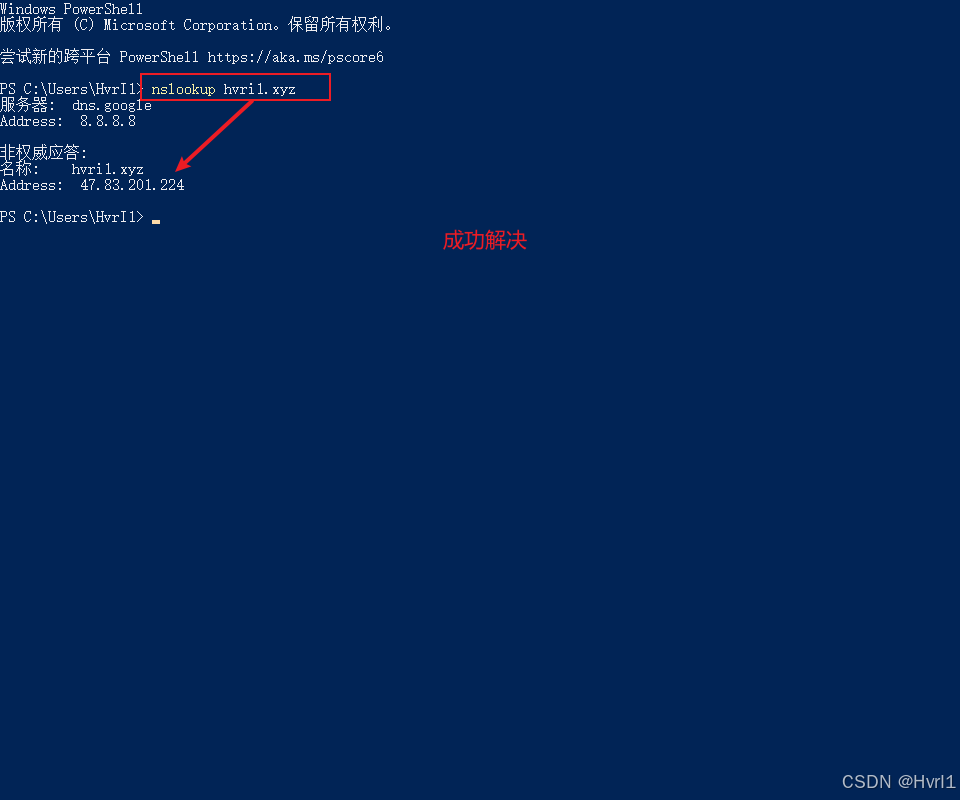
一、深度学习模型框架
在当今数字化时代,基于深度学习的电力负荷预测研究正成为保障电力系统稳定、高效运行的关键领域。其模型构建是一个复杂而精妙的过程,涉及多学科知识与前沿技术的融合应用。首先,要明确电力负荷预测的目标,即准确预估未来特定时间段内的电力需求,这关系到电力资源的合理分配与调度。数据收集是模型构建的基石,涵盖历史负荷数据、气象数据、节假日信息、经济指标等诸多变量。历史负荷数据能反映电力需求的周期性、趋势性变化规律;气象数据如温度、湿度、风速等,与人类生活用电行为紧密相关,温度的细微变化可能引发空调等大功率电器使用频率的波动,进而影响负荷;节假日信息可区分工作日与休息日不同的用电模式;经济指标则关联工商业活动强度与居民生活水平,影响整体电力消耗。
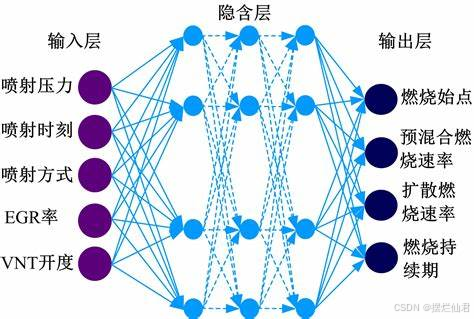
在数据预处理阶段,需对收集到的原始数据进行清洗,去除噪声、异常值与缺失值,确保数据质量。例如,对于缺失的负荷数据,可采用插值法或基于时间序列的预测算法进行填补;异常值可通过统计分析方法或聚类分析识别并修正,以避免其对模型训练过程的干扰,使模型能基于准确、可靠的数据进行学习。
深度学习模型的选择至关重要,常见的有循环神经网络(RNN)及其变体长短期记忆网络(LSTM)、门控循环单元(GRU)。RNN 能处理序列数据,但存在梯度消失问题,难以捕捉长周期的依赖关系。LSTM 通过引入遗忘门、输入门与输出门结构,有效缓解了梯度消失,能记忆长时间序列中的关键信息,对电力负荷这类具有明显时间先后关联的数据有良好适应性;GRU 在 LSTM 基础上进行简化,将遗忘门与输入门整合为更新门,减少参数数量,提高训练效率,在处理部分电力负荷数据时可取得与 LSTM 相当甚至更优的效果。
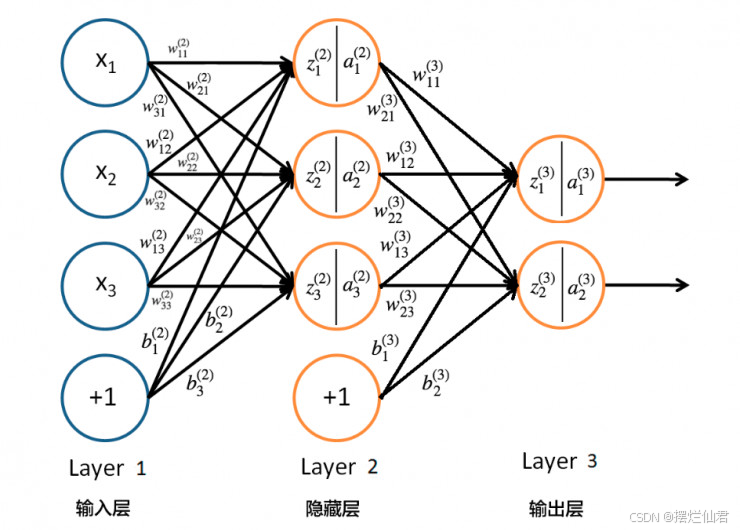
以 LSTM 为例,其模型构建细节如下。输入层接收预处理后的多维数据,包括历史负荷值、对应时刻的气象参数等,数据维度需根据实际数据特征与模型输入要求合理设置。隐藏层由多个 LSTM 单元构成,这些单元相互连接,形成时间序列处理链路。每个 LSTM 单元内部,遗忘门决定了先前时刻记忆信息中有多少被保留或舍弃;输入门控制当前输入数据进入单元状态的程度;输出门则依据单元状态输出有价值的信息用于后续预测。隐藏层的层数与每层神经元数量需通过反复试验确定,过多可能导致过拟合,过少则预测精度不足。输出层通常采用线性激活函数,输出未来特定时间点或时间段的电力负荷预测值。
在模型训练过程中,定义合适的损失函数是关键。对于电力负荷预测这类回归问题,均方误差(MSE)、平均绝对误差(MAE)是常用损失函数,它们衡量预测值与真实值之间的偏差大小,模型训练旨在最小化该误差。采用优化算法如随机梯度下降(SGD)、Adam 等调整模型参数,根据损失函数梯度更新 LSTM 单元的权重与偏置,不断优化模型预测能力。训练过程中需划分训练集、验证集与测试集,利用训练集对模型进行初步训练,通过验证集监控模型在未见数据上的表现,防止过拟合,当验证集误差不再显著下降时停止训练,最后在测试集上评估模型最终性能,确保其在实际应用中具备良好的泛化能力。
二、网络模型优化
在深度学习模型构建过程中,以下三种优化技术被广泛用于提高模型的性能和泛化能力:(1)超参数调优:超参数的选择对模型性能影响巨大,包括学习率、隐藏层数量、神经元数量等。利用网格搜索或随机搜索等方法,通过在验证集上评估不同超参数组合的表现,选择最优的超参数组合。(2)正则化:防止模型过拟合,主要通过L1和L2正则化实现。L2正则化在损失函数中加入权重的平方和,而L1正则化加入权重的绝对值之和,限制模型复杂度,提高泛化能力。(3)数据增强:通过生成新的训练样本来扩充数据集,如对历史负荷数据进行平移、添加噪声扰动,增强模型对数据变化的适应能力,提高泛化性能。
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras import regularizers
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from tensorflow.keras.callbacks import EarlyStopping
# 读取数据
data = pd.read_csv('electric_load_data.csv')
features = data[['temperature', 'humidity', 'historical_load', 'holiday_flag']]
labels = data['target_load']
# 数据预处理
scaler_features = MinMaxScaler()
scaler_labels = MinMaxScaler()
features_scaled = scaler_features.fit_transform(features)
labels_scaled = scaler_labels.fit_transform(labels.values.reshape(-1, 1))
# 数据增强
def data_augmentation(features, labels):
augmented_features = []
augmented_labels = []
for feature, label in zip(features, labels):
# 添加噪声扰动
noise = np.random.normal(0, 0.01, feature.shape)
augmented_features.append(feature + noise)
augmented_labels.append(label)
return np.array(augmented_features), np.array(augmented_labels)
augmented_features, augmented_labels = data_augmentation(features_scaled, labels_scaled)
# 数据集划分
X_train, X_val, y_train, y_val = train_test_split(augmented_features, augmented_labels, test_size=0.2, random_state=42)
# 构建LSTM模型
def build_lstm_model(input_shape):
model = Sequential()
model.add(LSTM(64, input_shape=input_shape, return_sequences=True, kernel_regularizer=regularizers.l2(0.01)))
model.add(Dropout(0.2))
model.add(LSTM(32, kernel_regularizer=regularizers.l1(0.01)))
model.add(Dropout(0.2))
model.add(Dense(1, activation='linear'))
model.compile(optimizer='adam', loss='mse')
return model
model = build_lstm_model((X_train.shape[1], X_train.shape[2]))
# 学习率调度器
def learning_rate_scheduler(epoch, lr):
if epoch < 10:
return lr
else:
return lr * 0.95
callbacks = [
EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True),
tf.keras.callbacks.LearningRateScheduler(learning_rate_scheduler)
]
# 模型训练
history = model.fit(X_train, y_train, epochs=50, batch_size=32,
validation_data=(X_val, y_val), callbacks=callbacks)
# 模型评估
loss = model.evaluate(X_val, y_val)
print(f"Validation Loss: {loss}")
# 预测结果反归一化
predicted = model.predict(X_val)
predicted_load = scaler_labels.inverse_transform(predicted)
true_load = scaler_labels.inverse_transform(y_val)
# 计算预测误差
mse = mean_squared_error(true_load, predicted_load)
print(f"Mean Squared Error: {mse}")三、测试结果分析
在电力负荷预测中,准确评估模型的预测性能至关重要。我们主要关注以下几个方面:(1)预测误差分析:计算预测值与真实值之间的误差,包括平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)等指标,以定量评估模型的预测精度。(2)结果可视化:通过绘制预测值与真实值的对比图,直观展示模型的预测效果,并分析预测曲线与实际曲线的吻合程度。(3)模型性能评估:综合考虑模型在不同时间段的表现,评估其在处理不同负荷模式时的适应性和稳定性,其定性分析的结果如下图所示。
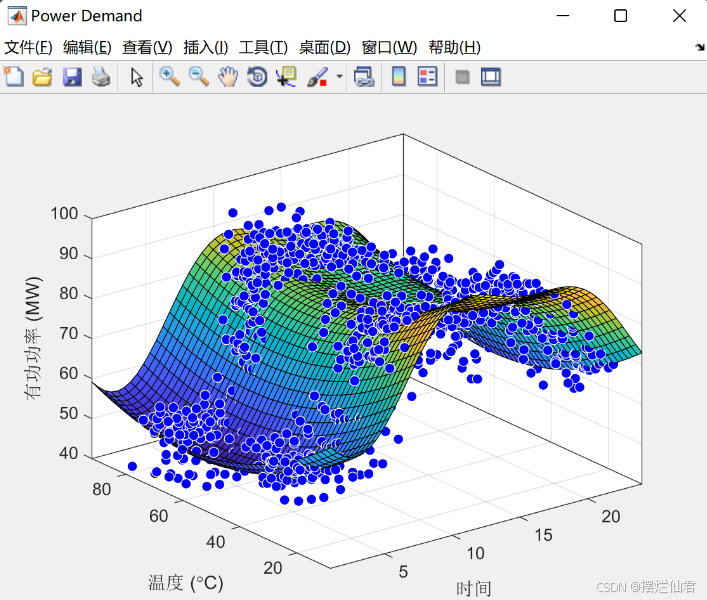
通过对模型预测结果的详细分析,我们可以全面评估模型的性能和可靠性。低预测误差和高R²值表明模型能够较好地捕捉电力负荷的变化趋势,为电力系统调度和资源分配提供有力支持。可视化结果进一步验证了模型的预测效果,使其在实际应用中具有较高的参考价值。