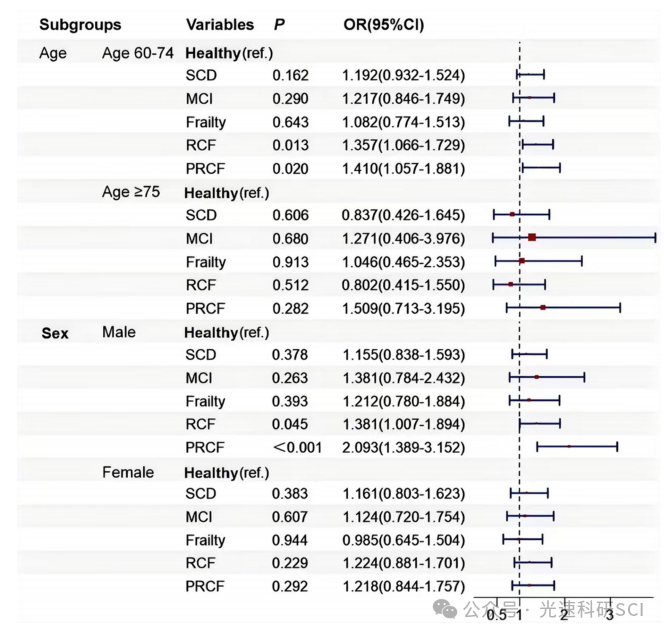
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
➡️ 论文标题:What is the Visual Cognition Gap between Humans and Multimodal LLMs?
➡️ 论文作者:Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg
➡️ 研究机构: University of Illinois Urbana-Champaign、Georgia Institute of Technology、University of Virginia、Purdue University、Shenzhen Children’s Hospital
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在语言引导的感知任务中,如识别、分割和目标检测,展现了巨大的潜力。然而,它们在解决需要高级推理的视觉认知问题上的有效性尚未得到充分验证。抽象视觉推理(Abstract Visual Reasoning, AVR)是其中的一个挑战,它涉及识别图像集中的模式关系并推断后续模式,这一技能在儿童早期神经发育阶段尤为重要。
➡️ 研究动机:尽管MLLMs在某些认知测试中表现出色,但它们在需要高级归纳推理的视觉问题上的表现仍然不足,尤其是在RAVEN IQ测试等任务中。为了评估MLLMs在AVR任务上的表现,并与人类智能进行比较,研究团队提出了一个新的数据集MaRs-VQA和一个新的基准VCog-Bench,旨在揭示MLLMs与人类智能之间的差距,并为未来的研究提供方向。
➡️ 方法简介:研究团队构建了一个新的AVR数据集MaRs-VQA,包含1,440个由心理学家设计的图像实例,这是目前最大的AVR评估数据集。此外,他们提出了VCog-Bench,这是一个综合的视觉认知基准,用于评估15个现有MLLMs在零样本设置下的AVR性能。研究团队还设计了链式思维(Chain-of-Thought, CoT)策略,以增强MLLMs在AVR任务中的零样本学习能力。
➡️ 实验设计:研究团队在三个数据集上进行了实验,包括RAVEN、CVR和MaRs-VQA。实验设计了不同的任务设置,如不同的选项数量和问题类型,以全面评估MLLMs在AVR任务中的表现。实验结果表明,即使是最强大的MLLMs在AVR任务上的表现也远不如人类,尤其是在处理复杂的抽象推理问题时。此外,研究还揭示了MLLMs在AVR任务和其他一般VQA问题之间的性能不匹配,为未来的模型改进提供了有价值的见解。
CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation
➡️ 论文标题:CoMM: A Coherent Interleaved Image-Text Dataset for Multimodal Understanding and Generation
➡️ 论文作者:Wei Chen, Lin Li, Yongqi Yang, Bin Wen, Fan Yang, Tingting Gao, Yu Wu, Long Chen
➡️ 研究机构: The Hong Kong University of Science and Technology (HKUST)、Wuhan University、Kuaishou Technology
➡️ 问题背景:交错图像-文本生成(Interleaved Image-Text Generation)是一项新兴的多模态任务,旨在根据查询生成交错的视觉和文本内容序列。尽管多模态大语言模型(MLLMs)在跨模态生成方面取得了显著进展,但在生成具有叙事连贯性和实体及风格一致性的交错图像-文本序列方面仍面临挑战。主要原因在于大多数模型是基于单个图像-文本对进行训练的,这限制了它们生成连贯和上下文集成的多模态内容的能力。
➡️ 研究动机:现有的多模态数据集在叙事连贯性、实体和风格一致性以及图像和文本之间的语义对齐方面存在不足。为了克服这些限制,研究团队构建了CoMM,一个高质量的连贯交错图像-文本多模态数据集,旨在提高生成内容的连贯性、一致性和对齐性。
➡️ 方法简介:CoMM数据集通过从特定网站(如WikiHow)收集高质量的交错图像-文本内容,初步确保数据集的连贯性和一致性。此外,研究团队设计了多视角过滤策略,包括文本序列过滤、图像序列过滤和图像-文本对齐过滤,利用先进的预训练模型(如CLIP和Llama3)来进一步提高数据集的质量。
➡️ 实验设计:研究团队设计了四个评估指标,分别评估生成的图像-文本序列的发展性、完整性、图像-文本对齐性和一致性。此外,通过在多个下游任务上进行少量样本实验,展示了CoMM在提高MLLMs上下文学习能力方面的有效性。研究还引入了四个新的任务,以全面评估MLLMs的多模态理解和生成能力,并提出了一个综合评估框架。
FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
➡️ 论文标题:FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
➡️ 论文作者:Zhikai Zhang, Yitang Li, Haofeng Huang, Mingxian Lin, Li Yi
➡️ 研究机构: Tsinghua University、Shanghai AI Laboratory、Shanghai Qi Zhi Institute
➡️ 问题背景:人类动作合成是计算机动画中的一个基本任务。尽管利用深度学习和动作捕捉数据在该领域取得了显著进展,但现有方法通常局限于特定的动作类别、环境和风格,缺乏对新环境和未见过的人类行为的泛化能力。此外,大规模高质量动作数据的收集难度和成本也是一个重要限制。
➡️ 研究动机:为了克服现有方法的局限性,研究团队首次探索了利用多模态大语言模型(MLLMs)在没有任何动作数据的情况下,通过自然语言指令控制的开放集人类动作合成。这一方法旨在利用MLLMs的广泛世界知识和推理能力,实现对新环境和任务的动态适应。
➡️ 方法简介:研究团队提出了一种名为FreeMotion的框架,该框架分为两个阶段:1)利用MLLMs作为关键帧设计者和动画师,生成一系列关键帧;2)通过插值和环境感知的动作跟踪,填补关键帧之间的空白。具体来说,第一阶段使用两个专门的GPT-4V代理,一个负责生成关键帧描述,另一个负责根据描述调整人体模型的姿势。第二阶段则通过插值和动作跟踪,将关键帧序列转换为流畅的动作片段。
➡️ 实验设计:研究团队在多种下游任务上评估了该方法,包括动作合成、风格迁移、人-场景交互和踏石任务。实验结果表明,该方法在没有动作数据的情况下,能够生成高质量的动作,展示了其在开放集动作合成中的潜力。
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
➡️ 论文标题:Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
➡️ 论文作者:Daiqing Qi, Handong Zhao, Zijun Wei, Sheng Li
➡️ 研究机构: University of Virginia、Adobe Research、Adobe Inc.
➡️ 问题背景:尽管多模态大语言模型(Multimodal Large Language Models, MLLMs)在视觉和语言指令的通用能力方面取得了显著进展,但在提供精确和详细的视觉指令响应时,仍面临关键问题,如无法识别新对象或实体、生成不存在的对象以及忽视对象的属性细节。
➡️ 研究动机:现有的解决方案,如增加数据量和使用更大的基础模型,虽然有效,但成本高昂。研究团队旨在通过引入检索增强的标签信息,改进多模态连接器的映射能力,从而提高模型对新对象和细节的识别能力。
➡️ 方法简介:研究团队提出了一种基于检索增强的标签信息(Tag-grounded visual instruction tUNing with retrieval Augmentation, TUNA)的方法,通过从大规模外部数据存储中检索相关标签,增强模型对新对象和细节的识别能力。TUNA通过图像感知的标签编码器和自适应权重调整器,将标签信息与输入图像结合,生成更准确的响应。
➡️ 实验设计:研究团队在12个基准数据集上进行了实验,包括视觉问答(VQA)和多模态基准测试。实验结果表明,TUNA在多个基准测试中显著优于现有的多模态大语言模型,特别是在识别新对象和实体方面表现出色。
Exploring the Potential of Multimodal LLM with Knowledge-Intensive Multimodal ASR
➡️ 论文标题:Exploring the Potential of Multimodal LLM with Knowledge-Intensive Multimodal ASR
➡️ 论文作者:Minghan Wang, Yuxia Wang, Thuy-Trang Vu, Ehsan Shareghi, Gholamreza Haffari
➡️ 研究机构: Monash University、MBZUAI
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在整合多种模态信息方面取得了显著进展,但在教育和科学领域的实际应用中仍面临挑战。特别是在知识密集型的多模态自动语音识别(ASR)任务中,如科学会议视频的转录,不仅需要准确转录口语内容,还需要理解和整合视觉信息。传统的评估指标如词错误率(WER)在评估技术术语的准确性方面存在不足,导致性能评估偏差。
➡️ 研究动机:为了应对这些挑战,研究团队提出了多模态科学ASR(MS-ASR)任务,专注于利用幻灯片中的视觉信息来提高技术术语的转录准确性。此外,研究团队还提出了一种新的评估指标——严重性感知WER(SWER),以更准确地反映ASR系统的性能。
➡️ 方法简介:研究团队提出了一种零样本推理框架——科学视觉增强ASR(SciVASR),该框架利用MLLMs来提取视觉信息并进行转录后编辑。通过在ACL 60/60数据集上进行实验,研究团队评估了不同模型在MS-ASR任务中的表现。
➡️ 实验设计:实验设计了四种设置:仅ASR、仅文本后编辑(Text-PE)、视觉增强后编辑(Vision-PE)和端到端视觉后编辑(E2E-Vision-PE)。评估指标包括WER、术语召回率(Term-Recall)和人类评估。实验结果表明,视觉信息的引入显著提高了转录质量,尤其是在术语召回率方面。GPT-4o在所有设置中表现最佳,特别是在视觉增强后编辑中,SWER相比仅ASR基线提高了45%。