用 PyTorch 从零实现简易GPT(Transformer 模型)
本文将结合示例代码,通俗易懂地拆解大模型(Transformer)从数据预处理到推理预测的核心组件与流程,并通过 Mermaid 流程图直观展示整体架构。文章结构分为四层,层次清晰,帮助读者系统掌握大模型原理与实战。
1 引言
大模型(如 GPT、BERT 等)之所以强大,得益于其背后多层自注意力和前馈网络的有机结合。本文以极简版中文 Transformer 为例,从最基础的数据准备到完整训练与推理过程,逐步剖析每个核心环节,让零基础读者也能轻松理解大模型的工作原理,并动手复现。
2 大模型核心组件概览
2.1 整体架构流程图

流程图中,数据层负责将中文句子转换为 ID 序列;模型层依次执行词嵌入、位置编码、编码器堆叠及线性投影;任务层完成训练(损失计算与优化)与推理(生成预测)。
3 模块详解
3.1 数据准备
3.1.1 原始文本与分词
-
原始中文句子
示例中我们定义了三句极简中文:sentences = [ "我今天去公园", "公园里有很多树", "树上有小鸟" ]每个字视为一个 token,无需额外分词工具。
3.1.2 构建词表
-
按首次出现顺序构建字表
chars = []; seen = set() for s in sentences: for c in s: if c not in seen: seen.add(c); chars.append(c) char2idx = {char: idx+2 for idx,char in enumerate(chars)} char2idx["<pad>"] = 0; char2idx["<unk>"] = 1 idx2char = {v:k for k,v in char2idx.items()} vocab_size = len(char2idx)<pad>:填充符,用于对齐;<unk>:未知符,用于未登录字符。
3.1.3 生成输入-目标对
-
滑动窗口生成序列
def create_sequences(data, seq_length=3): inputs, targets = [], [] for seq in data: for i in range(len(seq)-seq_length): inputs.append(seq[i:i+seq_length]) targets.append(seq[i+1:i+1+seq_length]) return torch.tensor(inputs), torch.tensor(targets) inputs, targets = create_sequences(data, seq_length=3)- 输入:连续 n 个字的 ID;
- 目标:右移一位后的 n 个字,用于语言模型预测。
3.2 位置编码(Positional Encoding)
-
为什么需要位置编码?
自注意力机制本身对序列顺序不敏感,必须加入显式位置编码以保留顺序信息。 -
实现思路
class PositionalEncoding(nn.Module): def __init__(self, d_model, max_len=5000): super().__init__() pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1).float() div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0)/d_model)) pe[:,0::2] = torch.sin(position * div_term) pe[:,1::2] = torch.cos(position * div_term) self.register_buffer('pe', pe.unsqueeze(0)) def forward(self, x): return x + self.pe[:, :x.size(1), :]- 正弦/余弦:不同频率编码,不同维度交替使用 sin/cos;
- 注册 buffer:在模型保存/加载时自动携带,不参与梯度更新。
3.3 Transformer 编码器
3.3.1 模型整体定义
class ChineseTransformer(nn.Module):
def __init__(self, vocab_size, d_model=32, nhead=4, num_layers=2):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pos_enc = PositionalEncoding(d_model, max_len=20)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=nhead,
dim_feedforward=128, dropout=0.1
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embed(x) # (batch, seq_len) -> (batch, seq_len, d_model)
x = self.pos_enc(x) # 加入位置编码
x = x.permute(1,0,2) # 转换为 (seq_len, batch, d_model)
x = self.transformer(x) # 多层编码器堆叠
x = x.permute(1,0,2) # 恢复 (batch, seq_len, d_model)
return self.fc(x) # 线性投影到 vocab_size
3.3.2 嵌入层(Embedding)
- 将离散的 token ID 映射到连续空间中的向量;
nn.Embedding(vocab_size, d_model):可训练的查表操作。
3.3.3 多头自注意力(Multi-Head Attention)
- 每个注意力头关注不同子空间;
nn.TransformerEncoderLayer内部集成了多头注意力与残差连接。
3.3.4 前馈网络(Feed-Forward Network)
- 两层线性变换 + 激活 + Dropout;
- 扩展后维度
dim_feedforward,再投回d_model。
3.4 训练与推理
3.4.1 损失函数与优化器
model = ChineseTransformer(vocab_size)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
- 忽略填充位置
<pad>; - Adam 优化器自适应学习率。
3.4.2 训练循环
num_epochs = 100
for epoch in range(num_epochs):
model.train(); optimizer.zero_grad()
output = model(inputs)
loss = criterion(output.view(-1, vocab_size), targets.view(-1))
loss.backward(); optimizer.step()
if (epoch+1) % 20 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")
- 展开:将
(batch, seq_len, vocab_size)转为二维,匹配交叉熵接口; - 定期打印:监控训练动态。
3.4.3 推理预测
def predict_next(text, model, temperature=1.0):
model.eval()
with torch.no_grad():
input_ids = torch.tensor([char2idx.get(c,1) for c in text[-3:]]).unsqueeze(0)
output = model(input_ids)
logits = output[0,-1,:] / temperature
probs = torch.softmax(logits, dim=-1)
return idx2char[torch.argmax(probs).item()]
- Temperature:温度系数调整采样分布;
- 贪心选择:直接取最大概率。
测试示例:
test_cases = ["我今天", "公园里", "树上有"]
for case in test_cases:
print(f"输入 '{case}' → 预测下一个字: '{predict_next(case, model)}'")
4 完整示例代码
import torch
import torch.nn as nn
import math
###############################
# 1. 准备中文训练数据(极简示例)
###############################
# 定义3个简单中文句子(每个字为一个token)
sentences = [
"我今天去公园", # 拆分为 ['我', '今', '天', '去', '公', '园']
"公园里有很多树", # 拆分为 ['公', '园', '里', '有', '很', '多', '树']
"树上有小鸟" # 拆分为 ['树', '上', '有', '小', '鸟']
]
# 构建有序词表(按首次出现顺序)
chars = [] # 初始化空列表
seen = set() # 用于去重
for s in sentences:
for c in s:
if c not in seen:
seen.add(c)
chars.append(c) # 保留首次出现顺序
char2idx = {char: idx+2 for idx, char in enumerate(chars)} # id从2开始,0和1留给特殊符号
char2idx["<pad>"] = 0 # 填充符
char2idx["<unk>"] = 1 # 未知符
vocab_size = len(char2idx) # 词表大小
idx2char = {v: k for k, v in char2idx.items()} # 反向映射
# 将句子转为索引序列
def text_to_ids(text):
return [char2idx.get(c, 1) for c in text] # 未知字用<unk>代替
data = [text_to_ids(s) for s in sentences]
###############################
# 2. 位置编码(同上)
###############################
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, max_len: int = 5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1), :]
return x
###############################
# 3. 定义Transformer模型(微调参数)
###############################
class ChineseTransformer(nn.Module):
def __init__(self, vocab_size: int, d_model: int = 32, nhead: int = 4, num_layers: int = 2):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model)
self.pos_enc = PositionalEncoding(d_model, max_len=20)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=128,
dropout=0.1
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embed(x) # (batch, seq_len) -> (batch, seq_len, d_model)
x = self.pos_enc(x)
x = x.permute(1, 0, 2) # 调整为(seq_len, batch, d_model)
x = self.transformer(x)
x = x.permute(1, 0, 2) # 恢复为(batch, seq_len, d_model)
x = self.fc(x)
return x
###############################
# 4. 数据预处理(生成输入-目标对)
###############################
def create_sequences(data, seq_length=3):
inputs, targets = [], []
for seq in data:
for i in range(len(seq) - seq_length):
inputs.append(seq[i:i+seq_length]) # 输入:前n个字
targets.append(seq[i+1:i+1+seq_length]) # 目标:后n个字(右移一位)
return torch.tensor(inputs), torch.tensor(targets)
# 生成训练数据(序列长度设为3)
inputs, targets = create_sequences(data, seq_length=3)
print("示例输入-目标对:")
print("输入:", [idx2char[i.item()] for i in inputs[0]], "→ 目标:", [idx2char[t.item()] for t in targets[0]])
###############################
# 5. 训练模型
###############################
model = ChineseTransformer(vocab_size=vocab_size)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充位置
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 简单训练循环(仅演示1个epoch)
# model.train()
# optimizer.zero_grad()
#
# output = model(inputs) # (batch_size, seq_len=3, vocab_size)
# loss = criterion(output.view(-1, vocab_size), targets.view(-1))
# loss.backward()
# optimizer.step()
#
# print(f"训练损失: {loss.item():.4f}")
num_epochs = 100
for epoch in range(num_epochs):
model.train()
optimizer.zero_grad()
# 前向传播
output = model(inputs)
# 计算损失
loss = criterion(output.view(-1, vocab_size), targets.view(-1))
# 反向传播
loss.backward()
optimizer.step()
# 每100次打印损失
if (epoch + 1) % 20 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")
###############################
# 6. 推理测试:预测下一个字
###############################
def predict_next(text, model, temperature=1.0):
model.eval()
with torch.no_grad():
# 将输入文本转为索引
input_ids = torch.tensor([char2idx.get(c, 1) for c in text[-3:]], dtype=torch.long).unsqueeze(0)
# 预测
output = model(input_ids) # (1, seq_len, vocab_size)
next_token_logits = output[0, -1, :] / temperature
probs = torch.softmax(next_token_logits, dim=-1)
next_token_id = torch.argmax(probs).item()
return idx2char[next_token_id]
# 测试预测
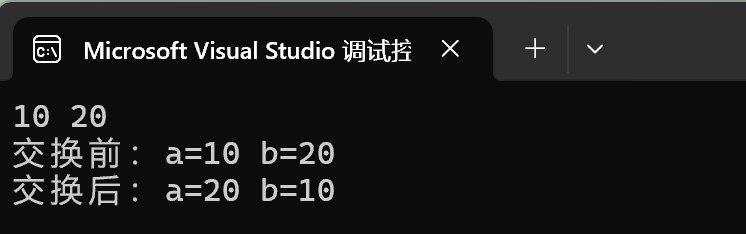
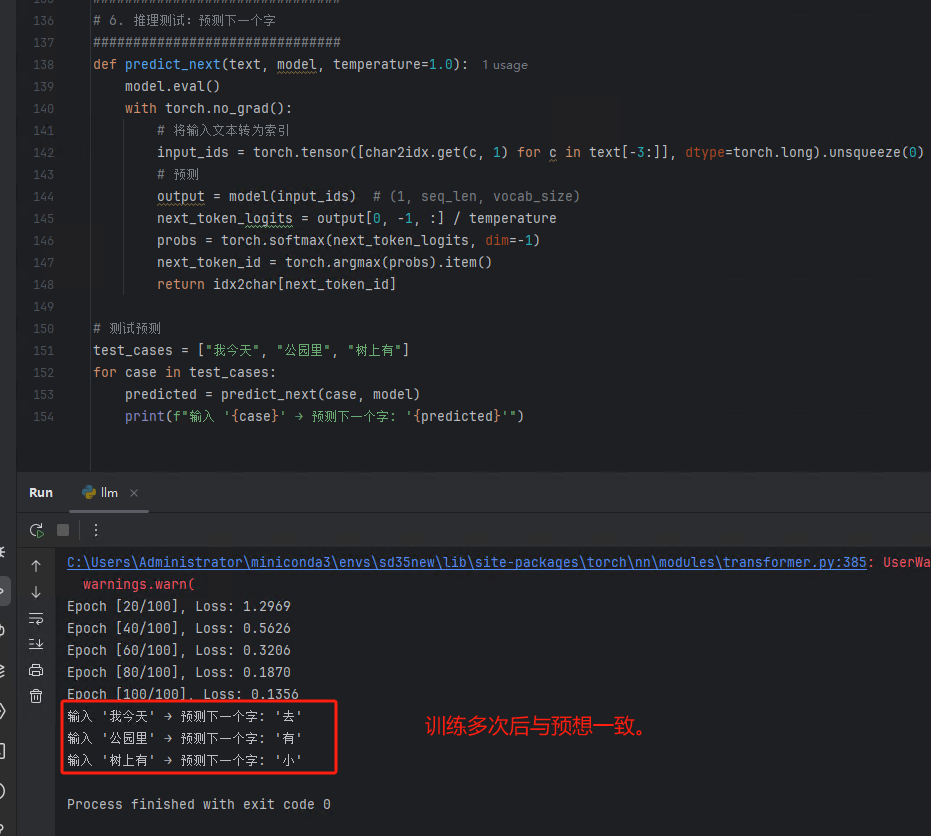
test_cases = ["我今天", "公园里", "树上有"]
for case in test_cases:
predicted = predict_next(case, model)
print(f"输入 '{case}' → 预测下一个字: '{predicted}'")
实测结果验证正确,如下图:
5 总结
- 通俗易懂:每个模块拆解为小步骤,结合代码示例加深理解;
- 实战演练:完整代码可直接运行,快速上手 Transformer 中文建模。
至此,读者已掌握大模型从数据到预测的全流程原理。欢迎在此基础上拓展更多高级功能,共同学习不断进阶!