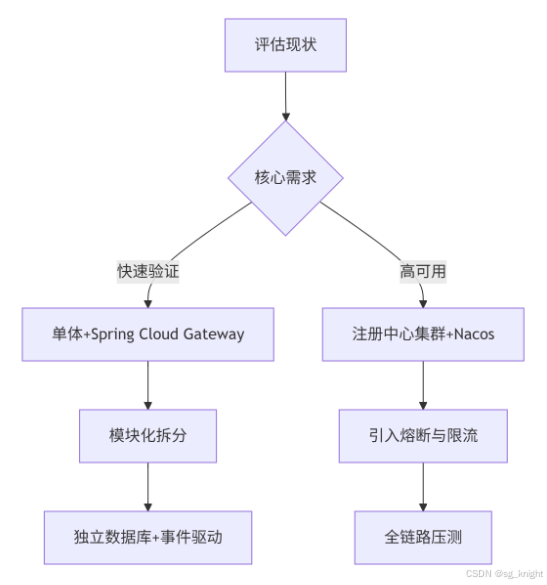
1,项目概述
VITS是一种语音合成的方法,是一个完全端到端的TTS 模型,它使用预先训练好的语音编码器将文本转化为语音,并且是直接从文本到语音波形的转换,无需额外的中间步骤或特征提取。
VITS的工作流程为:首先,系统接收输入的文本,然后通过一系列复杂的算法将其转换为发音规则。然后,这些规则被送入一个预先训练好的语音编码器,该编码器负责生成语音信号的特征表示。最后,这些特征会被输入到语音合成模型中,模型根据这个生成最终的语音。
它的优点在于能够生成与真实人声相媲美的高质量语音,但是缺点就是训练需要大量的训练语料来训练语音合成模型,同时也需要较复杂的训练流程。
所以, VITS-fast-fine-tuning 就是在 VITS 的基础上开发的一站式多角色模型微调工具,它通过微调预训练的 VITS 模型,使用户在不到 1 小时的时间内完成对预训练模型的微调,然后生成好的训练模型,就可以用指定的音色进行语音合成和声音克隆了。
【项目地址】https://github.com/Plachtaa/VITS-fast-fine-tuning
【数据格式】https://github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/DATA_EN.MD
2,本地部署
确保您已经安装了Python==3.8、CMake 和 C/C++ 编译器、ffmpeg;
pip install -r requirements.txt; # 安装处理视频数据所需的库 pip install imageio==2.4.1 pip install moviepyBuild monotonic align (necessary for training)
cd monotonic_align mkdir monotonic_align python setup.py build_ext --inplace cd ..下载训练辅助数据:
mkdir pretrained_models # download data for fine-tuning wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip unzip sampled_audio4ft_v2.zip # create necessary directories mkdir video_data mkdir raw_audio mkdir denoised_audio mkdir custom_character_voice mkdir segmented_character_voice下载任意一个预训练模型,可用选项有:
CJE: Trilingual (Chinese, Japanese, English) wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json -O ./configs/finetune_speaker.json CJ: Dualigual (Chinese, Japanese) wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/D_0-p.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/G_0-p.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/config.json -O ./configs/finetune_speaker.json C: Chinese only wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/D_0.pth -O ./pretrained_models/D_0.pth wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/G_0.pth -O ./pretrained_models/G_0.pth wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/config.json -O ./configs/finetune_speaker.json自定义数据放在 custom_character_voice:
custom_character_voice - XiJun -XiJun_1.wav -XiJun_2.wav
3,本地训练
【语音识别】借助 whisper-lager 语音识别,有哪些数据执行哪个!!!:
python scripts/video2audio.py python scripts/denoise_audio.py python scripts/long_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large python scripts/short_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large # 有辅助训练数据执行,记得修改目录 python scripts/resample.py【报错】Given groups=1, weight of size [1280, 128, 3], expected input[1, 80, 3000]
【解决】short_audio_transcribe line 24
mel = whisper.log_mel_spectrogram(audio).to(model.device) 👇 mel = whisper.log_mel_spectrogram(audio, n_mels=128).to(model.device)【数据整理】python preprocess_v2.py --add_auxiliary_data True --languages "{PRETRAINED_MODEL}"
【正式训练】python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs "{Maximum_epochs}" --drop_speaker_embed True
- epoch 建议100以上
- 关闭一些日志会很好
import warnings warnings.simplefilter(action='ignore', category=FutureWarning) logging.getLogger('numba').setLevel(logging.WARNING) warnings.filterwarnings( "ignore", message="stft with return_complex=False is deprecated" )【报错】Could not find module libtorio_ffmpeg6.pyd' (or one of its dependencies).
【解决】finetune_speaker_v2.py 最开始添加:
from torchaudio._extension.utils import _init_dll_path _init_dll_path()【报错】RuntimeError: use_libuv was requested but PyTorch was build without libuv support
【解决】finetune_speaker_v2 main() 添加:
os.environ['USE_LIBUV'] = '0'【报错】size mismatch for enc_p.emb.weight: copying a param with shape torch.Size([50, 192]) from checkpoint, the shape in current model is torch.Size([78, 192]).
【解决1】可能下载的预训练模型与配置文件搞串了,可能的多次下载导致。
【解决2】修改 untils.py 下的配置:
parser.add_argument('-c', '--config', type=str, default="./configs/modified_finetune_speaker.json", help='JSON file for configuration') 👇 parser.add_argument('-c', '--config', type=str, default="D:\\PyCharmWorkSpace\\TTS\\VITS-fast-fine-tuning\\configs\\finetune_speaker.json", help='JSON file for configuration')【报错】mel() takes 0 positional arguments but 5 were given
【解决】pip install librosa==0.8.0
4,推理效果
VITS:4张 V100 显卡训练一周,连话都说不清楚。
VITS-fast-fine:1张 4070 训练20分钟(200 epoch),效果还不错。
【注意】使用微调后的 config.json,主要在 VC_inference.py 中配置。
python VC_inference.py【报错】__init__() got an unexpected keyword argument 'source'
【解决】修改 VC_inference.py
record_audio = gr.Audio(label="record your voice", source="microphone") upload_audio = gr.Audio(label="or upload audio here", source="upload") 👇 record_audio = gr.Audio(label="record your voice") upload_audio = gr.Audio(label="or upload audio here")