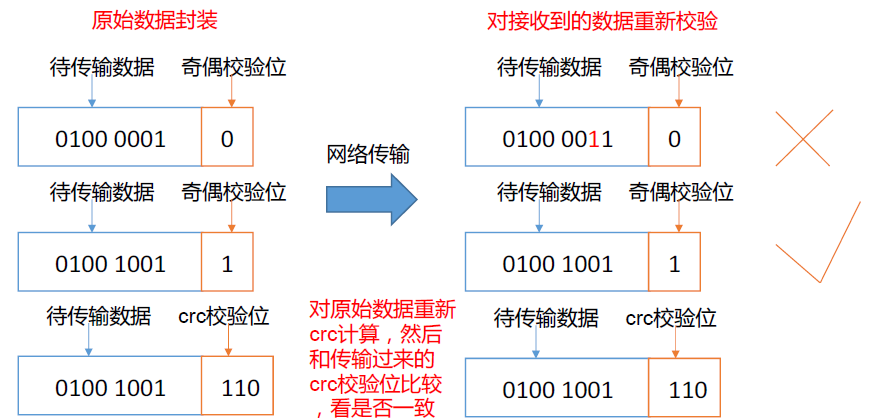
chapter2:深度学习基础
区分问题:回归问题还是分类问题?
输出结果是不明确的连续值的时候就是回归问题,比如房价预测,销售额预测等。
输出结果是明确几个离散值的时候就是分类问题,比如字符识别,猫狗分类等。
softmax回归是预测明确几个离散值,则适用于分类问题。
---------------------------------------------------------
2.1.1线性回归问题
以房价预测为例子,假设价格只取决于房屋状况的两个因素,即面积(平方米)和房龄(年)。
模型:就是x和y的表达式
设房屋的面积为 x1,房龄为x2 ,售出价格为 y,则模型是:
![]()
其中 w1和 w2是权重(weight), b是偏差(bias),且均为标量。
定义模型后,就要考虑训练模型
训练集(training set):收集一系列的真实数据,例如多栋房屋的真实售出价格和它们对应的面积和房龄
样本(sample):一个房屋就是一个样本
标签(label):一个房屋售出的真实价格
特征(feature):用来预测标签的两个因素
预测值表达式:

红线部分是需要训练得出的参数
损失函数(loss function):衡量预测值与真实值误差的函数称为损失函数
书中给出的本例子的损失函数:

分析一波损失函数的特点:
1、通常选择平方函数,通常选取误差为非负数,且预测值与真实值相等时为0,
2、常数1/2使对平方项求导后的常数系数为1
如何衡量模型预测的质量?
所有样本误差的平均值来衡量模型预测的质量
即:
样本平均损失最小,就是我们期望的w1,w2,b的参数值
对于求解w1,w2,b分出两种情况。
解析解:模型和损失函数简单,解可以求出来,就像这次房屋预测的线性模型一样,可以求出一个精确的解。
数值解:复杂的模型没有解析解,只能通过不断去迭代参数降低损失函数的值(深度学习通常为数值解)
数值解不断迭代的求解的做法是可以用在求解解析解,不断逼近解析解从而求解。
ps:通常情况下数值解解决复杂问题更加有意义,很多问题都不是线性这么简单,这也就是激活函数存在的意义,激活函数在后续会介绍。
数值解如何迭代求解?
书中介绍“小批量随机梯度下降(mini-batch stochastic gradient descent)"

这里就是用数值解迭代方式求解解析解的房屋预测问题。
超参数:人为设定,并不是模型训练给出,比如这里的批量大小和学习率。
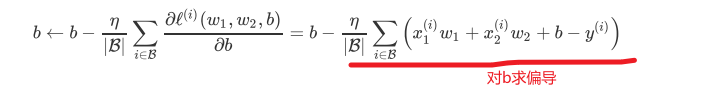 ps:损失函数设定应当是便于求导的,上面设置损失函数方便梯度下降迭代。
ps:损失函数设定应当是便于求导的,上面设置损失函数方便梯度下降迭代。
简单点,梯度下降就是用来求某个函数最小值时,自变量对应取值。
这篇文章细讲了梯度下降,可以了解它的原理,sir, this way:梯度下降![]() https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247626752&idx=4&sn=bfcf5f9c656316175c03d766c7bf3d63&chksm=fa8a4f6576277a914accf065dae89e80626eaa86b49964c677370d7915a52853ed2d33145990&scene=27
https://mp.weixin.qq.com/s?__biz=MzU0NjgzMDIxMQ==&mid=2247626752&idx=4&sn=bfcf5f9c656316175c03d766c7bf3d63&chksm=fa8a4f6576277a914accf065dae89e80626eaa86b49964c677370d7915a52853ed2d33145990&scene=27
学习率:是梯度下降算法中的一个关键参数,它决定了每次更新参数的步长。选择合适的学习率非常重要,学习率过大或过小都会影响模型的收敛效果。过大无法收敛,过小训练时间太长。
-------------------------------------
2.1.2 线性回归的表示方法
神经网络图
之前例子房屋预测神经网络图:
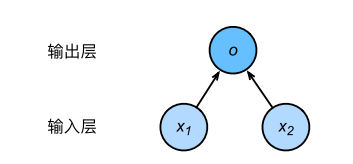
特征向量维度(特征数):输入个数也叫特征数或特征向量维度,这里为2。
层数:层数为1层,线性回归是单层神经网络
神经元:输出层中负责计算o 的单元又叫神经元
全连接层:输出层中的神经元和输入层中各个输入完全连接。
矢量计算:
数字图像是一个数字矩阵,不可避免需要大量运算,书中用两个1000维向量相加验证了矢量运算的优越性。
import torch
from time import time
a = torch.ones(1000)
b = torch.ones(1000)
# 标量运算,逐个相加
start = time()
c = torch.zeros(1000)
for i in range (1000):
c[i] = a[i]+b[i]
end= time()
print (end - start)
#向量运算,矢量加法
start = time()
c=a+b
end = time()
print(end - start)
在本人的破电脑上用时如下:
![]()
矢量计算 Win!
一张 500w黑白相机拍出来的图片,如果作为输入,那个维度就是现在的很多倍,时间差异和矢量计算优越性的就会明显体现出来。
在房价预测将标量运算重写为矢量运算,书中这么写:


------------------------------------------------------------
2.2线性回归从零实现
为了更好理解,只利用 Tensor 和 autograd 来实现一个线性回归的训练
2.2.1生成数据集:

实现代码(书中代码有些版本问题,已经处理bug):
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():
# 用矢量图显示
matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
plt.show();数据图像如下:

2.2.2读取数据集
在训练模型的时候,我们需要遍历数据集并不断读取小批量数据样本。这里我们定义一个函数:它 每次返回 batch_size (批量大小)个随机样本的特征和标签。让我们读取第一个小批量数据样本并打印。每个批量的特征形状为(10, 2),分别对应批量大小和输 入个数;标签形状为批量大小。
实现如下(#分线后面的为这部分实现的):
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():
# 用矢量图显示
matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
#plt.show();
####################################################接下来是本部分
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 样本的读取顺序是随机的
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
# 最后一次可能不足一个batch
j = torch.LongTensor(indices[i: min(i+batch_size,num_examples)])
# index_select函数根据索引返回对应元素
yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, y)
break
读取效果如下:

2.2.3初始化参数&定义模型&定义损失函数&定义优化算法
初始化参数:初始化w1,w2权重值为均值为0、标准差为0.01的正态随机数,偏差b则初始化成0。
w1,w2,b都是要不断去迭代的,求梯度(偏导数)来迭代参数,因此我们要让它们的 requires_grad=True 。
定义模型:是线性回归的矢量计算表达式的实现,使用 mm() 函数做矩阵乘法。
(ps:torch.mul()执行的是元素级相乘,也称为Hadamard乘积,保持输入矩阵的维度不变。torch.mm()则进行矩阵乘法,要求特定的维度匹配,二维矩阵乘积,返回一个新的矩阵。torch.matmul()更通用,可处理多维矩阵。)
定义损失函数:使用上一节描述的平方损失函数来定义线性回归的损失函数,其中真实值y和预测值为y_hat
定义优化算法:小批量随机梯度下降算法,通过不断迭代模型参数来优化损失函数。这里定义了sgd函数自动求梯度模块计算得来的梯度是一个批量样本的梯度和,将它除以批量大小来得到平均值。
在训练中,我们将多次迭代模型参数。在每次迭代中,我们根据当前读取的小批量数据样本(特征 X 和标签 y ),通过调用反向函数 backward 计算小批量随机梯度,并调用优化算法 sgd 迭代模型参 数。由于我们之前设批量大小 batch_size 为10,每个小批量的损失 l 的形状为(10, 1)。回忆一下自动 求梯度一节。由于变量 l 并不是一个标量,所以我们可以调用 .sum() 将其求和得到一个标量,再运行 l.backward() 得到该变量有关模型参数的梯度。注意在每次更新完参数后不要忘了将参数的梯度清零。(如果不清零,PyTorch默认会对梯度进行累加)
在一个迭代周期(epoch)中,我们将完整遍历一遍 data_iter 函数,并对训练数据集中所有样本 都使用一次(假设样本数能够被批量大小整除)。这里的迭代周期个数 num_epochs 和学习率 lr 都是超参数,分别设3和0.03。在实践中,大多超参数都需要通过反复试错来不断调节。虽然迭代周期数设得越大模型可能越有效,但是训练时间可能过长。
实现如下:
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
from IPython import display
import matplotlib_inline
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs, dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),dtype=torch.float32)
def use_svg_display():
# 用矢量图显示
matplotlib_inline.backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize
set_figsize()
# 加分号只显示图
plt.scatter(features[:, 1].numpy(), labels.numpy(), 1);
#####读取数据集#####
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 样本的读取顺序是随机的
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
# 最后一次可能不足一个batch
j = torch.LongTensor(indices[i: min(i+batch_size,num_examples)])
# index_select函数根据索引返回对应元素
yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10
#for X, y in data_iter(batch_size, features, labels):
# print(X, y)
# break
#####初始化模型参数#####
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)),dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
#####定义模型#####
def linreg(X, w, b):
return torch.mm(X, w) + b
##### 定义损失函数#####
def squared_loss(y_hat, y):#
return (y_hat - y.view(y_hat.size())) ** 2 / 2
#####定义优化算法#####
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
# 训练模型一共需要num_epochs个迭代周期
for epoch in range(num_epochs):
# 在每一个迭代周期中,会使用训练集中所有样本一次(假设样本数能够被批量大小整除)。
# X和y分别是小批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
# l是有关小批量X和y的损失
l = loss(net(X, w, b), y).sum()
# 小批量损失对模型参数求梯度
l.backward()
# 使用小批量随机梯度下降迭代模型参数
sgd([w, b], lr, batch_size)
# 梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch+1, train_l.mean().item()))
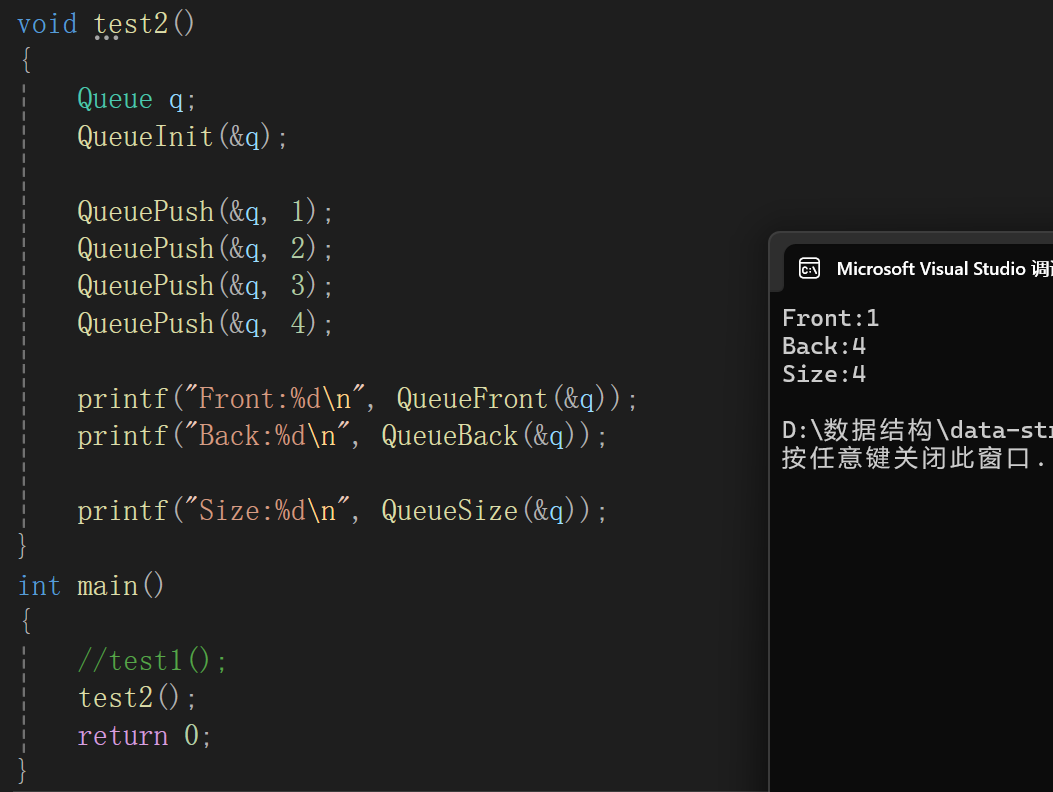
print(true_b,true_w)
print(w,b)运行效果如下:

这里推算出b逼近为4.2,w1和w2逼近为2,-3.4,和生成数据集时设置的结果吻合!


![Java 处理地理信息数据[DEM TIF文件数据获取高程]](https://i-blog.csdnimg.cn/direct/a387e788481b49a0a3d1f13918e08f8d.png)