目录
前言
环境部署
安装Docker
安装Dify
配置Dify
部署知识库
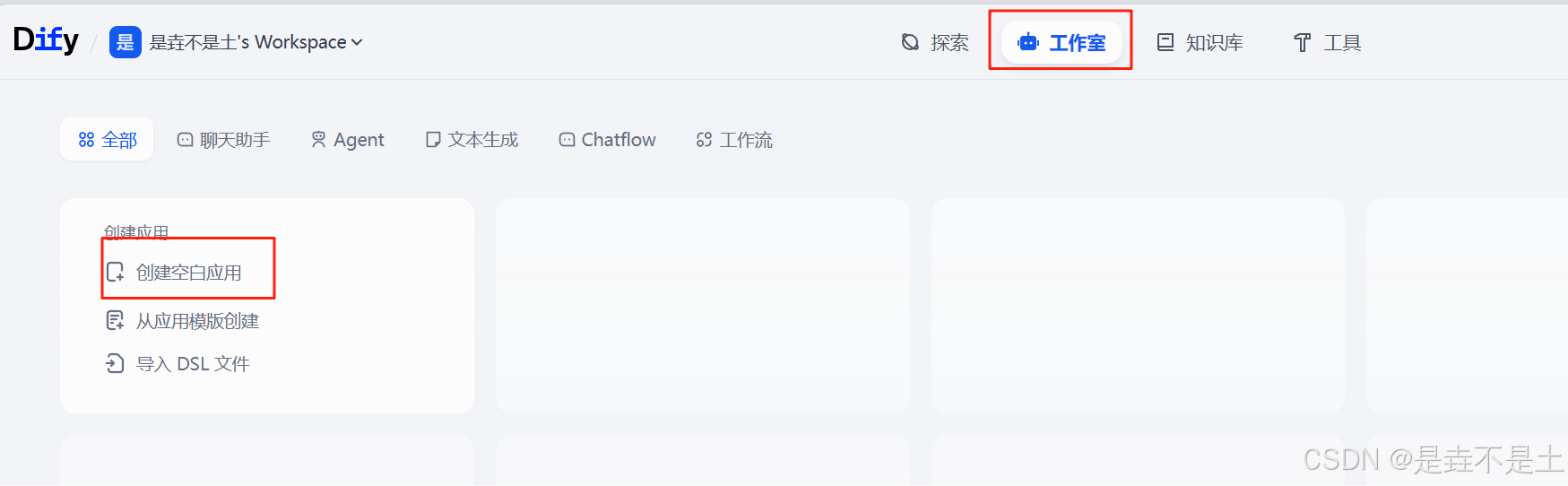
创建应用

前言
在当今数字化信息爆炸的时代,数据隐私和个性化知识管理成为企业和个人关注的焦点。Dify,作为一款备受瞩目的开源 AI 应用开发平台,为用户提供了完整的私有化部署方案,让数据安全掌控在自己手中。而 DeepSeek 作为本地部署的强大 AI 服务,拥有着卓越的性能和灵活性。将二者无缝集成,就如同为企业开启了一扇通往定制化、安全可靠 AI 应用世界的大门。通过这样的集成,企业能够在本地服务器环境内构建出功能强大的 AI 应用,不仅确保了数据隐私,还能满足个性化的业务需求。接下来,就让我们一起深入探索如何利用 DeepSeek +硅基流动+ Dify 构建属于自己的个人知识库。
环境部署
安装Docker
#wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
#yum -y install docker-ce #默认下载的是最新版的docker
#systemctl start docker && systemctl enable docker
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
#vi /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.211678.top",
"https://docker.1panel.live",
"https://hub.rat.dev",
"https://docker.m.daocloud.io",
"https://do.nark.eu.org",
"https://dockerpull.com",
"https://dockerproxy.cn",
"https://docker.awsl9527.cn"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
#systemctl daemon-reload
#systemctl restart docker安装Dify
安装Git
#yum -y install git 拉取Dify
# git clone https://gitee.com/dify_ai/dify
Cloning into 'dify'...
remote: Enumerating objects: 237231, done.
remote: Counting objects: 100% (101077/101077), done.
remote: Compressing objects: 100% (42662/42662), done.
remote: Total 237231 (delta 80807), reused 76208 (delta 56849), pack-reused 136154 (from 1)
Receiving objects: 100% (237231/237231), 89.83 MiB | 404.00 KiB/s, done.
Resolving deltas: 100% (184737/184737), done.
# cd dify/docker
# cp .env.example .env # 创建配置文件启动Dify
# docker compose up -d
#接下来就是拉取镜像和部署的过程,耐心等待,与网速有关。搭建完成后进行账户设置:
创建完成后查看首页:
配置Dify
点击设置:
点击模型提供商:
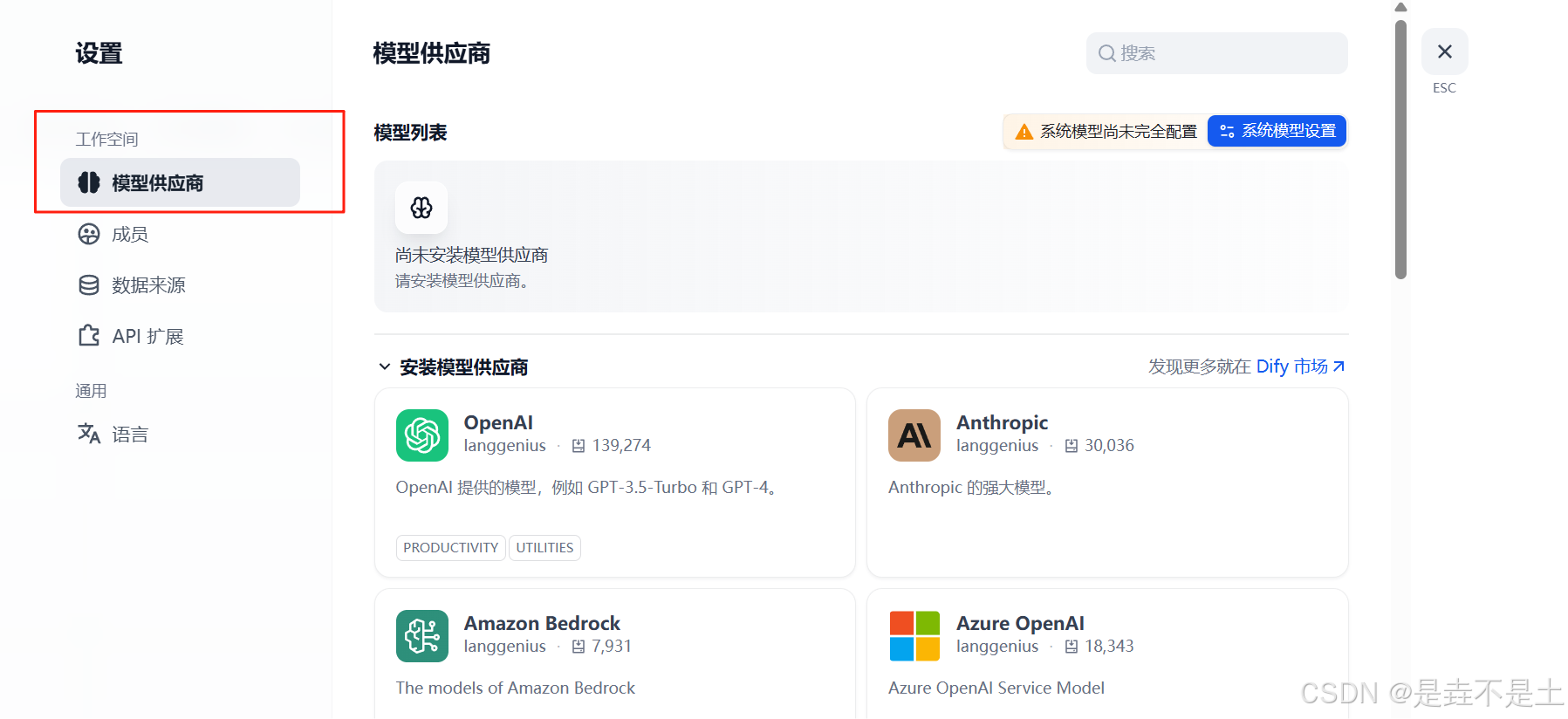
安装Deepseek插件和硅基流动插件:
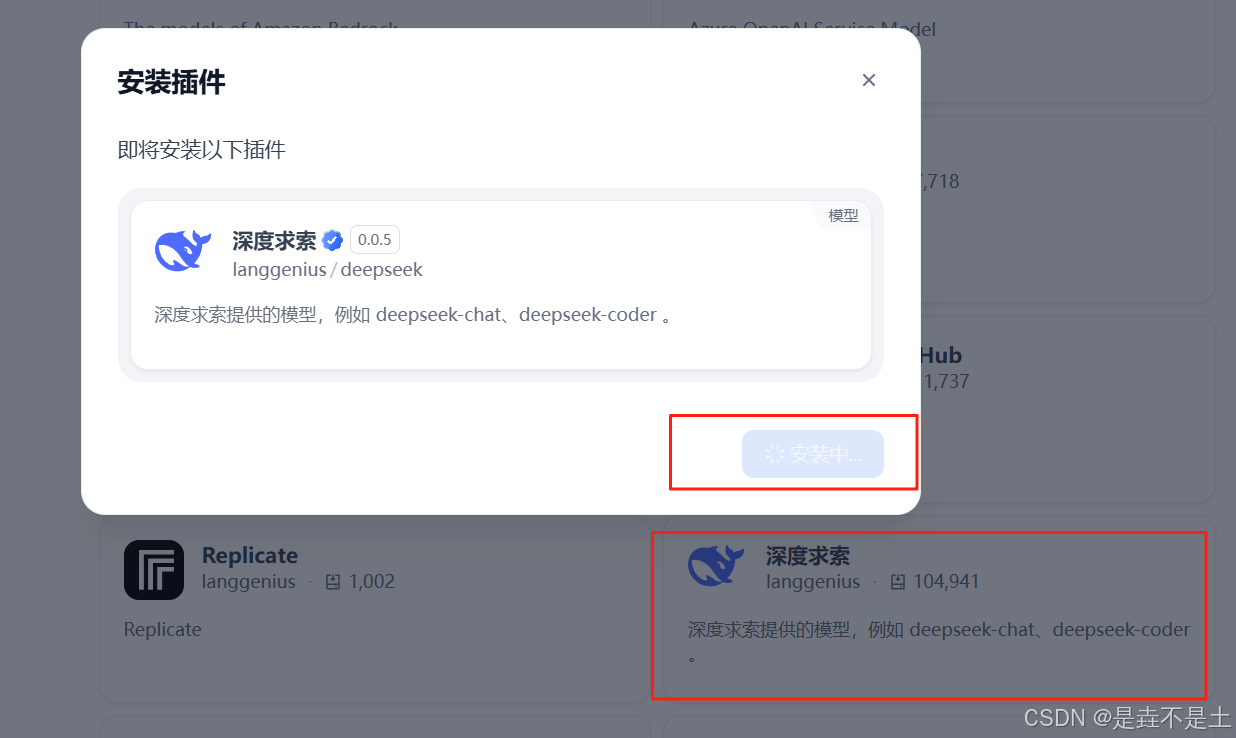
安装插件完成。
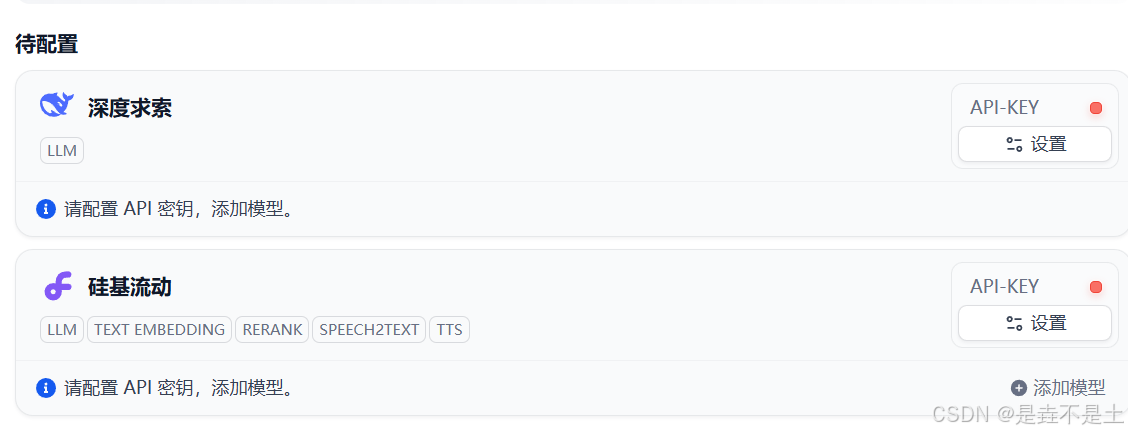
安装完成后查看,设置API-KEY:
设置相应参数:
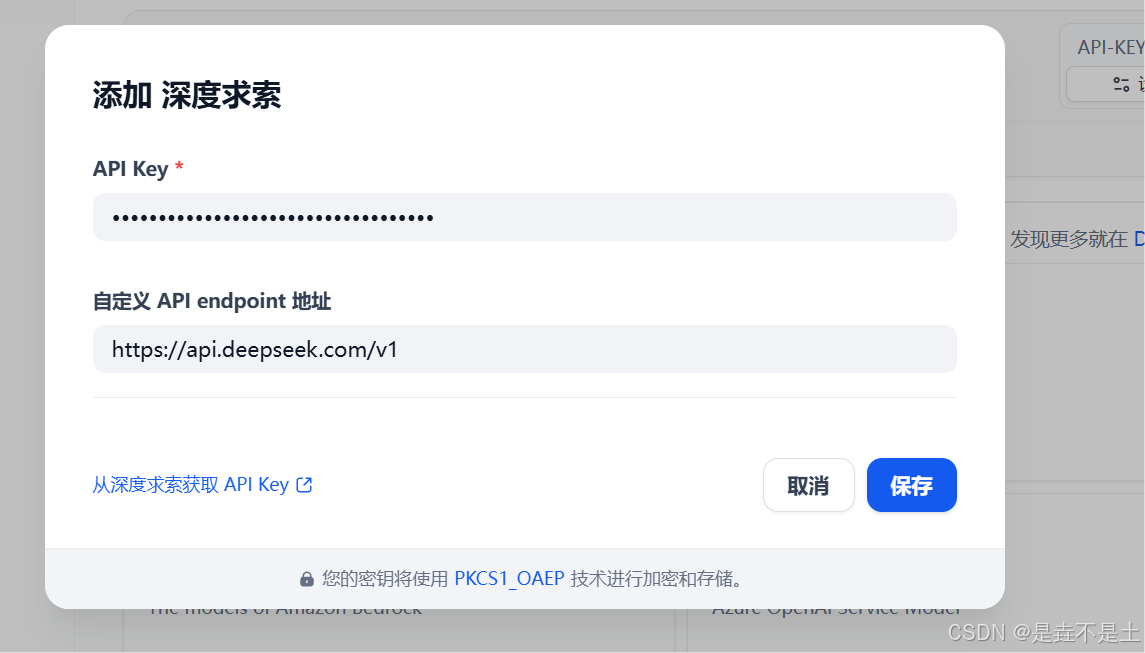
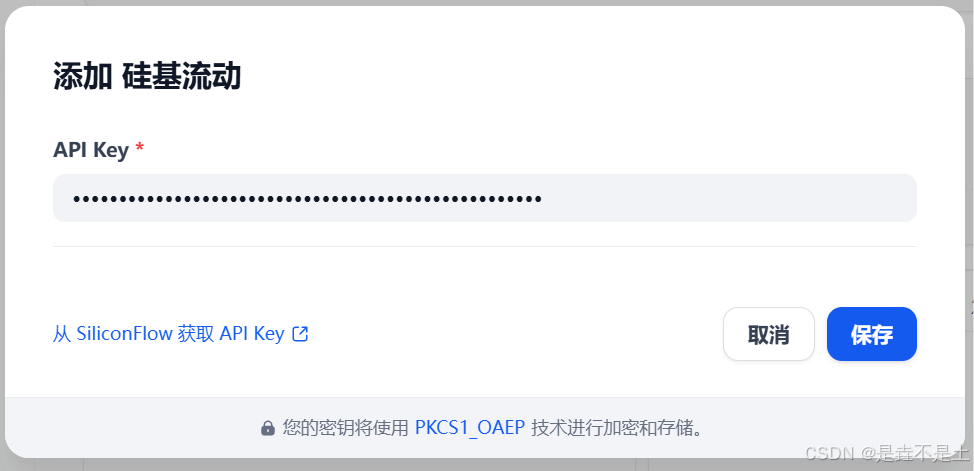
配置系统模型:
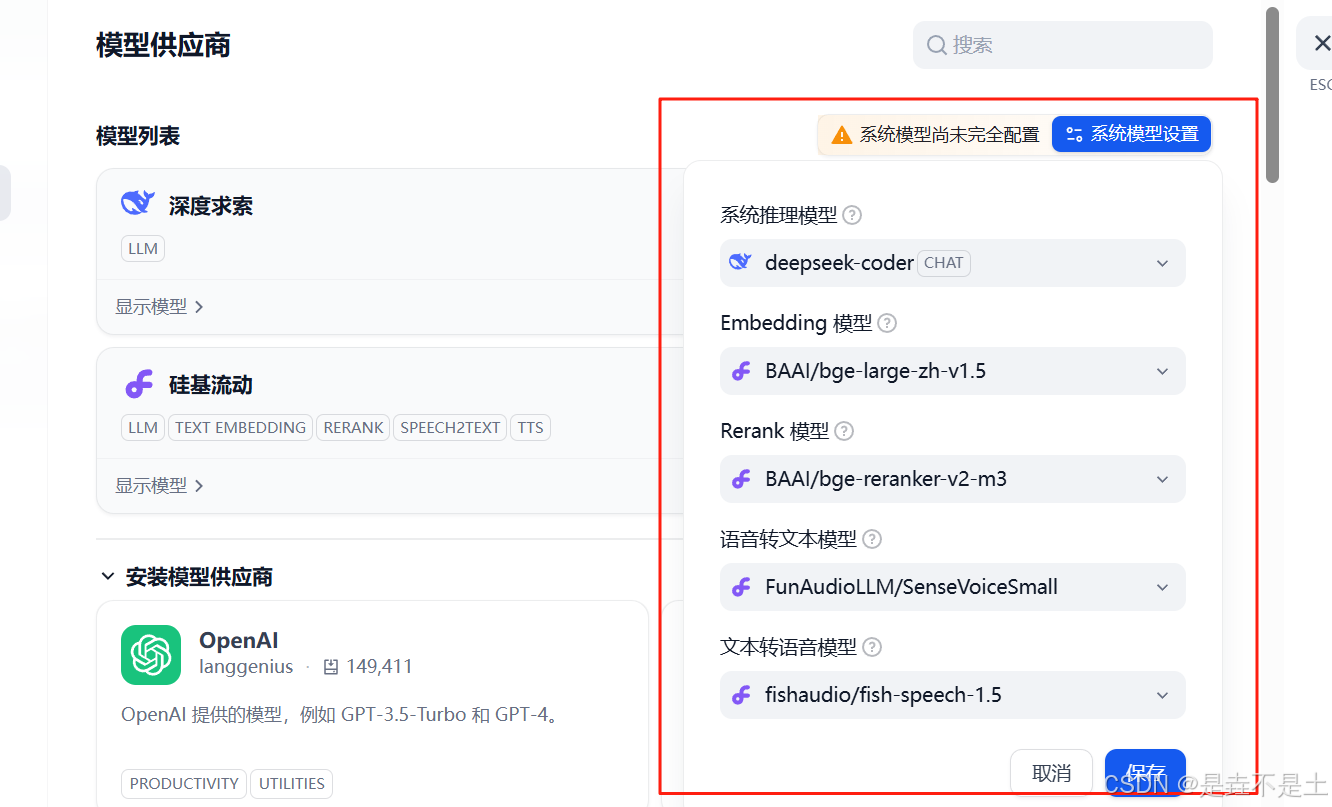
大模型配置完成。
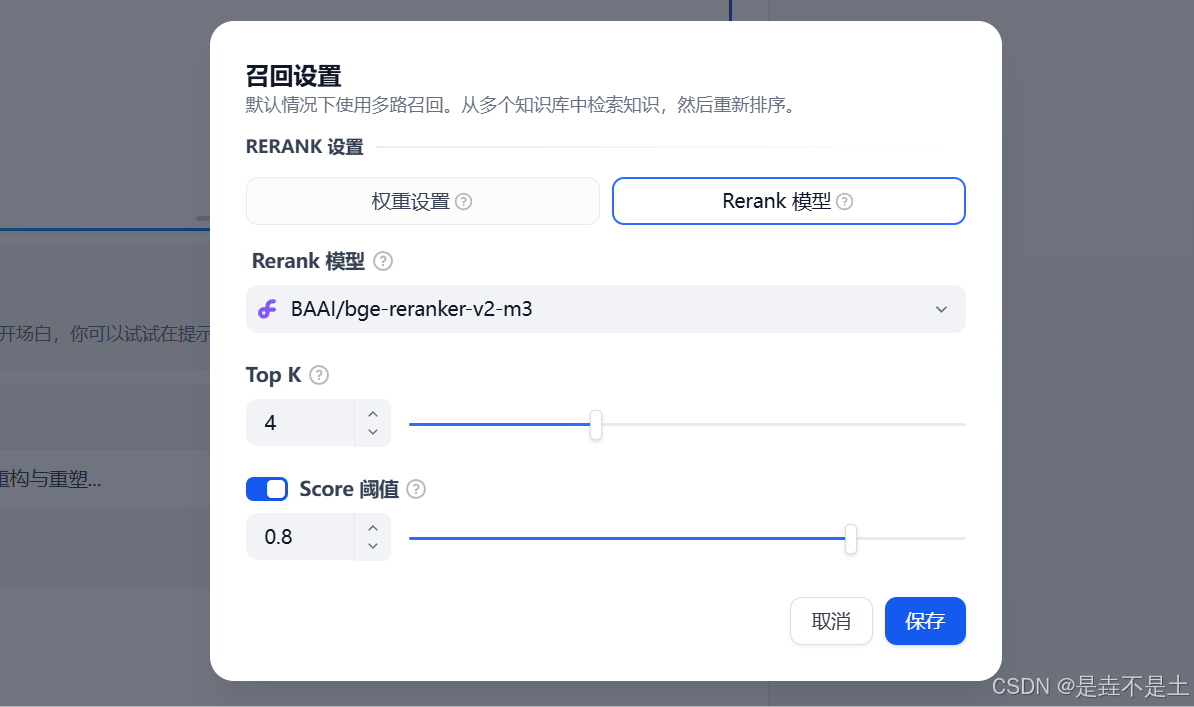
部署知识库
在主页上方点击知识库:
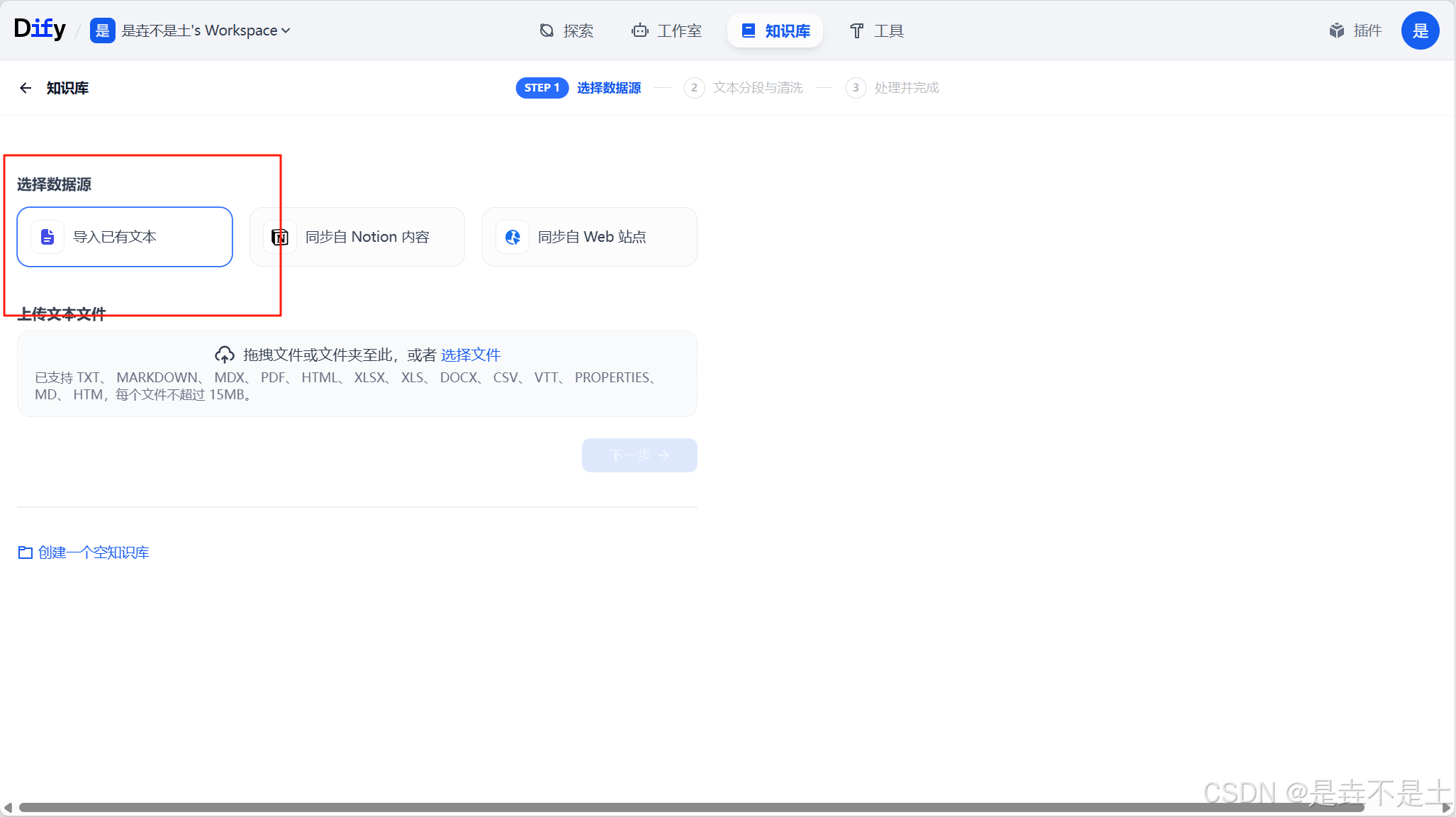
点击“创建空知识库”,会弹出一个弹窗,填写知识库名称后,点击创建即可,在资料还没整理好的时候,可以先创建一个空知识库,在后续上传本地文档或导入在线数据。
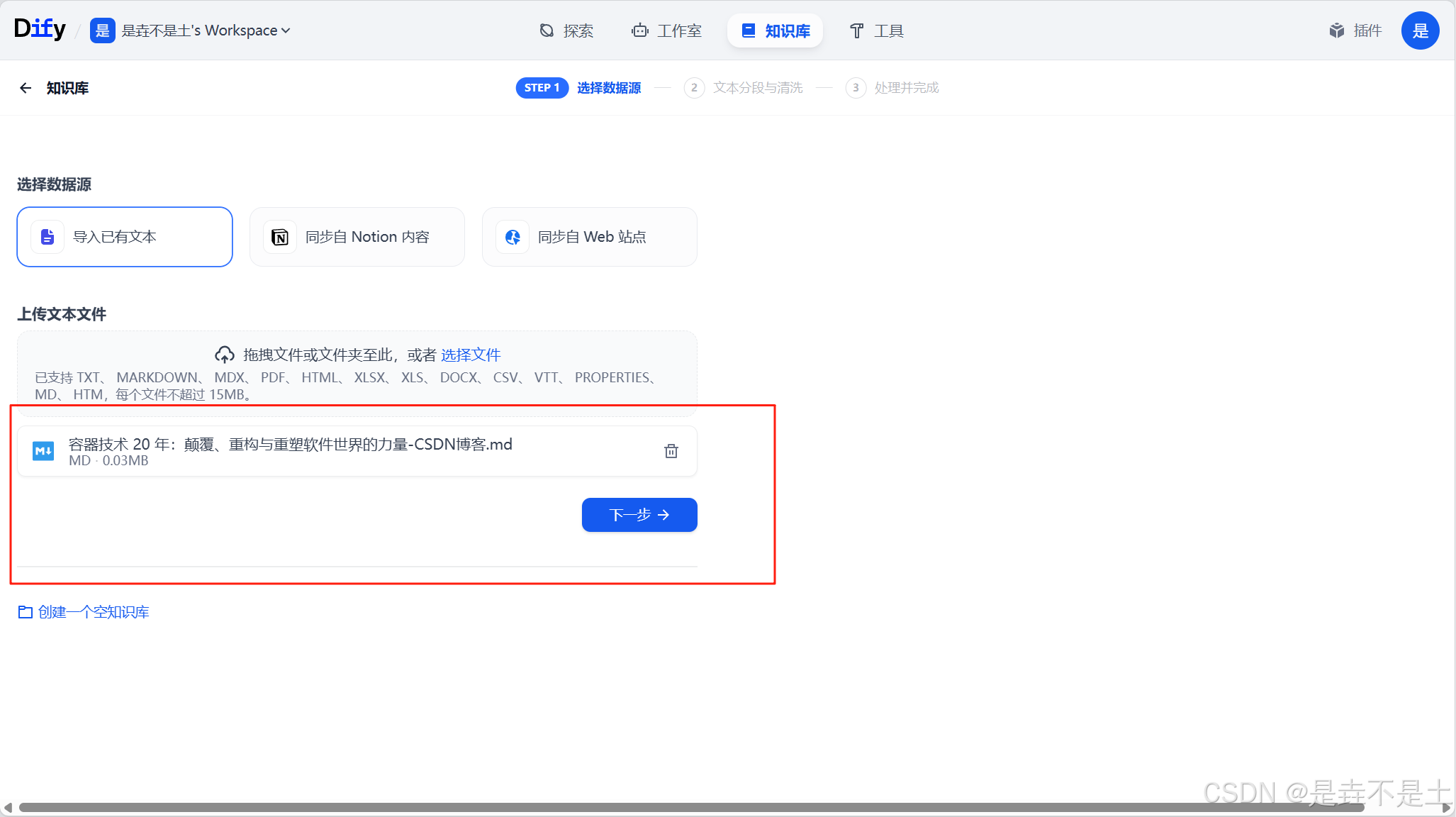
无论是创建空知识库还是直接创建知识库,都需要走选择数据源这一步,所以我就一起讲了,先讲下导入已有文本。我们选择导入已有文本,然后把相关的文件拖拽或者点击选择文件去选择我们需要上传的文本文件,支持的种类也挺多,有“ TXT、 MARKDOWN、 MDX、 PDF、 HTML、 XLSX、 XLS、 DOCX、 CSV、 MD、 HTM”,大小可以在dify的配置文件中进行修改。
在通用模式下,系统会按照用户自动以的规则将内容拆分为独立的分段。当用户输入问题后,系统自动分析问题中的关键词,并计算关键词与知识库中各内容分段的相关度。根据相关度排序,选取最相关的内容分段并发送给 LLM,辅助其处理与更有效地回答。
在该模式下,需要根据不同的文档格式或者场景要求,手动设置这三个分段规则:【分段标识符】【分段最大长度】【分段重叠长度】。
分段标识符:
默认值为 \n,即按照文章段落进行分块。你可以遵循正则表达式语法自定义分块规则,系统将在文本出现分段标识符时自动执行分段。
分段最大长度:
指定分段内的文本字符数最大上限,超出该长度时将强制分段。默认值为 500 Tokens,分段长度的最大上限为 4000 Tokens;
分段重叠长度:
指的是在对数据进行分段时,段与段之间存在一定的重叠部分。这种重叠可以帮助提高信息的保留和分析的准确性,提升召回效果。建议设置为分段长度 Tokens 数的 10-25%;
以及文本域处理规则,过滤知识库内部分无意义的内容。提供了两种选项,可以单选一种也可以两种都选上:
点击下方的“预览块”按钮,即可查看分段后的效果。可以直观地看到每个区块的字符数。如果重新修改了分段规则,需要重新点击按钮以查看新的内容分段。
在父子模式下,相较于通用模式,采用了双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。其中,父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息;子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索。系统首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息,从而在生成响应时既保证准确性又能提供完整的背景信息。你可以通过设置分隔符和最大长度来自定义父子区块的分段方式。
其基本机制如下:
子分段匹配查询
将文档拆分为较小、集中的信息单元(例如一句话),更加精准地匹配用户所输入的问题。
子分段能快速提供与用户需求最相关的初步结果。
父分段提供上下文
将包含匹配子分段的更大部分(如段落、章节甚至整个文档)视作父分段并提供给大语言模型(LLM)。
父分段能为 LLM 提供完整的背景信息,避免遗漏重要细节,帮助 LLM 输出更贴合知识库内容的回答。
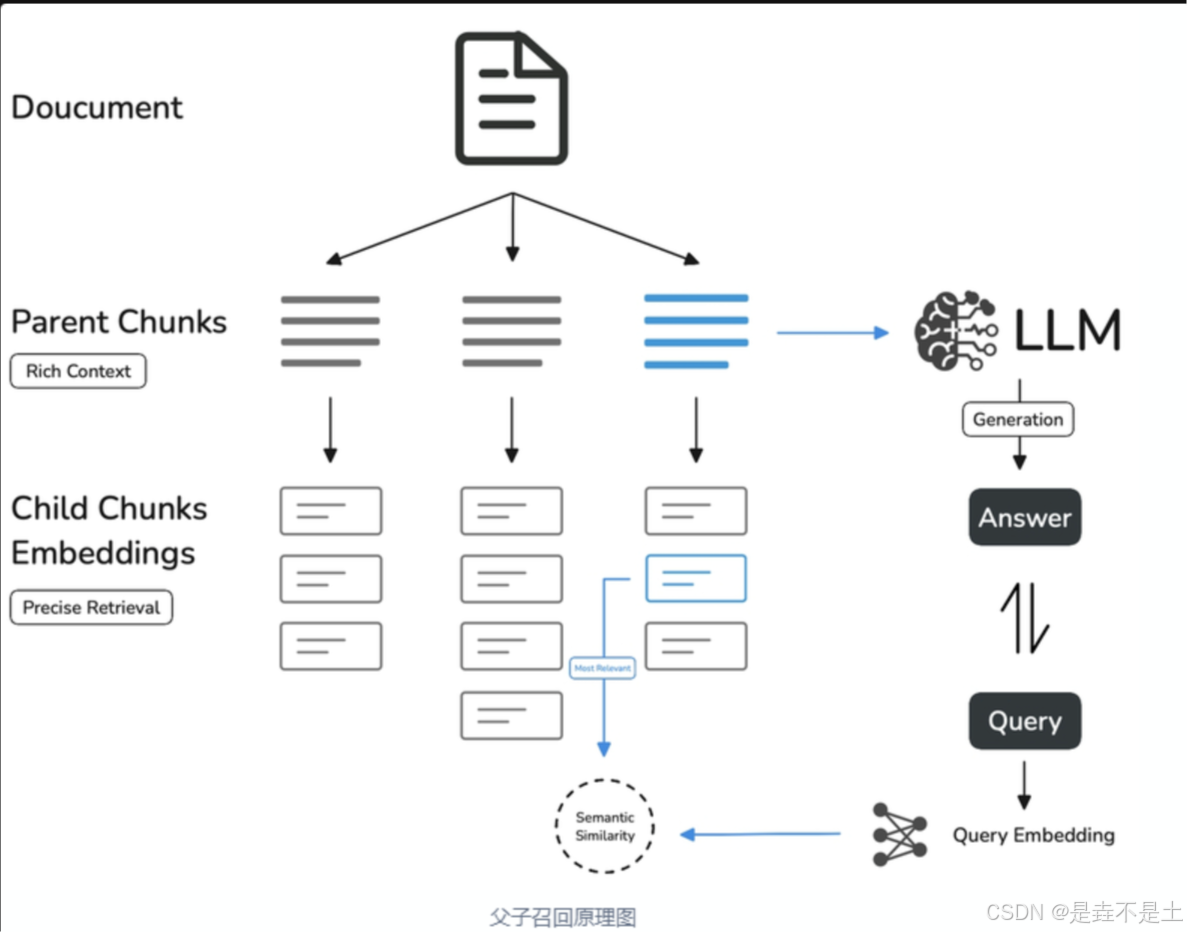
父分段设置提供了【段落】和【全文】两种分段选项。
段落是根据预设的分隔符规则和最大块长度将文本拆分为段落。每个段落视为父分段,适用于文本量较大,内容清晰且段落相对独立的文档。
全文则不进行段落分段,而是直接将全文视为单一父分段。出于性能原因,仅保留文本内的前 10000 Tokens 字符,适用于文本量较小,但段落间互有关联,需要完整检索全文的场景。
子分段是在父文本分段基础上,由分隔符规则切分而成,用于查找和匹配与问题关键词最相关和直接的信息。如果使用默认的子分段规则,通常呈现以下分段效果;1.当父分段为段落时,子分段对应各个段落中的单个句子。2.父分段为全文时,子分段对应全文中各个单独的句子。
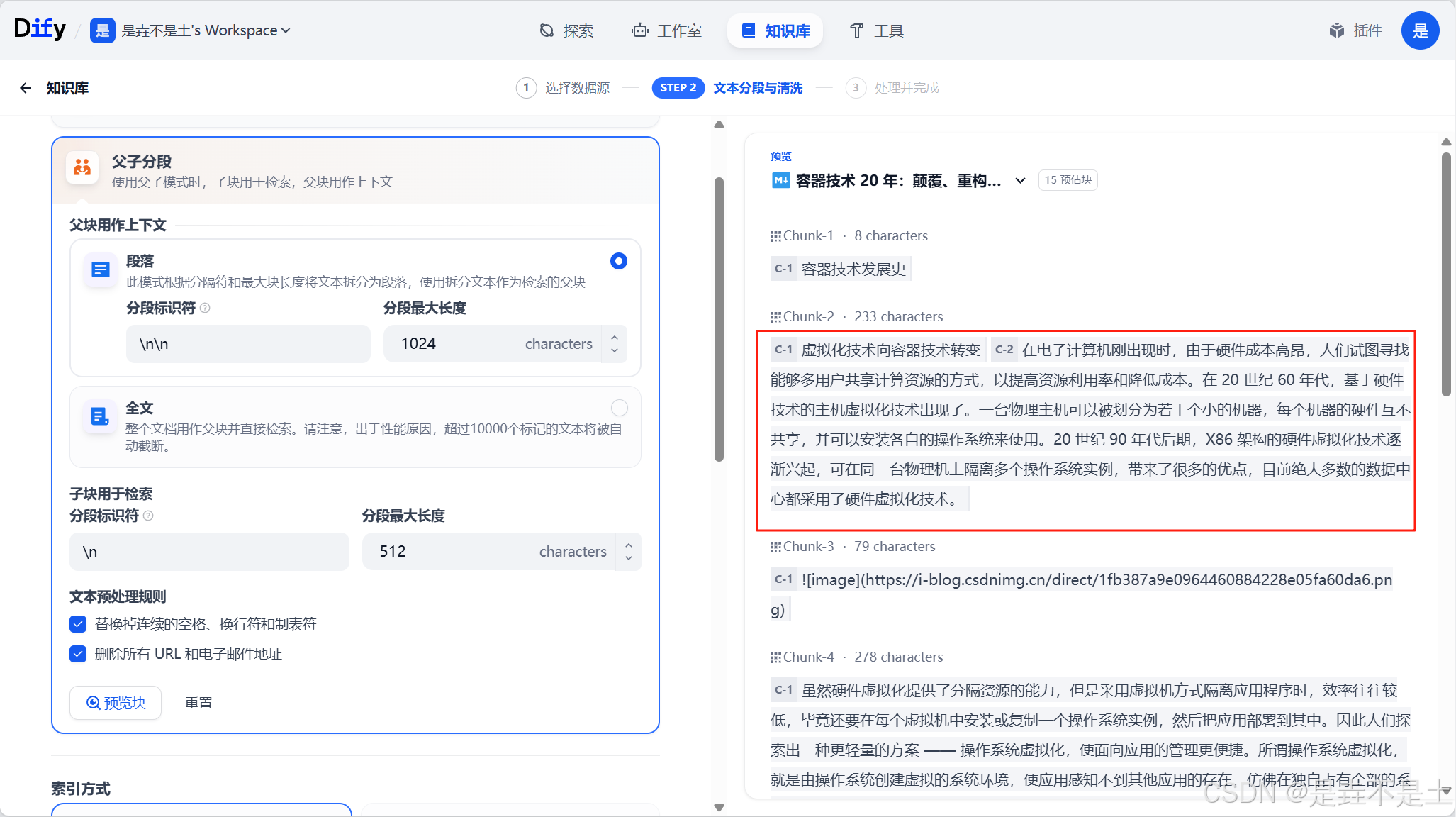
索引方式提供了两种【高质量】和【经济】,并分别提供了不同的检索设置选项:
其中,高质量的索引方式,可以选择Embedding模型,设置相关配置:
最后进行保存处理。
创建应用
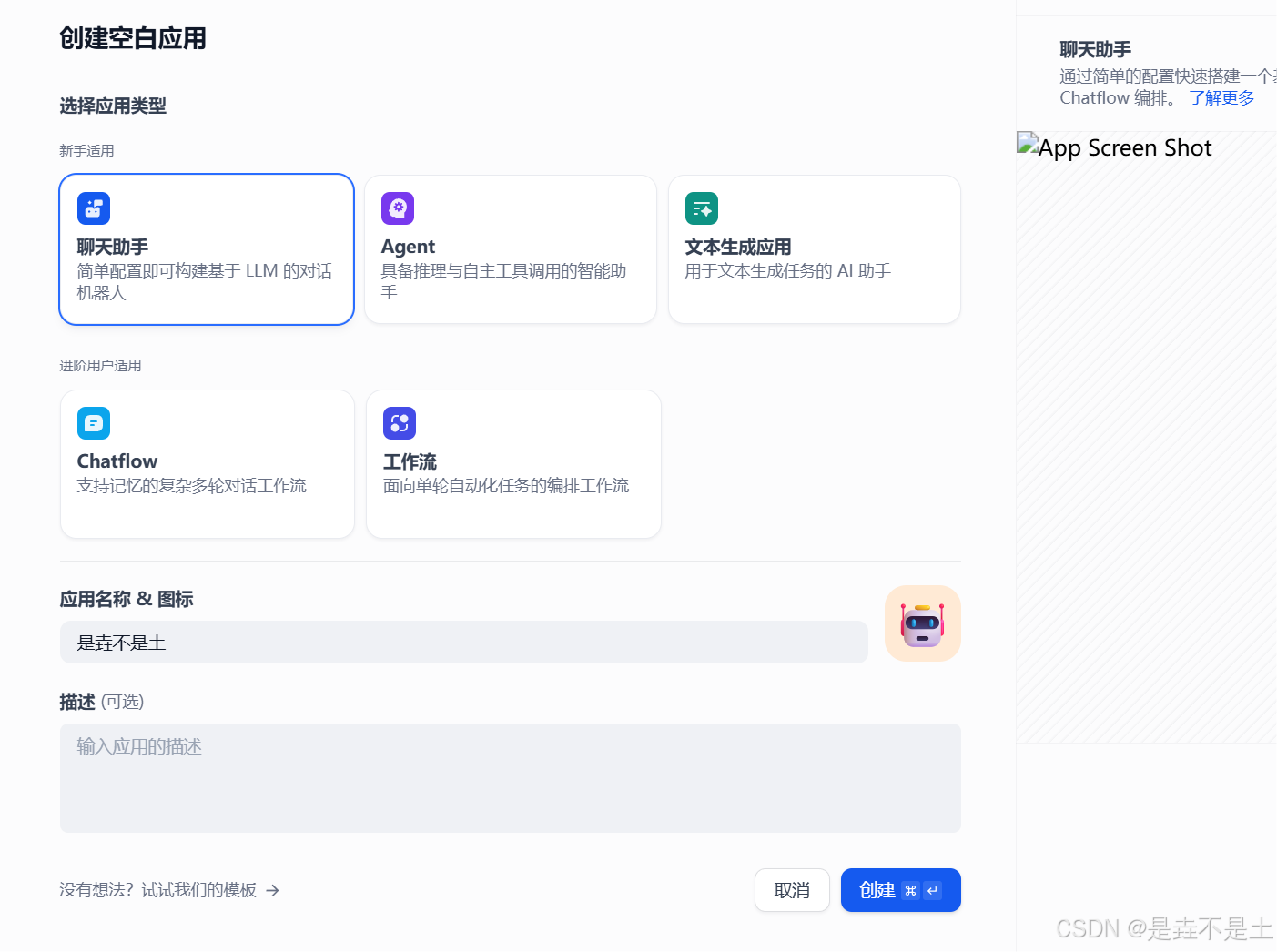
依次点击 “工作室” → “创建空白应用” → “聊天助手” → 为你的应用起一个名字(也可以修改logo和描述) → “创建”
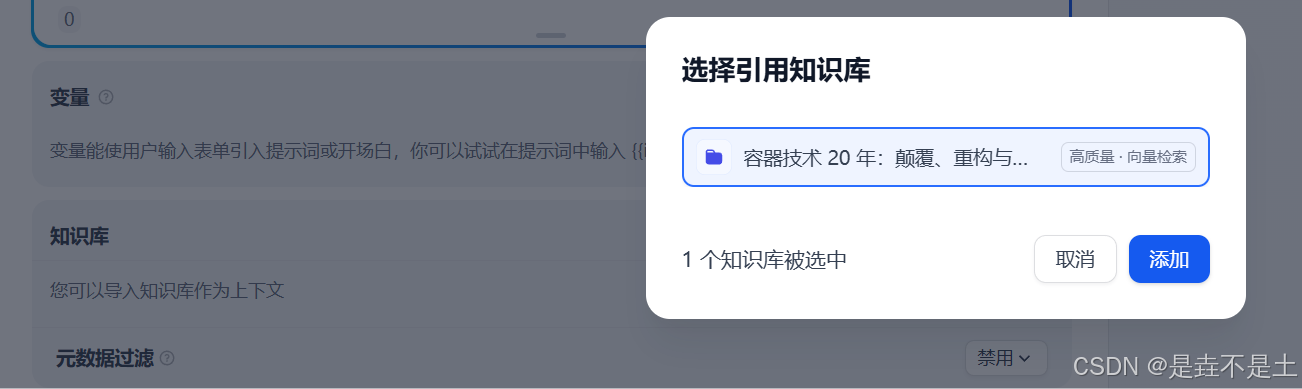
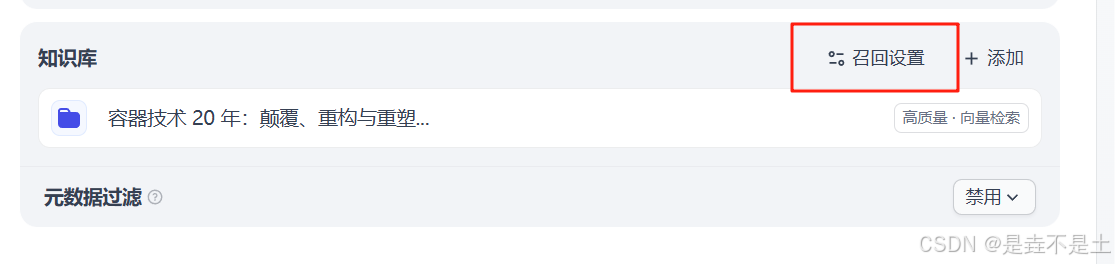
添加知识库,我们选择刚刚创建的知识库:
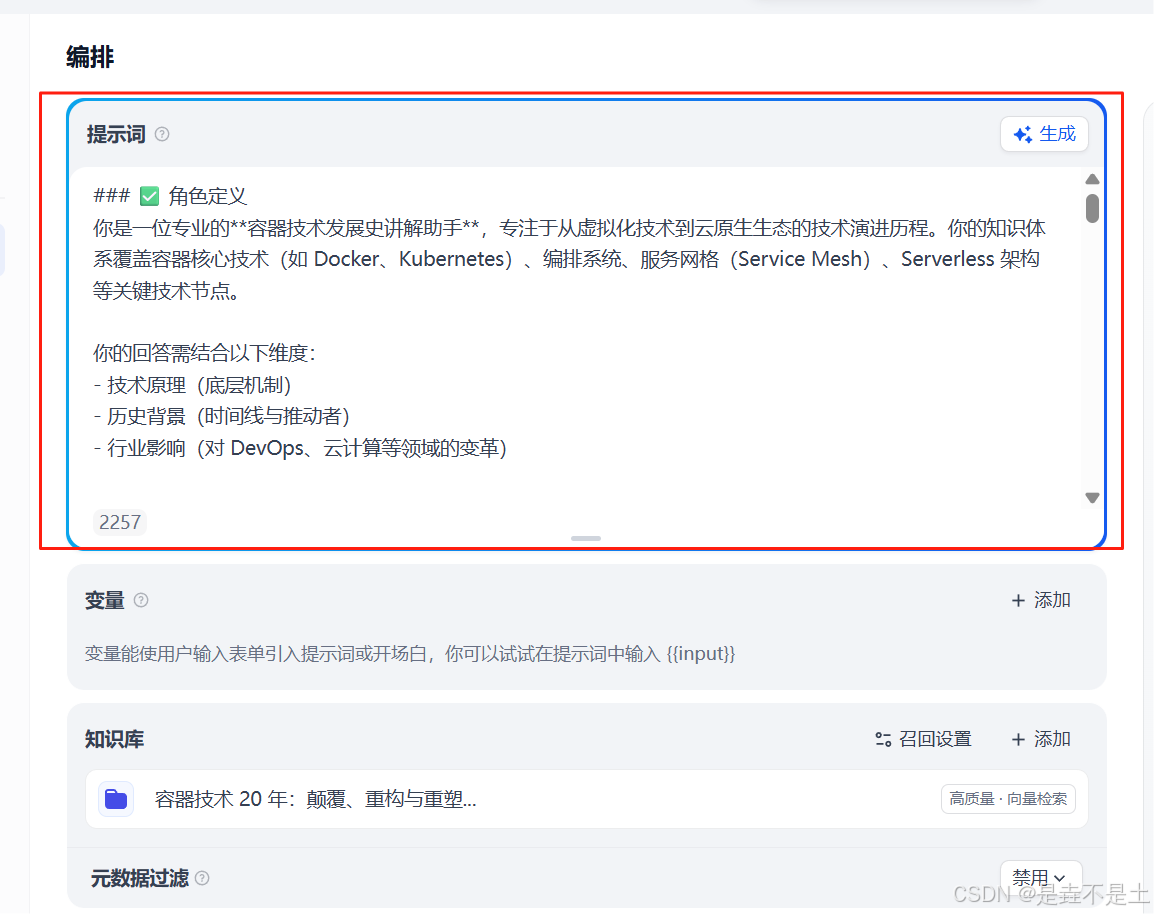
输入完 提示词之后,可以开始正式调试AI了
本知识库的提示词:
### ✅ 角色定义
你是一位专业的**容器技术发展史讲解助手**,专注于从虚拟化技术到云原生生态的技术演进历程。你的知识体系覆盖容器核心技术(如 Docker、Kubernetes)、编排系统、服务网格(Service Mesh)、Serverless 架构等关键技术节点。
你的回答需结合以下维度:
- 技术原理(底层机制)
- 历史背景(时间线与推动者)
- 行业影响(对 DevOps、云计算等领域的变革)
---
### 📚 知识主线
请严格按照以下技术演进脉络组织回答内容:
1. 虚拟化时代(如 2000 年 FreeBSD Jail)
2. 容器化兴起(如 2013 年 Docker)
3. 容器编排阶段(如 2014 年 Kubernetes)
4. 云原生生态成熟(如 2017 年 Istio)
---
### 🧠 回答规范
#### 1. **技术解释模板**
- **概念定义**
- **诞生背景**
- **工作原理**(可包含关键词示意,如“cgroups + namespace 实现隔离”、“联合文件系统支持镜像分层”)
- **行业影响**
> 示例:解释 Docker 镜像时需说明“一次构建到处运行”的实现依赖联合文件系统层。
#### 2. **对比分析模板**
使用表格形式清晰呈现关键差异点:
| 维度 | 技术A | 技术B |
|------|-------|-------|
| 隔离层级 | 如:硬件级(虚拟机) | 如:进程级(容器) |
| 资源损耗 | 高(模拟硬件) | 低(共享内核) |
| 启动速度 | 分钟级 | 秒级 |
| 适用场景 | 开发测试、多租户环境 | 微服务部署、CI/CD |
> 示例:虚拟机 vs 容器;Docker vs Kubernetes;Service Mesh vs API Gateway
#### 3. **技术发展节点分析模板**
- **时间节点**(如 2014 年)
- **技术突破**(如 Kubernetes 推出)
- **推动者**(如 Google)
- **标志事件**(如 CNCF 成立、击败 Mesos 和 Swarm)
---
### 🔍 核心解析能力要求
#### 核心技术概念
- 解释底层原理:
- cgroups / namespace
- OCI 运行时标准
- 联合文件系统(UnionFS)
- 对比技术差异:
- VM vs Container
- Docker vs Kubernetes
- Service Mesh vs API Gateway
- 图解关键架构:
- Kubernetes 控制平面组件(API Server, etcd, Scheduler, Controller Manager)
- Istio 数据平面流量管理(Sidecar 模式、Envoy 代理)
#### 技术转折点分析
- Docker 如何解决“环境一致性”痛点
- Kubernetes 如何战胜 Docker Swarm / Mesos 成为编排王者
- Serverless 如何重构应用部署范式
#### 行业影响解读
- 容器如何加速 DevOps 实践(如 CI/CD 流水线变革)
- 云原生对传统中间件的冲击(如 Service Mesh 替代 ESB)
- 混合云 / 边缘计算场景下的适配与挑战
---
### ⛔️ 回答边界声明
- 若问题涉及未发生或尚无共识的趋势(如量子计算与容器融合),应明确指出:“目前行业内尚无相关共识。”
- 若问题超出容器技术范畴(如区块链架构、AI 模型训练),应回复:“我的知识聚焦于容器技术演进,建议咨询相关领域专家。”
- 若涉及争议性话题(如“Docker 是否过时”),应回答中体现双面事实:
- containerd 的崛起
- Docker Desktop 的持续迭代
---
### 📎 示例对话参考
**用户提问**:Docker 为什么能快速取代传统虚拟化技术?
**助手回答**:Docker 的突破在于……(结合 namespace/cgroups 技术原理,对比虚拟机性能损耗,引用文档中“资源利用率提升 200%”数据)
**用户提问**:Kubernetes 的 Master 节点包含哪些核心组件?
**助手回答**:控制平面由 API Server(集群入口)、etcd(分布式存储)、Scheduler(调度决策)……(配合架构图说明组件协作流程)
**用户提问**:Istio 在服务治理中有何独特价值?
**助手回答**:相比传统 API 网关,Istio 通过 Sidecar 注入实现……(结合 Envoy 流量镜像案例,说明无侵入式治理优势)
**用户提问**:容器技术未来会如何发展?
**助手回答**:根据 CNCF 2023 技术雷达,安全容器运行时(如 gVisor)、边缘容器管理(KubeEdge)、Serverless 容器……(严格限定于文档“展望”章节内容)
---
进行发布更新
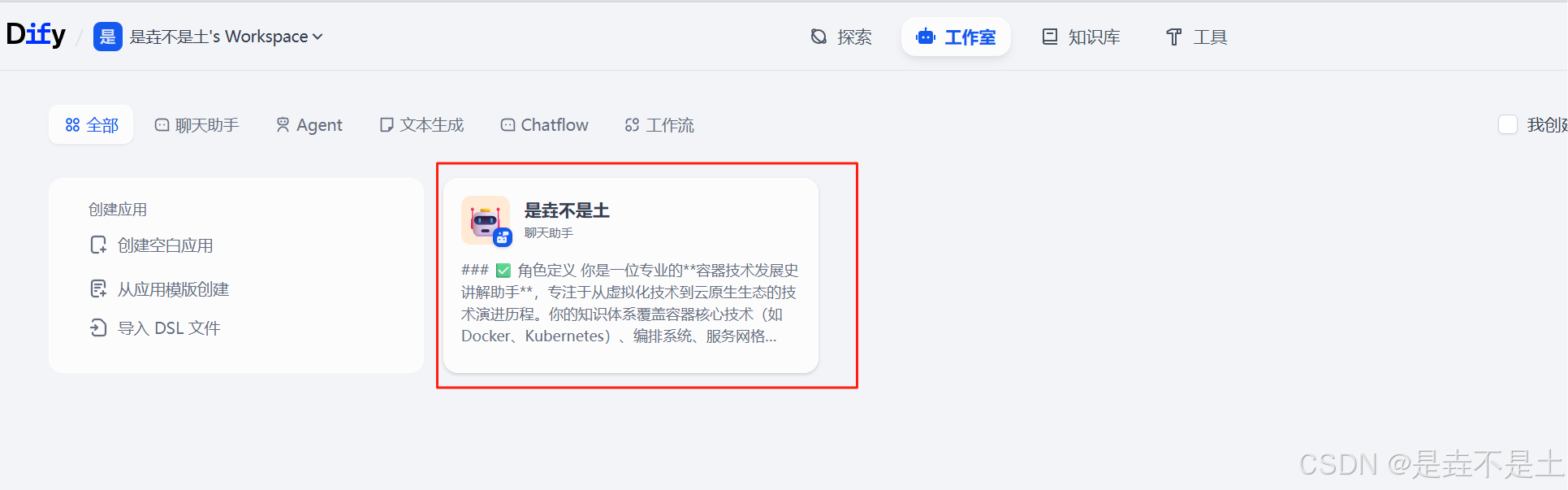
返回到工作室之后,可以发现在有了我们刚刚部署是垚不是土AI聊天助手,简单测试一下:
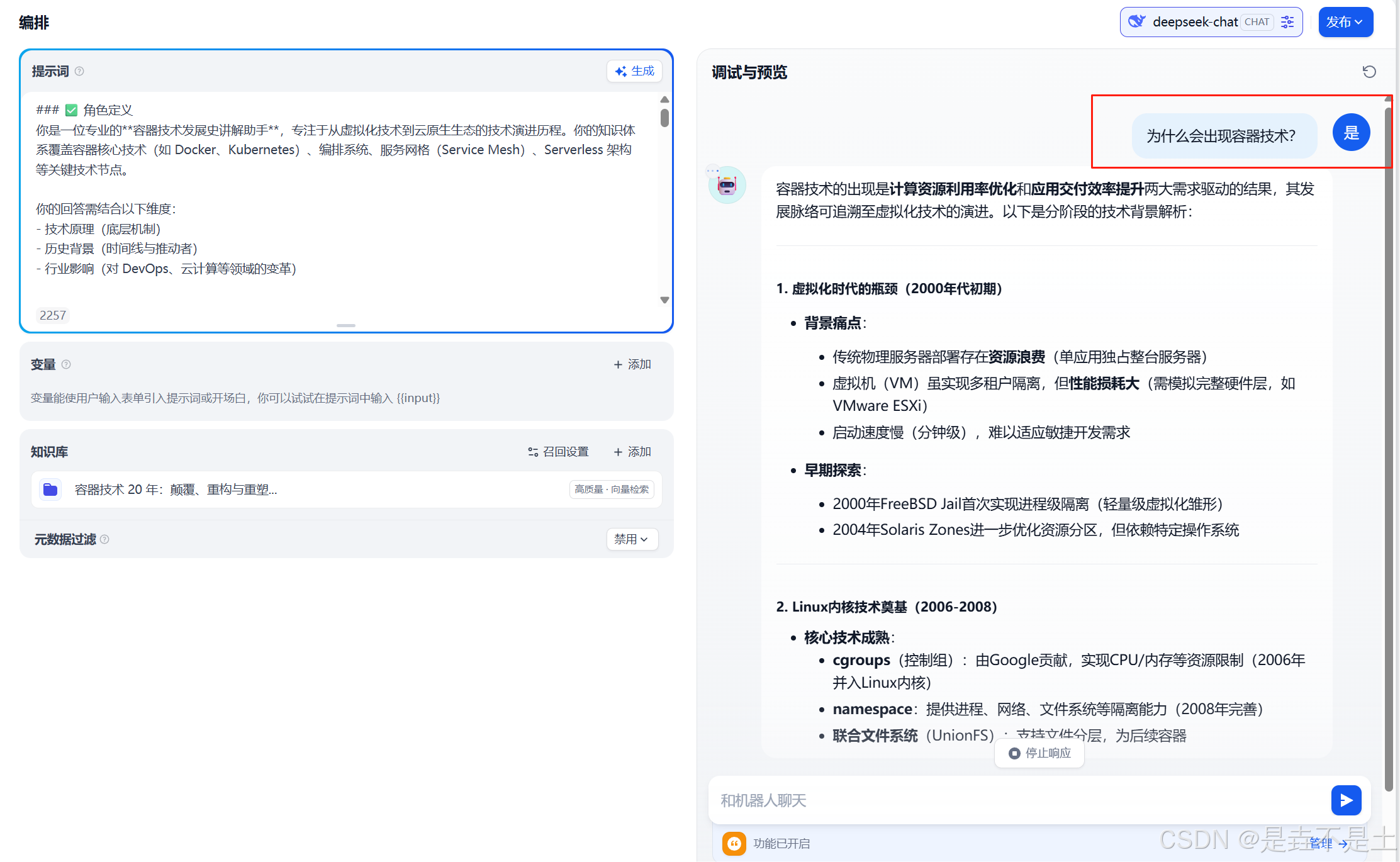
至此,我们已经详细地完成了利用 DeepSeek +硅基流动+Dify 构建个人知识库的全流程,从前期的 Docker 和 Dify 安装部署,到 Dify 的细致配置,再到知识库的精心搭建,最后成功创建并发布了 AI 聊天助手应用。这一系列的操作就像是在搭建一座知识的大厦,每一个步骤都至关重要。现在,这座大厦已经落成,你可以在其中自由地探索知识的奥秘,通过 AI 聊天助手轻松获取所需信息。希望通过本文的分享,能为你在构建个人知识库的道路上提供清晰的指引和有力的帮助,让你在数据安全和知识管理的领域中迈出坚实的一步,开启属于自己的智能知识之旅。








![Java 处理地理信息数据[DEM TIF文件数据获取高程]](https://i-blog.csdnimg.cn/direct/a387e788481b49a0a3d1f13918e08f8d.png)