继续研究一下大佬的RAG项目。开始我的碎碎念。
RAG可以分成两部分:一个是问答,一个是数据处理。
问答是人提问,然后查数据库,把查的东西用大模型组织成人话,回答人的提问。
数据处理是把当下知识库里的东西(不管是什么类型的数据),全弄成计算机话(代码能明白的格式)存到数据库,然后方便人提问的时候(也就是问答)给出可以回答的知识。
如果想让项目跑起来,必须把ES服务启动起来,该项目是用ES存的数据。
项目启动时,会先运行LoadStartup(在Springboot应用启动时),初始化向量存储(具体初始化向量存储用vectorstorage的initCollection()方法,指定名称和维度,向量维度是1024为了适配智谱AI)。总之就是自动初始化一个向量数据库的集合(Collection),用于存储后续的向量数据(如文本嵌入向量)。
我们看到LoadStartup类有一个注解@Component
所以@Service、@Repository等等这些注解,本质上都是@Component。只是根据层次有不同叫法。




这个collection是森马样子?回头再写吧。
首先,就是输入的问题。我们要存的知识不一定是什么类型,可能使txt,可能是word,甚至是pdf。那我们就需要把输入的东西先变成文本。
项目运行起来之前,点击运行下载好的es的bin文件夹下elasticsearch.bat,启动服务。
此时可以再终端看到可交互的shell命令行。这个应该是通过spring shell工具包实现的,项目的pom.xml文件里可以看到已经配置了shell的起步依赖。怎么用这个shell包呢?可以通过自己编写java类,自己做命令。前面说过把RAG分成两部分:问答,数据处理。使用add命令完成数据处理部分的工作,使用chat命令完成问答部分的工作。新建command文件夹来存放这两个类:add命令类,chat命令类。
通过 @ShellMethod 注解将 Java 方法暴露为 Shell 命令。
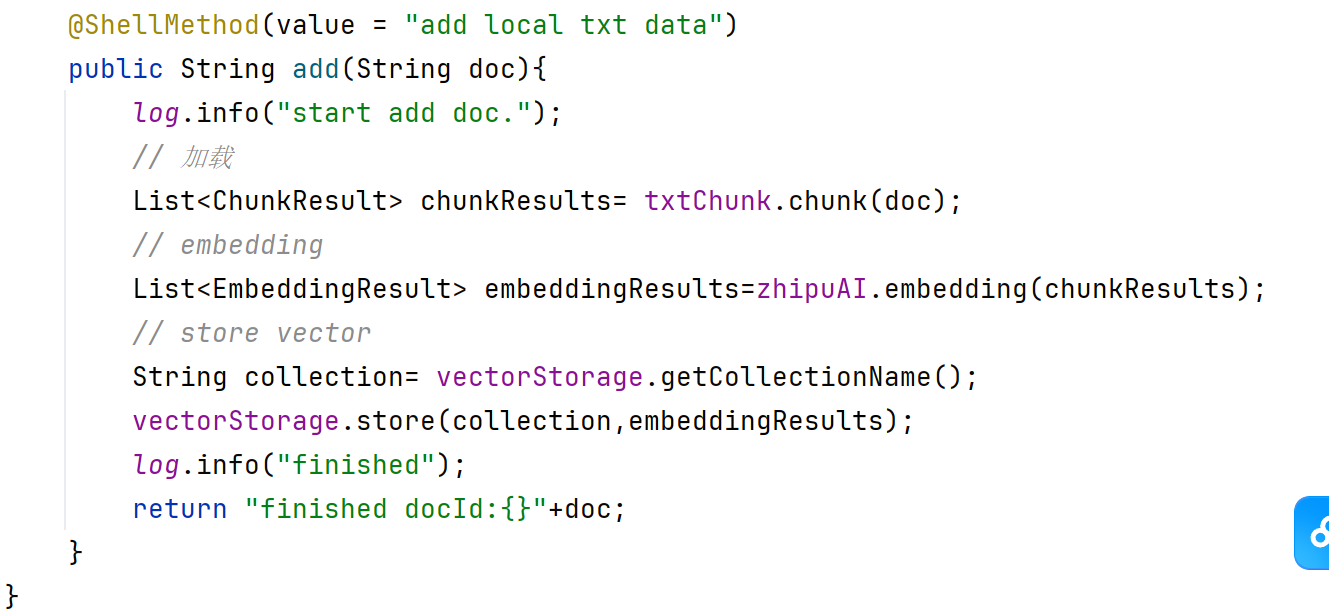
@ShellMethod(value = "add local txt data") // 声明这是一个Shell命令,描述为"add local txt data"
public String add(String doc) { // 定义命令方法,接收一个字符串参数doc(文件路径或文本内容)
log.info("start add doc."); // 打印日志:开始处理文档
// 1. 文本分块(Chunking)
List<ChunkResult> chunkResults = txtChunk.chunk(doc); // 调用分块工具,将文档拆分为多个文本块
// 2. 向量化(Embedding)
List<EmbeddingResult> embeddingResults = zhipuAI.embedding(chunkResults); // 使用智谱AI(或其他模型)将文本块转为向量
// 3. 向量存储
String collection = vectorStorage.getCollectionName(); // 获取向量数据库的集合名(类似表名)
vectorStorage.store(collection, embeddingResults); // 将向量存储到数据库中
log.info("finished"); // 打印日志:处理完成
return "finished docId:{}" + doc; // 返回处理结果(格式有误,应为String.format)
}数据处理的三步:文本分块、向量化、向量存储。最后返回结果。
这几步全调用方法,现在看是一个黑盒,知道输入输出和功能就行,后面再具体看黑盒里面的代码。
doc参数是文件内容还是文件路径搞不懂?试着输出了doc,发现是文件名。但是,根据文件名就能找着??
![]()
发现有一个默认路径/data,然后再默认路径/data下找doc文件名。找一下哪里设置的默认路径。
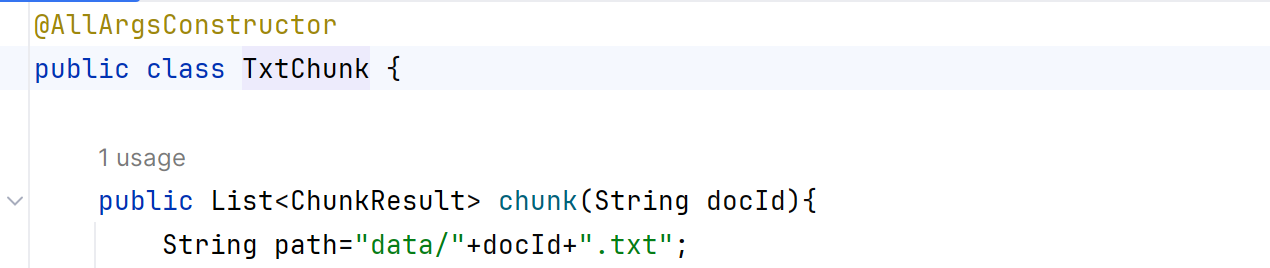
/data在chunk这里。
所以这个意思是,add 文件名。add这个方法就收到了参数doc文件名。然后进行文本分块(数据处理的具体代码放在/compoents文件夹),调用了chunk方法,然后根据默认路径+文件名+.txt,就得到一条完整的路径(相对路径)。
读取文件流classpathresource(path)


来回流转的数据,封装在对象中,而这些对象的代码都放在/domain文件夹里。
明天再写。