知识点回归:
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
作业
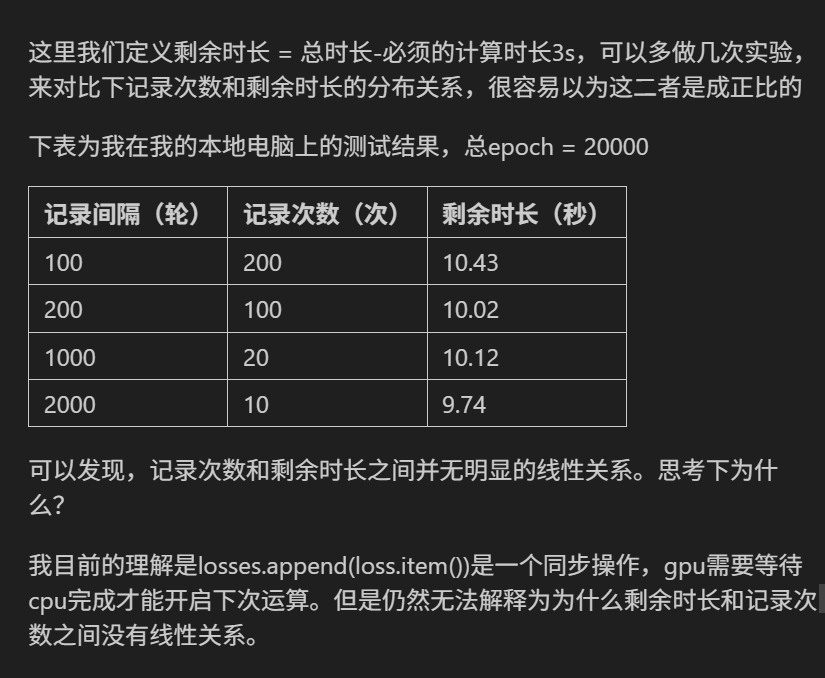
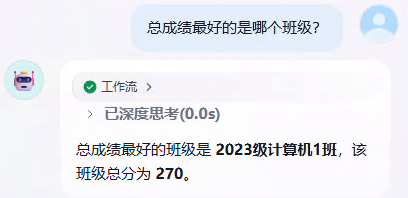
- 计算资源分配与调度:虽然
losses.append(loss.item())是同步操作,但 GPU 和 CPU 之间的资源分配与调度并非简单线性。每次记录操作时,系统可能会根据当前整体负载、其他进程占用资源情况等动态调整资源分配。比如,即使记录次数减少,如果此时系统中其他任务占用了 CPU 或 GPU 资源,也会影响计算时长,导致剩余时长不按记录次数成比例变化。 - 硬件特性与缓存机制:硬件层面的缓存机制会影响计算速度。当记录间隔不同时,数据在缓存中的命中情况会变化。记录间隔小,数据频繁访问,可能存在缓存未及时更新或频繁失效的情况;记录间隔大,数据访问间隔长,缓存可能在较长时间内保持有效。这些都会对实际计算时间产生影响,破坏记录次数和剩余时长的线性关系。
- 计算任务的复杂性与动态性:深度学习训练中的计算任务并非完全均一。不同的记录间隔下,每次计算涉及的数据量、计算图的构建与执行等可能存在差异。比如,间隔小的时候,每次计算的数据可能存在更多中间依赖,计算图更复杂,即使记录次数多,也不一定能简单按比例反映在剩余时长上。
@浙大疏锦行