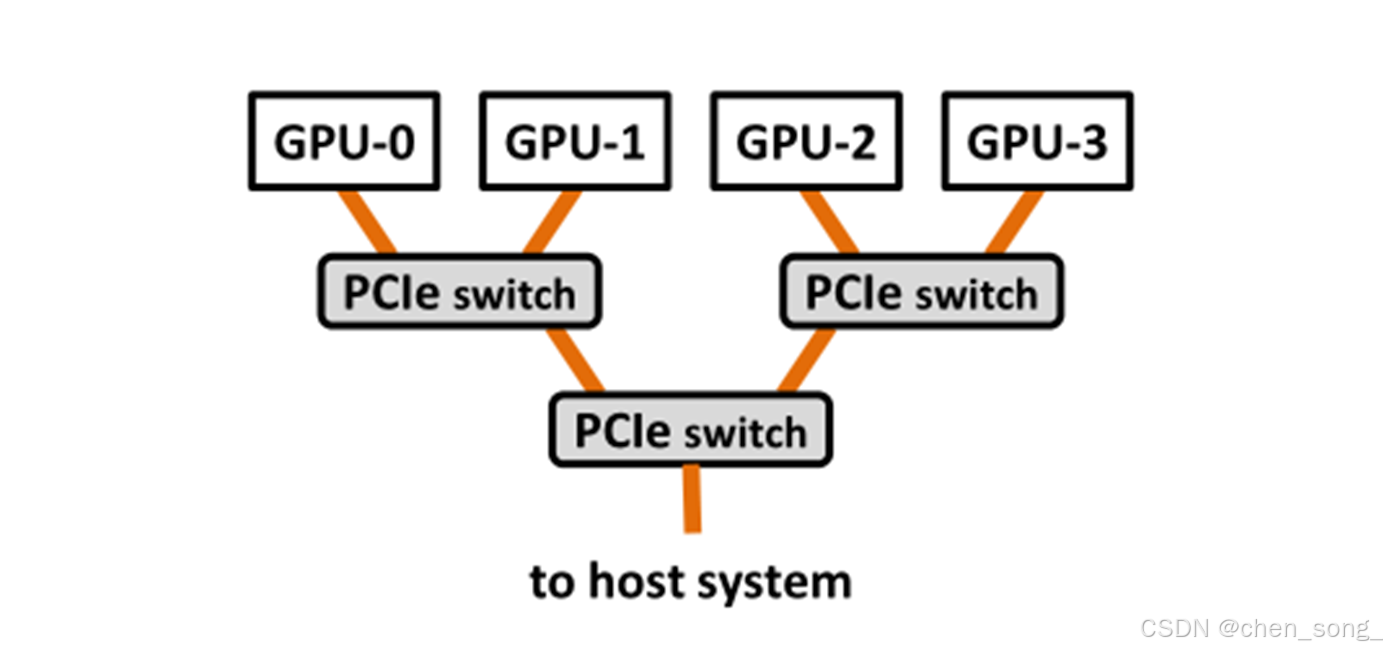
2 多GPU 编码
- 两个GPU之间数据访问是通过PCIe

int gpu1 = 0;
int gpu2 = 1;
void* d_A = NULL;
//1. 设置当前使用gpu索引id
cudaSetDevice(gpu1);
cudaMalloc(&d_A, 1024);
int accessible = 0;
cudaDeviceCanAccessPeer(&accessible, gpu1, gpu2);
if (accessible)
{
cudaSetDevice(gpu2);
//设置gpu2 可以访问gpu1的内存地址
cudaDeviceEnablePeerAccess(gpu1, 0);
// kernel<<<x, y, z>>>核心函数
}
- 两个GPU设备之间的数据拷贝函数 字节
cudaMemcpyPeerAsync(void* dst, int dstDevice, const void* src, int srcDevice, size_t count, cudaStream_t stream );
- 如果两个设备允许字节在最短的PCIe路径PCIe路径上传输
- 如果两个设备不允许CUDA驱动通过CPU驱动通过CPU memory传输
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce MX150"
CUDA Driver Version / Runtime Version 12.9 / 12.9
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 2048 MBytes (2147352576 bytes)
MapSMtoCores for SM 6.1 is undefined. Default to use 192 Cores/SM
MapSMtoCores for SM 6.1 is undefined. Default to use 192 Cores/SM
( 3) Multiprocessors x (192) CUDA Cores/MP: 576 CUDA Cores
GPU Clock rate: 1532 MHz (1.53 GHz)
Memory Clock rate: 3004 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 524288 bytes
Max Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384)
Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Bus ID / PCI location ID: 2 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.9, CUDA Runtime Version = 12.9, NumDevs = 1, Device0 = NVIDIA GeForce MX150
总结
CUDA项目源码地址:https://github.com/chensongpoixs/ccuda





![Java[IDEA]里的debug](https://i-blog.csdnimg.cn/direct/a31cb5d8792b405c9687aac82d7bf567.png)