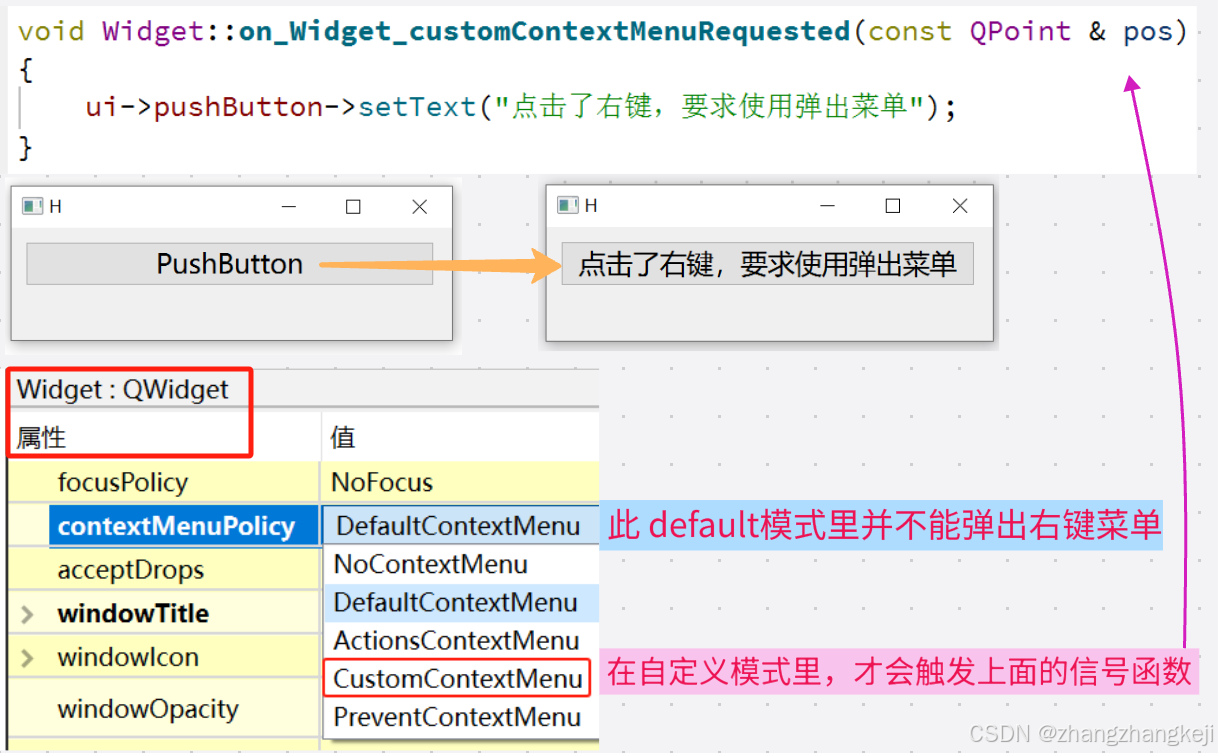
TCP 长连接和短连接有什么区别?
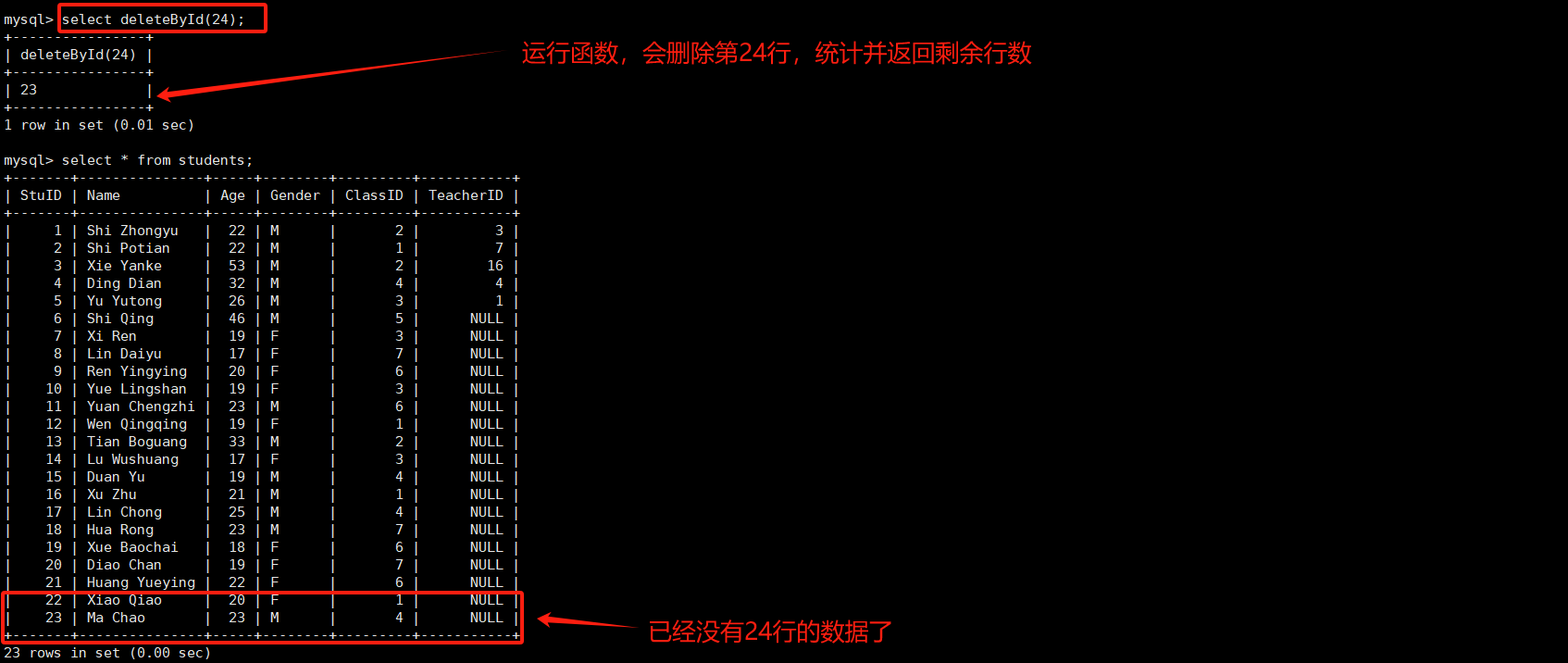
TCP 短连接是指客户端与服务端连接后只进行一次读写就关闭连接,一般是客户端关闭。
而长连接则是指在进行完一次读写后不关闭连接,直到服务端压力过大则选择关闭一些长时间为进行读写的连接。
- TCP 短连接的优点在于管理简单,而且不会对服务端造成太大的压力,而缺点是每次读写都需要连接耗时较长。
- TCP 长连接的优点是可以迅速进行多次读写,缺点是对服务端压力大,且容易被恶意连接影响服务。
长短连接的区别就在于客户端和服务端选择的关闭策略不同,具体需要根据应用场景来选择合适的策略。
TCP 通过哪些方式来保证数据的可靠性?
TCP 保证数据可靠性的方式大致可以分为三类:
- 在数据包层面:校验和
- 在数据包传输层面:序列号、确认应答、超时重传
- 在流量控制层面:拥塞控制
校验和
计算方式:在数据传输的过程中,将发送的数据段都当做一个 16 位的整数。将这些整数加起来。并且加上进位,最后取反,得到校验和。
TCP 与 UDP 校验方式相同
序列号、确认应答、超时重传
在数据包传输的过程中,每个数据包都有一个序列号,当数据到达接收方时,接收方会发出一个确认应答,表示收到该数据包,并会说明下一次需要接收到的数据包序列号(32 位确认序列号)。如果发送端在一段时间内(2RTT 没有收到确认应答,则说明可能是发送的数据包丢失或者确认应答包丢失,此时发送端会进行数据包重传。
但发送端并不是一定要等到接收到上一个数据包的确认应答再发送下一个数据包,TCP 会利用窗口控制来提高传输速度,在一个发送窗口大小内,不用一定要等到应答才能发送下一段数据,发送窗口大小就是无需等待确认而可以继续发送数据的最大值。而发送窗口的大小是由接收端的接受窗口的剩余大小和拥塞窗口来决定的。(TCP 会话的双方都各自维护一个发送窗口和一个接收窗口)
拥塞控制
发送端维持一个叫做拥塞窗口 cwnd(congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送端让自己的发送窗口等于拥塞窗口,另外考虑到接受方的接收能力,发送窗口可能小于拥塞窗口。
TCP 的拥塞控制主要是采用慢启动以及增性加,乘性减的机制,TCP一开始将拥塞窗口设置的很小,在逐渐经过一段时间的指数增长后超过门限,进入增性加阶段,此时窗口大小的增长是线性的,比之前的指数增长要慢很多,而当发生网络拥塞时,拥塞窗口大小直接减半(乘性减)。
Redis 怎么统计在线用户
统计在线人数的方法有很多,像redis中比较常见的,HyperLogLog基数统计,位图,集合,有序集合都可以实现统计在线人数的方法
使用集合或者有序集合都可以存储具体的在线用户名单,但是会消耗大量的内存。 而使用 HyperLogLog 虽然能够有效地减少统计在线用户所需的内存 ,但是它的准确性比较低,也就是说它没有办法准确的记录在线用户名单。
Redis的位图就是一个由二进制位组成的数组, 通过将数组中的每个二进制位与用户 ID 进行一一对应, 我们可以使用位图去记录每个用户是否在线。
当一个用户上线时, 我们就使用 SETBIT 命令, 将这个用户对应的二进制位设置为 1
通过使用 GETBIT 命令去检查一个二进制位的值是否为 1 , 我们可以知道指定的用户是否在线
通过 BITCOUNT 命令, 我们可以统计出位图中有多少个二进制位被设置成了 1 , 也即是有多少个用户在线
用户也能够对多个位图进行聚合计算 —— 通过 BITOP 命令, 用户可以对一个或多个位图执行逻辑并、逻辑或、逻辑异或或者逻辑非操作
简单说明一下 DNS 负载均衡的优点
DNS 负载均衡最大的优点就是配置简单。服务器集群的调度工作完全由 DNS 服务器承担,那么就可以把精力放在后端服务器上,保证他们的稳定性与吞吐量。而且完全不用担心DNS服务器的性能,即便是使用了轮询策略,它的吞吐率依然卓越。
DNS 负载均衡具有较强了扩展性,完全可以为一个域名解析较多的 IP ,而且不用担心性能问题。
写出进程间通信主要有哪些方法
进程之间的通信方式主要有六种,包括:
- 管道
- 信号量
- 消息队列
- 信号
- 共享内存
- 套接字
对 MySQL 架构的了解?
MySQL的体系结构可以分为两层,MySQL Server层和存储引擎层。
在MySQL Server层中又包括连接层和SQL层。
- 应用程序通过接口( 如ODBC、JDBC)来连接MySQL。
- 最先连接处理的是连接层,连接层包括通信协议、线程处理、用户名密码认证三个部分。
- 通信协议负责检测客户端版本是否兼容MySQL服务端。
线程处理是指每一个连接请求都会分配一个对应的线程,
- 相当于一条SQL对应一个线程,一个线程对应一个逻辑 CPU,并会在多个逻辑CPU之间进行切换。
- 用户名密码认证验证创建的账号和密码,以及host主机授权是否可以连接到MySQL服务器。
- SQL层包含权限判断、查询缓存、解析器、预处理、查询优化器、缓存和执行计划。
- 权限判断可以审核用户有没有访问某个库、某个表,或者表里某行的权限。
- 查询缓存通过 Query Cache 进行操作,如果数据在 Query Cache 中,则直接返回结果给客户端。
查询解析器针对 SQL 语句进行解析,判断语法是否正确。预处理器对解析器无法解析的语义进行处理。
- 优化器对 SQL 进行改写和相应的优化,并生成最优的执行计划,就可以调用程序的 API 接口,通过存储引擎层访问数据。
- 存储引擎层也是 MySQL 数据库区别于其他数据库最核心的一点
一条 SQL 语句在数据库框架中的执行流程?
- 如果是查询语句,首先查询缓存,查询直接命中返回,否则进入下一步 (MySQL得到查询请求,将首先查询缓存,看看该语句之前是否执行过。) 以前执行的语句及其结果作为键-值对直接缓存在内存中。Key为查询语句,value为查询结果。如果查询可以直接在缓存中找到键,则值将直接返回给客户端。
- 分析器对SQL 语句做解析。分析器先会做“词法分析”(比如"select"这个关键字识别出来)、“语法分析”(语法分析根据语法规则,判断输入的这个 SQL语句是否满足 MySQL 的语法规范)
- 优化器的处理。优化器是在表里有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。(逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案)
- 执行器阶段,开始执行语句。打开表,根据表的引擎定义,去使用这个引擎提供的接口,存取数据。
- 返回
数据库的三范式是什么?
- 第一范式:要求有主键,并且要求每一个字段原子性不可再分
- 第二范式:要求所有非主键字段完全依赖主键,不能产生部分依赖
- 第三范式:所有非主键字段和主键字段之间不能产生传递依赖
char 和 varchar 的区别?
char的长度是不可变的,而varchar的长度是可变的。
- char因为其长度固定,方便程序的存储与查找。
- -char的存储方式是:对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节。varchar的存储方式是:对每个英文字符占用2个字节,汉字也占用2个字节。
- 两者的存储数据都非unicode的字符数据。
nchar和nvarchar是存储的unicode字符串数据