目录
一、Kafka 是什么
二、Kafka 的基础概念
2.1 核心术语解读
2.2 工作模式剖析
三、Kafka 的应用场景
四、Kafka 与其他消息队列的比较
五、Kafka 的安装与配置
5.1 环境准备
5.2 安装步骤
5.3 常见问题及解决
六、Kafka 的基本操作
6.1 命令行工具使用
6.1.1 主题管理
6.1.2 消息生产与消费
6.1.3 消费者组管理
6.2 Java 代码示例
6.2.1 Kafka 生产者
6.2.2 Kafka 消费者
七、总结与展望
一、Kafka 是什么
在当今数字化时代,数据如同汹涌澎湃的浪潮,不断产生和流动。为了应对数据洪流带来的挑战,分布式消息系统应运而生,而 Kafka 就是其中的佼佼者,被誉为分布式消息系统的“中流砥柱”。它是一个开源的分布式事件流平台,最初由 LinkedIn 公司开发,后来成为 Apache 软件基金会的顶级项目。凭借高吞吐量、低延迟、可扩展性强等特点,Kafka 被广泛应用于大数据处理、日志收集、实时监控等领域,超过 80% 的世界 500 强公司都在使用它。
二、Kafka 的基础概念
2.1 核心术语解读
在深入探索 Kafka 的工作原理之前,我们先来认识一些 Kafka 的核心术语,它们是理解 Kafka 的基石。
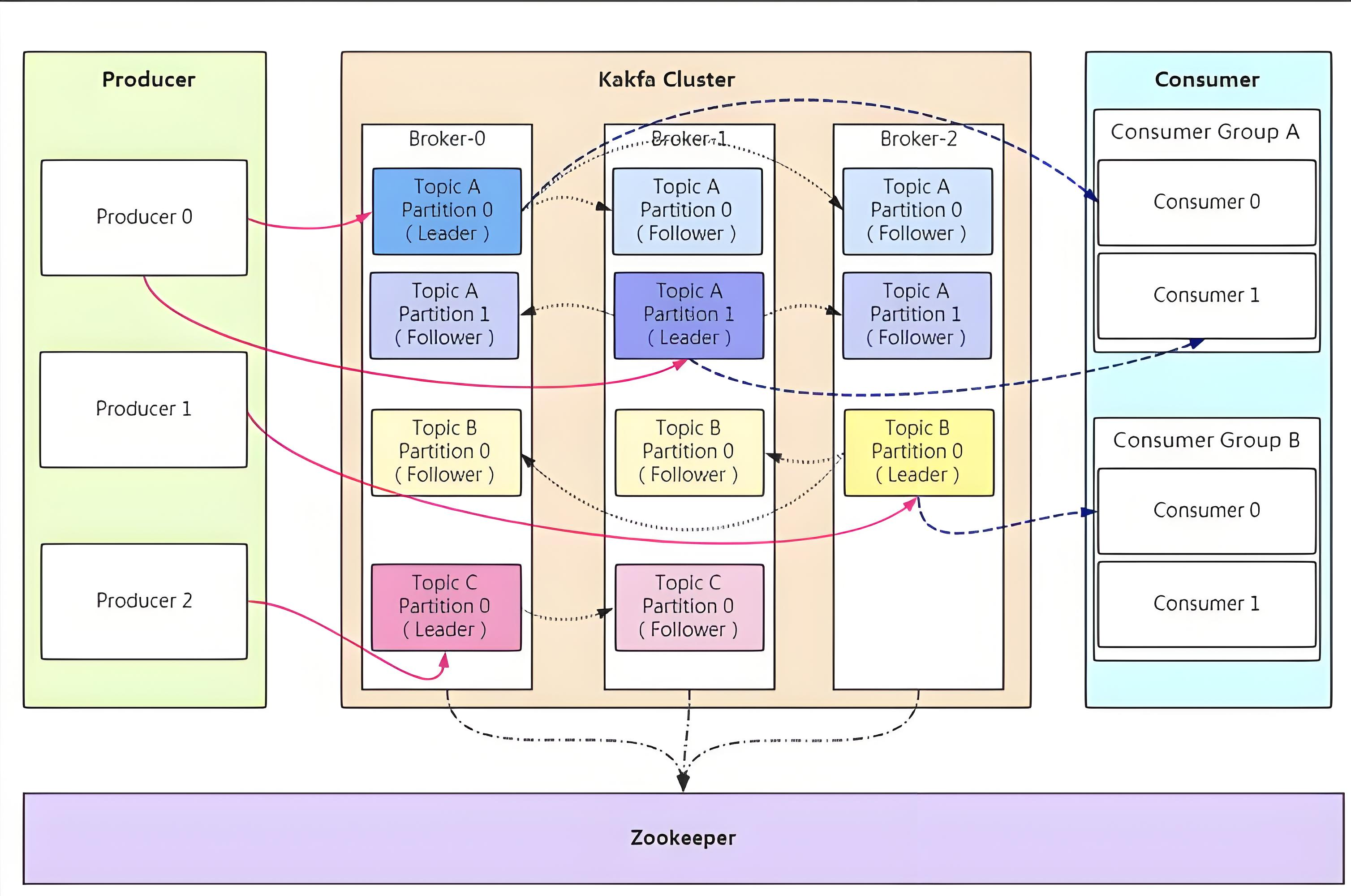
Broker:Kafka 集群中的一台服务器就是一个 Broker,它就像是一个大型的仓库管理员,负责接收、存储和发送消息。多个 Broker 可以组成一个 Kafka 集群,共同承担数据处理的重任,实现高可用性和可扩展性。比如,一个拥有 5 个 Broker 的 Kafka 集群,可以更好地应对大量消息的涌入,即使其中某个 Broker 出现故障,其他 Broker 也能继续提供服务,确保数据的可靠存储和传输。
Topic:可以将其理解为一个消息的分类标签,是承载消息的逻辑容器。不同类型的消息可以发送到不同的 Topic,就像将不同种类的物品存放在不同的仓库区域。例如,我们可以创建一个名为“user_behavior”的 Topic,专门用于存储用户行为相关的消息,如用户的登录、浏览、购买等操作记录。这样,生产者在发送消息时,就可以将用户行为消息发送到这个 Topic 中,而消费者也可以从这个 Topic 订阅并获取这些消息,实现消息的分类管理和高效处理。
Partition:Partition 是 Topic 物理上的分组,一个 Topic 可以分为多个 Partition,每个 Partition 是一个有序的队列。它就像是仓库中的一个个货架,每个货架上存放着属于同一类的消息。Partition 的存在使得 Kafka 能够实现水平扩展,将消息分布在不同的 Broker 上,提高数据处理的并行性和吞吐量。同时,每个 Partition 都有自己的 offset,用于唯一标识消息在 Partition 中的位置,确保消息的顺序性。例如,一个“user_behavior”的 Topic 可以分为 3 个 Partition,分别存储不同时间段或不同用户群体的行为消息,消费者可以根据自己的需求从不同的 Partition 中获取消息。
Producer:消息的生产者,是负责向 Kafka 的 Topic 发送消息的应用程序。就像工厂里的生产工人,源源不断地生产消息并发送到 Kafka 这个“消息工厂”中。Producer 在发送消息时,可以指定消息发送到哪个 Topic,以及是否需要指定 Partition 等参数。例如,一个电商应用中的订单生成模块,就可以作为 Producer,在用户下单后,将订单相关的消息发送到“order_topic”中,供后续的订单处理系统进行消费和处理。
Consumer:消息的消费者,是从 Kafka 的 Topic 订阅并消费消息的应用程序。它类似于仓库的取货员,从 Kafka 中获取自己需要的消息进行处理。Consumer 可以订阅一个或多个 Topic,按照自己的节奏从 Topic 中拉取消息。同时,Consumer 还可以组成 Consumer Group,实现消息的负载均衡和重复消费控制。例如,一个数据分析系统可以作为 Consumer,订阅“user_behavior”和“order_topic”等多个 Topic,获取用户行为和订单消息,进行数据分析和挖掘,为企业决策提供支持。
Consumer Group:多个消费者实例组成的一个组,它们共同消费一组 Topic 的消息。每个 Partition 在同一时间只会被 Consumer Group 中的一个 Consumer 消费,这样可以实现消息的负载均衡,提高消费效率。比如,在一个实时监控系统中,有多个 Consumer 实例组成一个 Consumer Group,共同消费“system_monitoring”Topic 的消息,每个 Consumer 负责处理一部分消息,确保系统能够及时响应和处理大量的监控数据。
2.2 工作模式剖析
Kafka 采用发布 - 订阅的工作模式,这种模式使得消息的生产、存储和消费过程高效而有序。
消息生产:Producer 将消息发送到指定的 Topic。在发送过程中,Producer 首先会对消息进行序列化,将消息对象转换为字节数组,以便在网络中传输。然后,根据消息的 Key 或其他分区策略,将消息分配到对应的 Partition 中。如果消息没有指定 Key,Producer 会使用轮询算法将消息平均分配到各个 Partition。例如,一个日志收集系统作为 Producer,将收集到的日志消息发送到“log_topic”中,根据日志的类型或来源等信息,将不同的日志消息分配到不同的 Partition,实现日志的分类存储和管理。
消息存储:Kafka 的 Broker 接收到 Producer 发送的消息后,会将消息追加到对应 Partition 的日志文件中。为了防止日志文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 Partition 分为多个 Segment,每个 Segment 对应两个文件:“.index”索引文件和“.log”日志文件。“.index”文件存储大量的索引信息,索引信息按照数组的逻辑排列,指向对应数据文件中 message 的物理偏移地址;“.log”文件存储大量的数据,数据直接紧密排列。这样,通过索引文件可以快速定位到消息在日志文件中的位置,提高数据读取的效率。例如,当 Broker 接收到“user_behavior”Topic 中某个 Partition 的消息时,会将消息追加到该 Partition 对应的日志文件中,并更新索引文件,以便后续消费者能够快速获取消息。
消息消费:Consumer 从指定的 Topic 订阅消息。Consumer 在消费消息时,会向 Broker 发送拉取请求,Broker 根据 Consumer 的请求,从对应的 Partition 中读取消息并返回给 Consumer。Consumer 在消费消息的过程中,会记录自己的消费位置,即 offset,以便在下次消费时能够从上次的位置继续消费,保证消息的顺序性和不重复消费。同时,Consumer 还可以根据自己的需求,选择从最早的消息开始消费,或者从最新的消息开始消费。例如,一个实时报表系统作为 Consumer,订阅“sales_data”Topic 的消息,从 Broker 中拉取最新的销售数据消息,进行报表生成和展示,为企业的销售决策提供实时数据支持。
在 Kafka 的工作模式中,还有一些重要的特性和机制。比如,Kafka 的副本机制,每个 Partition 都可以配置多个副本,其中一个副本作为 Leader,负责处理读写请求,其他副本作为 Follower,从 Leader 同步数据。当 Leader 出现故障时,Kafka 会自动从 Follower 中选举出一个新的 Leader,保证数据的可用性和一致性。另外,Kafka 还支持消息的批量发送和消费,通过批量处理可以减少网络开销,提高系统的吞吐量。
三、Kafka 的应用场景
Kafka 凭借其卓越的性能和强大的功能,在众多领域都有着广泛的应用场景,为企业和开发者提供了高效的数据处理解决方案。
日志收集与管理:在大型分布式系统中,各个组件和服务会产生大量的日志数据,这些日志蕴含着丰富的系统运行信息、用户行为数据等,对于系统的监控、故障排查、数据分析等具有重要价值。Kafka 可以作为一个统一的日志收集平台,高效地收集来自不同服务器、不同应用的日志消息。通过 Kafka,这些日志数据能够以统一的接口服务方式开放给各种消费者,如 Flink、Hadoop、Hbase、ElasticSearch 等。例如,在一个拥有多个微服务的电商系统中,每个微服务的日志都可以发送到 Kafka 的特定 Topic 中,然后使用 ElasticSearch 进行日志索引和存储,通过 Kibana 进行可视化查询和分析,方便运维人员快速定位系统故障和性能瓶颈。
消息队列与异步通信:Kafka 作为消息队列,能够实现不同系统间的解耦和异步通信。在电商系统中,订单系统、支付系统、库存系统等各个模块之间可以通过 Kafka 进行通信。当用户下单后,订单系统将订单消息发送到 Kafka 的“order_topic”中,支付系统和库存系统可以从该 Topic 中订阅消息并进行相应的处理。这样,各个系统之间不需要直接相互调用,降低了系统的耦合度,提高了系统的灵活性和可扩展性。同时,Kafka 还可以缓存消息,在系统高峰期时,能够有效地削峰填谷,保证系统的稳定性。
用户活动跟踪与分析:Kafka 经常被用来记录 Web 用户或者 App 用户的各种活动,如浏览网页、搜索、点击、购买等。这些活动信息被各个服务器发布到 Kafka 的 Topic 中,然后消费者通过订阅这些 Topic 来做实时的监控分析,也可以将数据保存到数据库中进行后续的深度挖掘。以淘宝为例,用户在淘宝 App 上的每一次操作,包括商品搜索、浏览商品详情、加入购物车、下单支付等行为,都会产生相应的消息并发送到 Kafka 中。通过对这些消息的实时分析,淘宝可以实现个性化推荐、实时营销活动推送等功能,提升用户体验和购物转化率。
实时数据处理与分析:在大数据时代,实时数据处理和分析的需求日益增长。Kafka 可以与 Spark Streaming、Storm、Flink 等流处理框架集成,作为实时数据处理系统的数据源或数据输出。电商平台可以实时收集订单数据、用户行为数据等,通过 Kafka 将这些数据传输到 Flink 中进行实时分析,如实时统计商品销量、用户活跃度、订单转化率等指标,为企业的运营决策提供实时的数据支持。同时,还可以根据实时分析的结果,实现实时的风险预警和异常检测,及时发现并处理潜在的问题。
运营指标监控与报警:Kafka 也常用于记录运营监控数据,包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。在一个大型的数据中心,服务器的 CPU 利用率、内存使用率、磁盘 I/O 等性能指标可以通过监控工具采集后发送到 Kafka 的“server_performance_topic”中。监控应用程序从该 Topic 中订阅消息,对这些指标进行实时分析和可视化展示。当某个指标超出正常范围时,系统可以自动触发报警机制,通知运维人员及时采取措施,保障系统的正常运行。
四、Kafka 与其他消息队列的比较
在消息队列的领域中,Kafka 以其独特的优势在众多产品中脱颖而出,与传统的消息队列如 RabbitMQ、ActiveMQ 相比,有着显著的差异。
吞吐量对比:Kafka 的吞吐量堪称一绝,单机 TPS 可达百万条 / 秒级别。这得益于它的分布式架构和高效的存储机制,采用磁盘顺序读写和零拷贝技术,极大地提高了数据传输效率,每秒可以轻松处理几十万甚至数百万条消息。在大规模日志收集场景中,Kafka 可以快速接收和存储海量的日志数据,而不会出现性能瓶颈。相比之下,RabbitMQ 的吞吐量一般在万级,ActiveMQ 也处于类似水平,它们更侧重于对消息可靠性和灵活性的支持,在处理高并发、大数据量的场景时,性能表现不如 Kafka。
持久性与可靠性:Kafka 将消息持久化到本地磁盘,并且支持数据备份,通过多副本机制和 ISR(In - Sync Replicas)同步策略,确保在部分节点故障时数据不丢失,保障了数据的高可靠性。在电商订单处理中,即使某个 Broker 节点出现故障,订单消息也不会丢失,依然能够被正确处理。而 RabbitMQ 通过消息确认机制和持久化队列来保证消息可靠性,但在大规模数据和高并发情况下,其可靠性保障的成本相对较高;ActiveMQ 虽然支持消息的持久化和事务处理,但在高并发场景下,性能和可靠性会受到一定影响。
可扩展性:Kafka 集群支持热扩展,只需简单地添加新的 Broker 节点,就可以轻松应对不断增长的数据量和并发请求,实现水平扩展,并且 Broker、Producer、Consumer 都原生自动支持分布式,自动实现负载均衡。当一个互联网公司业务量快速增长时,Kafka 集群可以方便地进行扩展,以满足数据处理的需求。而 RabbitMQ 在集群扩展方面相对复杂,需要进行较多的配置和管理工作;ActiveMQ 的集群实现也较为繁琐,扩展性不如 Kafka 灵活。
延迟性:Kafka 的延迟最低可达几毫秒,能够满足大多数实时性要求较高的场景。在实时监控系统中,Kafka 可以快速地将监控数据传输给消费者,以便及时做出响应。RabbitMQ 的延迟通常在毫秒级,相对较低,但在高负载情况下,延迟可能会有所增加;ActiveMQ 的延迟表现与 RabbitMQ 类似,在处理大量消息时,延迟可能会变得不可忽视。
功能特性:Kafka 专注于分布式流处理,提供了丰富的流处理 API,适合构建实时数据处理和分析系统。RabbitMQ 支持多种消息协议,如 AMQP、XMPP、SMTP、STOMP 等,具有灵活的路由功能,通过 Exchange 和 Binding 机制,可以实现复杂的消息路由规则,更适合复杂业务场景下的消息传递。ActiveMQ 同样支持多种协议,并且支持 XA 协议,可以和 JDBC 一起实现 2PC 分布式事务,但由于性能和复杂性等原因,在实际应用中较少使用。
五、Kafka 的安装与配置
5.1 环境准备
在安装 Kafka 之前,首先需要确保系统中已经安装了 Java 环境,因为 Kafka 是基于 Java 开发的,它依赖 Java 运行时环境(JRE)来执行。Kafka 对 Java 版本有一定的要求,建议安装 Java 8 及以上版本。你可以通过以下步骤来检查系统中是否已经安装了 Java 以及查看 Java 的版本:在命令行中输入“java -version”,如果系统已经安装了 Java,会显示 Java 的版本信息;如果未安装,则需要先安装 Java。
Java 的下载地址为:Oracle Java 下载,你可以根据自己的操作系统选择对应的 Java 安装包进行下载和安装。在安装过程中,按照安装向导的提示进行操作即可,安装完成后,还需要配置 Java 的环境变量,将 Java 的安装路径添加到系统的“PATH”环境变量中,以便在命令行中能够正确找到 Java 命令。
5.2 安装步骤
首先,访问 Apache Kafka 官方网站(https://kafka.apache.org/downloads)下载最新版本的 Kafka 二进制文件。
下载完成后,上传到服务器后进行解压:
tar -zxvf kafka_2.12-3.8.0.tgz -C /export/server配置 Kafka 的软链接:
ln -s /export/server/kafka_2.12-3.8.0 /export/server/kafka配置 KAFKA_HOME 环境变量,以及将$KAFKA_HOME/bin文件夹加入PATH环境变量中
vim /etc/profile尾部添加如下:
export KAFKA_HOME=/export/server/kafka
export PATH=:$PATH:${KAFKA_HOME}生效环境变量:
source /etc/profile在Kafka的 config 目录下存在相关的配置信息——本次我们只想让Kafka快速启动起来只关注 server.properties 文件即可:
cd ${KAFKA_HOME}/config
ls
#connect-console-sink.properties connect-file-source.properties consumer.properties server.properties
#connect-console-source.properties connect-log4j.properties kraft tools-log4j.properties
#connect-distributed.properties connect-mirror-maker.properties log4j.properties trogdor.conf
#connect-file-sink.properties connect-standalone.properties producer.properties zookeeper.properties打开配置文件,并主要注意以下几个配置:
vim server.properties
broker.id=0 #kafka服务节点的唯一标识,这里是单机不用修改
#listeners = PLAINTEXT://your.host.name:9092 别忘了设置成自己的主机名
listeners=PLAINTEXT://SHENYANG:9092 #kafka底层监听的服务地址,注意是使用主机名,不是ip。
# log.dirs 指定的目录 kafka启动时可以自动创建,因此不要忘了让kafka可以有读写这个目录的权限。
log.dirs=/export/server/kafka/data ##kafka的分区以日志的形式存储在集群中(其实就是broker数据存储的目录)
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168 #日志的留存策略,默认168小时也就是一周
# zookeeper 的连接地址 ,别忘了设置成自己的主机名,单机情况下可以使用 localhost
zookeeper.connect=SHENYANG:2181上述配置完成后就可以在单机环境下成功启动 Kafka了。
./bin/kafka-server-start.sh -daemon config/server.properties #后台启动kafka使用 jps 查看是否成功启动kafka:
jps
34843 QuorumPeerMain
21756 Jps
116076 Kafka单机启动完成。
5.3 常见问题及解决
端口冲突:如果在启动 Kafka 或 Zookeeper 时提示端口被占用,比如常见的 Zookeeper 端口 2181 或 Kafka 的 9092 端口被占用。可以使用命令“netstat -ano | findstr : 端口号”(在 Windows 系统中)或“lsof -i: 端口号”(在 Linux 系统中)来查看占用该端口的进程,然后根据进程信息关闭占用端口的程序,或者修改 Kafka 或 Zookeeper 的配置文件,将端口号改为其他未被占用的端口。
配置错误:如果在启动过程中出现因为配置文件错误导致的问题,比如配置文件中的参数拼写错误、格式不正确等。需要仔细检查“config/server.properties”和“config/zookeeper.properties”文件中的各项配置,确保参数的正确性和格式的规范性。例如,如果在配置 Zookeeper 连接地址时,地址或端口写错,就会导致 Kafka 无法连接到 Zookeeper,从而启动失败。
Java 环境问题:如果系统中没有正确安装 Java 环境或者 Java 环境变量配置不正确,会导致 Kafka 无法启动。需要确保已经正确安装了 Java 8 及以上版本,并且 Java 环境变量已经正确配置。可以在命令行中输入“java -version”来验证 Java 环境是否正常。
六、Kafka 的基本操作
6.1 命令行工具使用
Kafka 提供了丰富的命令行工具,方便用户对 Kafka 集群进行管理和操作,这些工具就像是 Kafka 的“瑞士军刀”,涵盖了主题管理、消息生产与消费、消费者组管理等各个方面。
6.1.1 主题管理
创建主题:使用 kafka-topics.sh 脚本可以创建新的主题。例如,要创建一个名为“test_topic”,包含 3 个分区和 2 个副本的主题,命令如下:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --topic test_topic --partitions 3 --replication-factor 2--bootstrap-server:指定 Kafka 集群的地址和端口;
--topic:指定主题名称;
--partitions:指定分区数量;
--replication-factor:指定副本因子,即每个分区的副本数量。
查看主题列表:使用以下命令,可以列出 Kafka 集群中所有的主题。
bin/kafka-topics.sh --list --bootstrap-server localhost:9092查看主题详情:使用以下命令,能够查看指定主题的详细信息,包括分区数量、副本分布、Leader 副本所在的 Broker 等。
bin/kafka-topics.sh --describe --topic test_topic --bootstrap-server localhost:9092修改主题分区数:如果需要增加主题的分区数(注意,分区数只能增加,不能减少),可以使用以下命令,将“test_topic”的分区数增加到 5 个。
bin/kafka-topics.sh --alter --topic test_topic --partitions 5 --bootstrap-server localhost:9092删除主题:使用以下命令,即可删除指定的主题。不过,在生产环境中删除主题时需要谨慎操作,因为这将永久性地删除该主题及其所有消息。
bin/kafka-topics.sh --delete --topic test_topic --bootstrap-server localhost:90926.1.2 消息生产与消费
发送消息:通过kafka-console-producer.sh脚本,我们可以向 Kafka 主题发送消息。运行
bin/kafka-console-producer.sh --topic test_topic --bootstrap-server localhost:9092然后在控制台输入消息内容,每按一次回车键,消息就会被发送到指定的主题。例如,输入“Hello, Kafka!”,这条消息就会被发送到“test_topic”主题中。
消费消息:kafka-console-consumer.sh脚本用于从 Kafka 主题消费消息。从主题的开头开始消费消息,命令为:
bin/kafka-console-consumer.sh --topic test_topic --bootstrap-server localhost:9092 --from-beginning如果希望从最新的消息开始消费,不带上--from-beginning参数即可。例如,执行上述命令后,就可以实时看到“test_topic”主题中之前发送的消息。
6.1.3 消费者组管理
查看消费者组列表:使用以下命令,可以列出 Kafka 集群中所有的消费者组。
bin/kafka-consumer-groups.sh --list --bootstrap-server localhost:9092查看消费者组详情:使用以下命令,能够查看指定消费者组的详细信息,包括每个分区的当前偏移量、消费进度等。这里,--group指定消费者组的名称。通过这些信息,我们可以了解消费者组的消费情况,及时发现潜在的问题。
bin/kafka-consumer-groups.sh --describe --group test_group --bootstrap-server localhost:90926.2 Java 代码示例
除了命令行工具,我们还可以通过编写 Java 代码来与 Kafka 进行交互,实现生产者和消费者的功能。以下是使用 Kafka 的 Java 客户端库编写的简单示例。
6.2.1 Kafka 生产者
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka服务器地址
String bootstrapServers = "localhost:9092";
// 主题名称
String topic = "test_topic";
// 配置生产者属性
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 设置key的序列化器
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 设置value的序列化器
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
for (int i = 0; i < 10; i++) {
String key = "key_" + i;
String value = "message_" + i;
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.out.println("发送消息失败: " + exception.getMessage());
} else {
System.out.println("消息发送成功: " +
"主题: " + metadata.topic() +
", 分区: " + metadata.partition() +
", 偏移量: " + metadata.offset());
}
}
});
}
// 关闭生产者
producer.close();
}
}在上述代码中,首先创建了一个Properties对象,用于配置 Kafka 生产者的属性,包括 Kafka 服务器地址、key 和 value 的序列化器。然后创建了KafkaProducer实例,并通过循环发送 10 条消息到指定的主题。在发送消息时,使用了回调函数Callback,以便在消息发送成功或失败时进行相应的处理。最后,在消息发送完成后,关闭了生产者。
6.2.2 Kafka 消费者
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class KafkaConsumerExample {
public static void main(String[] args) {
// Kafka服务器地址
String bootstrapServers = "localhost:9092";
// 消费者组ID
String groupId = "test_group";
// 主题名称
String topic = "test_topic";
// 配置消费者属性
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
// 设置消费者组ID
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 设置key的反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 设置value的反序列化器
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 自动提交偏移量
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交偏移量的时间间隔
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
// 拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : records) {
System.out.println("收到消息: " +
"主题: " + record.topic() +
", 分区: " + record.partition() +
", 偏移量: " + record.offset() +
", key: " + record.key() +
", value: " + record.value());
}
}
} finally {
// 关闭消费者
consumer.close();
}
}
}这段代码展示了如何使用 Java 编写一个简单的 Kafka 消费者。首先配置了消费者的属性,包括 Kafka 服务器地址、消费者组 ID、key 和 value 的反序列化器,以及自动提交偏移量的相关配置。然后创建了KafkaConsumer实例,并使用subscribe方法订阅了指定的主题。在一个无限循环中,通过poll方法不断从 Kafka 服务器拉取消息,并打印出每条消息的相关信息。最后,在程序结束时关闭了消费者。
七、总结与展望
Kafka 作为分布式消息系统的佼佼者,以其卓越的性能、强大的功能和广泛的应用场景,在大数据和分布式系统领域占据着举足轻重的地位。通过本文,我们深入了解了 Kafka 的核心概念,如 Broker、Topic、Partition、Producer、Consumer 和 Consumer Group 等,这些概念是理解 Kafka 工作机制的基础。同时,我们还探讨了 Kafka 在日志收集、消息队列、用户活动跟踪、实时数据处理和运营指标监控等多个领域的应用,以及它与其他消息队列相比所具有的优势。
对于想要深入学习和应用 Kafka 的读者,建议进一步阅读 Kafka 的官方文档,深入研究其原理和高级特性,如 Kafka 的流处理功能、事务支持、安全性等。同时,可以通过实际项目实践,不断积累经验,提升自己在分布式消息处理领域的能力。相信在未来,随着数据量的不断增长和分布式系统的广泛应用,Kafka 将发挥更加重要的作用,为我们的数据处理和系统架构带来更多的可能性。