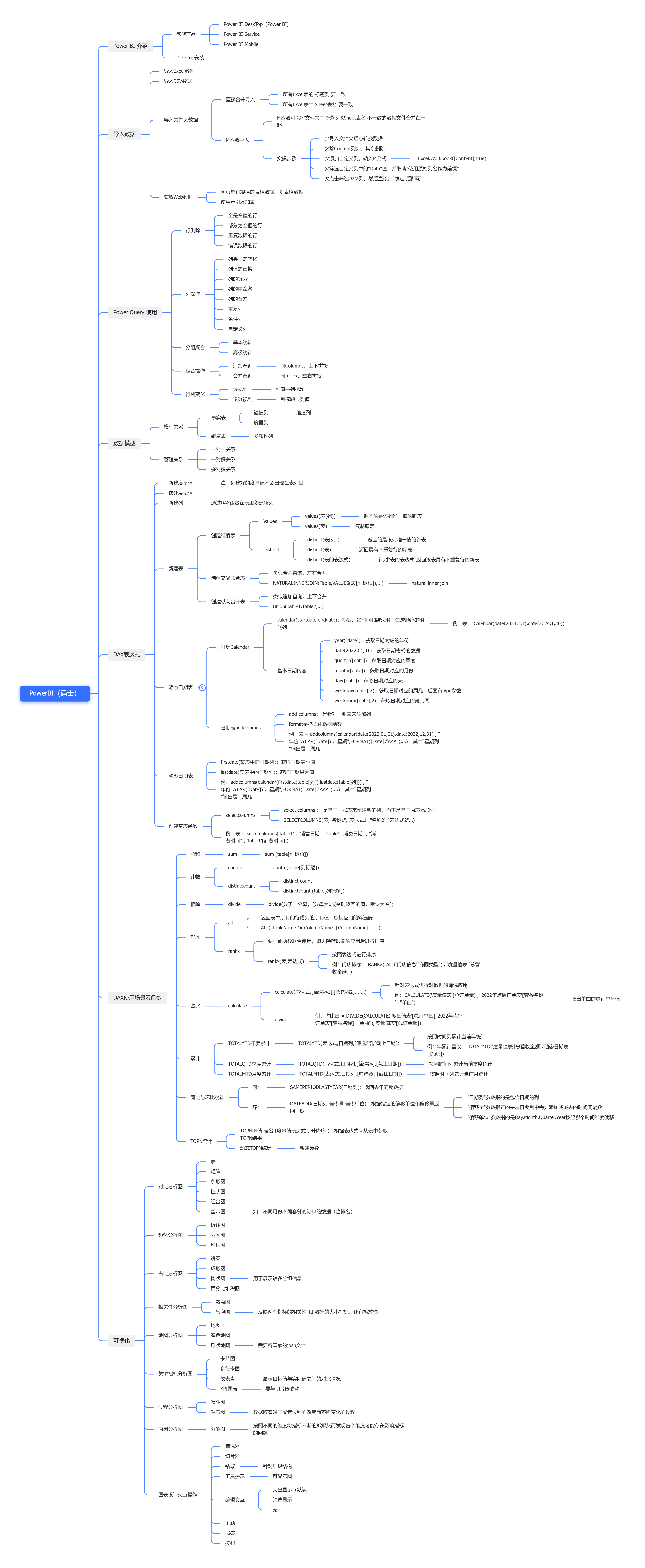
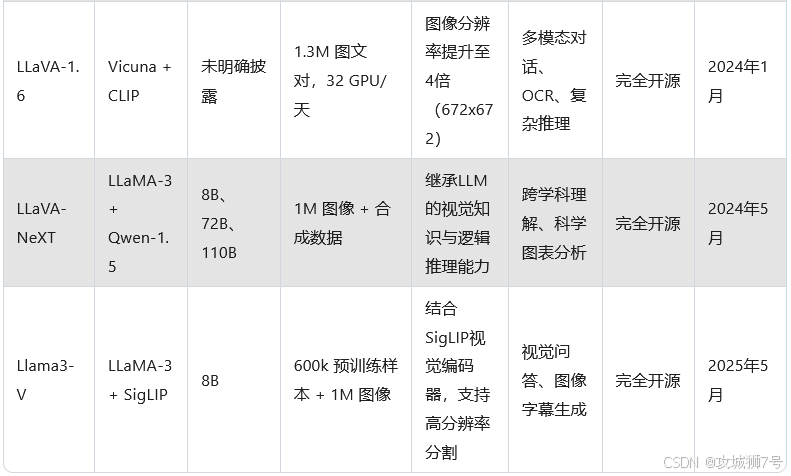
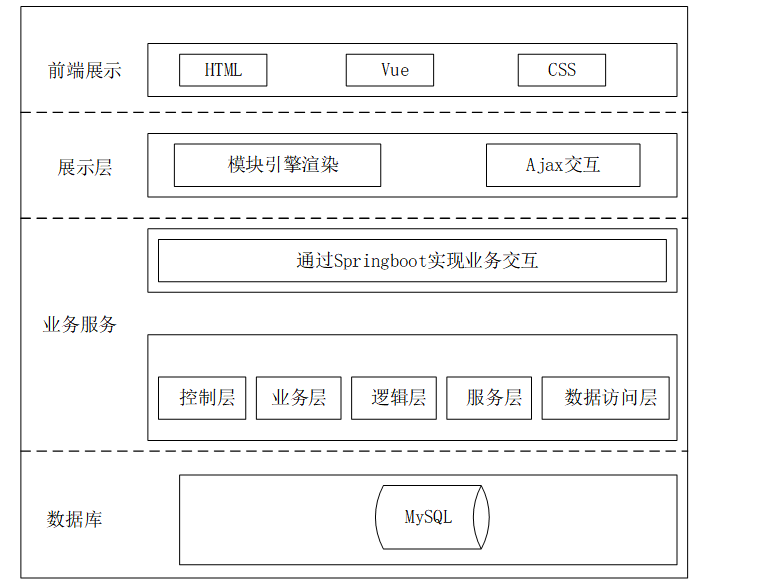
一、YOLOv3的诞生:继承与突破的起点
YOLOv3作为YOLO系列的第三代算法,于2018年由Joseph Redmon等人提出。它在YOLOv2的基础上,针对小目标检测精度低、多类别标签预测受限等问题进行了系统性改进。通过引入多尺度特征图检测、残差网络架构和独立分类器设计,YOLOv3在保持实时性的同时,显著提升了检测精度,成为目标检测领域的经典算法之一。
二、核心架构:Darknet-53与多尺度检测的完美协同
(一)Darknet-53:残差网络的高效实践
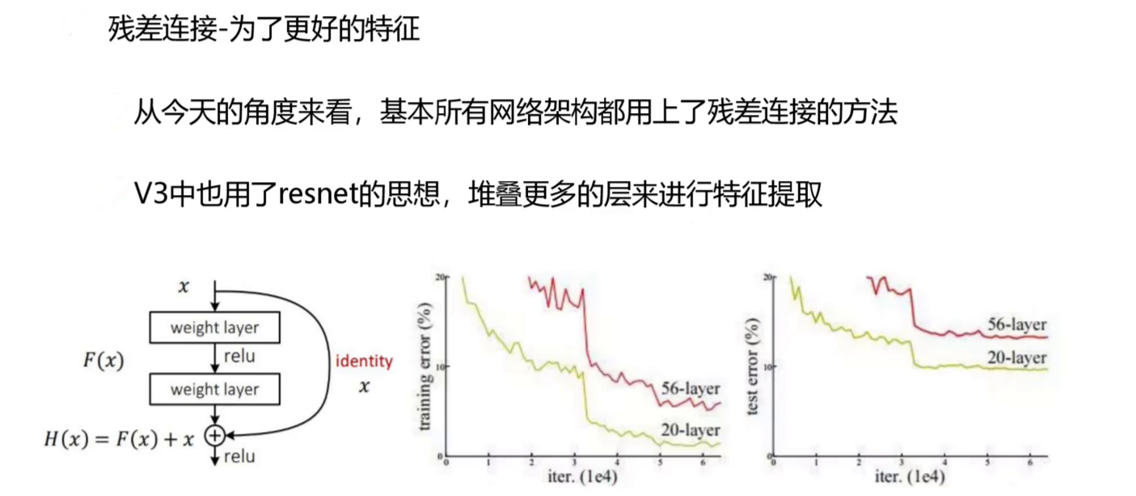
YOLOv3的骨干网络Darknet-53以**残差连接(Residual Connection)**为核心,构建了53层的全卷积网络,其架构设计体现了“深度与效率的平衡”:
-
残差块结构:每个残差块由两个卷积层(1×1和3×3)和一个捷径连接组成。
这种结构通过学习输入与输出的残差(而非直接学习输出),有效缓解了深层网络的梯度消失问题,允许网络堆叠更多层以提取更复杂的特征。 -
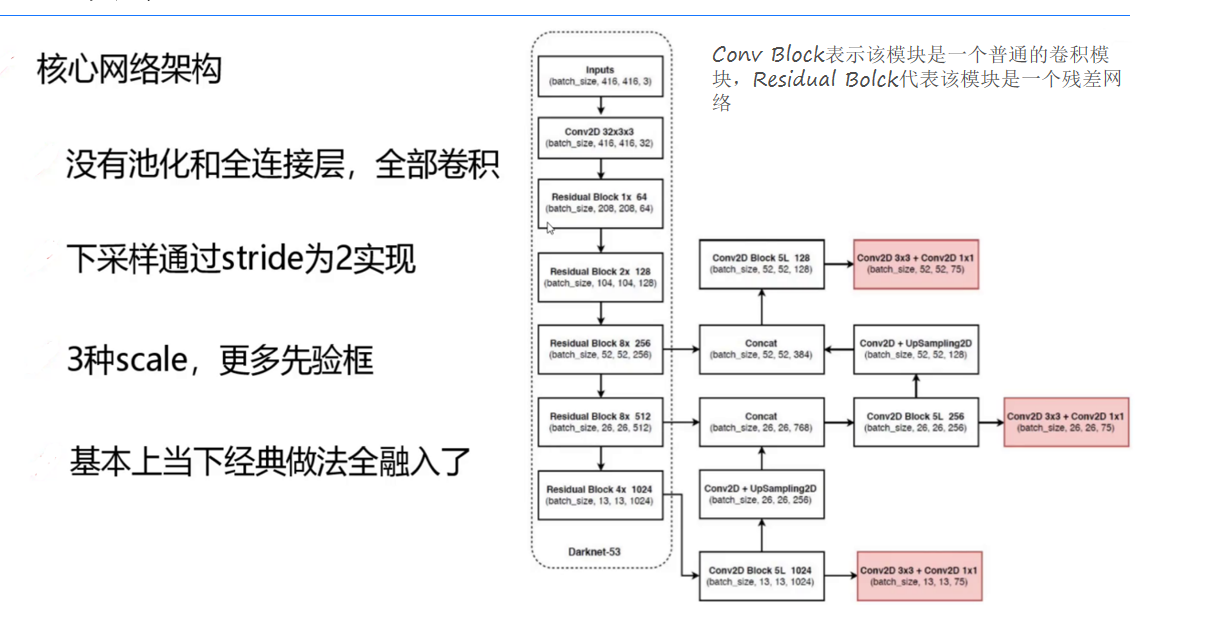
降采样策略:摒弃传统的池化层,通过步长为2的3×3卷积层实现降采样。例如,输入416×416的图像,经过5次降采样后,依次输出52×52、26×26、13×13三种尺度的特征图,分别对应小、中、大目标的检测。
-
性能优势:在ImageNet分类任务中,Darknet-53的TOP-1准确率达77.2%,优于ResNet-101(77.8%),且浮点运算量(FLOPs)仅为7.52B,约为ResNet-101的一半,体现了更高的计算效率。
(二)三尺度特征图检测:小目标检测的破局之道
YOLOv3首次将**特征金字塔网络(FPN)**引入YOLO系列,通过多尺度特征融合解决小目标检测难题:
-
特征图尺度与目标匹配:
- 52×52特征图(感受野小):负责检测小型目标,如昆虫、文字等,对应先验框:(10×13)、(16×30)、(33×23)。
- 26×26特征图(感受野中等):检测中型目标,如行人、车辆,对应先验框:(30×61)、(62×45)、(59×119)。
- 13×13特征图(感受野大):检测大型目标,如建筑物、飞机,对应先验框:(116×90)、(156×198)、(373×326)。
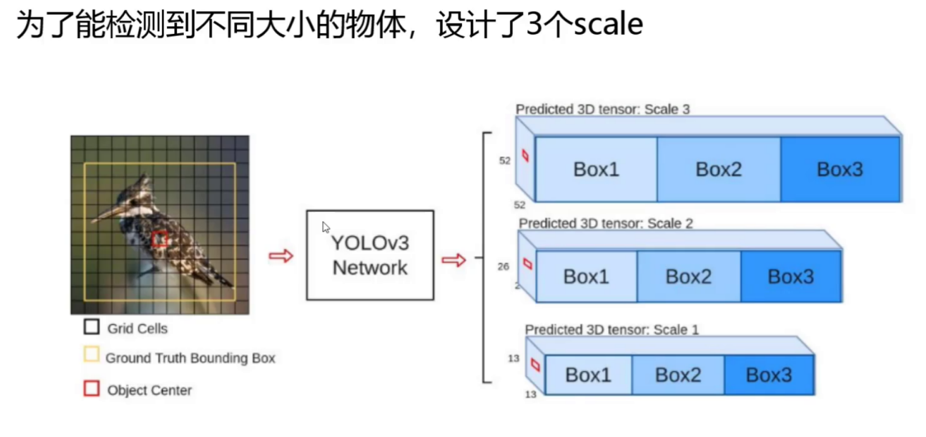
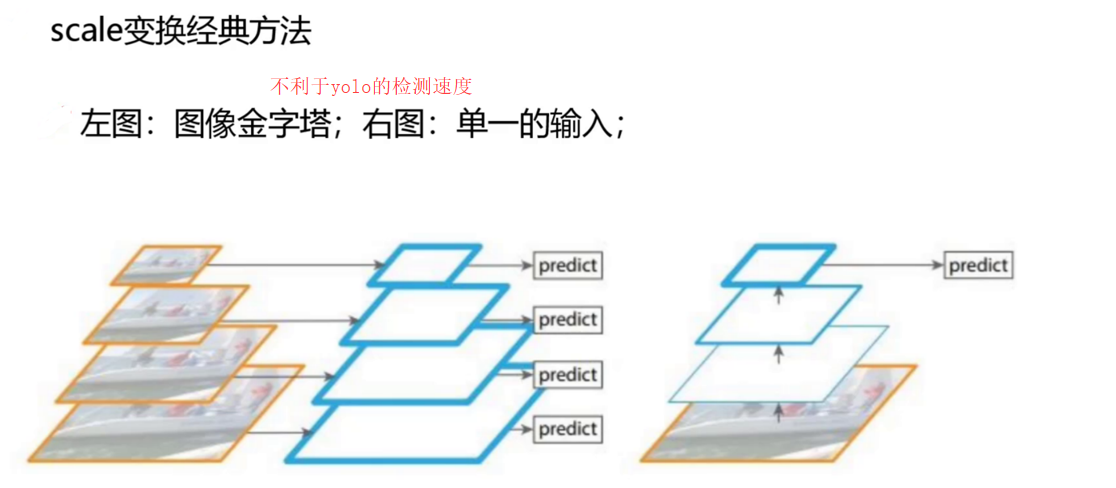
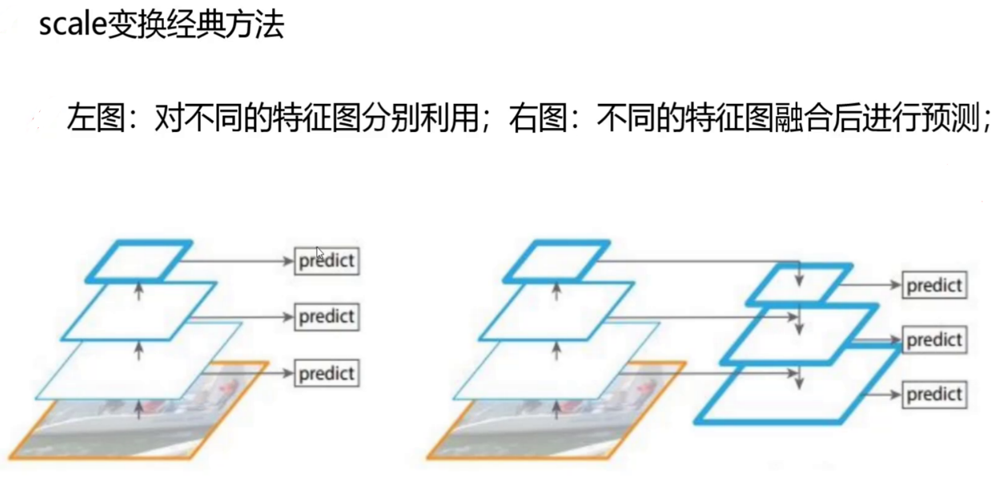
-
特征融合流程:
- 自顶向下路径:高层特征图(如13×13)通过上采样(插值或转置卷积)放大至低层特征图尺寸(如26×26、52×52),与低层特征图进行横向连接(Concat操作)。
- 横向连接优化:在融合前,对低层特征图进行1×1卷积以减少通道数,对高层特征图进行3×3卷积以增强特征表达,确保融合后的特征兼具高层语义信息(如“车辆”类别)和低层空间细节(如目标轮廓)。
- 输出检测头:每个尺度的融合特征图后接独立的检测头,包含3个卷积层和1个1×1卷积层,输出该尺度下的检测结果(坐标、置信度、类别概率)。
-
效果验证:在COCO数据集上,YOLOv3对小目标(面积<32²像素)的mAP提升至19.0%,相比YOLOv2的13.0%显著提升,证明了多尺度检测的有效性。
三、关键改进:从分类到定位的细节革新
(一)独立Logistic分类器:突破单标签限制
YOLOv3舍弃了传统的Softmax分类器,改用独立Logistic回归对每个类别进行二分类预测,核心改进如下:
- 多标签支持:每个类别使用Sigmoid激活函数,输出独立的概率值(0-1),允许目标同时属于多个类别。例如,一张图像中的“消防栓”可同时被标记为“公共设施”和“金属物体”。
- 阈值灵活设定:通过调整类别概率阈值(如0.5),可适应不同场景的检测需求。在医疗影像中,可降低阈值以避免漏检,在工业质检中可提高阈值以减少误报。
- 计算优化:Logistic分类器无需计算Softmax的全局归一化,计算量减少约30%,推理速度略有提升。

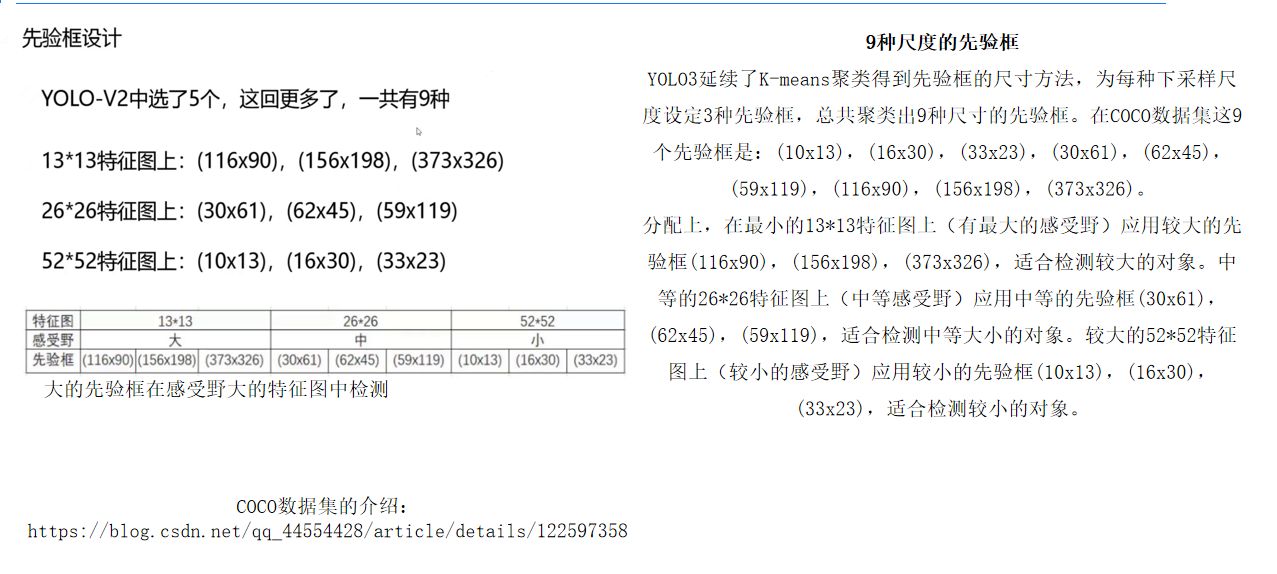
(二)先验框设计:K-means聚类与尺度分配策略
-
聚类生成先验框:在COCO数据集上使用K-means算法对真实框进行聚类,生成9种尺寸的先验框,并按尺度均匀分配到三个特征图:
- 小特征图(52×52):3种小先验框,侧重捕捉细节。
- 中特征图(26×26):3种中等先验框,平衡语义与定位。
- 大特征图(13×13):3种大先验框,适应远距离目标。
-
先验框的作用:为预测框提供初始尺寸和位置,减少网络学习的复杂度。实验表明,引入先验框后,YOLOv3的召回率从YOLOv1的81%提升至88%,意味着模型能检测到更多潜在目标。
(三)典型应用场景
- 智能安防:实时监控视频中的异常行为(如人群聚集、物品遗留),通过多尺度检测识别远距离的小目标(如远处的可疑包裹)。
- 自动驾驶:检测道路标志、行人、车辆,利用13×13特征图识别远处车辆(大目标),52×52特征图识别近处行人(小目标),支持多目标追踪与路径规划。
- 工业自动化:电子元件缺陷检测,通过高分辨率输入(如608×608)和52×52特征图捕捉元件表面的微小裂纹或污渍。
- 遥感图像处理:卫星影像中的建筑物、车辆检测,利用大感受野特征图(13×13)识别大型建筑,小感受野特征图(52×52)识别密集车辆群。
四、总结:YOLOv3的技术遗产与未来启示
YOLOv3的成功源于其对多尺度特征融合、残差网络效率和多标签分类的深刻理解,其技术创新对后续目标检测算法产生了深远影响:
- 多尺度检测成为后续YOLOv4/v5、Faster R-CNN等算法的标配,甚至扩展至语义分割(如DeepLabv3+)。
- 残差连接与特征金字塔的组合思想被广泛应用于各类视觉任务,如姿态估计、实例分割。
- 端到端的单阶段检测架构依然是工业界的首选,其高效性在边缘计算、实时系统中不可替代。
尽管YOLOv4/v5在精度和速度上进一步突破,但YOLOv3作为承上启下的里程碑,依然是理解现代目标检测算法的关键切入点。它证明了在深度学习中,通过合理的架构设计与细节优化,完全可以在效率与精度之间找到最优解,这一理念将持续启发研究者在计算机视觉领域探索更高效、更通用的解决方案。