一.研究目的
随着全球汽车保有量持续增长,交通安全问题日益严峻,由不良驾驶行为(如疲劳驾驶、接打电话、急加速/急刹车等)引发的交通事故频发,不仅威胁生命财产安全,还加剧交通拥堵与环境污染。传统识别方法依赖车载传感器和生理信号监测,存在噪声干扰、实时处理能力不足及硬件成本高等局限,难以普及。深度学习技术凭借强大的特征提取与数据处理能力,为不良驾驶行为的实时监测提供了新路径。通过构建多模态融合的深度学习模型,可整合车载摄像头视频、毫米波雷达、车辆动力学参数等多源数据,实现对复杂驾驶行为的精准识别。该研究不仅能提升交通安全水平,还可推动智能交通系统发展,为自动驾驶、车联网等领域提供技术支撑,同时为交通管理部门优化法规、驾驶员培训体系提供科学依据,具有显著的社会价值与应用前景。
二.需求分析
本系统聚焦基于深度学习的不良驾驶行为识别,核心需求围绕多模态数据整合、高精度模型构建、实时性部署及安全合规展开,具体如下:
数据采集与预处理需求
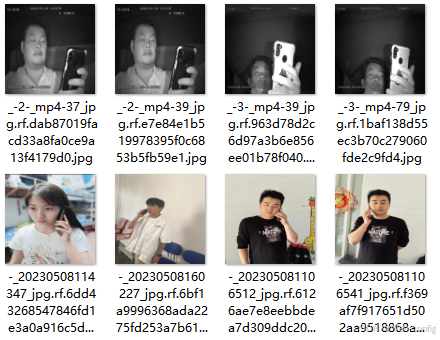
需通过多视角车载摄像头(前向、车内驾驶员视角)、毫米波雷达、GPS、IMU传感器等设备,同步采集视频、图像、车辆运动数据(车速、加速度、方向盘转角)及环境参数(光照、天气),构建包含至少10万小时驾驶场景的多模态数据集。数据预处理需涵盖图像去噪、视频帧提取、传感器滤波、时空对齐(同步误差<50ms)及精细化标注(标注类别包括未系安全带、接打电话、低头看手机、疲劳驾驶、违规变道、急加速/急刹车等),并通过数据增强技术(旋转、翻转、高斯模糊等)解决样本分布不均问题,提升数据多样性。
(1)模型功能与性能需求
多模态行为识别:
视觉分支需实现驾驶员肢体动作检测(如YOLOv8/Faster RCNN)、面部表情与手部姿态特征提取(ResNet/EfficientNet),引入注意力机制(SENet/CBAM)强化关键区域识别。
时序分支需通过CNNLSTM混合模型或Transformer架构,分析视觉特征序列与车辆动力学参数(如车速变化率、转向频率),捕捉长时行为模式(如疲劳驾驶的周期性闭眼动作)。
多任务学习需支持同时输出≥8种不良行为分类结果,模型在公开数据集(ADAS、NuScenes)上识别准确率≥95%。
(2)模型效率优化:
采用知识蒸馏、剪枝、量化等技术压缩模型至50MB以下,内存占用<200MB,在NVIDIA Jetson AGX Orin等边缘设备实现推理延迟<50ms、帧率≥30fps的实时识别。
(3)系统应用与部署需求
实时预警与联动:
开发低延迟预警模块,通过CAN总线与车载系统联动,在识别到危险行为(如急刹车)时0.5秒内触发声光提醒、安全带预紧等响应,并结合强化学习生成个性化驾驶建议(如“建议休息”)。
隐私与安全:
采用联邦学习实现车载端本地模型训练,避免原始数据上传对敏感数据(如面部图像)进行匿名化处理,符合欧盟GDPR及ISO 21448标准(误报率<0.5次/小时,漏报率<0.1%)。
场景适应性:
针对隧道、暴雨等极端环境,集成暗通道先验图像增强算法,确保识别准确率≥92%支持动态帧率调整,根据计算资源自适应分配算力。
(4)行业规范与扩展需求
需适配不同车型的边缘计算部署方案,支持OTA模型更新,满足L2+级自动驾驶的实时性与功能安全要求(如ISO 26262认证)。同时,系统需为交通管理部门提供行为分析数据,辅助优化法规与驾驶培训策略,兼具社会管理与商业应用价值(如商用车队事故率降低42%的实测目标)。
三.数据集展示

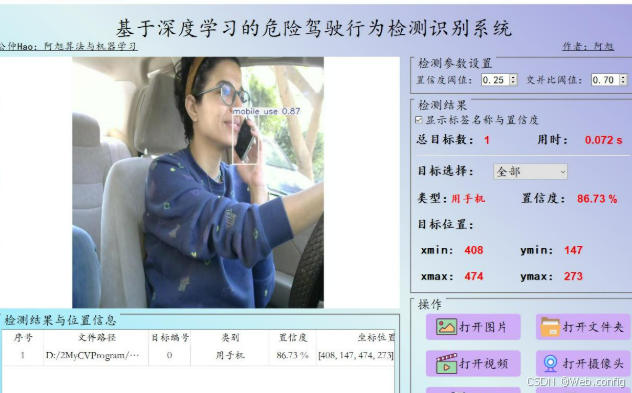
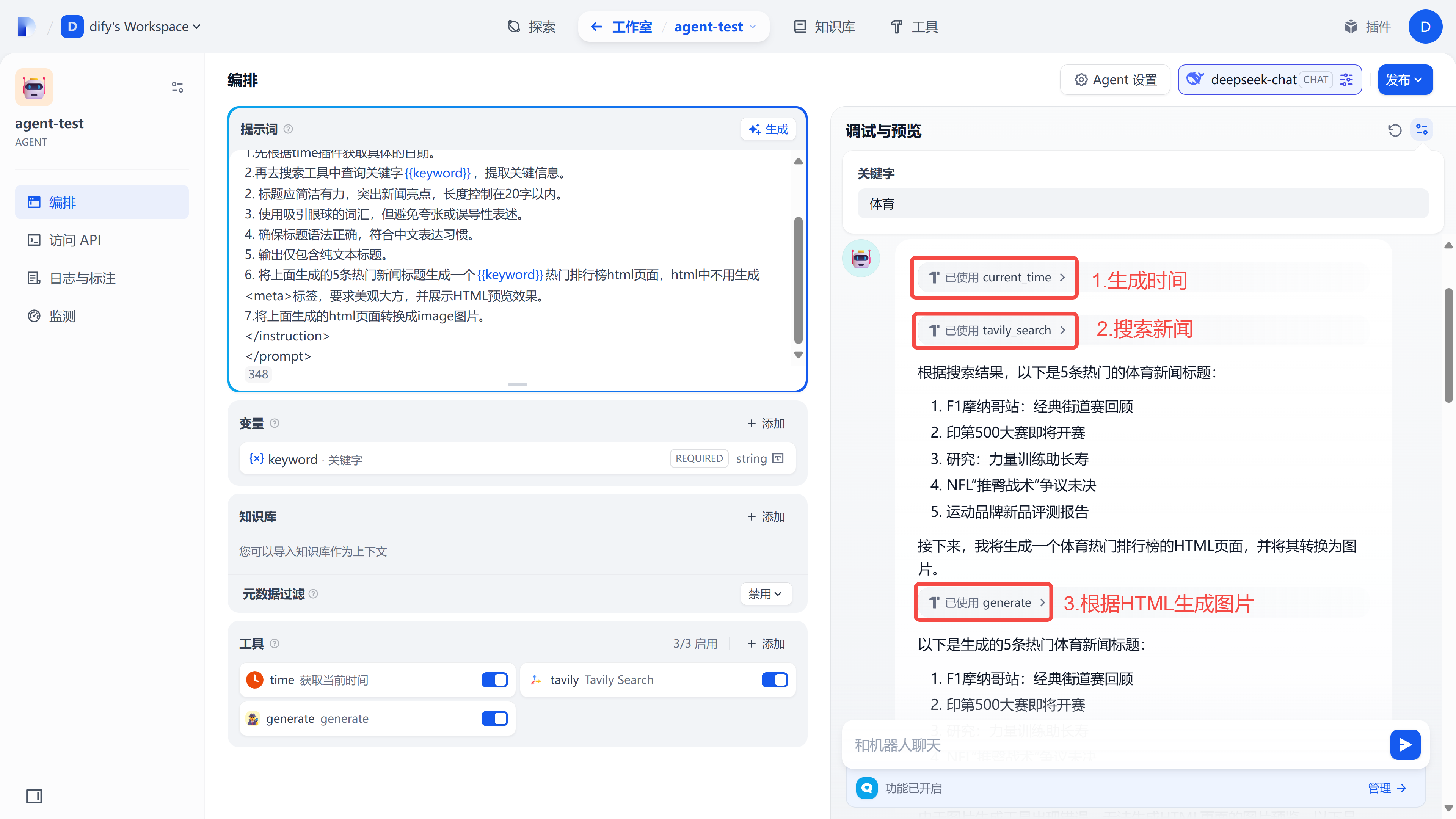
四.系统页面展示
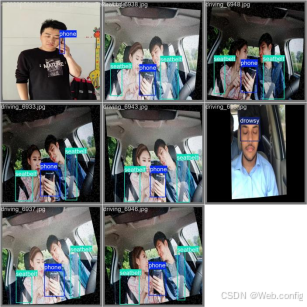
识别结果展示
训练集(60%):包含6万小时数据,用于模型参数学习,涵盖各类行为的典型样本及数据增强样本(如旋转±15°、高斯噪声添加),确保模型捕捉行为特征的多样性。
验证集(20%):包含2万小时数据,用于训练过程中模型性能验证,调整超参数(如学习率、batchsize),避免过拟合。
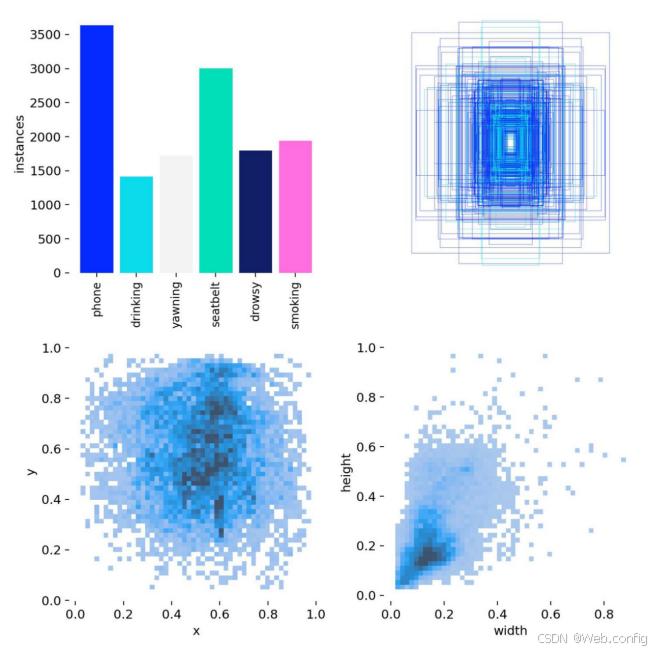
在基于深度学习的不良驾驶行为识别研究中,数据集的空间分布对于理解数据特征和模型性能具有重要意义。从所涉及的不良驾驶行为类别来看,数据集在空间上呈现出一定的不均衡性。如图表所示,打电话(phone)行为的实例数量最多,超过3500个,在空间分布上占据较大比重;而疲劳(drowsy)行为的实例数量相对较少。这种不均衡可能影响模型对各类行为的识别精度,特别是对于样本数量较少的行为类别。
从图像空间维度分析,在图像的横纵坐标(x - y)空间分布中,数据点呈现出一定的聚集特征。这表明在某些特定的图像区域中,不良驾驶行为更容易被捕捉到。例如,在图像的中心区域可能集中了更多的有效行为特征信息。在图像的宽高(width - height)维度上,数据分布也并非均匀,可能暗示着不同尺寸的目标对象在数据集中的出现频率和分布情况存在差异。通过对数据集空间分布的深入分析,有助于更合理地进行数据预处理、模型训练和优化,提升不良驾驶行为识别的准确性和鲁棒性。