结论
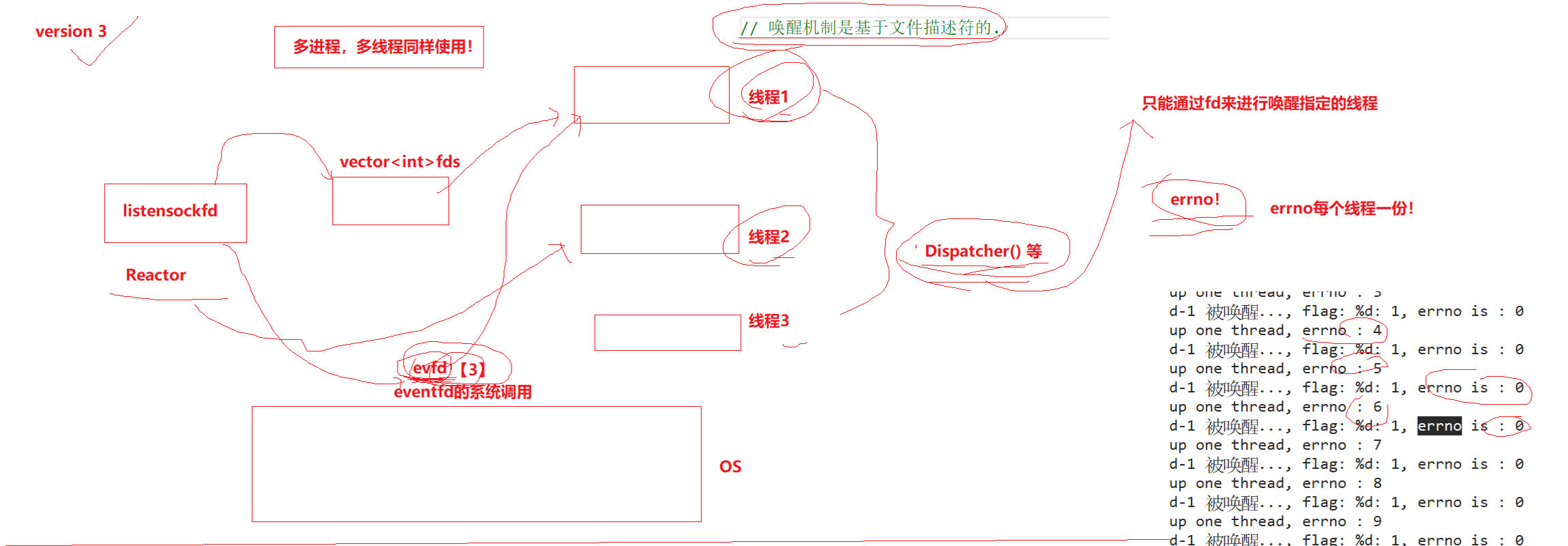
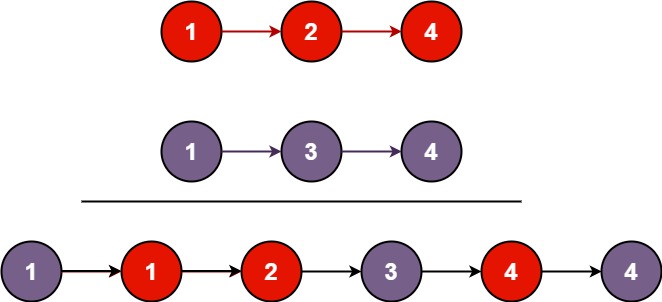
1:EXIST可以用于链表,且可以利用到索引
2:当join无法合理利用到索引,可以尝试EXIST链表
3:EXIST在某些情况下可以更好地利用到索引
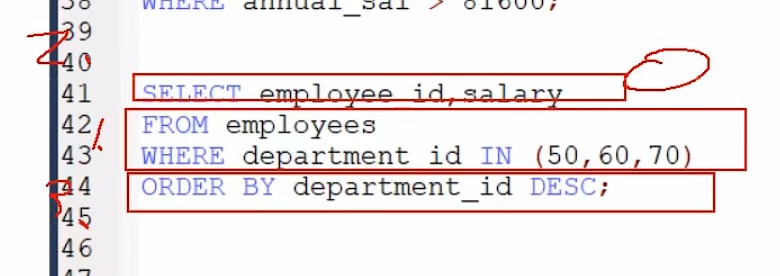
4:大数据量时,要考虑EXIST的使用EXIST SQL:

EXPLAN

JOIN SQL:

EXPLAN

GPT解释的原因
EXISTS 子查询
在第一个查询中使用了EXISTS子查询,这种结构通常被优化为半连接(semi-join),其目的是检查子查询的结果是否存在,而不是真正地进行两表之间的完整连接。当MySQL优化器处理带有EXISTS的查询时,它可能会选择一种更高效的路径来查找匹配的数据行,特别是在外部查询和子查询之间存在合适的索引时。在这个例子中,由于gm.mark_type上有索引,MySQL可以高效地检查goods_mark_type_common表中的mark_type值是否满足条件,并且快速确定是否存在匹配项,从而能够有效地利用索引。
JOIN 操作
第二个查询使用了JOIN操作结合DISTINCT来消除重复的记录。尽管g.mark_type = gm.mark_type条件理论上允许MySQL利用gm.mark_type上的索引来加速连接过程,但实际能否有效利用索引还受到多个因素的影响,比如数据分布、连接类型的选择、以及MySQL版本等。此外,使用DISTINCT可能需要额外的操作来确保结果集的唯一性,这可能会导致MySQL无法仅依赖索引完成整个查询过程,特别是如果MySQL认为先执行连接再过滤和去重比直接利用索引更加高效的话。
然而,值得注意的是,现代版本的MySQL在优化JOIN查询方面已经做了很多改进,使得在许多情况下也能很好地利用索引。如果你发现你的JOIN查询没有如预期那样利用索引,可能是由于特定的数据特性或查询条件导致的。可以通过查看具体的EXPLAIN输出了解MySQL是如何执行这些查询的,进而调整查询或者数据库配置以改善性能。