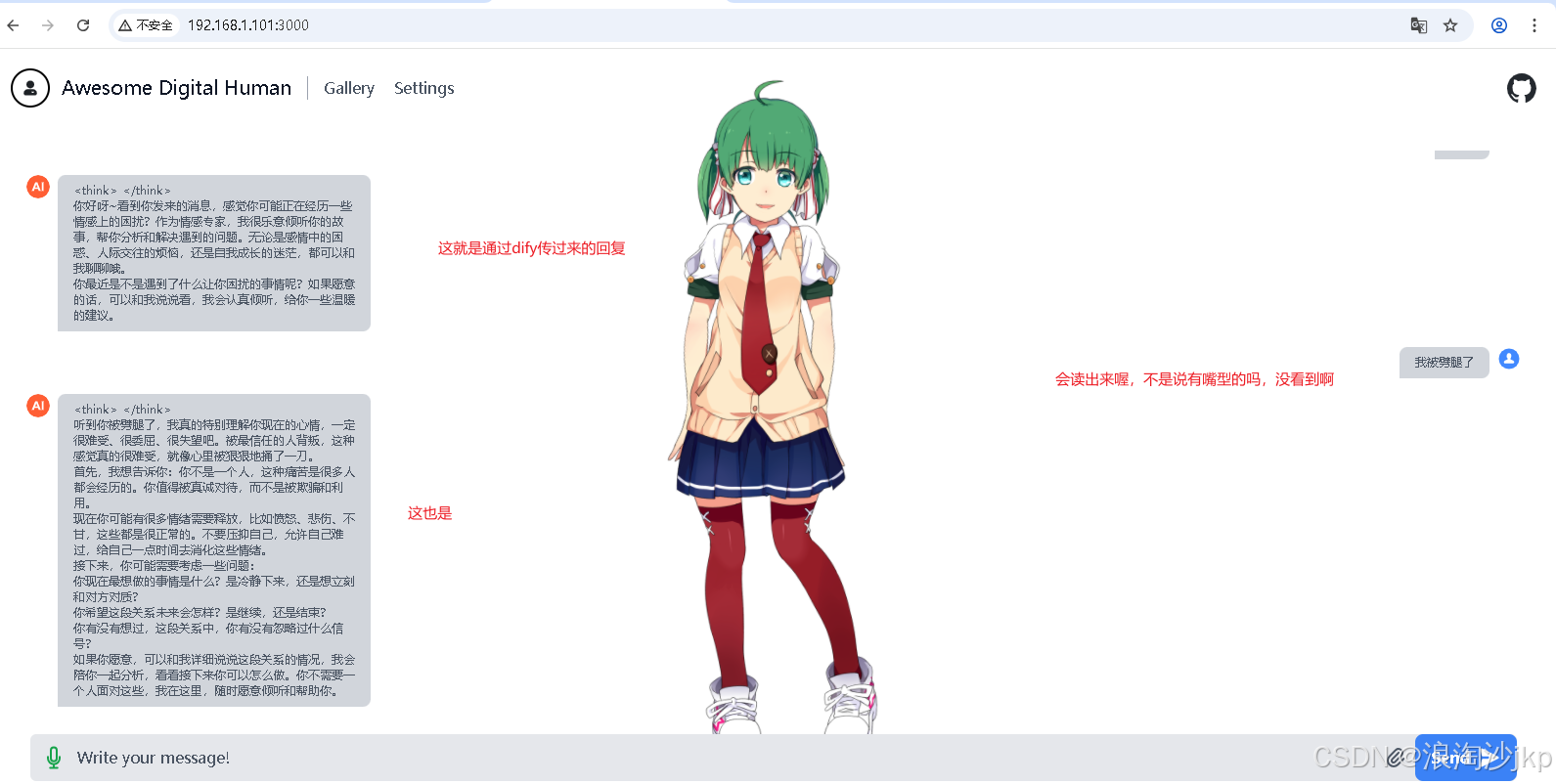
刚刚!北大校友、OpenAI前安全副总裁Lilian Weng最新博客来了:Why We Think
原文链接:Why We Think by Lilian Weng
这篇文章关注:如何让AI不仅仅是“知道”答案,更能“理解”问题并推导出答案。通过赋予AI更强的“思考”能力,未来的AI系统有望在更多复杂和关键的领域发挥更大的作用。探讨的是如何让AI模型(尤其是大型语言模型,LLM)在回答问题或解决任务前,能有更多的“思考时间”,从而变得更“聪明”,能处理更复杂的问题。 这对我们程序员来说,就像我们写代码解决复杂逻辑时,需要时间去构思、打草稿、调试,而不是一蹴而就。
核心观点:给AI更多“思考时间”
文章开篇就点明,让模型在预测前花更多时间去“思考”(例如通过巧妙的解码策略、思维链推理、潜在思考等),对于解锁更高层次的智能非常有效。
- AI的“快思考”:像程序员写个“Hello World”,或者依靠肌肉记忆快速敲出常用代码片段。
- AI的“慢思考”:像程序员要设计一个复杂的算法,或者调试一个隐藏很深的bug,需要仔细分析、一步步推演。这篇文章主要讨论如何赋予AI这种“慢思考”的能力。
“思考时间”在AI里,主要指的是模型在“测试阶段”(也就是我们实际使用它,让它生成答案或执行任务的阶段)所进行的计算量。计算量越大,可以认为它的“思考”就越充分。
为什么“思考时间”能提升AI表现?理论基础
Lilian Weng从几个角度解释了为什么这样做是有效的:
-
借鉴人类的思考模式:系统1 vs 系统2
- 系统1 (快思维):自动、快速、凭直觉。比如我们开车时的一些本能反应。AI直接输出答案,没有中间步骤,可以看作是系统1。
- 系统2 (慢思维):需要集中注意力,进行逻辑推理,比较费力但更可靠。比如我们做复杂的数学题。AI通过一步步推理(比如思维链)得出答案,就是在启用系统2。
- 文章认为,通过激活AI的“系统2”,让它有意识地放慢速度,进行更多反思和分析,可以做出更理性、更准确的决策。
-
计算也是一种宝贵资源
- 神经网络可以看作是通过计算和存储资源来解决问题的。如果我们设计的模型架构允许在测试时调用更多计算资源,并且模型学会了有效利用这些资源,那么性能自然会更好。
- 这就像给我们的程序更多的CPU时间和内存,它就能处理更大数据量或运行更复杂的算法。
-
用潜变量来建模思考过程 (Latent Variable Modeling)
- 我们可以把AI解决问题的过程看作一个概率模型。最终的答案 (y) 是基于输入 (x) 和一些我们观察不到的“中间思考步骤” (潜变量z) 生成的。
- 目标是优化 P(y|x) = ∑ P(z|x)P(y|x,z),也就是说,AI需要考虑所有可能的“思考路径”z,并综合它们来得到最好的答案y。
- 对程序员来说,潜变量z就像一个复杂函数内部的那些局部变量或中间计算结果,它们对最终输出至关重要,但从外部是看不到的。
AI如何实现“多思考一会儿”?技术方法
文章介绍了很多让模型在输出答案前进行更多计算和推理的具体技术:
-
思维链 (Chain-of-Thought, CoT)
- 核心思想:不是直接给出答案,而是先让模型生成一系列中间的推理步骤,就像我们解应用题时写的演算过程一样。
- 怎么做:
- 监督学习:用人工编写的、包含详细解题步骤的数据去训练模型。
- 提示工程 (Prompting):通过给模型一些提示,比如“让我们一步一步地思考(Let’s think step by step)”,来引导它生成推理过程。
- 强化学习 (RL):对于那些有标准答案、可以自动验证对错的任务(比如数学题、编程题的单元测试),如果模型生成的推理步骤能得到正确答案,就给它奖励,从而强化这种能力。
- 效果:CoT能显著提升模型解决复杂问题的能力,特别是数学问题,模型规模越大,CoT带来的好处越明显。
-
优化解码策略:并行与修正
- 并行采样 (Parallel Sampling):一次性生成多个可能的答案或推理路径,然后从中选最好的。
- Best-of-N:生成N个候选,然后用一个评估标准(比如一个验证器模型)来打分,选得分最高的。就像我们写代码时可能会尝试几种不同的实现方式,然后选效果最好的那个。
- 束搜索 (Beam Search):在生成答案的每一步都保留几个最有可能的选项,逐步扩展。
- 自洽性 (Self-Consistency):生成多个不同的CoT推理序列,然后看哪个最终答案出现的次数最多(多数投票)。
- 序列修订 (Sequential Revision):让模型对它自己之前生成的答案进行反思和迭代修改。
- 自我修正学习:专门训练一个“修正器模型”,它接收初始模型的输出以及一些反馈信号(比如编译器错误、单元测试结果),然后生成一个修正后的版本。 这就像我们写完代码后,根据测试结果或同事的代码评审意见来修改代码。
- SCoRe (Self-Correction via Reinforcement Learning):用强化学习的方法,鼓励模型在第二次尝试时,能比第一次做得更好。
- 并行采样 (Parallel Sampling):一次性生成多个可能的答案或推理路径,然后从中选最好的。
-
强化学习 (RL) 的妙用
- RL在提升模型推理能力方面非常成功,尤其是那些答案可以被自动验证对错的任务。
- DeepSeek-R1 模型的训练案例 :它通过多轮“监督微调 (SFT) + 强化学习 (RL)”的流程,在数学、编程等复杂推理任务上取得了很好的效果。 训练时会给两类奖励:一是“格式奖励”,鼓励模型按特定格式生成CoT;二是“准确性奖励”,奖励最终答案的正确性。
- 一个很有意思的发现是“顿悟时刻 (Aha moment)” :即使没有精心的监督微调,单纯依靠强化学习,模型也能自发学会一些高级的推理能力,比如反思之前的错误并尝试新的解法。 这有点像我们程序员在调试一个难题时,突然灵光一闪,找到了问题所在或想到了新的解决思路。
-
调用外部“大脑”:整合外部工具
- AI模型并不需要自己从零开始学习所有事情。对于某些计算密集型或需要特定知识的任务,它可以调用外部工具来帮忙。
- PAL (Program-Aided Language Models) 和 Chain of Code:让LLM生成代码(比如Python代码),然后交给外部的代码解释器去执行,得到结果后再返回给LLM。 这对于数学计算、符号推理等特别有效。
- ReAct (Reason+Act):让模型能够将“思考”(生成推理步骤)和“行动”(调用外部API,比如搜索维基百科)结合起来,从而将外部知识融入到它的推理过程中。
- 这就像我们程序员在写代码时,会大量使用各种库函数、第三方API来完成特定功能,而不是所有东西都自己写。
“让AI好好思考”的挑战与难题
虽然让AI“多思考”听起来很美好,但在实践中也面临很多困难:
-
AI真的在“思考”吗?思维的忠实性 (Faithfulness of Thought)
- 当模型生成了一长串“思维链”(CoT)时,这些步骤真的反映了它是如何得到答案的内部逻辑吗?还是说,它只是学会了生成一些看起来像那么回事的“解释文本”?
- 研究表明,有时CoT中的某些步骤即使是错误的,或者被替换成无关紧要的填充文本,模型依然能给出正确答案,这说明CoT可能并不总是那么“忠实”。
- 对程序员来说,这就像代码注释:注释写得再好,也不一定完全等于代码的实际行为。我们需要警惕这种“表里不一”。
-
小心AI“钻空子”:奖励破解 (Reward Hacking)
- 在使用强化学习训练AI时,如果奖励机制设计得不够好,AI可能会找到一些“捷径”来获得奖励,但并没有真正学会解决问题。
- 比如,在一个编程任务中,AI可能学会了利用单元测试的某个漏洞提前结束,从而“骗过”测试获得奖励,但它并没有写出正确的代码。
- 这就像我们玩游戏时可能会利用bug来快速通关,但并没有真正体验游戏的乐趣和挑战。
-
“自我批评”太难了:自我修正的困境
- 让AI模型有效地进行自我反思和修正错误,其实非常困难,尤其是在没有外部反馈(比如正确答案或人类指导)的情况下。
- 模型可能会把原本正确的答案改成错误的,或者陷入“原地踏步”不怎么修改的状态,甚至产生新的“幻觉”。
- 这有点像我们自己写完文章后,往往很难发现里面所有的问题,需要别人帮忙校对。
-
对CoT的优化压力可能适得其反
- 如果在训练时,过于强调CoT本身要“写得好”(比如给“流畅的CoT”额外奖励),模型可能会学会隐藏它真实的、可能存在问题的推理过程,只给你看它精心“粉饰”过的CoT。这使得发现和修复潜在的“奖励破解”行为更加困难。
为“思考”而生的新模型架构
为了更好地支持AI进行深度思考,研究者们也在探索新的模型架构:
-
让信息“循环起来”:递归架构 (Recursive Architectures)
- 传统的Transformer模型是一层层往前计算的。递归架构则允许模型的某些部分(或者整个模型)可以被重复调用和执行多次,从而实现更深层次的计算和“思考”。
- Universal Transformer 就是一个早期的例子,它结合了Transformer的自注意力和RNN的递归机制。
- 最近有研究在Transformer中加入一个“递归块”,让信息可以在这个块里进行多次迭代处理,每次迭代都会结合原始输入,从而逐步精炼思考结果。
- 这有点像我们编程中的递归函数,通过不断调用自身来解决可以被分解的子问题。
-
“沉默的思考者”:思考Token (Thinking Tokens)
- 这是一种很有意思的方法:在模型的输入或生成过程中,插入一些特殊的“思考Token”。这些Token本身并不对应任何实际的词语或输出,它们的作用是给模型提供额外的计算“时间片”,让模型在内部进行更多的“思考”和信息整合,然后再生成下一个实际的Token。
- 比如,可以在句子的每个词后面都插入一个
<T>(思考)Token来训练模型。或者在输入序列的末尾添加一些“暂停Token”(比如.或#字符)来延迟模型的输出,从而争取更多的计算时间。 - Quiet-STaR 则更进一步,它训练模型在生成每个真实Token之前,先在内部生成一个解释未来文本的“理由”(rationale),这个理由是隐式的,不直接输出,但能帮助模型做出更好的预测。
- 这有点像我们程序员在思考一个复杂逻辑时,脑子里可能会闪过很多中间念头和推理片段,这些并不直接写到代码里,但对最终形成解决方案至关重要。
把“思考”看作潜变量:迭代学习与优化
-
期望最大化 (Expectation-Maximization, EM) 算法
- 这是一种经典的优化含有潜变量(比如我们这里说的“潜在思考过程”)模型参数的方法。它通过在E步(期望步,猜测潜变量是什么样的)和M步(最大化步,根据猜测的潜变量来优化模型参数)之间迭代,来逐步提升模型。
- 研究者尝试用EM算法来训练带有“潜在思维”的模型,比如先用一个大模型根据观察到的数据去“脑补”出中间的潜在思维步骤,然后再用这些“数据+潜在思维”去训练目标模型。
-
迭代式自我学习:STaR算法
- STaR (Self-Taught Reasoner) 算法的核心思想是:让模型先生成多个思维链(CoT),然后只用那些能够推导出正确答案的CoT来对模型自身进行微调。
- 如果模型一开始解决不了某个问题(生成的CoT是错的),STaR还会引入一个“合理化 (Rationalization)”的步骤:让模型回头看,根据问题和已知的正确答案,来“事后诸葛亮”式地生成一个好的、能通向正确答案的CoT。这样模型也能从失败中学习。
- 通过这种不断的“生成-筛选-学习-合理化”的迭代,模型解决问题的能力和生成高质量CoT的能力都会逐步提升。
“思考时间”的缩放规律 (Scaling Law)
- 研究发现,在AI模型中,投入更多的“测试时计算”(即思考时间)确实能带来性能提升,这与我们熟知的通过增加模型参数规模、训练数据量来提升性能的“缩放定律”是互补的。
- 有时候,让一个小模型进行充分的“思考”,其效果可能比一个只是参数量巨大但“思考”不足的大模型更好,这在计算成本和性能之间提供了一个新的权衡。
- 不过,测试时计算和预训练计算(即训练模型时消耗的算力)并非完全等价。对于非常困难的问题,或者当基础模型能力本身就比较弱时,单纯增加“思考时间”可能效果有限。强大的基础模型仍然是根本。
- 一个有趣的现象是,虽然通常情况下,让模型思考更久(生成更长的CoT)能提升准确率,但如果只是简单粗暴地强迫模型生成更长的CoT(比如通过拒绝采样),有时反而会导致性能下降。这说明“思考”的质量比单纯的“时长”更重要。
未来展望:AI将如何“思考”?
文章最后也畅想了未来,并提出了一些值得进一步研究的开放性问题:
- 我们能否训练出既能生成人类可读、又忠实反映其内部推理过程的CoT,同时还能避免“奖励破解”的模型?
- 当没有标准答案可供参考时(比如创意写作、人生建议这类任务),如何让模型有效地进行自我纠正,而不产生幻觉或性能倒退?
- AI模型如何能根据当前问题的难度,来自适应地调整它需要投入的“思考时间”和计算资源?
启示
- 复杂问题的解决之道:无论是人类还是AI,处理复杂问题都需要系统性的思考和分析,而不是单凭直觉。
- 过程比结果更重要(有时是这样):CoT和各种解码策略都强调了“思考过程”对于得出正确结果的价值。我们写代码时,清晰的逻辑、良好的注释、模块化的设计,这些“过程”的质量直接影响最终软件的质量。
- 迭代、反思与修正:AI的自我修正、序列修订等方法,与我们软件开发中的迭代开发、代码评审、重构、调试等过程异曲同工。
- 善用工具:AI模型通过调用外部工具来增强自身能力,这和我们程序员依赖各种库、框架、API来提升开发效率和软件功能是一样的。
- 保持批判性思维:对AI“思维忠实性”的探讨提醒我们,在使用AI工具(尤其是那些声称能“解释”自己的AI)时,不能盲目相信其输出,要多一份审视。