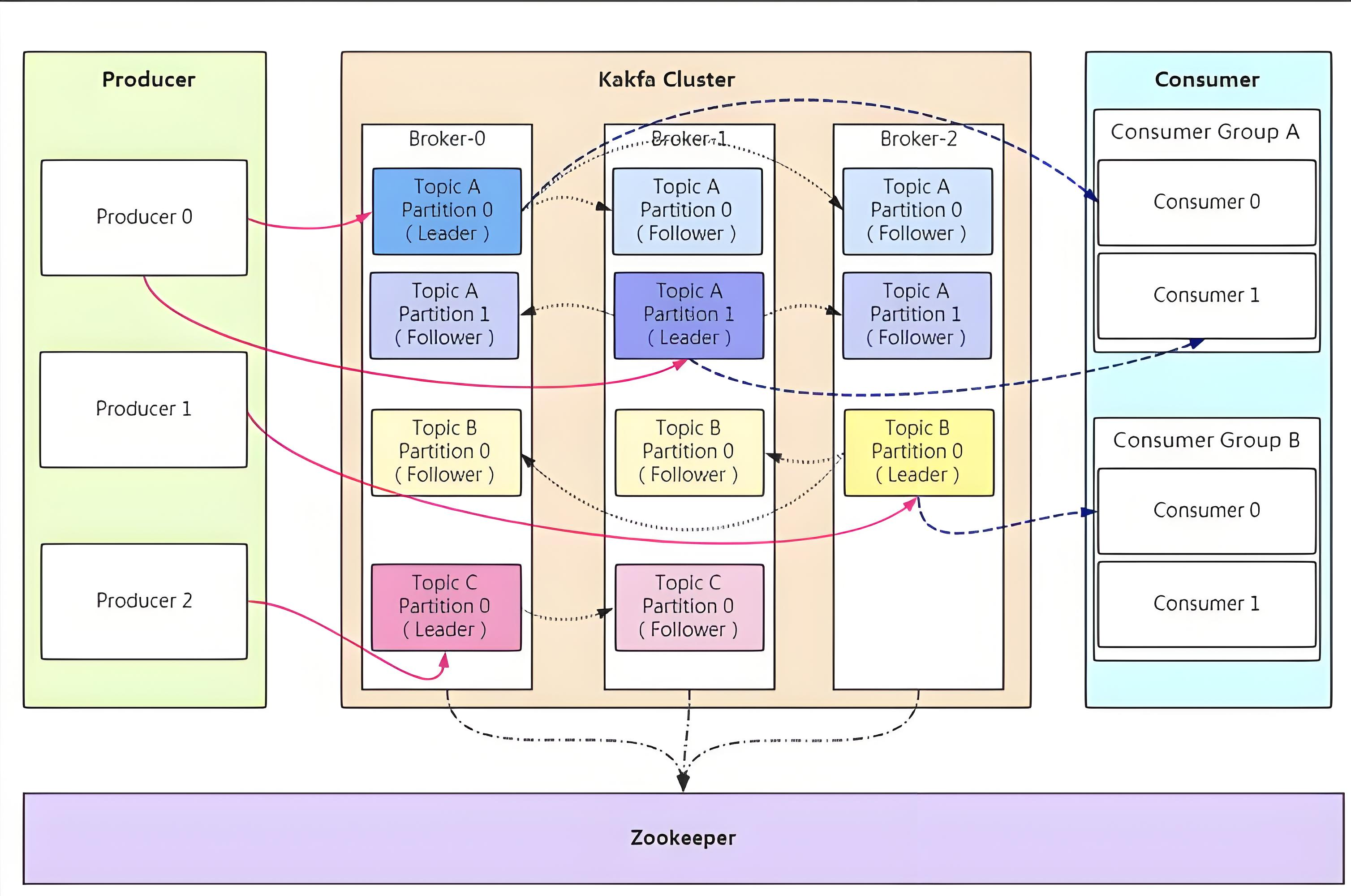
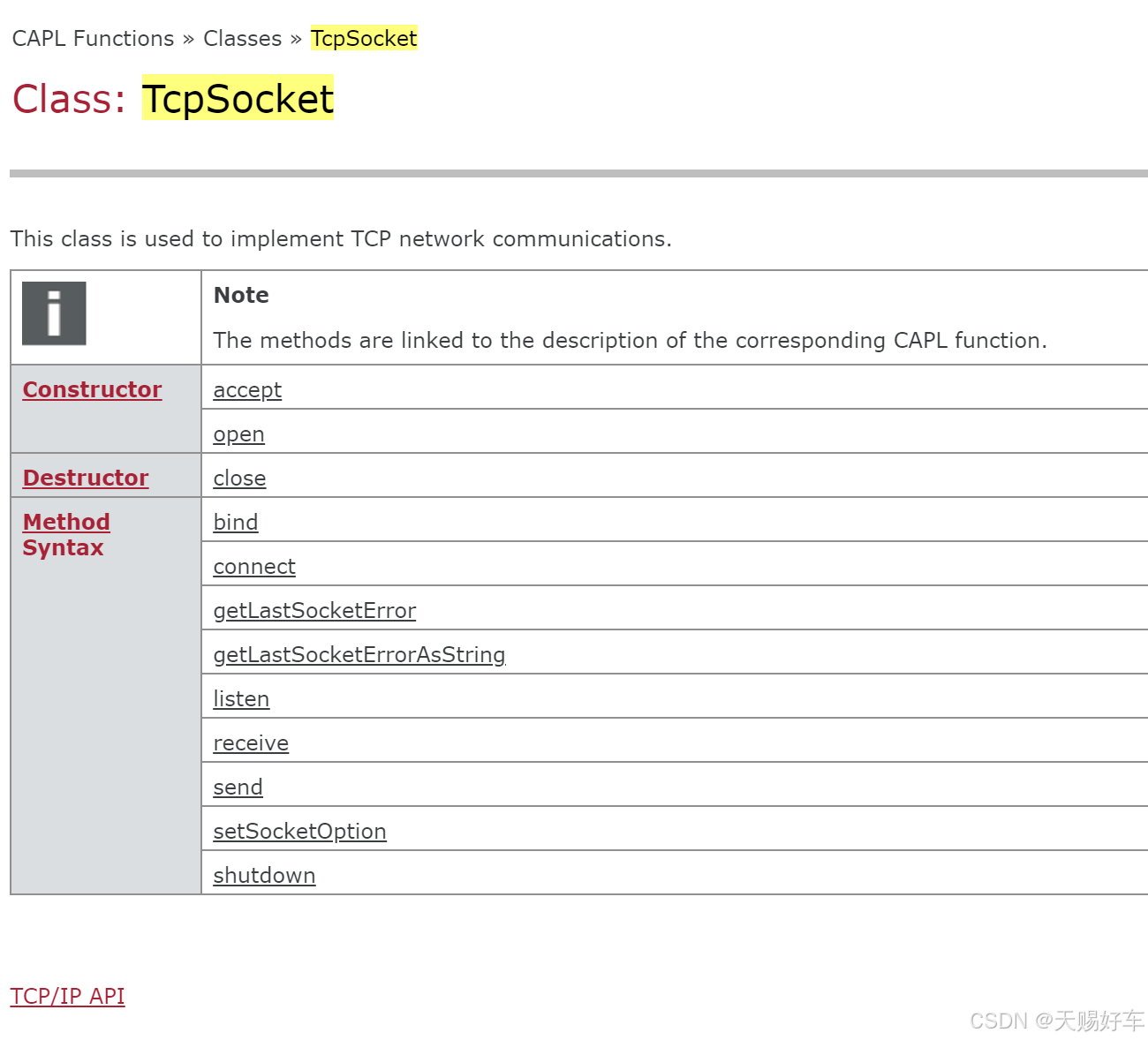
Langchain系列文章目录
01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南
02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖
03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南
04-玩转 LangChain:从文档加载到高效问答系统构建的全程实战
05-玩转 LangChain:深度评估问答系统的三种高效方法(示例生成、手动评估与LLM辅助评估)
06-从 0 到 1 掌握 LangChain Agents:自定义工具 + LLM 打造智能工作流!
07-【深度解析】从GPT-1到GPT-4:ChatGPT背后的核心原理全揭秘
08-【万字长文】MCP深度解析:打通AI与世界的“USB-C”,模型上下文协议原理、实践与未来
Python系列文章目录
PyTorch系列文章目录
机器学习系列文章目录
深度学习系列文章目录
Java系列文章目录
JavaScript系列文章目录
深度学习系列文章目录
01-【深度学习-Day 1】为什么深度学习是未来?一探究竟AI、ML、DL关系与应用
02-【深度学习-Day 2】图解线性代数:从标量到张量,理解深度学习的数据表示与运算
03-【深度学习-Day 3】搞懂微积分关键:导数、偏导数、链式法则与梯度详解
04-【深度学习-Day 4】掌握深度学习的“概率”视角:基础概念与应用解析
05-【深度学习-Day 5】Python 快速入门:深度学习的“瑞士军刀”实战指南
06-【深度学习-Day 6】掌握 NumPy:ndarray 创建、索引、运算与性能优化指南
07-【深度学习-Day 7】精通Pandas:从Series、DataFrame入门到数据清洗实战
08-【深度学习-Day 8】让数据说话:Python 可视化双雄 Matplotlib 与 Seaborn 教程
09-【深度学习-Day 9】机器学习核心概念入门:监督、无监督与强化学习全解析
10-【深度学习-Day 10】机器学习基石:从零入门线性回归与逻辑回归
11-【深度学习-Day 11】Scikit-learn实战:手把手教你完成鸢尾花分类项目
12-【深度学习-Day 12】从零认识神经网络:感知器原理、实现与局限性深度剖析
文章目录
- Langchain系列文章目录
- Python系列文章目录
- PyTorch系列文章目录
- 机器学习系列文章目录
- 深度学习系列文章目录
- Java系列文章目录
- JavaScript系列文章目录
- 深度学习系列文章目录
- 前言
- 一、神经网络的灵感之源:生物神经元
- 1.1 生物神经元简介
- 1.1.1 结构与功能
- 1.1.2 信息传递方式
- 1.2 从生物到人工:模型的抽象
- 1.2.1 关键元素的类比
- 二、感知器模型 (Perceptron Model)
- 2.1 感知器的定义与结构
- 2.1.1 基本组成
- 2.1.2 数学表示
- 2.2 激活函数:阶跃函数 (Step Function)
- 2.2.1 定义与作用
- 2.2.2 图示阶跃函数
- 2.3 感知器的学习规则 (简述)
- 2.3.1 目的
- 2.3.2 更新规则 (感知器学习算法)
- 三、感知器的能力与局限性
- 3.1 线性可分性
- 3.1.1 感知器能做什么?
- 3.1.2 代码示例:实现 AND/OR 逻辑门 (Python)
- 3.2 感知器的致命缺陷:XOR 问题
- 3.2.1 XOR 逻辑的定义
- 3.2.2 为什么感知器无法解决 XOR?
- 3.2.3 历史意义与影响
- 四、从感知器到神经网络
- 4.1 克服局限性的思考
- 4.1.1 多层结构的需求
- 4.2 展望:多层感知器 (MLP)
- 五、总结
前言
欢迎来到深度学习系列的第12篇文章!在前面的章节中,我们已经为深度学习之旅奠定了坚实的数学、编程和机器学习基础。我们了解了线性回归和逻辑回归等基本模型,并对模型训练的基本流程有了初步认识。从本篇开始,我们将正式踏入神经网络的核心领域。神经网络是当前人工智能浪潮中最耀眼的技术之一,而理解其最基本的构建单元——感知器(Perceptron)——是至关重要的一步。本文将带你深入了解感知器的概念、工作原理、能力以及其著名的局限性,为后续学习更复杂的神经网络结构打下坚实的基础。
一、神经网络的灵感之源:生物神经元
在深入研究人工神经网络之前,了解一下它们的生物学灵感来源——生物神经元,会非常有帮助。虽然人工神经网络是对生物神经系统的高度简化和抽象,但其核心思想确实源于此。
1.1 生物神经元简介
生物神经元是构成大脑和神经系统的基本单元,负责处理和传递信息。
1.1.1 结构与功能
一个典型的生物神经元主要由以下几个部分组成:
- 树突 (Dendrites):像树枝一样的结构,负责从其他神经元接收化学或电信号。
- 细胞体 (Soma):神经元的核心部分,包含细胞核。它整合从树突接收到的所有信号。
- 轴突 (Axon):一根长的纤维状结构,负责将细胞体处理后的信号传递给其他神经元、肌肉或腺体。
- 突触 (Synapse):神经元之间的连接点。当信号(动作电位)到达轴突末梢时,会通过突触释放神经递质,这些化学物质作用于下一个神经元的树突,从而传递信号。突触的强度是可以变化的,这构成了学习和记忆的基础。
下图展示了一个简化的生物神经元结构:
1.1.2 信息传递方式
生物神经元通过复杂的电化学过程传递信息。当树突接收到的信号累积到一定阈值时,细胞体会“兴奋”并产生一个称为“动作电位”的电脉冲。这个电脉冲沿着轴突传递到突触,并触发神经递质的释放,进而影响下一个神经元。这个过程可以看作是一种“全或无”的响应:要么神经元被激活并传递信号,要么不被激活。
1.2 从生物到人工:模型的抽象
人工神经网络中的“神经元”(通常指感知器或其变体)正是对生物神经元信息处理机制的一种数学抽象和简化。
1.2.1 关键元素的类比
我们可以将人工神经元的组成部分与生物神经元进行类比:
- 输入 (Inputs):类似于生物神经元的树突接收到的信号。
- 权重 (Weights):每个输入都带有一个权重,这可以类比于生物神经元中突触的强度。权重决定了对应输入信号的重要性。
- 加权和与偏置 (Weighted Sum & Bias):人工神经元会将所有输入信号与其对应的权重相乘后求和,再加上一个偏置项。这可以看作是对细胞体整合信号过程的模拟。偏置项可以理解为神经元固有的激活阈值,调整神经元被激活的难易程度。
- 激活函数 (Activation Function):加权和与偏置的结果会经过一个激活函数处理,产生最终的输出。这类似于生物神经元达到一定阈值后才会被激活(“放电”)的过程。
- 输出 (Output):激活函数的输出,类似于生物神经元通过轴突传递出去的信号。
通过这种抽象,科学家们构建了能够模拟生物学习过程的数学模型,即我们接下来要详细讨论的感知器。
二、感知器模型 (Perceptron Model)
感知器(Perceptron)由弗兰克·罗森布拉特(Frank Rosenblatt)在1957年首次提出,是已知最简单、最古老的人工神经网络模型之一。它是一个二分类(binary classification)的线性分类器。
2.1 感知器的定义与结构
一个感知器接收多个二进制输入(通常是0或1,或者-1和1),计算这些输入的加权和,如果这个和超过某个阈值,则输出1(代表一个类别),否则输出0(代表另一个类别)。
2.1.1 基本组成
一个感知器由以下几个关键部分构成:
- 输入 (Inputs):一组特征值,表示为 x _ 1 , x _ 2 , . . . , x _ n x\_1, x\_2, ..., x\_n x_1,x_2,...,x_n。
- 权重 (Weights):每个输入 x _ i x\_i x_i 都对应一个权重 w _ i w\_i w_i。权重表示该输入对于最终决策的重要性。权重可以是正数也可以是负数。
- 偏置 (Bias):一个常数项 b b b。偏置可以看作是独立于任何输入的额外参数,它允许我们上下平移决策边界,使得模型有更大的灵活性。如果没有偏置,决策边界必须通过原点。
- 激活函数 (Activation Function):通常是一个简单的阶跃函数(Step Function),用于根据加权和与偏置的结果产生输出。
2.1.2 数学表示
感知器的计算过程可以分为两步:
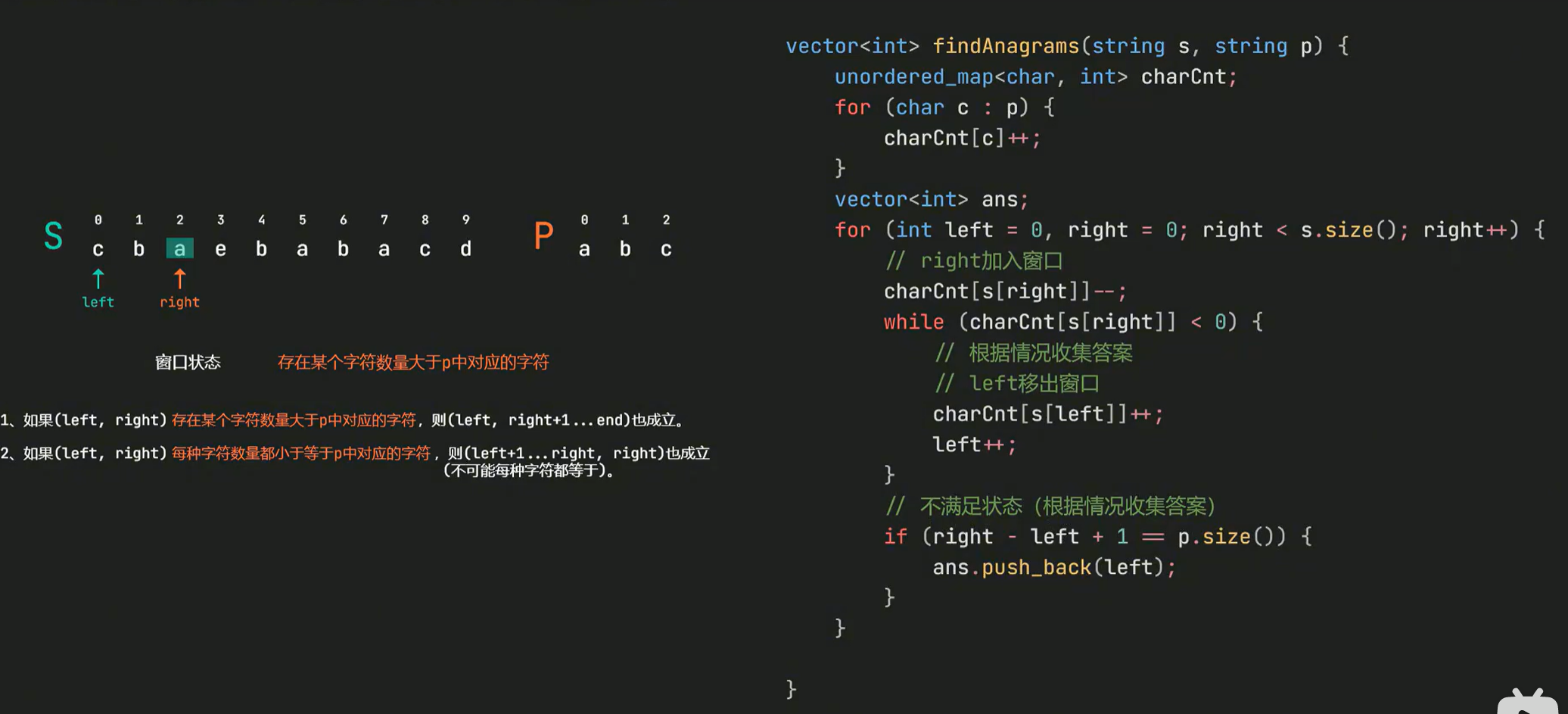
-
计算加权和 (Weighted Sum):将所有输入与它们对应的权重相乘,然后加上偏置项。这个结果通常用 z z z 表示。
$$z = (w_1 x_1 + w_2 x_2 + \dots + w_n x_n) + b
$$如果使用向量表示,令权重向量为 W = [ w _ 1 , w _ 2 , d o t s , w _ n ] T W = [w\_1, w\_2, \\dots, w\_n]^T W=[w_1,w_2,dots,w_n]T, X = [ x _ 1 , x _ 2 , d o t s , x _ n ] T X = [x\_1, x\_2, \\dots, x\_n]^T X=[x_1,x_2,dots,x_n]T,则加权和可以表示为:
$$z = W^T X + b
-
通过激活函数得到输出 (Output via Activation Function):将 z z z 输入到激活函数 f f f 中,得到最终的输出 y y y。
$$y = f(z)
下面是一个感知器的结构示意图:
graph TD
subgraph 感知器模型
direction LR
X1[输入 x1] -->|w1| S((Σ))
X2[输入 x2] -->|w2| S
Xd[...] -->|...| S
Xn[输入 xn] -->|wn| S
B[偏置 b] --> S
S -- 加权和 z --> AF[激活函数 f(z)]
AF -- 输出 y --> O[输出 y]
end
在这个图中, S i g m a \\Sigma Sigma 表示求和操作,输出 z = s u m w _ i x _ i + b z = \\sum w\_i x\_i + b z=sumw_ix_i+b。
2.2 激活函数:阶跃函数 (Step Function)
在经典的感知器模型中,最常用的激活函数是阶跃函数(也称为赫维赛德阶跃函数 Heaviside step function)。
2.2.1 定义与作用
阶跃函数的作用是将感知器的加权和 z z z 映射到一个二进制输出(通常是0或1,或者-1和1)。它引入了一种简单的非线性(尽管这种非线性能力有限),使得感知器能够做出决策。
如果我们将偏置 b b b 视为一个特殊的权重 w _ 0 w\_0 w_0,其对应的输入 x _ 0 x\_0 x_0 恒为1,即 z = s u m _ i = 0 n w _ i x _ i z = \\sum\_{i=0}^{n} w\_i x\_i z=sum_i=0nw_ix_i(其中 w _ 0 = b , x _ 0 = 1 w\_0=b, x\_0=1 w_0=b,x_0=1)。此时,阶跃函数可以定义为:
f ( z ) = { 1 if z > θ 0 if z ≤ θ f(z) = \begin{cases} 1 & \text{if } z > \theta \\ 0 & \text{if } z \le \theta \end{cases} f(z)={10if z>θif z≤θ其中 t h e t a \\theta theta 是一个预设的阈值。
更常见地,当偏置 b b b 显式包含在加权和 z = W T X + b z = W^T X + b z=WTX+b 中时,阶跃函数通常定义为(阈值为0):
KaTeX parse error: Expected 'EOF', got '&' at position 29: …begin{cases} 1 &̲ \\text{if } z …这意味着如果加权和大于0,感知器“激活”并输出1;否则,它输出0。
2.2.2 图示阶跃函数
阶跃函数(以阈值为0为例)的图像如下:
xychart-beta
title "阶跃函数 (Step Function)"
x-axis [-5, 5]
y-axis [-0.5, 1.5]
line [{ x: -5, y: 0 }, { x: 0, y: 0 }]
line [{ x: 0, y: 1 }, { x: 5, y: 1 }]
point [{x:0, y:0}]
point [{x:0, y:1}]
(注意:严格来说,在 z = 0 z=0 z=0 处的取值可以定义为0、1或0.5,具体取决于约定。在感知器中,通常将其归为一类,例如 z l e 0 z \\le 0 zle0 输出0。)
2.3 感知器的学习规则 (简述)
感知器的“学习”过程就是调整其权重 w _ i w\_i w_i 和偏置 b b b 的过程,目标是使得对于给定的训练数据集,感知器的输出能够尽可能地与真实的标签一致。
2.3.1 目的
学习的目的是找到一组权重和偏置,使得感知器能够正确地将输入数据点划分到它们各自的类别中。
2.3.2 更新规则 (感知器学习算法)
感知器学习算法是一个迭代的过程。对于训练集中的每一个样本 ( X , y _ t r u e ) (X, y\_{true}) (X,y_true)(其中 X X X 是输入特征向量, y _ t r u e y\_{true} y_true 是真实标签):
- 使用当前的权重 W W W 和偏置 b b b 计算感知器的输出 y _ p r e d = f ( W T X + b ) y\_{pred} = f(W^T X + b) y_pred=f(WTX+b)。
- 计算误差: e r r o r = y _ t r u e − y _ p r e d error = y\_{true} - y\_{pred} error=y_true−y_pred。
- 如果
e
r
r
o
r
n
e
0
error \\ne 0
errorne0(即预测错误),则更新权重和偏置:
- w _ i ( t e x t n e w ) = w _ i ( t e x t o l d ) + e t a c d o t e r r o r c d o t x _ i w\_i(\\text{new}) = w\_i(\\text{old}) + \\eta \\cdot error \\cdot x\_i w_i(textnew)=w_i(textold)+etacdoterrorcdotx_i (对每个权重 w _ i w\_i w_i)
-
b
(
t
e
x
t
n
e
w
)
=
b
(
t
e
x
t
o
l
d
)
+
e
t
a
c
d
o
t
e
r
r
o
r
b(\\text{new}) = b(\\text{old}) + \\eta \\cdot error
b(textnew)=b(textold)+etacdoterror
其中, e t a \\eta eta(eta)是学习率 (learning rate),一个介于0和1之间的小正数,它控制了每次更新的步长。
更新规则的直观理解:
- 如果 y _ t r u e = 1 y\_{true}=1 y_true=1 但 y _ p r e d = 0 y\_{pred}=0 y_pred=0(应激活但未激活),则 e r r o r = 1 error = 1 error=1。此时,为了使 z = W T X + b z = W^T X + b z=WTX+b 增大,需要增加那些 x _ i x\_i x_i 为正的输入的权重,并增加偏置。
- 如果 y _ t r u e = 0 y\_{true}=0 y_true=0 但 y _ p r e d = 1 y\_{pred}=1 y_pred=1(不应激活但激活了),则 e r r o r = − 1 error = -1 error=−1。此时,为了使 z = W T X + b z = W^T X + b z=WTX+b 减小,需要减小那些 x _ i x\_i x_i 为正的输入的权重,并减小偏置。
如果训练数据是线性可分的,感知器学习算法保证能在有限次数的迭代后收敛,即找到一个能够完美划分数据的权重和偏置组合。
三、感知器的能力与局限性
理解感知器能做什么和不能做什么是学习神经网络的关键。
3.1 线性可分性
感知器本质上是一个线性分类器。
3.1.1 感知器能做什么?
感知器能够解决线性可分 (linearly separable) 的问题。在线性代数中,方程 W T X + b = 0 W^T X + b = 0 WTX+b=0 定义了一个 n n n 维空间中的超平面。这个超平面将输入空间分成了两部分。感知器的决策边界就是这个超平面。如果一个数据集中的两类样本可以通过这样一个超平面完美地分开,那么这个问题就是线性可分的。
常见的线性可分问题包括逻辑门,如AND(与门)和OR(或门)。
- AND门:只有当所有输入都为1时,输出才为1。
- OR门:只要有任何一个输入为1,输出就为1。
3.1.2 代码示例:实现 AND/OR 逻辑门 (Python)
下面我们用一个简单的 Python 函数来模拟感知器,并展示如何用它来实现 AND 和 OR 逻辑门。
import numpy as np
class Perceptron:
def __init__(self, input_size, learning_rate=0.1, epochs=100):
"""
初始化感知器
:param input_size: 输入特征的数量 (不包括偏置的输入)
:param learning_rate: 学习率
:param epochs: 训练迭代次数
"""
# 初始化权重 (input_size + 1, 其中+1是为了偏置项的权重)
# np.random.rand 返回 [0, 1) 之间的随机数
self.weights = np.random.rand(input_size + 1) # w0, w1, ..., wn (w0 is bias weight)
self.learning_rate = learning_rate
self.epochs = epochs
def _step_function(self, z):
"""阶跃激活函数"""
return 1 if z > 0 else 0
def predict(self, inputs):
"""
进行预测
:param inputs: 输入特征向量 (不包含偏置的 x0=1)
:return: 预测结果 (0 或 1)
"""
# 构造带偏置的输入向量 [1, x1, x2, ..., xn]
inputs_with_bias = np.insert(inputs, 0, 1) # 在索引0处插入1作为偏置的输入
# 计算加权和 z = w0*1 + w1*x1 + ...
z = np.dot(self.weights, inputs_with_bias)
return self._step_function(z)
def train(self, training_inputs, labels):
"""
训练感知器
:param training_inputs: 训练数据集, shape (num_samples, num_features)
:param labels: 对应的真实标签, shape (num_samples,)
"""
for _ in range(self.epochs):
for inputs, label in zip(training_inputs, labels):
prediction = self.predict(inputs)
error = label - prediction
# 更新权重,包括偏置的权重 self.weights[0]
inputs_with_bias = np.insert(inputs, 0, 1)
self.weights += self.learning_rate * error * inputs_with_bias
print("训练完成。最终权重:", self.weights)
# --- AND 门示例 ---
print("训练 AND 门感知器:")
# 输入数据: [[0,0], [0,1], [1,0], [1,1]]
# 对应标签: [0, 0, 0, 1]
and_inputs = np.array([[0,0], [0,1], [1,0], [1,1]])
and_labels = np.array([0, 0, 0, 1])
and_perceptron = Perceptron(input_size=2, learning_rate=0.1, epochs=10) # 通常需要很少的迭代
and_perceptron.train(and_inputs, and_labels)
print("\nAND 门测试:")
for inputs in and_inputs:
print(f"输入: {inputs}, 预测输出: {and_perceptron.predict(inputs)}")
# 手动设置 AND 门的权重和偏置进行验证 (一种可能的解)
# 例如: w1 = 0.5, w2 = 0.5, bias_weight (w0) = -0.7
# z = -0.7*1 + 0.5*x1 + 0.5*x2
# (0,0) -> z = -0.7 -> 0
# (0,1) -> z = -0.7 + 0.5 = -0.2 -> 0
# (1,0) -> z = -0.7 + 0.5 = -0.2 -> 0
# (1,1) -> z = -0.7 + 1.0 = 0.3 -> 1
# --- OR 门示例 ---
print("\n训练 OR 门感知器:")
# 输入数据: [[0,0], [0,1], [1,0], [1,1]]
# 对应标签: [0, 1, 1, 1]
or_inputs = np.array([[0,0], [0,1], [1,0], [1,1]])
or_labels = np.array([0, 1, 1, 1])
or_perceptron = Perceptron(input_size=2, learning_rate=0.1, epochs=10)
or_perceptron.train(or_inputs, or_labels)
print("\nOR 门测试:")
for inputs in or_inputs:
print(f"输入: {inputs}, 预测输出: {or_perceptron.predict(inputs)}")
# 手动设置 OR 门的权重和偏置进行验证 (一种可能的解)
# 例如: w1 = 0.5, w2 = 0.5, bias_weight (w0) = -0.2
# z = -0.2*1 + 0.5*x1 + 0.5*x2
# (0,0) -> z = -0.2 -> 0
# (0,1) -> z = -0.2 + 0.5 = 0.3 -> 1
# (1,0) -> z = -0.2 + 0.5 = 0.3 -> 1
# (1,1) -> z = -0.2 + 1.0 = 0.8 -> 1
代码说明:
Perceptron类封装了感知器的逻辑。__init__:初始化权重(包括一个偏置项的权重self.weights[0])。_step_function:阶跃激活函数。predict:根据当前权重计算输出。输入inputs会被添加一个前导1,与偏置权重self.weights[0]相乘。train:实现感知器学习规则,迭代更新权重。
运行上述代码,你会看到感知器能够通过训练学会正确分类AND门和OR门的输入。
3.2 感知器的致命缺陷:XOR 问题
尽管感知器能够解决像AND和OR这样的简单问题,但它有一个著名的局限性:它无法解决异或 (XOR, exclusive OR) 问题。
3.2.1 XOR 逻辑的定义
XOR逻辑门当两个输入不同时输出1,相同时输出0。其真值表如下:
| 输入 x _ 1 x\_1 x_1 | 输入 x _ 2 x\_2 x_2 | 输出 y y y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
3.2.2 为什么感知器无法解决 XOR?
XOR问题不是线性可分的。我们无法在二维平面上画出一条直线,将XOR的输入点 (0,0), (1,1)(对应输出0)与 (0,1), (1,0)(对应输出1)完美地分开。
我们可以用图示来理解:
graph TD
subgraph XOR 数据点 (二维空间)
A[ (0,0) - 输出0 ]
B[ (0,1) - 输出1 ]
C[ (1,0) - 输出1 ]
D[ (1,1) - 输出0 ]
end
%% 尝试用一条直线分割是不可能的
%% 类0的点: A, D
%% 类1的点: B, C
几何直观解释:
想象一下在图上绘制这四个点:
- (0,0) 和 (1,1) 属于一类(输出0)。
- (0,1) 和 (1,0) 属于另一类(输出1)。
无论你如何尝试画一条直线,都无法将这两组点完全分到直线的两侧。至少会有一个点被错误分类。因为感知器的决策边界是一条直线(或高维空间中的超平面),所以单个感知器无法解决XOR问题。
3.2.3 历史意义与影响
1969年,马文·明斯基(Marvin Minsky)和西摩尔·派普特(Seymour Papert)在其著作《感知器》(Perceptrons)中深入分析了感知器的能力和局限性,并明确指出了其无法解决XOR这类非线性问题的缺陷。这本书对当时的人工智能领域产生了深远影响,导致了对神经网络研究热情的减退和资金的削减,这一时期有时被称为第一次“AI寒冬”(AI Winter)。
然而,XOR问题也激发了研究者们思考如何克服这一局限性,最终推动了多层感知器 (Multi-Layer Perceptron, MLP) 的发展,即通过将多个感知器组合成网络层次来解决非线性问题。
四、从感知器到神经网络
感知器的局限性(特别是XOR问题)清楚地表明,单个感知器不足以解决许多现实世界中的复杂问题,因为这些问题往往是非线性的。
4.1 克服局限性的思考
要解决像XOR这样的非线性问题,我们需要更强大的模型。关键的思路是:如果单个感知器(一条直线)不行,那么多个感知器组合起来(多条直线形成的区域)是否可以呢?
4.1.1 多层结构的需求
答案是肯定的。通过将感知器组织成层次结构——即多层感知器 (MLP)——我们可以创建能够学习非线性决策边界的模型。例如,XOR问题可以通过一个包含输入层、一个隐藏层(包含两个感知器)和一个输出层(一个感知器)的简单MLP来解决。隐藏层的感知器可以将输入空间转换到一个新的表示空间,在这个新的空间里,问题就变得线性可分了,然后输出层的感知器就可以进行最终的分类。
4.2 展望:多层感知器 (MLP)
多层感知器(MLP)是前馈神经网络(Feedforward Neural Network)的一种基本形式,它至少包含一个输入层、一个或多个隐藏层以及一个输出层。与单个感知器不同,MLP中的神经元通常使用平滑的、可微分的激活函数(如Sigmoid、Tanh或ReLU),而不是简单的阶跃函数。这使得我们可以使用基于梯度的优化算法(如反向传播)来训练网络。
在接下来的文章中,我们将深入探讨不同类型的激活函数,并学习如何构建和训练多层感知器,从而真正开启深度学习的大门。
五、总结
本篇文章我们详细介绍了神经网络的“原子”——感知器。通过学习,我们应掌握以下核心内容:
- 感知器模型:理解其由输入、权重、偏置和阶跃激活函数组成的基本结构。
- 数学表示与决策:感知器通过计算输入的加权和,并应用阶跃函数来产生二进制输出,从而实现分类决策。
- 线性可分性:感知器能够解决线性可分的问题,例如逻辑AND门和OR门,其决策边界是一个超平面。
- XOR困境:感知器的核心局限在于它无法解决非线性可分的问题,最经典的例子就是XOR(异或)问题。
- 历史意义:XOR问题及其在《感知器》一书中的阐述,对早期神经网络研究产生了重大影响,并间接推动了多层网络的发展。
- 奠基石作用:尽管功能有限,但感知器是理解更复杂神经网络(如多层感知器)的基础,为我们后续学习神经网络的层级结构和非线性处理能力奠定了基础。
理解感知器是进入神经网络世界的关键第一步。它的简单性使其易于理解,而其局限性则自然地引出了对更强大网络结构的需求。在下一篇文章中,我们将探讨各种激活函数,它们是构建更强大神经网络不可或缺的组件。敬请期待!