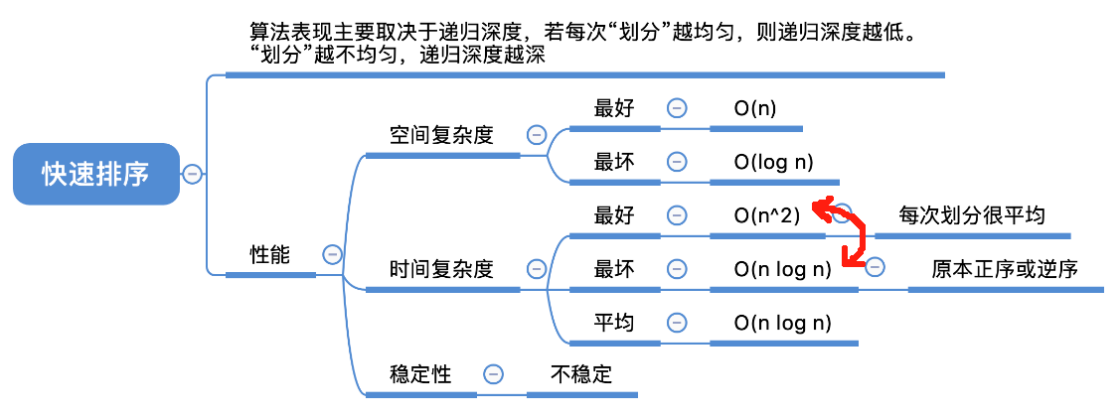
概述
若计划使用 TDengine 搭建一个时序数据平台,须提前对计算资源、存储资源和网络资源进行详细规划,以确保满足业务场景的需求。通常 TDengine 会运行多个进程,包括 taosd、taosadapter、taoskeeper、taos-explorer 和 taosx。
在这些进程中,taoskeeper、taos-explorer、taosadapter 和 taosx 的资源占用相对较少,通常不需要特别关注。此外,这些进程对存储空间的需求也较低,其占用的 CPU 和内存资源一般为 taosd 进程的十分之一到几分之一(特殊场景除外,如数据同步和历史数据迁移。在这些情况下,涛思数据的技术支持团队将提供一对一的服务)。系统管理员应定期监控这些进程的资源消耗,并及时进行相应处理。
在本节中,我们将重点讨论 TDengine 数据库引擎的核心进程 taosd 的资源规划。合理的资源规划将确保 taosd 进程的高效运行,从而提高整个时序数据平台的性能和稳定性。
服务器内存需求
每个数据库能够创建固定数量的 vgroup,默认情况下为两个。在创建数据库时,可以通过 vgroups<num> 参数指定 vgroup 的数量,而副本数则由 replica<num> 参数确定。由于每个 vgroup 中的副本会对应一个 vnode,因此数据库所占用的内存由参数 vgroups、replica、buffer、pages、pagesize 和 cachesize 确定。
为了帮助用户更好地理解和配置这些参数,TDengine 的官方文档的数据库管理部分提供了详细说明。根据这些参数,可以估算出一个数据库所需的内存大小,具体计算方式如下(具体数值须根据实际情况进行调整)。
占用内存大小 = vgroups × replica × (buffer + pages × pagesize + cachesize)
以上参数意义参考 TDengine 创建数据库
需要明确的是,这些内存资源并非仅由单一服务器承担,而是由整个集群中的所有 dnode 共同分摊,也就是说,这些资源的负担实际上是由这些 dnode 所在的服务器集群共同承担的。若集群内存在多个数据库,那么所需的内存总量还须将这些数据库的需求累加起来。更为复杂的情形在于,如果集群中的 dnode 并非一开始就全部部署完毕,而是在使用过程中随着节点负载的上升逐步添加服务器和 dnode,那么新加入的数据库可能会导致新旧 dnode 之间的负载分布不均。在这种情况下,简单地进行理论计算是不够准确的,必须考虑到各个 dnode 的实际负载状况来进行综合评估。
系统管理员可以通过如下 SQL 查看 information_schema 库中的 ins_vnodes 表来获得所有数据库所有 vnodes 在各个 dnode 上的分布。
select * from information_schema.ins_vnodes;
dnode_id |vgroup_id | db_name | status | role_time | start_time | restored |
===============================================================================================
1| 3 | log | leader | 2024-01-16 13:52:13.618 | 2024-01-16 13:52:01.628 | true |
1| 4 | log | leader | 2024-01-16 13:52:13.630 | 2024-01-16 13:52:01.702 | true |
客户端内存需求
- 原生连接方式
由于客户端应用程序采用 taosc 与服务器进行通信,因此会产生一定的内存消耗。这些内存消耗主要源于:写入操作中的 SQL、表元数据信息的缓存,以及固有的结构开销。假设该数据库服务能够支持的最大表数量为 N(每个通过超级表创建的表的元数据开销约为 256B),最大并发写入线程数为 T,以及最大 SQL 语句长度为 S(通常情况下为 1MB)。基于这些参数,我们可以对客户端的内存消耗进行估算(单位为 MB)。
M = (T × S × 3 + (N / 4096) + 100)
例如,用户最大并发写入线程数为 100,子表数为 10 000 000,那么客户端的内存最低要求如下:
100 × 3 + (10000000 / 4096) + 100 ≈ 2841 (MB)
即配置 3GB 内存是最低要求。
- RESTful/WebSocket 连接方式
当将 WebSocket 连接方式用于数据写入时,如果内存占用不大,通常可以不予关注。然而,在执行查询操作时,WebSocket 连接方式会消耗一定量的内存。接下来,我们将详细讨论查询场景下的内存使用情况。
当客户端通过 WebSocket 连接方式发起查询请求时,为了接收并处理查询结果,必须预留足够的内存空间。得益于 WebSocket 连接方式的特性,数据可以分批次接收和解码,这样就能够在确保每个连接所需内存固定的同时处理大量数据。
计算客户端内存占用的方法相对简单:只须将每个连接所需的读 / 写缓冲区容量相加即可。通常每个连接会额外占用 8MB 的内存。因此,如果有 C 个并发连接,那么总的额
外内存需求就是 8×C(单位 MB)。
例如,如果用户最大并发连接数为 10,则客户端的额外内存最低要求是 80(8×10)MB。
与 WebSocket 连接方式相比,RESTful 连接方式在内存占用上更大,除了缓冲区所需的内存以外,还需要考虑每个连接响应结果的内存开销。这种内存开销与响应结果的 JSON 数据大小密切相关,特别是在查询数据量很大时,会占用大量内存。
由于 RESTful 连接方式不支持分批获取查询数据,这就导致在查询获取超大结果集时,可能会占用特别大的内存,从而导致内存溢出,因此,在大型项目中,建议使用 WebSocket 连接方式,实现流式结果集返回,从而避免内存溢出的风险
注意
- 建议采用 RESTful/WebSocket 连接方式来访问 TDengine 集群,而不采用 taosc 原生连接方式。
- 在绝大多数情形下,RESTful/WebSocket 连接方式均满足业务写入和查询要求,并且该连接方式不依赖于 taosc,集群服务器升级与客户端连接方式完全解耦,使得服务器维护、升级更容易。
CPU 需求
TDengine 用户对 CPU 的需求主要受以下 3 个因素影响:
- 数据分片:在 TDengine 中,每个 CPU 核心可以服务 1 至 2 个 vnode。假设一个集群配置了 100 个 vgroup,并且采用三副本策略,那么建议该集群的 CPU 核心数量为 150~300 个,以实现最佳性能。
- 数据写入:TDengine 的单核每秒至少能处理 10,000 个写入请求。值得注意的是,每个写入请求可以包含多条记录,而且一次写入一条记录与同时写入 10 条记录相比,消耗的计算资源相差无几。因此,每次写入的记录数越多,写入效率越高。例如,如果一个写入请求包含 200 条以上记录,单核就能实现每秒写入 100 万条记录的速度。然而,这要求前端数据采集系统具备更高的能力,因为它需要缓存记录,然后批量写入。
- 查询需求:虽然 TDengine 提供了高效的查询功能,但由于每个应用场景的查询差异较大,且查询频次也会发生变化,因此很难给出一个具体的数字来衡量查询所需的计算资源。用户需要根据自己的实际场景编写一些查询语句,以便更准确地确定所需的计算资源。
综上所述,对于数据分片和数据写入,CPU 的需求是可以预估的。然而,查询需求所消耗的计算资源则难以预测。在实际运行过程中,建议保持 CPU 使用率不超过 50%,以确保系统的稳定性和性能。一旦 CPU 使用率超过这一阈值,就需要考虑增加新的节点或增加 CPU 核心数量,以提供更多的计算资源。
存储需求
相较于传统通用数据库,TDengine 在数据压缩方面表现出色,拥有极高的压缩率。在大多数应用场景中,TDengine 的压缩率通常不低于 5 倍。在某些特定情况下,压缩率
甚至可以达到 10 倍乃至上百倍,这主要取决于实际场景中的数据特征。
要计算压缩前的原始数据大小,可以采用以下方式:
RawDataSize = numOfTables × rowSizePerTable × rowsPerTable
示例:1000 万块智能电表,电表每 15min 采集一次数据,每次采集的数据量为 20B,那么一年的原始数据量约 7TB。TDengine 大概需要消耗 1.4TB 存储空间。
为了迎合不同用户在数据存储时长及成本方面的个性化需求,TDengine 赋予了用户极大的灵活性,用户可以通过一系列数据库参数配置选项来定制存储策略。其中,keep 参数尤其引人注目,它赋予用户自主设定数据在存储空间上的最长保存期限的能力。这一功能设计使得用户能够依据业务的重要性和数据的时效性,精准调控数据的存储生命周期,进而实现存储成本的精细化控制。
然而,单纯依赖 keep 参数来优化存储成本仍显不足。为此,TDengine 进一步创新,推出了多级存储策略。
此外,为了加速数据处理流程,TDengine 特别支持配置多块硬盘,以实现数据的并发写入与读取。这种并行处理机制能够最大化利用多核 CPU 的处理能力和硬盘 I/O 带宽,大幅提高数据传输速度,完美应对高并发、大数据量的应用场景挑战。
技巧 如何估算 TDengine 压缩率
用户可以利用性能测试工具 taosBenchmark 来评估 TDengine 的数据压缩效果。通过使用 -f 选项指定写入配置文件,taosBenchmark 可以将指定数量的 CSV 样例数据写入指定的库参数和表结构中。
在完成数据写入后,用户可以在 TDengine CLI 中执行 flush database 命令,将所有数据强制写入硬盘。接着,通过 Linux 操作系统的 du 命令获取指定 vnode 的数据文件夹大小。最后,将原始数据大小除以实际存储的数据大小,即可计算出真实的压缩率。
通过如下命令可以获得 TDengine 占用的存储空间。
taos> flush database <dbname>;
$ du -hd1 <dataDir>/vnode --exclude=wal
多级存储
除了存储容量的需求以外,用户可能还希望在特定容量下降低存储成本。为了满足这一需求,TDengine 推出了多级存储功能。该功能允许将近期产生且访问频率较高的数据存储在高成本存储设备上,而将时间较长且访问频率较低的数据存储在低成本存储设备上。通过这种方式,TDengine 实现了以下目标。
- 降低存储成本:通过将海量极冷数据存储在廉价存储设备上,可以显著降低存储成本。
- 提高写入性能:每级存储支持多个挂载点,WAL 文件也支持 0 级的多挂载点并行写入,这些措施极大地提高了写入性能(实际场景中的持续写入速度可达 3 亿测
点/秒),在机械硬盘上也能获得极高的硬盘 I/O 吞吐(实测可达 2GB/s)。
用户可以根据冷热数据的比例来决定高速和低成本存储设备之间的容量划分。
TDengine 的多级存储功能在使用上还具备以下优点。
- 方便维护:配置各级存储挂载点后,数据迁移等工作无须人工干预,存储扩容更加灵活、方便。
- 对 SQL 透明:无论查询的数据是否跨级,一个 SQL 即可返回所有数据,简洁高效
网络带宽需求
网络带宽需求可以分为两个主要部分—写入查询和集群内部通信。
写入查询是指面向业务请求的带宽需求,即客户端向服务器发送数据以进行写入操作的带宽需求。
集群内部通信的带宽需求进一步分为两部分:
- 各节点间正常通信的带宽需求,例如,leader 将数据分发给各 follower,taosAdapter 将写入请求分发给各 vgroup leader 等。
- 集群为响应维护指令而额外需要的内部通信带宽,如从单副本切换到三副本导致的数据复制、修复指定 dnode 引发的数据复制等情况。
为了估算入站带宽需求,我们可以采用以下方式:
由 于 taosc 写入在 RPC 通信过程中自带压缩功能,因此写入带宽需求相对于 RESTful/WebSocket 连接方式较低。在这里,我们将基于 RESTful/WebSocket 连接方式的
带宽需求来估算写入请求的带宽。
示例:1000 万块智能电表,电表每 15min 采集一次数据,每次采集的数据量为 20B,可计算出平均带宽需求为 0.22MB。
考虑到智能电表存在集中上报的情况,在计算带宽需求时须结合实际项目情况增加带宽需求。考虑到 RESTful 请求以明文传输,实际带宽需求还应乘以倍数,只有这样才能得到估算值。
特别提示
网络带宽和通信延迟对于分布式系统的性能与稳定性至关重要,特别是在服务器节点间的网络连接方面。
我们强烈建议为服务器节点间的网络专门分配 VLAN,以避免外部通信干扰。在带宽选择上,建议使用万兆网络,至少也要千兆网络,并确保丢包率低于万分之一。
如果采用分布式存储方案,必须将存储网络和集群内部通信网络分开规划。一个常见的做法是采用双万兆网络,即两套独立的万兆网络。这样可以确保存储数据和集群内部通信互不干扰,提高整体性能。
对于入站网络,除了要保证足够的接入带宽以外,还须确保丢包率同样低于万分之一。这将有助于减少数据传输过程中的错误和重传,从而提高系统的可靠性和效率。
服务器数量
根据前面对内存、CPU、存储和网络带宽的预估,我们可以得出整个 TDengine 集群所需的内存容量、CPU 核数、存储空间以及网络带宽。若数据副本数不是 1,还需要将总需求量乘以副本数以得到实际所需资源。
得益于 TDengine 出色的水平扩展能力,我们可以轻松计算出资源需求的总量。接下来,只须将这个总量除以单台物理机或虚拟机的资源量,便能大致确定需要购买多少台物理机或虚拟机来部署 TDengine 集群。
网络端口要求
下表列出了 TDengine 的一些接口或组件的常用端口,这些端口均可以通过配置文件中的参数进行修改。
| 接口或组件名称 | 端口 | 协议 |
|---|---|---|
| 原生接口(taosc) | 6030 | TCP |
| RESTful 接口 | 6041 | TCP |
| WebSocket 接口 | 6041 | TCP |
| taosKeeper | 6043 | TCP |
| statsd 格式写入接口 | 6044 | TCP/UDP |
| collectd 格式写入接口 | 6045 | TCP/UDP |
| openTSDB TELNET 格式写入接口 | 6046 | TCP |
| collectd 使用 openTSDB TELNET 格式写入接口 | 6047 | TCP |
| icinga2 使用 openTSDB TELNET 格式写入接口 | 6048 | TCP |
| tcollector 使用 openTSDB TELNET 格式写入接口 | 6049 | TCP |
| taosX | 6050, 6055 | TCP |
| taosExplorer | 6060 | TCP |
访问官网
更多内容欢迎访问 TDengine 官网


![Java[IDEA]里的debug](https://i-blog.csdnimg.cn/direct/a31cb5d8792b405c9687aac82d7bf567.png)