前言
之前的文件分享过基于内存的STL缓存、环形缓冲区,以及基于文件的队列缓存mqueue、hash存储、向量库annoy存储,这两种属于比较原始且高效的方式。
那么,有没有高级且高效的方式呢。有的,从数据角度上看,(封装好底层的)SQL语法开发就是一种成熟、高效的方式。
本文主要讲解的是不需要搭建服务器的数据库类型(支持SQL语法)的轻量级缓存数据库SQLite。
SQLite特性
- 单文件存储:整个数据库(表、索引、视图等)存储在一个文件中,便于移植和备份;
- 无服务器架构:无需独立服务进程,通过函数调用操作数据;
- 资源占用低:库文件仅约 1MB,内存消耗少,适合资源受限环境;
- 高性能:读写操作直接访问磁盘文件,省去网络开销,响应速度快;
- 跨平台兼容:支持所有主流操作系统(Windows、Linux、macOS、Android、iOS等),文件格式统一,跨平台迁移无需转换;
局限性
- 并发写入:同一时间仅支持单线程写入,高并发写场景性能受限;
- 无用户管理:缺乏内置的用户权限系统,依赖文件系统权限;
- 数据规模:单库文件理论上支持 TB 级数据,但更适合中小规模应用;
使用场景
从以上特性及局限性可以看出sqlite是适合本地调用的GB级别数据库,可以很好的支持资源受限的移动应用、嵌入式设备,以及访问量较低的中小型网站、缓存数据量较低的应用场景()。
特别适合这种场景:比如计划安装redis、mysql来搭建SQL服务时,经过评估每日数据量,一个表都达不到100万条数据的情况下,可以直接选用SQLite提供数据库存储。
这里要额外的说明,SQLite本身不支持网络访问,如果是C/S架构,可以在服务器端搭建的网络服务中间件(比如通过前端、python、C/C++ socket方式提供网络服务)。
详细讲解
本文的源码是在国产桌面操作系统(统信UOS和麒麟kylin系统)下进行编译开发的,默认安装有sqlite3,如果没有安装,可以用以下命令安装:
sudo apt install sqlite3 libsqlite3-dev命令行操作
安装完成之后,可以在命令行查看库文件:
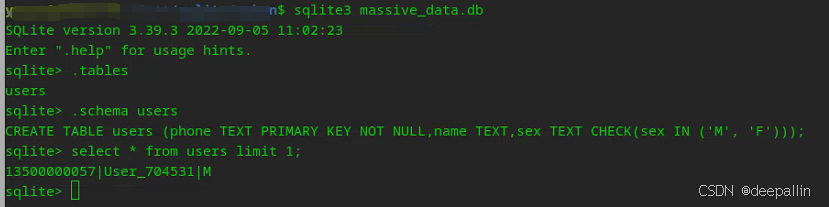
sqlite3库开发
本文分享的源码中,在SQLiteDB类中封装了打开数据库、创建表、插入表、批量插入表、更新表、查询表的功能,其中批量插入表提供批量插入模板(支持传结构体),文件结构如下:
mysqlite.h
#ifndef MY_SQLITE_H
#define MY_SQLITE_H
#include <sqlite3.h>
#include <iostream>
#include <list>
#include <vector>
#include <map>
#include <string>
#include <set>
// 查询结果的数据结构
typedef struct QueryResult {
void* data; //指向C++的QueryResult对象
} QueryResult;
class SQLiteDB {
public:
// 构造函数/析构函数
explicit SQLiteDB(const std::string& dbname);
~SQLiteDB();
// 基础操作
int createTable(const char* sql);// 创建表
int insertTable(const char* sql);// 插入数据
int updateTable(const char* sql);// 更新数据
int queryTable(const char* sql , QueryResult* result);// 查询数据
void closedb();// 关闭数据库
//批量插入模板
template<typename Container, typename BindFunc>
int batchInsertTemplate(const char* insert_sql,const Container& container,BindFunc binder)
{
// 使用预编译语句优化插入性能
sqlite3_stmt* stmt = nullptr;
// 准备预编译语句
if (sqlite3_prepare_v2(sql_db, insert_sql, -1, &stmt, nullptr) != SQLITE_OK) {
std::cerr << "准备预编译语句失败: " << sqlite3_errmsg(sql_db) << std::endl;
return -1;
}
setcache();
beginTransaction(); // 开启事务
int success_count = 0;
int batch_size = 1000; // 每批插入量
try {
int counter = 0;
for (const auto& item : container) {
// 绑定参数
binder(stmt, item);
// 执行插入
int rc = sqlite3_step(stmt);
if (rc != SQLITE_DONE) {
//std::cerr << "插入数据失败[" << counter << "]: "
// << sqlite3_errmsg(db) << " Phone: " << user.phone << std::endl;
// 继续尝试下一条而非直接返回
} else {
success_count++;
}
sqlite3_reset(stmt);
counter++;
// 分批提交
if (counter % batch_size == 0) {
commitTransaction();// 提交记录
beginTransaction(); // 开启新事务
}
}
// 提交剩余记录
commitTransaction();// 提交最后一批可能不足1000条的记录
} catch (...) {
rollbackTransaction();
sqlite3_finalize(stmt);// 释放预编译语句
throw; // 重新抛出异常
}
// 释放预编译语句
sqlite3_finalize(stmt);
return success_count;
}
//读取结果
QueryResult* createQueryResult();
void freeQueryResult(QueryResult* result);//释放QueryResult内存
const std::list<std::string>& getColumnNames(const QueryResult* result);
const std::vector<std::map<int, std::string>>& getRows(const QueryResult* result);
bool m_status;
private:
bool opendb(const char* dbname);
int execsql(const char* sql);
// 实现事务函数
int beginTransaction();
int commitTransaction();
int rollbackTransaction();
int setcache();
sqlite3* sql_db;
};
#endif // MY_SQLITE_H
mysqlite.cpp
#include "mysqlite.h"
struct InternalQueryResult {
std::list<std::string> columnNames;
std::vector<std::map<int, std::string>> rows;
};
SQLiteDB::SQLiteDB(const std::string& dbname){
opendb(dbname.c_str());
}
SQLiteDB::~SQLiteDB(){
}
bool SQLiteDB::opendb(const char* dbname) {
m_status=true;
int rc = sqlite3_open(dbname, &sql_db);
if (rc != SQLITE_OK) {
//std::cerr << "无法打开数据库: " << sqlite3_errmsg(db) << std::endl;
sqlite3_close(sql_db); // 打开失败时关闭数据库
m_status = false;
//return m_status;
}
return m_status;
}
int SQLiteDB::execsql(const char* sql) {
char* errMsg = nullptr;
int rc = sqlite3_exec(sql_db, sql, nullptr, nullptr, &errMsg);
if (rc != SQLITE_OK) {
sqlite3_free(errMsg);
//std::cerr << "执行失败: " << errMsg << std::endl;
return -1;
}
return 0;
}
int SQLiteDB::createTable(const char* sql) {
int ret=execsql(sql);
if(ret==-1) std::cerr << "创建表失败: " << std::endl;
else std::cout << "创建表成功" << std::endl;
return ret;
}
int SQLiteDB::insertTable( const char* sql) {
int ret=execsql(sql);
//if(ret==-1) std::cerr << "插入数据失败: " << std::endl;
//else std::cout << "插入数据成功" << std::endl;
return ret;
}
int SQLiteDB::updateTable( const char* sql) {
int ret=execsql(sql);
//if(ret==-1) std::cerr << "更新数据失败: " << std::endl;
//else std::cout << "更新数据成功" << std::endl;
return ret;
}
// 回调函数:将数据存储到QueryResult中
static int callback(void* data, int argc, char** argv, char** colName) {
InternalQueryResult* retdata = static_cast<InternalQueryResult*>(data);
// 保存列名(只在第一次回调时保存)
if (retdata->columnNames.empty()) {
for (int i = 0; i < argc; i++) {
retdata->columnNames.push_back(colName[i]);
}
}
// 保存当前行数据
std::map<int, std::string> row;
for (int i = 0; i < argc; i++) {
row[i] = argv[i] ? argv[i] : "NULL"; // 键=列索引,值=数据
}
retdata->rows.push_back(row);
return 0;
}
// 创建QueryResult对象
QueryResult* SQLiteDB::createQueryResult() {
auto* result = new QueryResult;
result->data = new InternalQueryResult;
return result;
}
// 释放QueryResult内存
void SQLiteDB::freeQueryResult(QueryResult* result) {
if (result) {
delete static_cast<InternalQueryResult*>(result->data);
delete result;
}
}
// 获取列名列表
const std::list<std::string>& SQLiteDB::getColumnNames(const QueryResult* result) {
return static_cast<InternalQueryResult*>(result->data)->columnNames;
}
// 获取行数据
const std::vector<std::map<int, std::string>>& SQLiteDB::getRows(const QueryResult* result) {
return static_cast<InternalQueryResult*>(result->data)->rows;
}
int SQLiteDB::queryTable(const char* sql , QueryResult* result) {
char* errMsg = nullptr;
auto* internalResult = static_cast<InternalQueryResult*>(result->data);
int rc = sqlite3_exec(sql_db, sql, callback, internalResult, &errMsg);
if (rc != SQLITE_OK) {
std::cerr << "查询失败: " << errMsg << std::endl;
sqlite3_free(errMsg);
return -1;
}
return 0;
}
void SQLiteDB::closedb() {
sqlite3_close(sql_db);
}
// 实现事务模式
int SQLiteDB::beginTransaction() {
return sqlite3_exec(sql_db, "BEGIN IMMEDIATE TRANSACTION;", nullptr, nullptr, nullptr);
}
int SQLiteDB::setcache() {
return sqlite3_exec(sql_db, "PRAGMA cache_size=10000;", nullptr, nullptr, nullptr);
}
//
int SQLiteDB::commitTransaction() {
return sqlite3_exec(sql_db, "COMMIT;", nullptr, nullptr, nullptr);
}
int SQLiteDB::rollbackTransaction() {
return sqlite3_exec(sql_db, "ROLLBACK;", nullptr, nullptr, nullptr);
}
引用类的主程序main.cpp
#include "mysqlite.h"
#include <string>
#include <iostream>
#include <chrono>
#include <random>
#include <set>
// 用户结构体定义
typedef struct user_st {
std::string phone;
std::string name;
std::string sex;
// 用于set排序的比较函数
bool operator<(const user_st& other) const {
return phone < other.phone;
}
} user_st;
// 准备绑定函数
auto stBinder = [](sqlite3_stmt* stmt, const user_st& p) {
return sqlite3_bind_text(stmt, 1, p.phone.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK &&
sqlite3_bind_text(stmt, 2, p.name.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK &&
sqlite3_bind_text(stmt, 3, p.sex.c_str(), -1, SQLITE_TRANSIENT) == SQLITE_OK;
};
// 生成随机手机号 (135xxxxxxxx)
std::string generatePhone() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 99999999);
char buf[12];
snprintf(buf, sizeof(buf), "135%08d", dis(gen));
return buf;
}
int main() {
// 打开数据库
SQLiteDB litedb("massive_data.db");
if (!litedb.m_status) {
std::cerr << "无法打开数据库" << std::endl;
return -1;
}
if(0)//创建表并批量插入测试
{
// 创建表(如果不存在)
const char* createTableSQL =
"CREATE TABLE IF NOT EXISTS users ("
"phone TEXT PRIMARY KEY NOT NULL,"
"name TEXT,"
"sex TEXT CHECK(sex IN ('M', 'F'))"
");";
if (litedb.createTable(createTableSQL) != 0) {
std::cerr << "创建表失败" << std::endl;
litedb.closedb();
return -1;
}
std::set<user_st> user_set;
for (int i = 0; i < 1000000; ++i) {
user_st usermsg;
usermsg.phone = generatePhone();
usermsg.name = "User_" + std::to_string(i);
usermsg.sex = (i % 2) ? "M" : "F";
user_set.insert(usermsg);
}
//插入100万条数据(批量事务优化)
std::cout << "开始插入100万条数据..." << std::endl;
auto startInsert = std::chrono::high_resolution_clock::now();
const char* insert_sql = "INSERT OR IGNORE INTO users (phone, name, sex) VALUES (?, ?, ?);";
litedb.batchInsertTemplate(insert_sql,user_set,stBinder);
auto endInsert = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> insertTime = endInsert - startInsert;
std::cout << "插入完成,耗时: " << insertTime.count() << "秒" << std::endl;
}
{//查询数据
std::cout << "测试100万条数据查询速度..." << std::endl;
auto startquery = std::chrono::high_resolution_clock::now();
QueryResult* result = litedb.createQueryResult();
const char* sqlstr = "SELECT * FROM users WHERE phone='13555927718';";
std::vector<std::string> colname;
if (litedb.queryTable(sqlstr,result) == 0) {
// 打印列名
std::cout << "列名: ";
for (const auto& col : litedb.getColumnNames(result)) {
std::cout << col << " ";
colname.push_back(col);
}
std::cout << std::endl;
// 打印所有行数据
int rowNum = 0;
for (const auto& row : litedb.getRows(result)) {
std::cout << "行 " << rowNum++ << ": ";
for (const auto& pair : row) {
//std::cout << pair.first << "=" << pair.second << " ";
std::cout << colname[pair.first] << "=" << pair.second << " ";
}
std::cout << std::endl;
}
}
litedb.freeQueryResult(result);
auto endquery = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> duration = endquery - startquery;
std::cout << "查询完成,耗时: " << duration.count() << "秒" << std::endl;
}
litedb.closedb();
return 0;
}
Makefile文件
CC = g++
CFLAGS =
DEBUGFLAG = -g -Wall
SRCS = $(wildcard *.cpp)
LIBDIRS = -L./
LIBS = -lsqlite3
INCLUDE = -I.
TARGET = sqlitetest
OBJS = $(SRCS:.cpp=.o)
all: $(TARGET)
# 生成可执行文件
$(TARGET): $(OBJS)
$(CC) $(LIBS) $^ -o $@
# 通用规则:编译 .cpp 文件为 .o 文件
%.o: %.cpp
$(CC) $(LIBS) -c $< -o $@
clean:
rm -f $(OBJS) $(TARGET)
.PHONY: all clean
测试效果图:

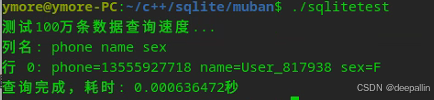
通过以上的批量插入和查询性能测试,我的国产信创终端设备,插入100万条速度15秒,查询速度是0.6毫秒,满足我的QT应用及后台应用开发需求(1条处理不超过1000条数据)。
sqlite默认是使用 B+ Tree作为其主要的索引结构(与MySQL一样)能够进行高效的范围查询。另外
其他分享:之前分享的hash存储查询方式,是在同一台国产设备上运行的,100万条记录查询1条记录速度是1微妙,比sqlite要强很多,适合TB级数据处理。hash存储查询![]() https://blog.csdn.net/liangyuna8787/article/details/147492363?spm=1001.2014.3001.5501
https://blog.csdn.net/liangyuna8787/article/details/147492363?spm=1001.2014.3001.5501
篇尾
sqlite的轻量级数据库特性,不仅易于部署,并且容易移植,且维护成本低,适合对数据库依赖性低的项目,C/C++项目本身就对数据库依赖低,所以本文专门分享从性能测试角度来选型sqlite。