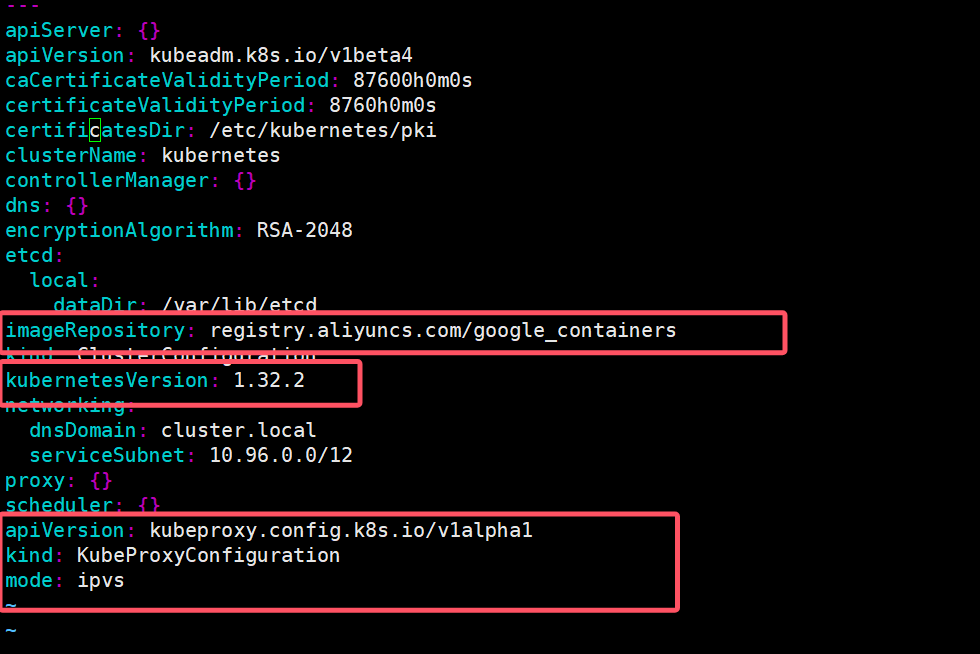
一、什么是数据预处理
数据预处理(Data Preprocessing)是数据分析和机器学习中至关重要的步骤,旨在将原始数据转换为更高质量、更适合分析或建模的形式。由于真实世界的数据通常存在不完整、不一致、噪声或冗余等问题,预处理可以帮助提高数据的可用性和模型的性能。
数据预处理的主要步骤
-
数据清洗(Data Cleaning)
-
处理缺失值:填充(均值、中位数、众数等)、删除缺失样本或字段。
-
处理噪声数据:平滑或剔除异常值(如使用分箱、聚类或统计方法)。
-
纠正不一致数据:统一格式(如日期格式、单位)、修正逻辑错误。
-
-
数据集成(Data Integration)
-
合并多个数据源,解决冗余、冲突或重复问题(例如同名不同义的字段)。
-
-
数据变换(Data Transformation)
-
标准化(Standardization):将数据缩放到均值为0、标准差为1(如Z-score)。
-
归一化(Normalization):将数据缩放到固定范围(如[0,1])。
-
离散化(Discretization):将连续数值分段(如年龄分为“青年”“中年”“老年”)。
-
特征编码:将分类变量转换为数值(如独热编码、标签编码)。
-
-
数据归约(Data Reduction)
-
降低数据规模,同时保留关键信息,例如:
-
特征选择:筛选重要特征(如相关系数、随机森林重要性)。
-
降维:使用主成分分析(PCA)、t-SNE等方法压缩维度。
-
-
-
数据分箱(Binning)
-
将连续值划分为区间,减少噪声影响(如将收入分为“低、中、高”)。
-
数据预处理的目的
-
提高数据质量:消除噪声、错误和不一致性。
-
提升模型性能:通过标准化、归一化等手段优化数据分布。
-
减少计算成本:降维和归约可加速模型训练。
-
适配算法需求:许多算法对输入数据的格式和范围敏感(如神经网络需要归一化)。
举例说明
-
原始数据问题:某用户年龄字段包含“-1”(异常值),收入字段有缺失。
-
预处理后:删除“-1”,用中位数填充缺失值,并对收入进行归一化处理。
数据预处理是数据科学流程中不可或缺的环节,直接影响最终结果的可靠性和模型效果。
二、数据检测
1.准备数据
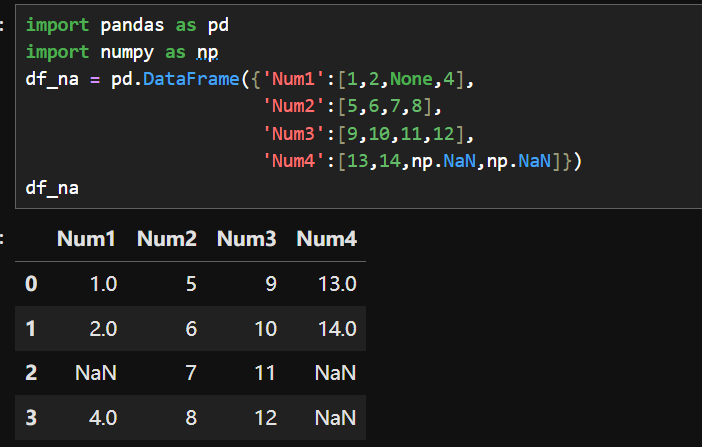
2.查看NaN值
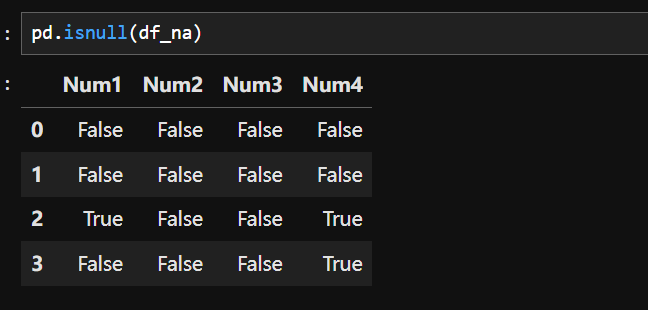
方法一:
isnull():是查看数据是否存在NaN值,如果有则返回True
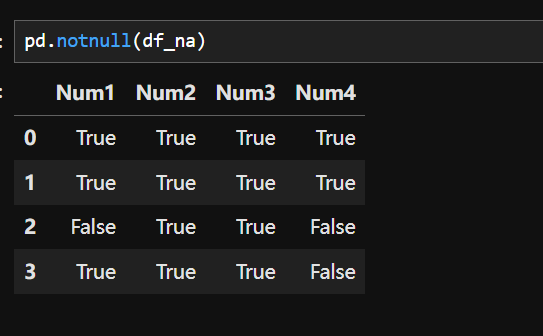
方法二:
notnull():是查数据是否不存在NaN值,如果不存在则返回True
三、缺失值处理
1.查看缺失值的占比
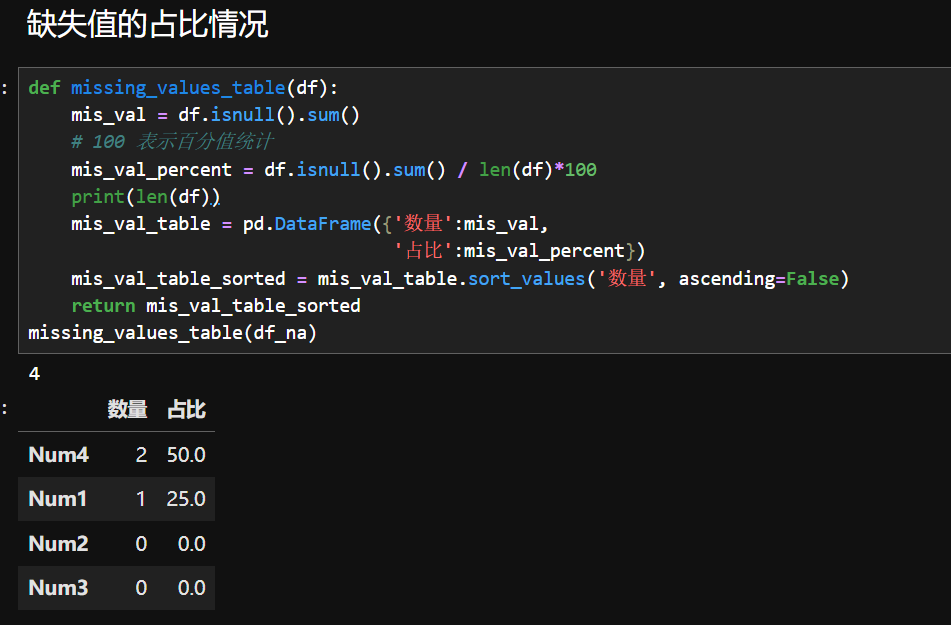
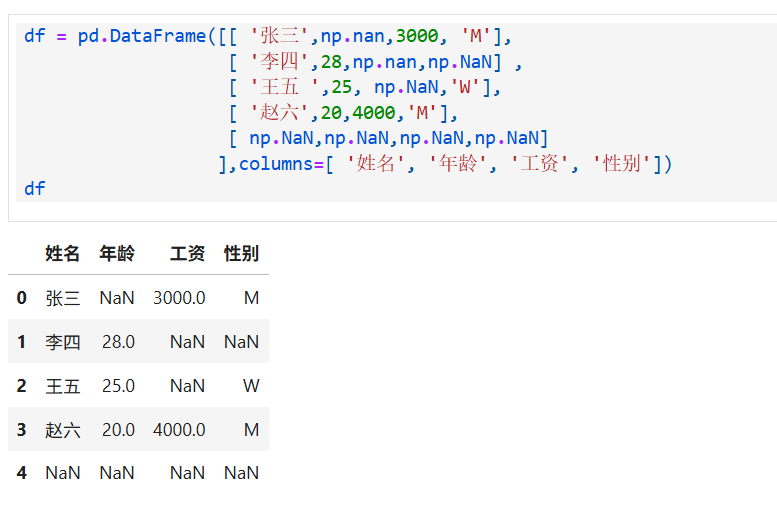
2.提取出完整的数据
这里使用另外一组数据
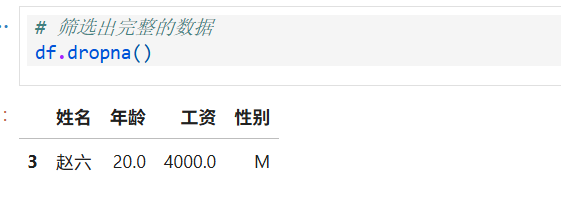
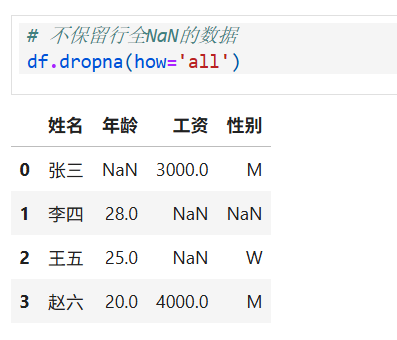
3.清除全空值
dropna是 Pandas 中 DataFrame 的一个方法,用于删除包含缺失值(NaN)的行或列,目的是清理数据中的无效缺失信息。how是dropna方法的一个参数,用于指定删除行或列的条件:- 当
how='any'时,只要行或列中 存在任意一个NaN,就删除该行或列。 - 当
how='all'时,仅当行或列中 所有值都为NaN时,才删除该行或列。
- 当
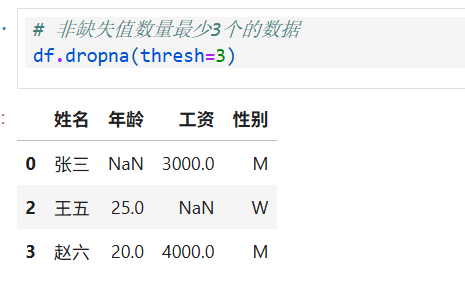
4.筛选非空值数
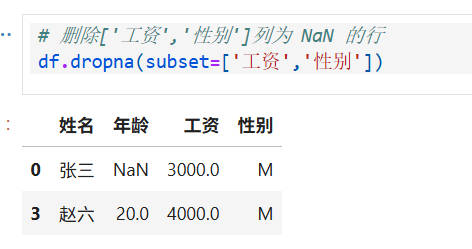
5.某一列 = NaN,删除整行数据
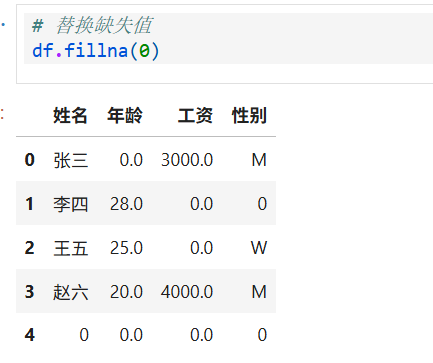
6.缺失值的替换处理
7.缺失值的填充处理
fillna是 Pandas 中 DataFrame 的一个方法,用于填充数据中的缺失值(NaN),其常见属性(参数)包括value(填充的具体值)、method(填充方法)、axis(指定轴,0或'index'表示行,1或'columns'表示列)等。method是fillna方法的一个参数,用于指定填充缺失值的具体方法:'ffill'(forward - fill的缩写)表示向前填充,即用缺失值前面(按指定轴方向)的非缺失值来填充当前缺失值。例如,若按行方向(axis=0),则用同一列中上方的非缺失值填充下方缺失值;若按列方向(axis=1),则用同一行中前方的非缺失值填充后方缺失值。-
另一种常见值是
'bfill'(backward - fill的缩写),表示向后填充,即用缺失值后面(按指定轴方向)的非缺失值来填充当前缺失值。
因为是向上填充,第一行已是最初数据,无法填充
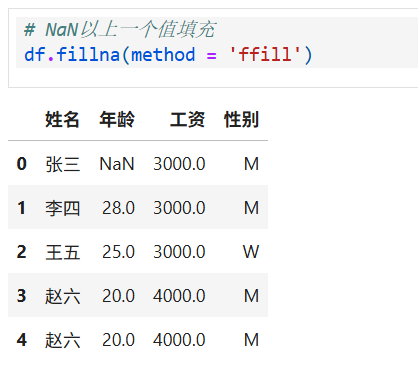
向下填充
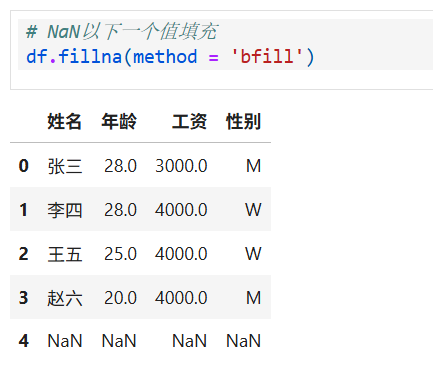
四、重复值处理
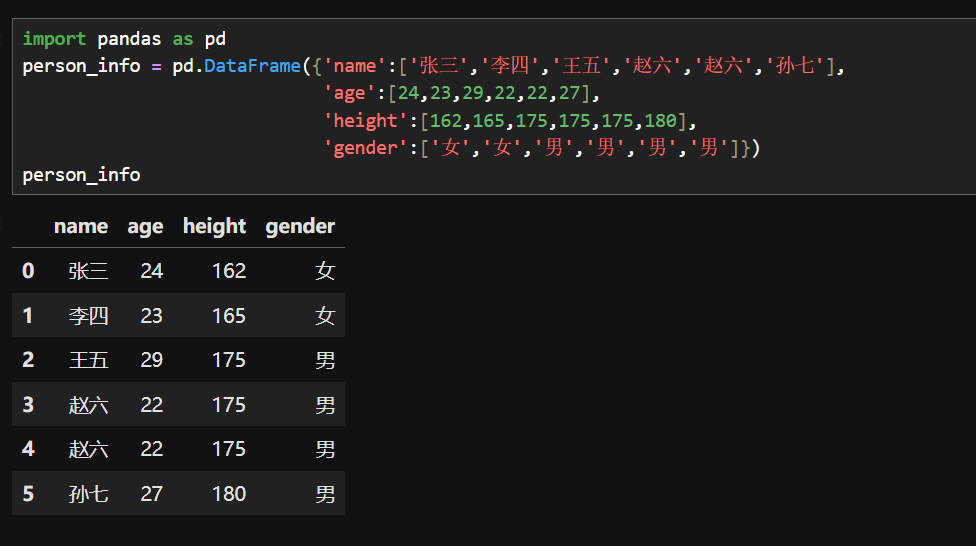
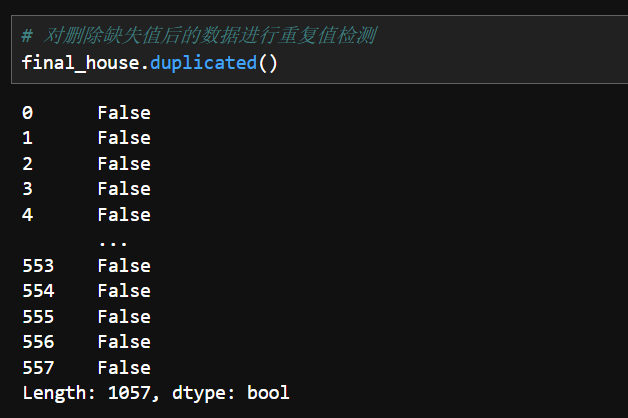
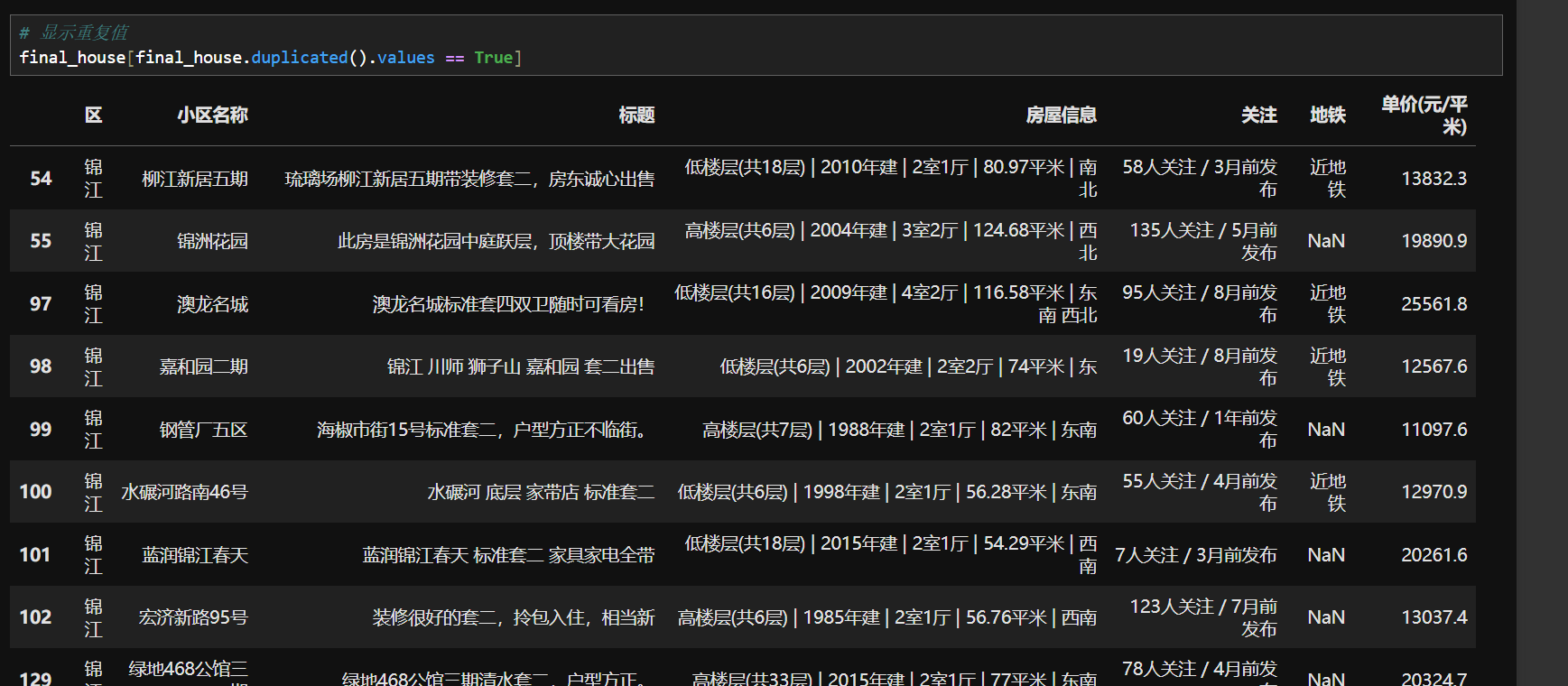
1.查看重复值
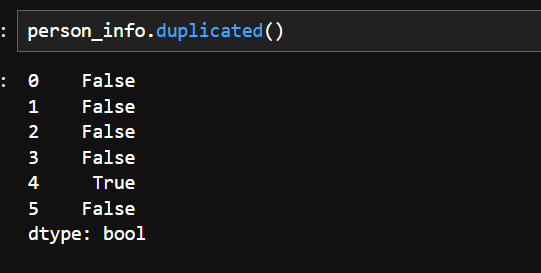
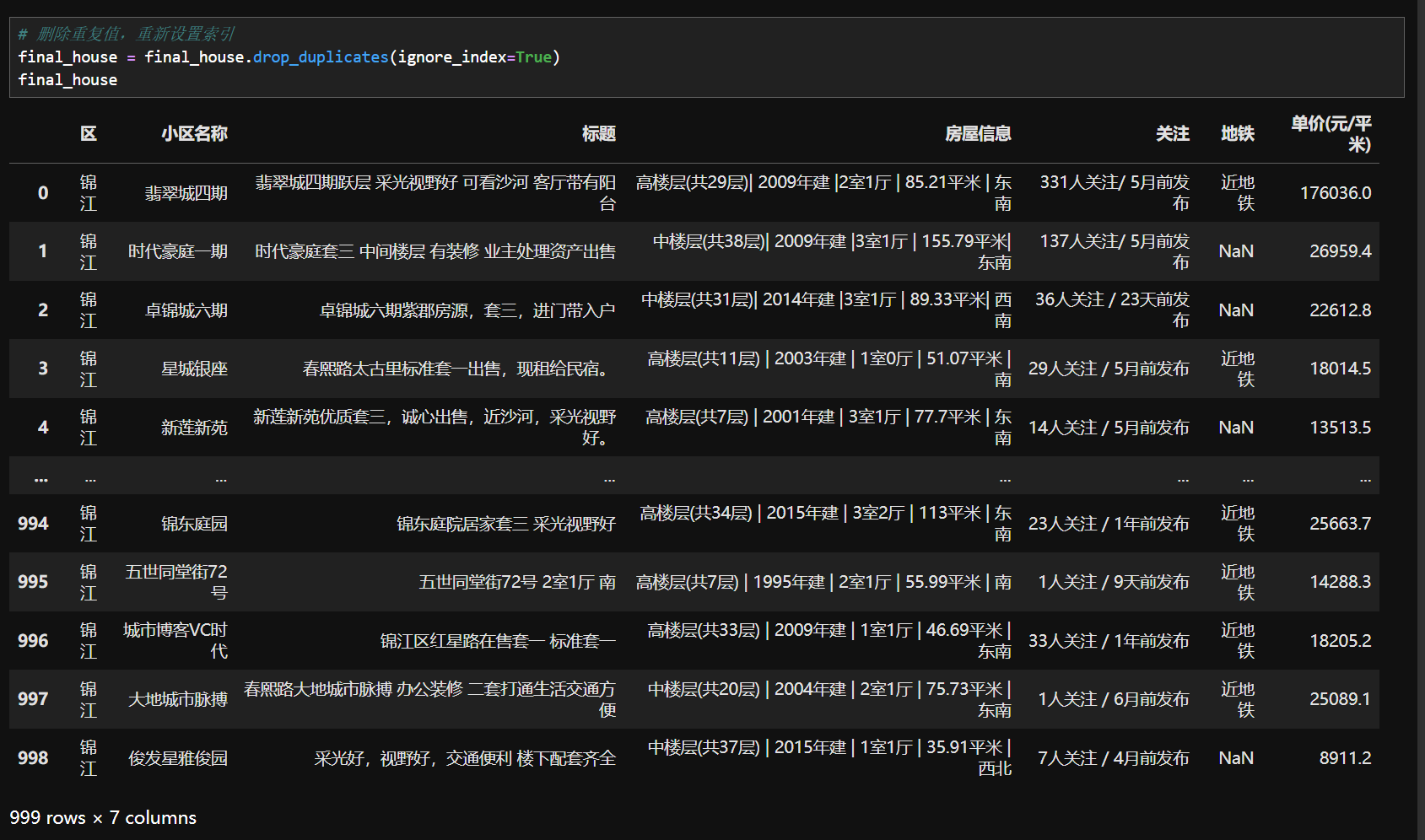
2.删除重复值数据
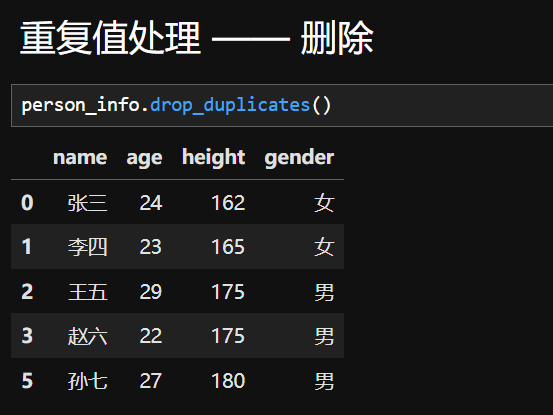
五、异常值处理
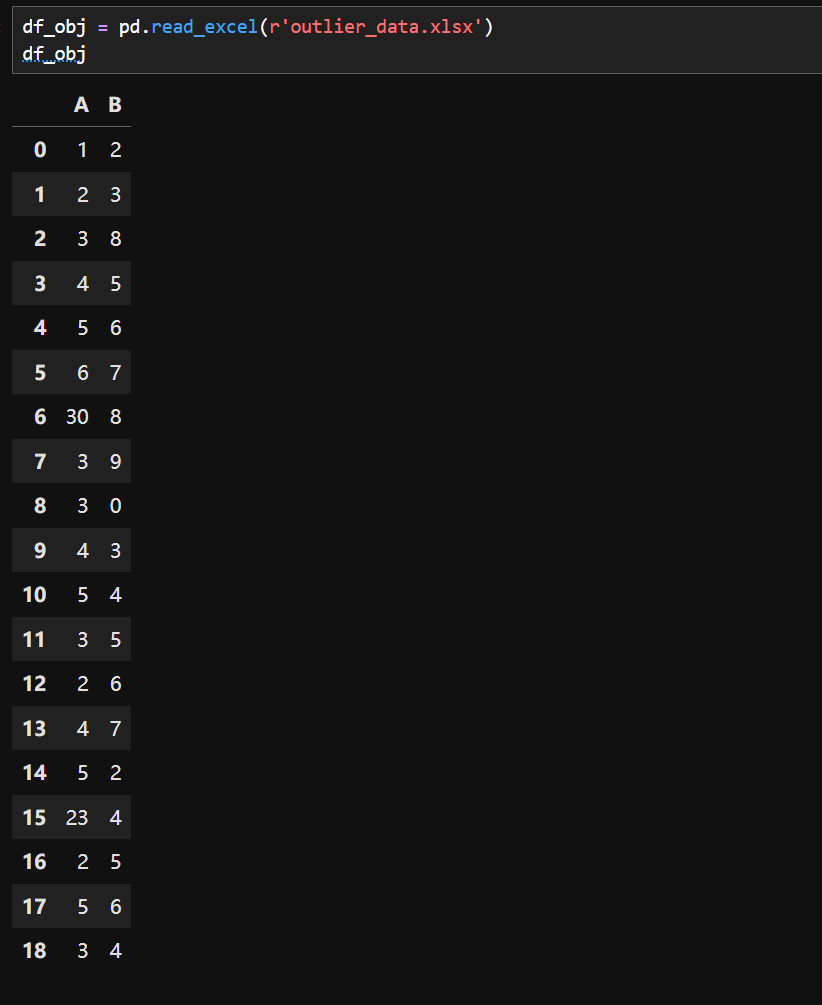
1.异常值替换
存在23和50替换成3和2
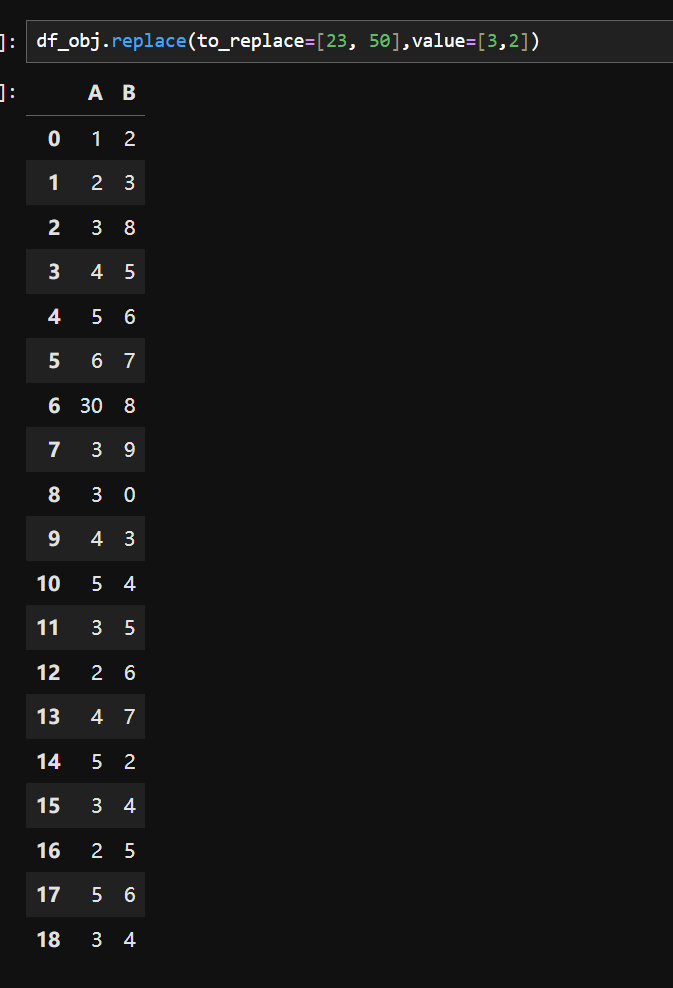
2.三西格玛法则
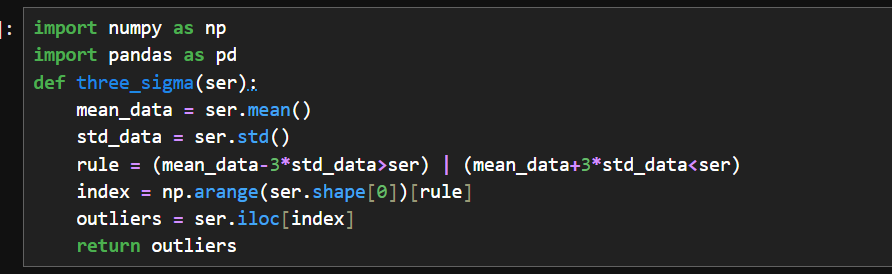
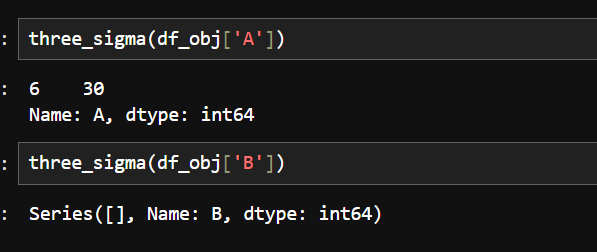
three_sigma(df_obj['A']):对 df_obj 数据框中的 'A' 列应用 three_sigma 函数,输出为 6 30 Name: A, dtype: int64,表明 'A' 列中存在符合三西格玛法则判定的异常值(这里显示为 6 和 30)。
three_sigma(df_obj['B']):对 df_obj 数据框中的 'B' 列应用该函数,输出为 Series([], Name: B, dtype: int64),表示 'B' 列中没有符合三西格玛法则判定的异常值,返回一个空的 Series。
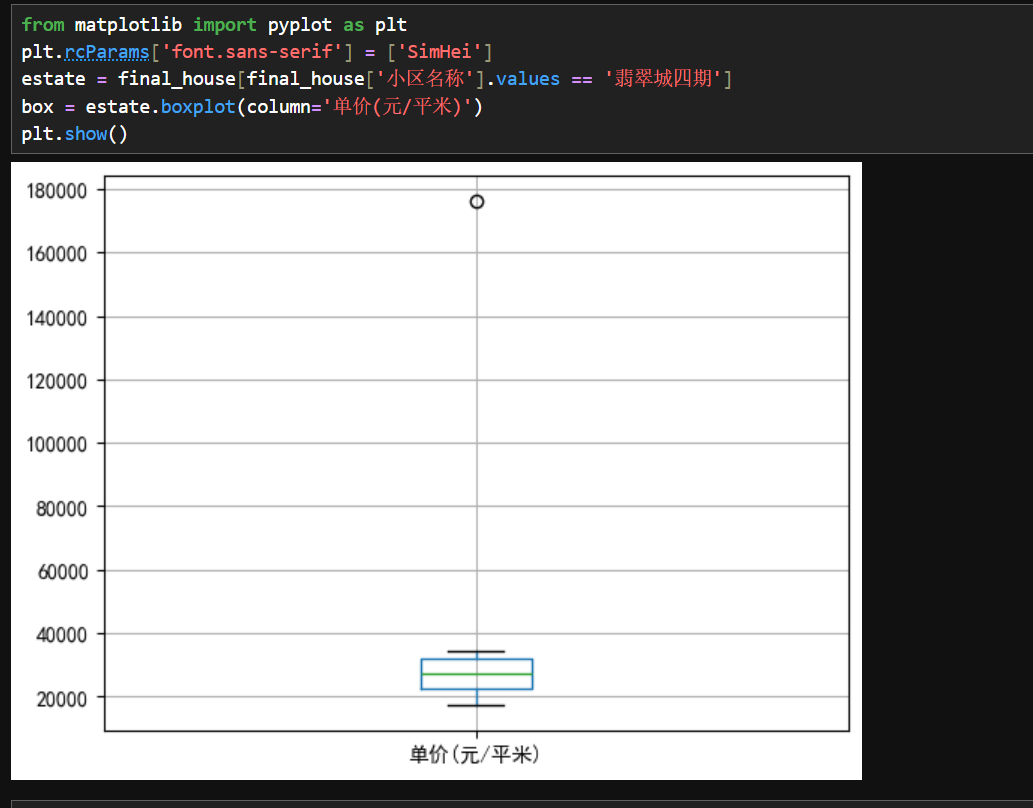
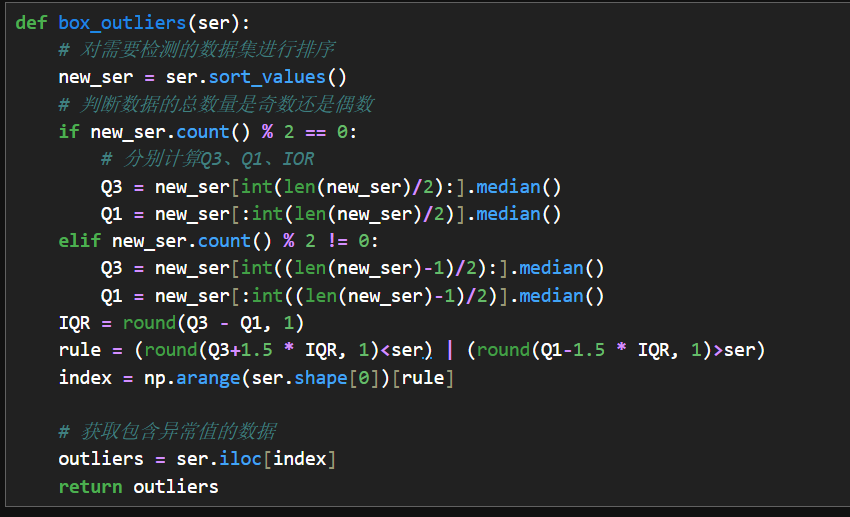
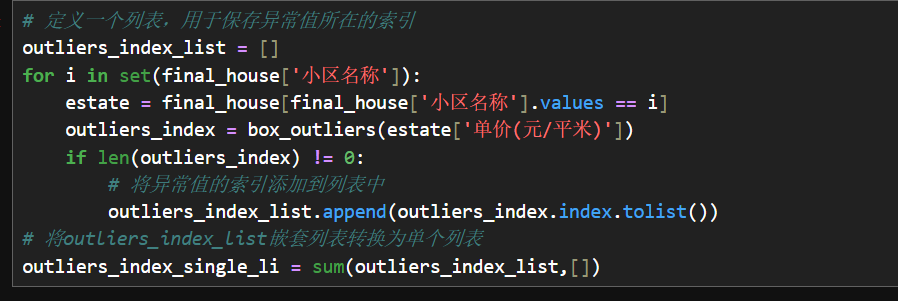
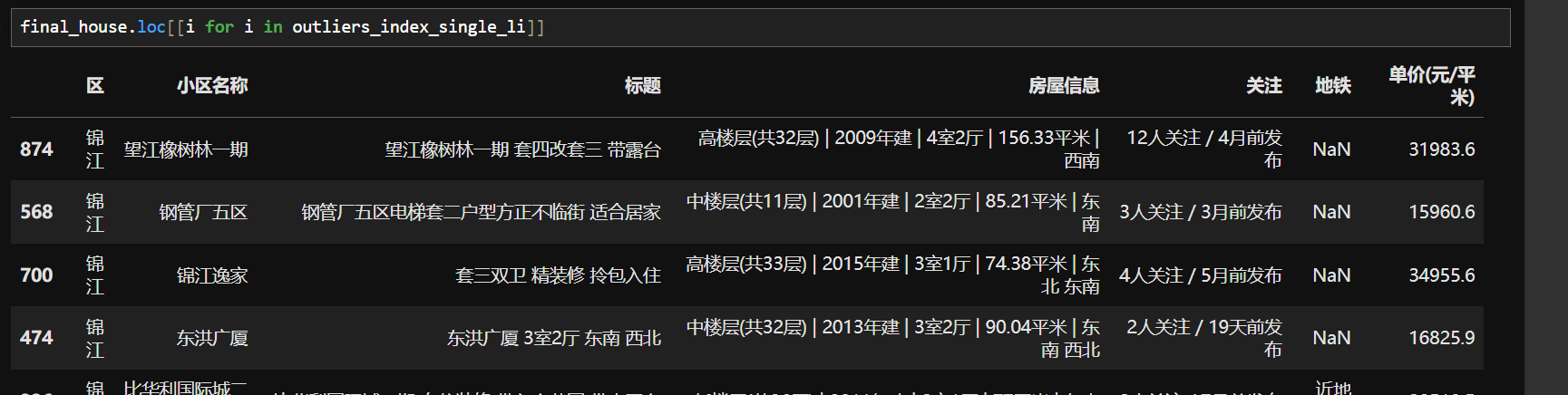
3.箱形图检测
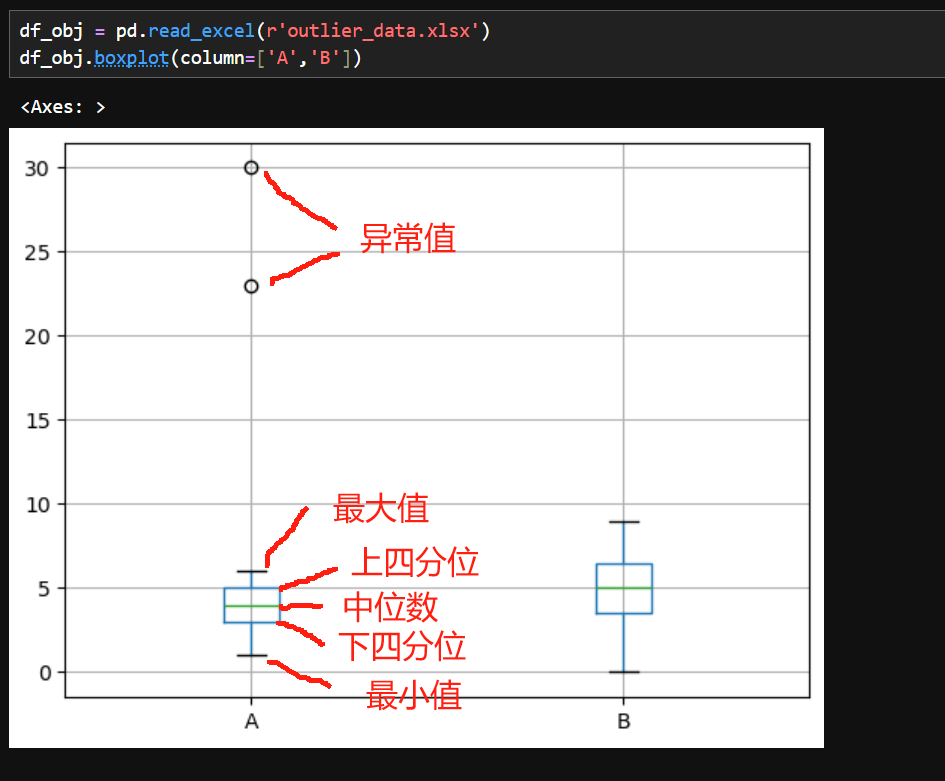
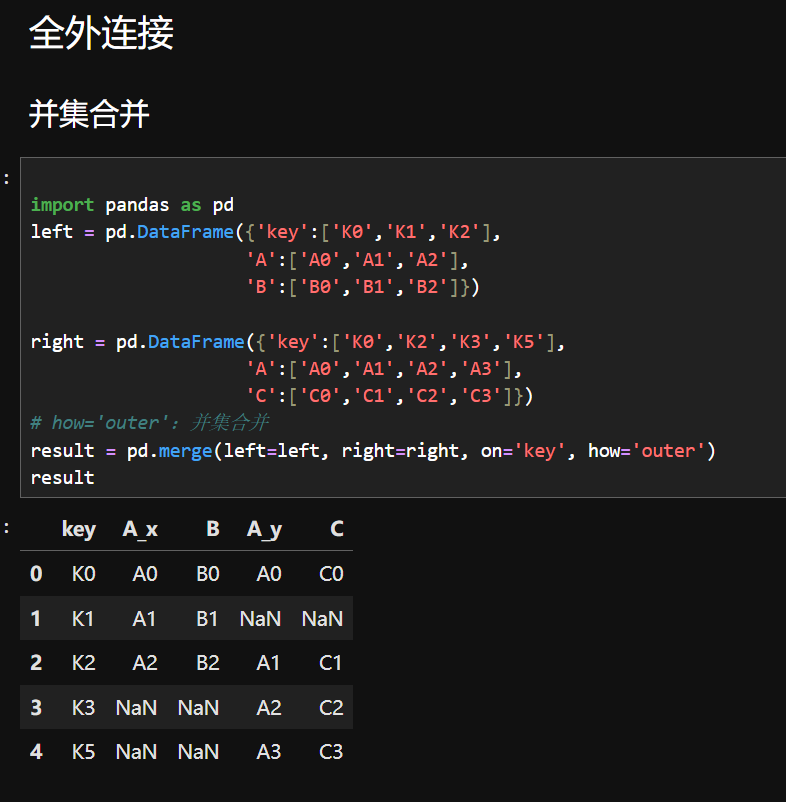
六、数据合并
| 维度 | 横向堆叠(列合并) | 纵向堆叠(行合并) |
|---|---|---|
| 方向 | 左右扩展(新增列) | 上下扩展(新增行) |
| 核心操作 | JOIN(内连接、外连接等)、merge、concat(axis=1) | UNION、UNION ALL、concat(axis=0) |
| 关键条件 | 需通过 “键” 对齐列(可能存在列名冲突) | 需列结构一致(列数、列名相同或可自动对齐) |
| 连接策略 | 外连接(横向操作) | 内连接(横向操作) |
|---|---|---|
| 保留记录 | 至少一个表的所有记录,未匹配列填 NULL | 仅保留两表连接键完全匹配的记录 |
| 典型场景 | 保留所有数据(如客户全量信息,无论是否有消费记录) | 筛选交集数据(如同时存在于两个表中的用户) |
总结
- 横向堆叠是列合并,外连接是横向合并时保留非匹配记录的策略;
- 纵向堆叠是行合并,与内连接无直接关联(内连接属于横向合并的匹配策略)。
- 混淆点:内连接本质是横向操作(列合并 + 筛选行),而纵向堆叠是单纯的行追加,两者分属不同数据合并维度。
pd.concat(
objs, # 需要合并的对象列表(DataFrame/Series)
axis=0, # 合并方向:0=纵向(默认),1=横向
join='outer', # 连接方式:'outer'(默认)外连接(并集)或 'inner'内连接(交集)
ignore_index=False, # 是否重置索引
keys=None, # 创建多层索引
sort=False, # 是否对列排序(axis=1 时)
verify_integrity=False # 是否检查重复索引
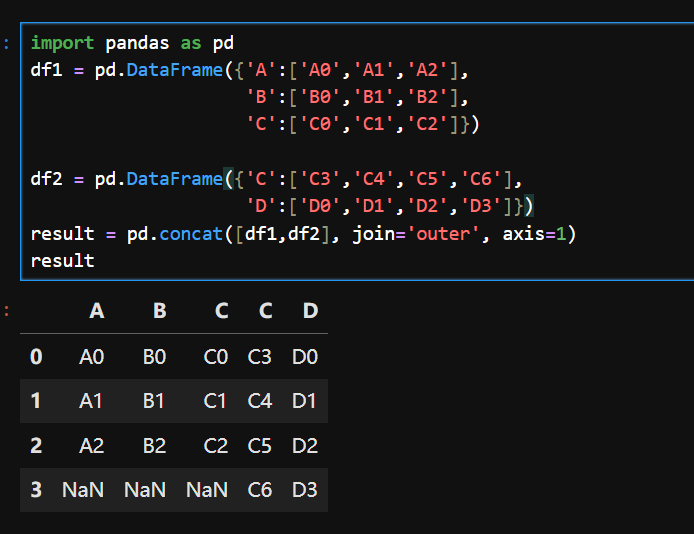
)1.横向堆叠与外连接(并集)
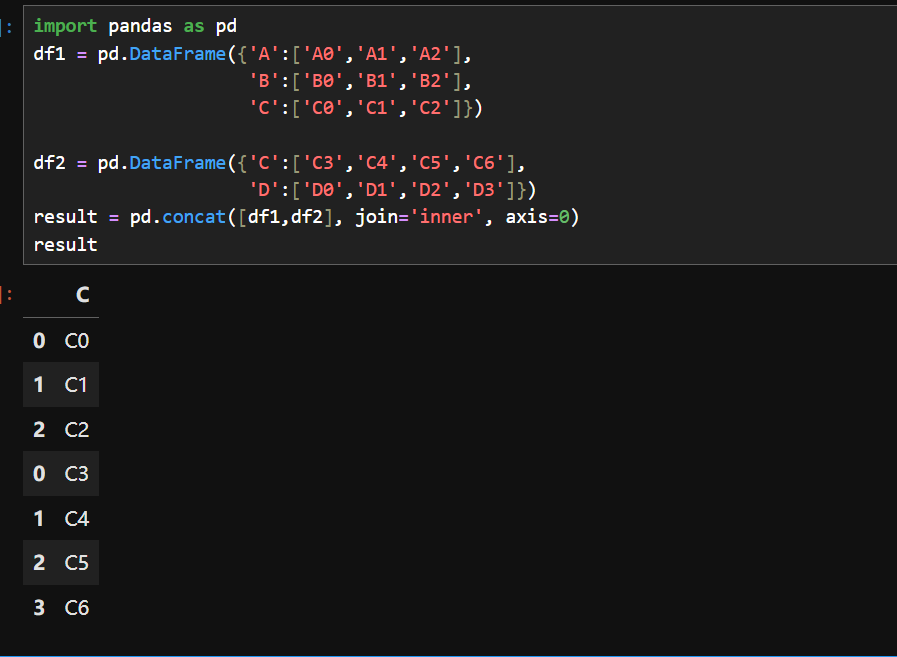
2.纵向堆叠与内连接(交集)
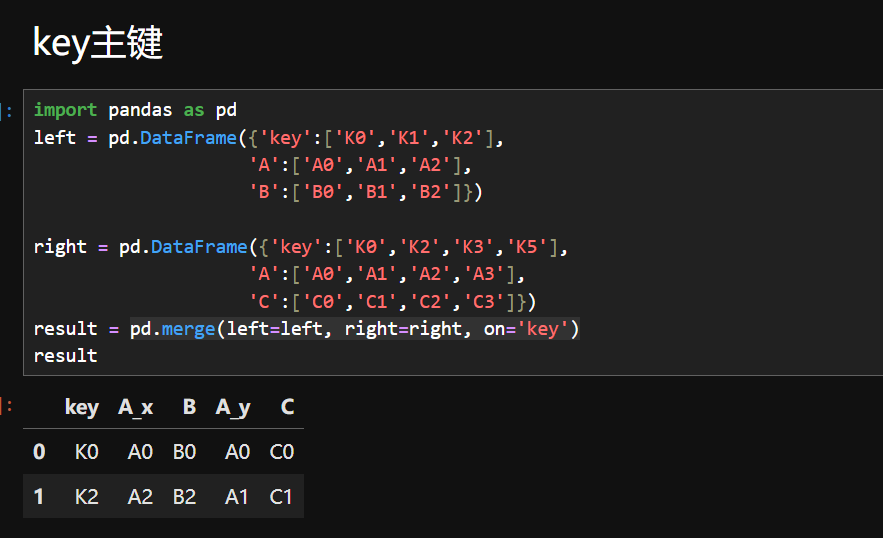
3.主键合并
pd.merge(
left, # 左侧 DataFrame
right, # 右侧 DataFrame
how='inner', # 连接方式:'inner'(默认)、'outer'、'left'、'right'
on=None, # 用于连接的列名(必须同时存在于左右 DataFrame 中)
left_on=None, # 左侧 DataFrame 中用于连接的列
right_on=None, # 右侧 DataFrame 中用于连接的列
left_index=False, # 是否使用左侧 DataFrame 的索引作为键
right_index=False, # 是否使用右侧 DataFrame 的索引作为键
suffixes=('_x', '_y') # 用于区分重复列的后缀
)与其他合并函数的对比
| 函数 | 核心特点 | 适用场景 |
|---|---|---|
pd.merge() | 按键连接,支持多种连接类型(SQL 风格) | 基于共同列合并数据 |
pd.concat() | 按行 / 列堆叠,支持多层索引 | 快速合并同结构数据 |
df.join() | 基于索引的快速合并(默认左连接) | 按索引合并多个 DataFrame |
内连接规则:仅保留 'key' 列在两表中都存在的值(K0 和 K2),以 left 的 key 为主,找共同有的元素

4.笛卡尔连接
关键点:on=‘key’
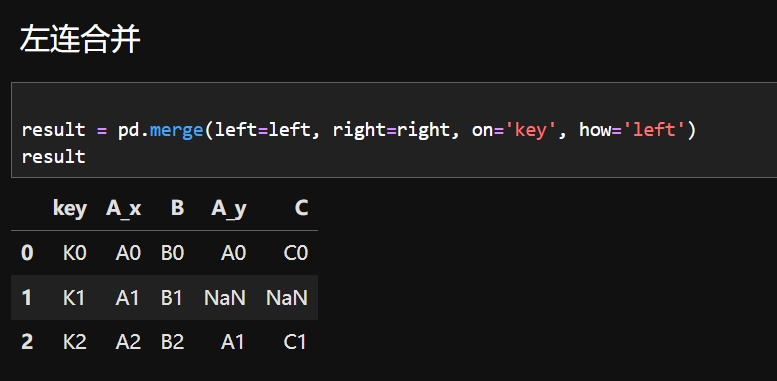
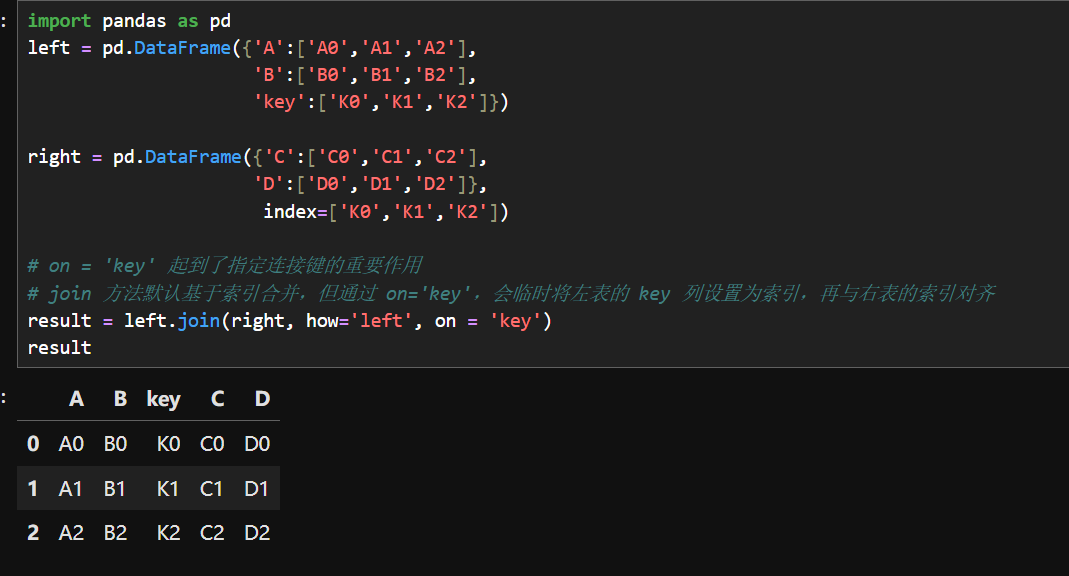
5.左连接合并
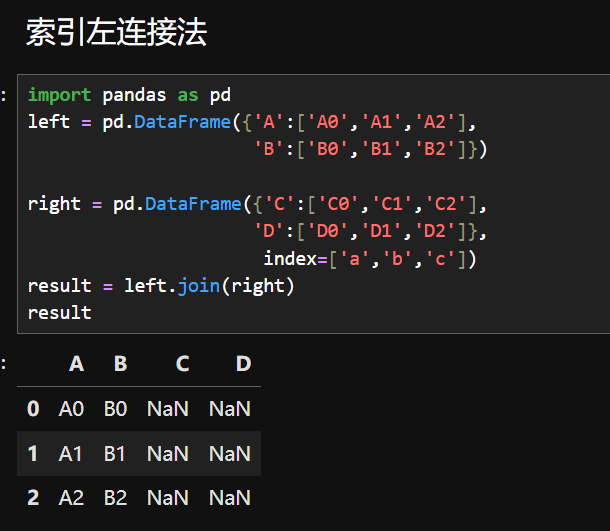
6.根据索引合并
为什么C和D的值的NaN?因为 right 的标签的 abc,不是012
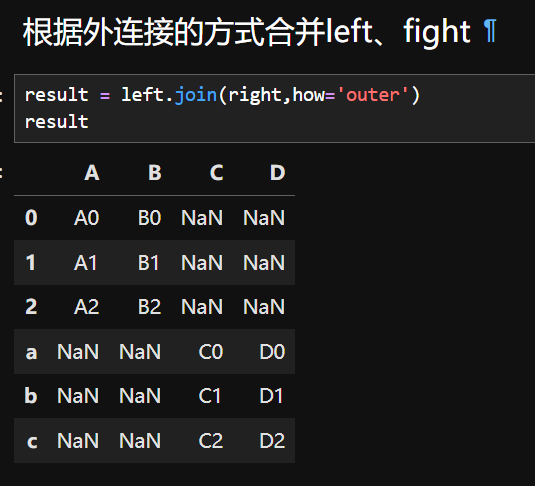
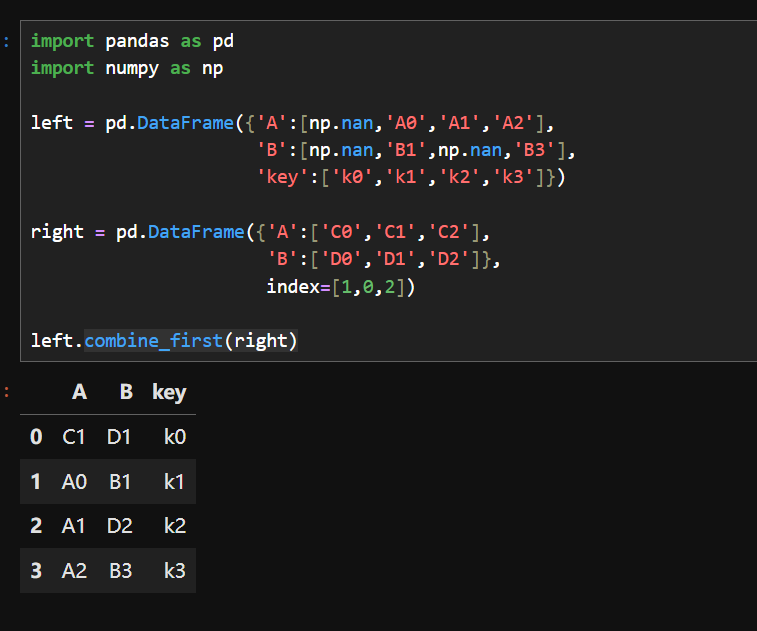
7.合并重叠数据
基本语法
df1.combine_first(df2) # 用 df2 的值填充 df1 的缺失值注意:right的标签顺序
七、数据重塑
| 方法 | 转换方向 | 作用 |
|---|---|---|
stack() | 列 → 行(宽 → 长) | 将列标签转为行索引(多级索引) |
unstack() | 行 → 列(长 → 宽) | 将行索引转为列标签(常用于逆操作) |
melt() | 多列 → 两列(id_vars + value_vars) | 将指定列保留为标识符,其余列转为值列 |
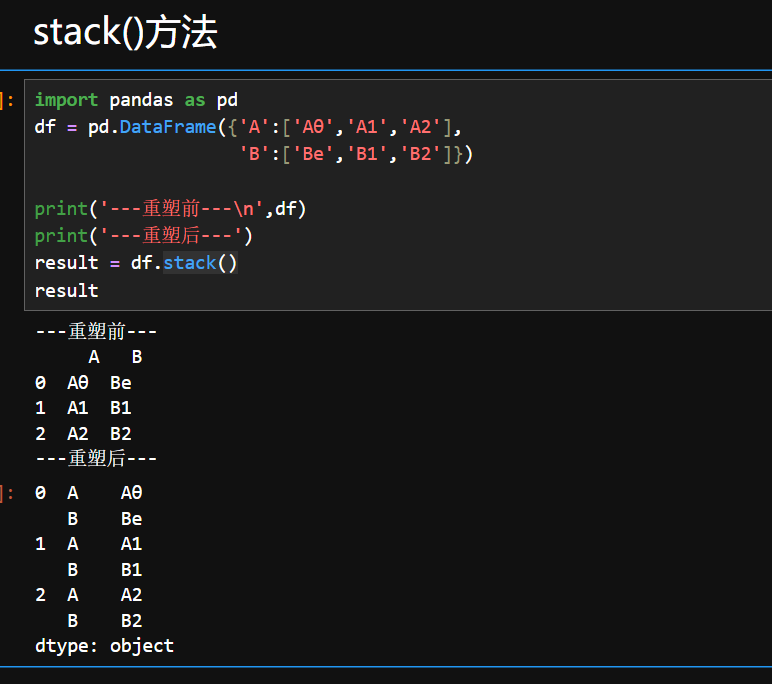
1.stack()方法
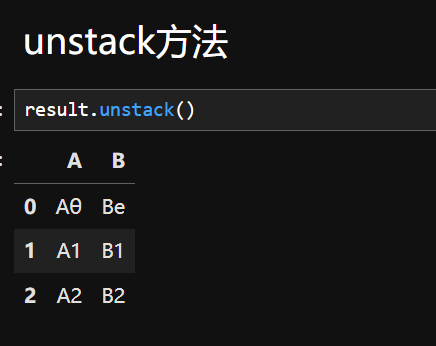
2.unstack()方法
3.重塑旋转
future_stack=True 是 Pandas 2.1.0 版本引入的一个参数,用于启用 stack() 方法的新实现逻辑。这个参数的出现是为了平滑过渡到未来版本中默认的 stack() 行为,避免旧代码在升级后产生意外结果。
新旧实现的核心差异
| 场景 | 旧实现( 默认 stack() ) | 新实现 stack(future_stack=True) |
|---|---|---|
| 处理缺失值(NaN) | 可能静默丢弃或保留 NaN,取决于索引对齐方式 | 严格保留所有索引,未匹配的值用 NaN 填充 |
| 多级索引堆叠 | 行为较宽松,可能导致索引层级混乱 | 强制保持索引层级的一致性,避免潜在的歧义 |
| 重复列名处理 | 允许重复列名,堆叠后可能生成重复的索引 | 强制要求列名唯一(否则抛出 ValueError) |
| 性能优化 | 某些情况下可能较慢 | 优化了内存使用和计算效率 |
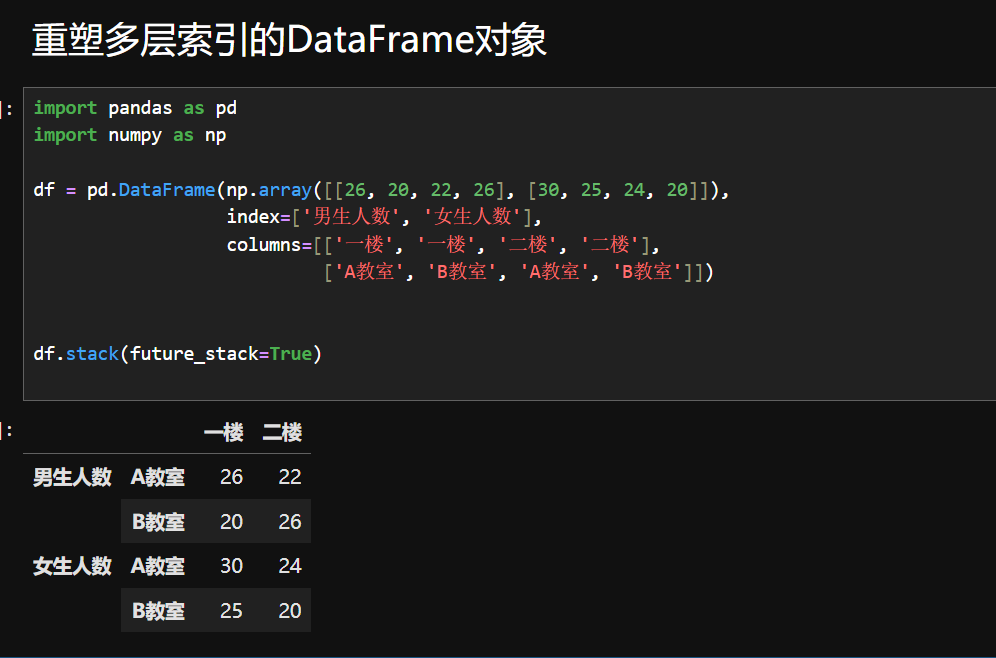
level=1 表示对列索引的第二层(“A 教室”“B 教室” 这一层)进行堆叠
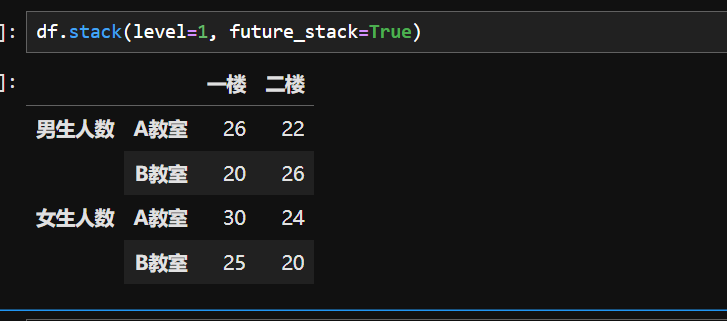
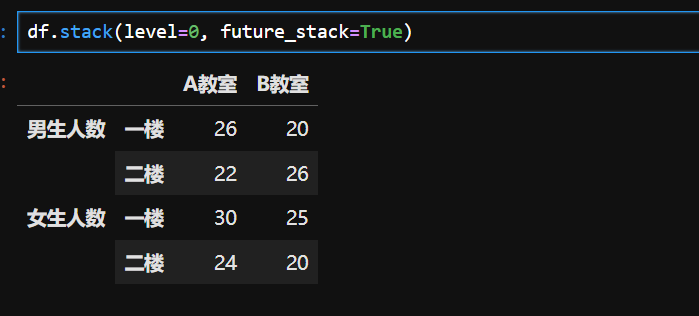
关键差异总结
| 参数 | 堆叠层级 | 结果索引层级 | 列维度保留情况 |
|---|---|---|---|
level=-1(默认) | 所有列索引层级 | 原行索引 + 所有列层级 | 无(全部转为行) |
level=1 | 仅第 1 层列索引 | 原行索引 + 第 1 层列索引 | 第 0 层列索引保留为列 |
核心作用
- 列转行:将 DataFrame 中指定层级的列索引(若有多级列索引)移动到行索引,形成多级行索引。
- 结构转换:例如,原数据中某几列代表不同分类的指标,堆叠后这些分类指标转为行的一部分,数据整体更 “长” 更 “窄”。
4.轴向旋转
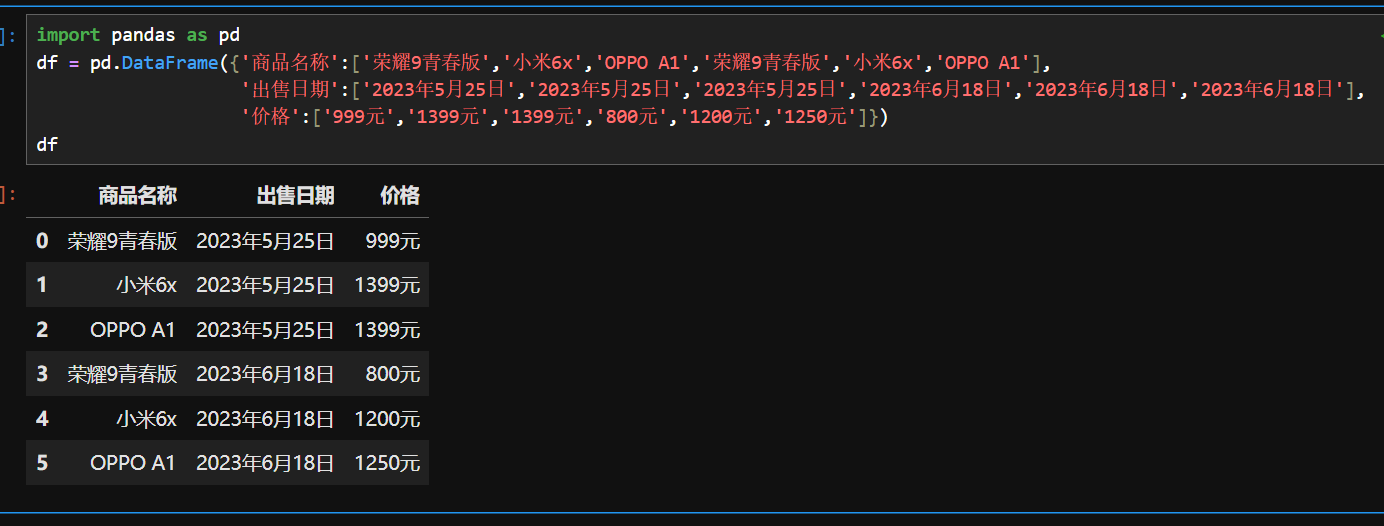
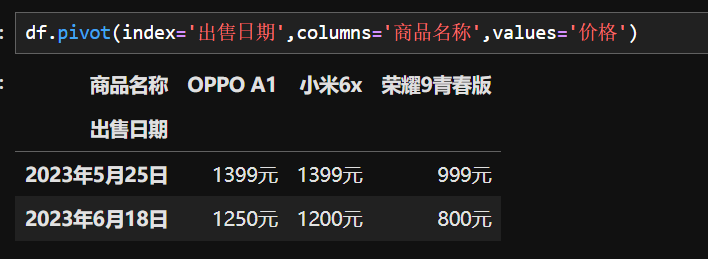
pivot() 是数据处理中用于重塑数据结构的函数,常见于 Pandas 库,作用类似 “透视表”,能将数据从长格式转换为宽格式,便于分析。
Pandas 中 pivot() 的语法与参数
- 语法:
pivot(index=None, columns=None, values=None) → DataFrame - 参数说明:
index:指定一列作为新 DataFrame 的行索引。columns:指定一列的值作为新 DataFrame 的列名(必须传值)。values:指定一列作为新 DataFrame 的值(可选,若省略,原 DataFrame 的列会保留在结果中)。
形成一个直观的手机降价对比图
八、数据转换
1.面元划分
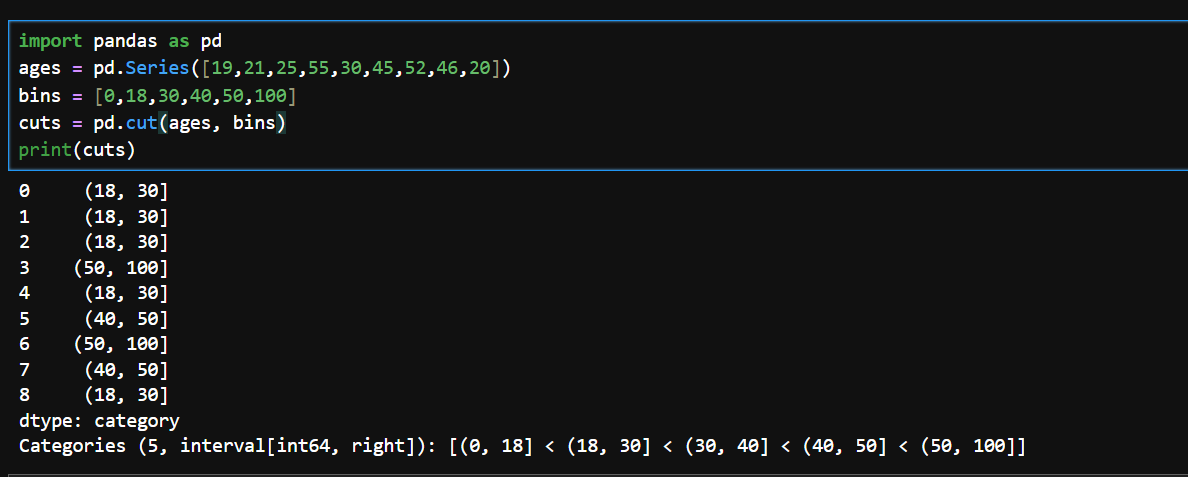
pd.cut()是 Pandas 库中用于将连续型数值数据切分为离散区间(分箱)的函数,常用于数据预处理、分组分析或可视化。通过设定区间规则,它能将连续值转换为分类数据(如将年龄分为 “青年”“中年”“老年”),便于进一步分析。
pd.cut()是 Pandas 中用于将连续型数据划分为离散区间(分箱)的函数,其参数说明如下:
x
- 输入的一维数据(如
Series、数组或列表),是待分箱的数据源,必须为一维结构。
bins
- 定义分箱的依据,有三种形式:
- 若为 整数,表示将数据等宽划分为指定数量的区间(如
bins=3表示分成 3 个等宽区间)。- 若为 序列(如
[10, 20, 30]),按指定边界划分区间(区间默认为左开右闭,如(10,20])。- 若为 间隔索引(
IntervalIndex),需确保区间不重叠。
right
- 布尔值,默认为
True,表示区间是否包含右边界。
- 例:
bins=[1,2,3]且right=True时,区间为(1,2]、(2,3];若right=False,则为[1,2)、[2,3)。
labels
- 为分箱指定标签,需与分箱数量一致。
- 若为 数组,标签直接对应每个区间(如
labels=['低','中','高'])。- 若为
False,则返回数据所在区间的整数指示(如0,1,2表示第 1、2、3 个区间)。
retbins
- 布尔值,默认为
False。若设为True,除返回分箱结果外,还会返回区间边界。
precision
- 整数,默认
3,用于指定区间边界的小数精度(如precision=2表示保留两位小数)。
include_lowest
- 布尔值,默认为
False,表示区间左边界是否闭合。
- 例:
bins=[10,20]且include_lowest=True时,左区间为[10,20](否则为(10,20])。
duplicates
- 处理分箱临界值重复的方式,可选
'raise'(默认,重复时报错)或'drop'(忽略重复边界)。
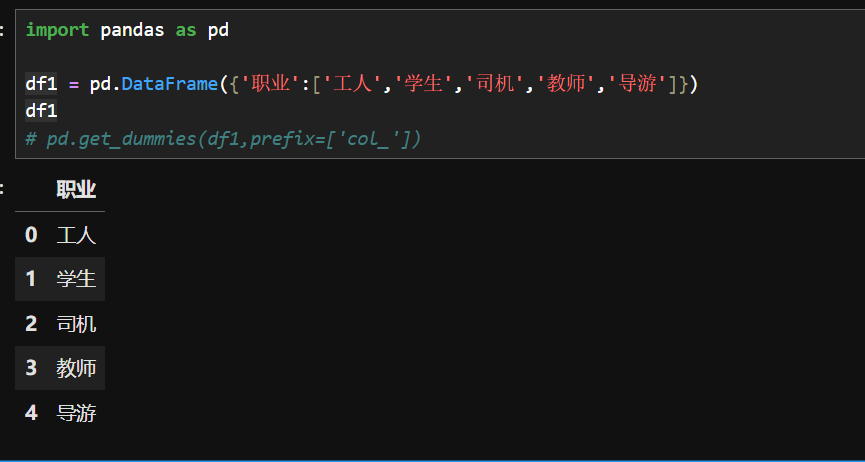
2.哑变量处理
哑变量处理(Dummy Variable Treatment)是将分类变量(如性别、职业、商品类别等非数值型变量)转换为若干个二元变量(取值为 0 或 1)的过程。其核心目的是将定性的分类信息转化为数值形式,使机器学习、统计分析等模型能够有效处理这些数据。例如,性别变量有 “男”“女” 两类,可生成一个哑变量(1 代表男,0 代表女);若分类变量有n个类别,通常生成\(n-1\)个哑变量(以其中一个类别作为参照),避免多重共线性。
pd.get_dummies()是 Pandas 中用于将分类变量转换为哑变量(虚拟变量)的函数,其常见参数如下:
data
- 必选参数,输入需要进行哑变量转换的数据,支持
Series、DataFrame或类似数组(array-like)的结构。
prefix
- 可选参数,用于定义哑变量列名的前缀。可以是字符串、字符串列表或字典(键为列名,值为对应前缀)。例如,设置
prefix='cat',生成的哑变量列名可能为cat_类别1、cat_类别2。
prefix_sep
- 可选参数,默认为
'_',用于连接前缀和原始列名(当前缀存在时)。如prefix='cat'且prefix_sep='/',列名可能为cat/类别1。
dummy_na
- 可选参数,布尔值,默认为
False。若设为True,会为缺失值(NaN)单独生成一列(值为1表示该样本为缺失值,否则为0)。
columns
- 可选参数,指定需要进行哑变量编码的列。若为
None(默认),则对所有object、string或category数据类型的列进行转换。
sparse
- 可选参数,布尔值,默认为
False。若设为True,返回的哑变量数据将以稀疏矩阵形式存储,用于节省内存(适用于大量零值的场景)。
drop_first
- 可选参数,布尔值,默认为
False。若设为True,会删除每个分类变量的第一个类别对应的哑变量列,以避免多重共线性(常用于回归分析等场景)。
dtype
- 可选参数,指定生成的哑变量列的数据类型(如
np.uint8、bool等),默认为np.uint8。
以下操作基于上面练习的实操,所需的两个资源已经放在资源包里了
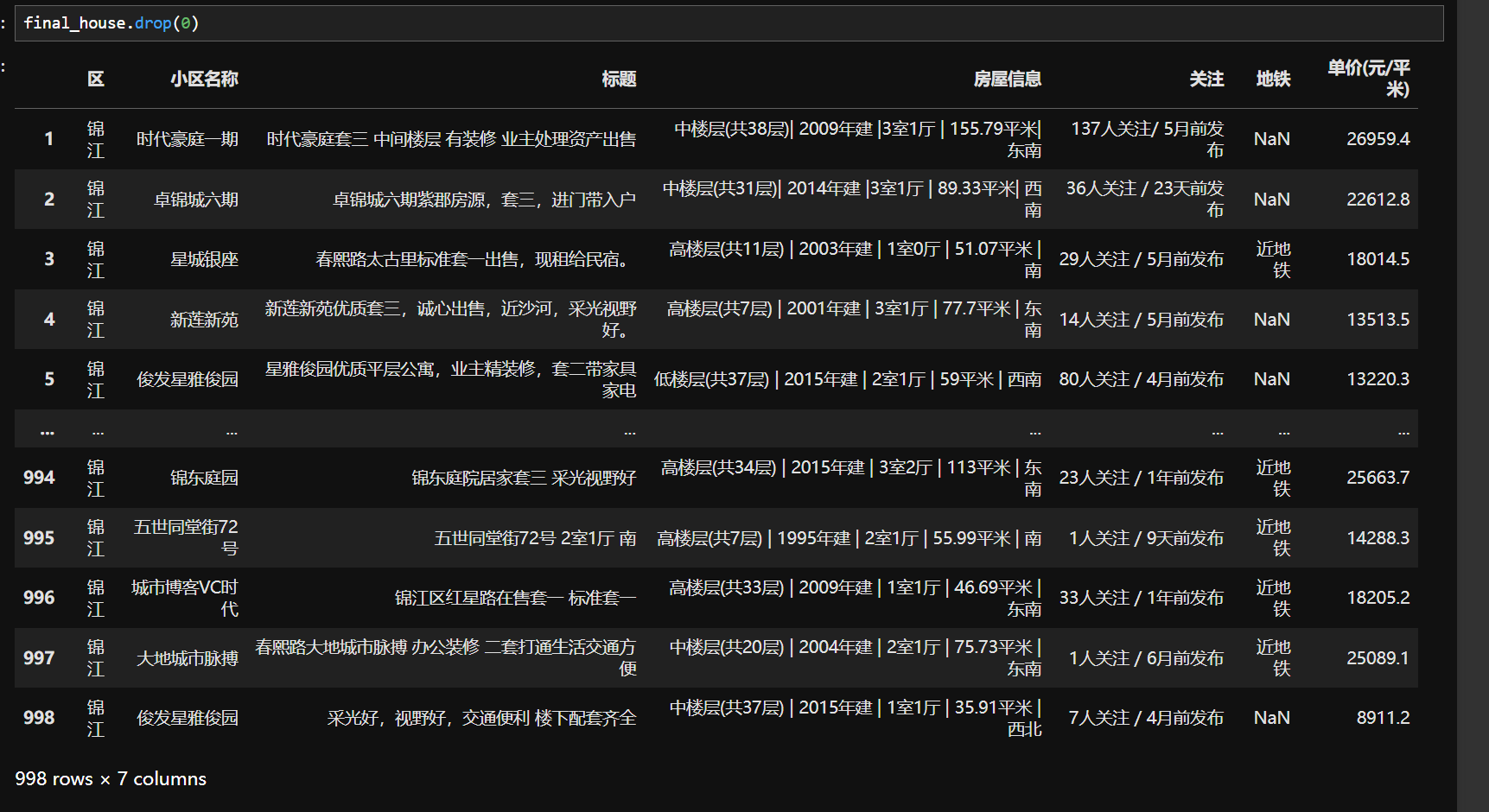
九、预处理二手房数据(综合案例)
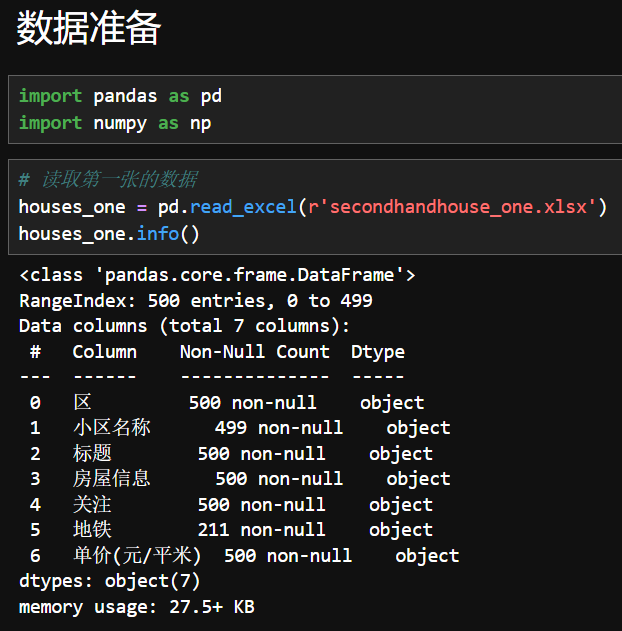
1.查看数据1
2.查看数据2
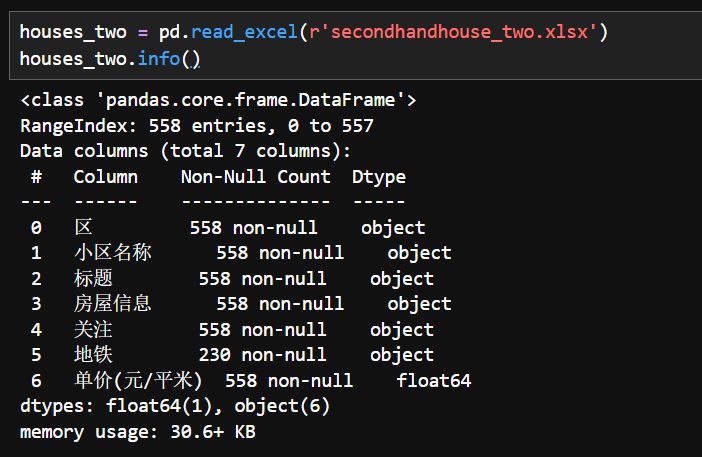
3.数据统一
因为数据表的数据不一致
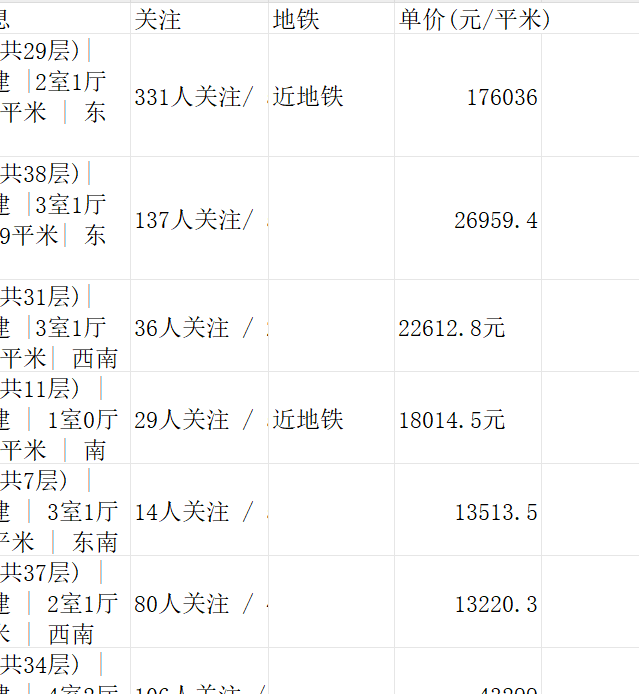
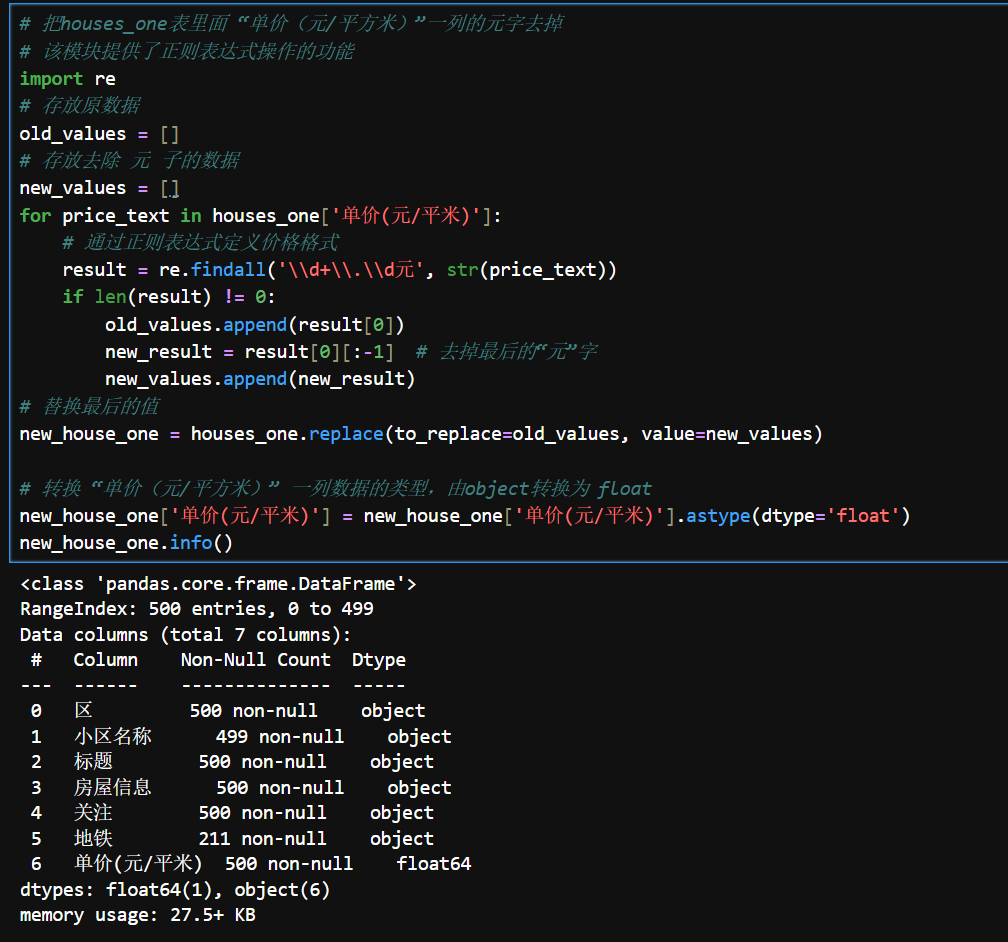
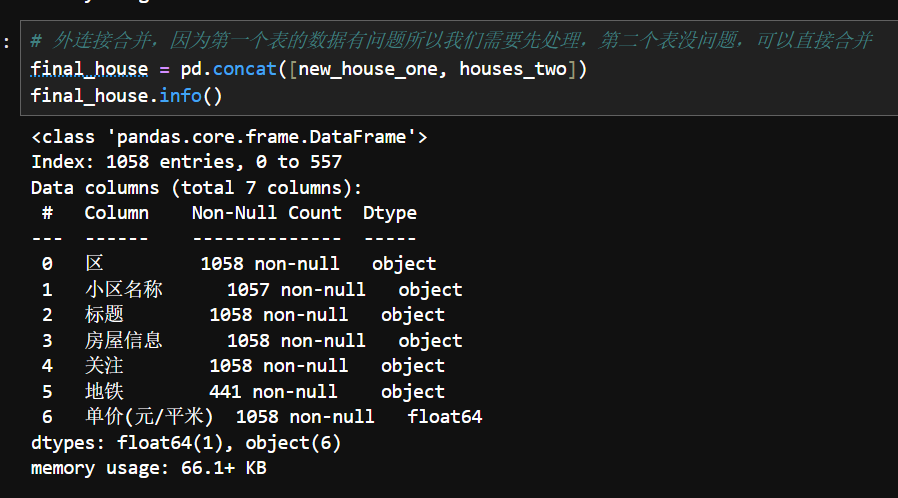
4.数据合并
5.缺失值处理
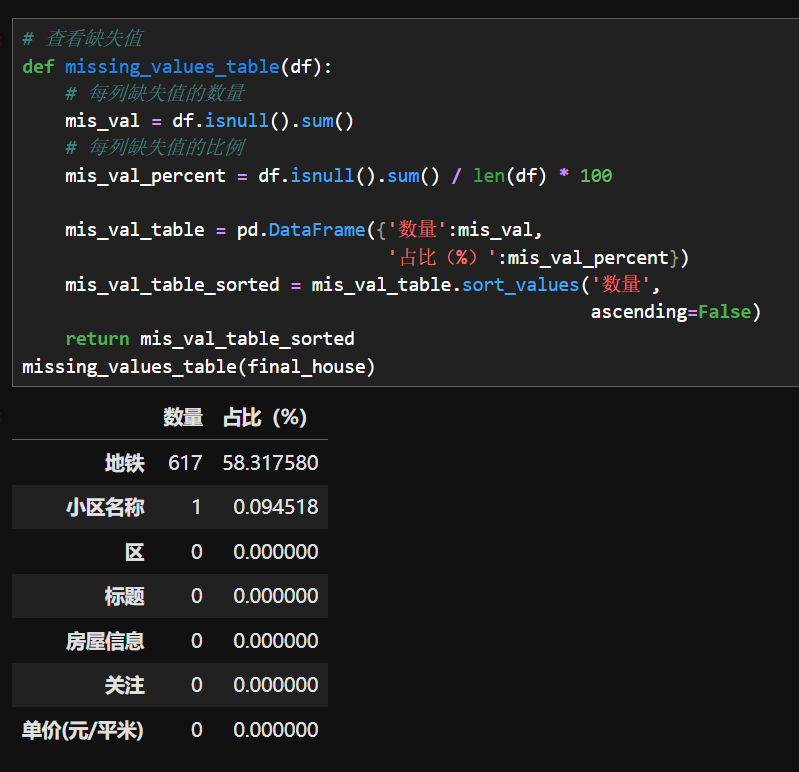

6.重复值处理
7.异常值处理