目录
一、引言
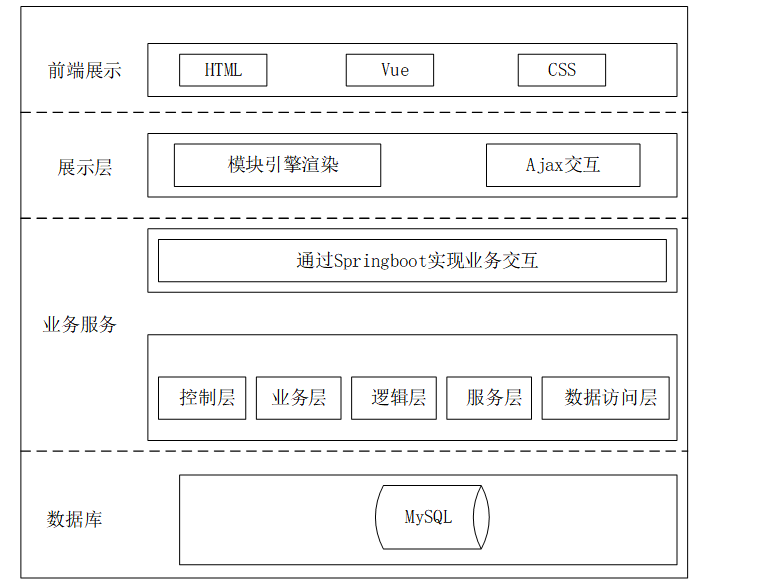
二、LLaVA与LLaMA的定义
2.1 LLaMA
2.2 LLaVA
2.3 LLaVA-NeXT 的技术突破
三、产生的背景
3.1 LLaMA的背景
3.2 LLaVA的背景
四、与其他竞品的对比
4.1 LLaMA的竞品
4.2 LLaVA的竞品
五、应用场景
5.1 LLaMA的应用场景
5.2 LLaVA的应用场景
六、LLaVA和LLaMA的学习地址与开源情况
6.1 LLaMA 和 Llama 4
6.2 LLaVA
七、结语

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 LLaVA与LLaMA
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
一、引言
随着人工智能技术的飞速发展,大语言模型(Large Language Models, LLMs)已成为自然语言处理(NLP)领域的核心驱动力。近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)的出现,进一步拓展了AI的应用边界。其中,LLaVA(Large Language and Vision Assistant)和LLaMA(Large Language Model Meta AI)作为两个备受瞩目的模型,不仅在学术界引发了广泛讨论,也在工业界掀起了新一轮的技术革新。本文将详细介绍LLaVA和LLaMA的定义、背景、竞品对比、应用场景以及使用方法,帮助读者全面了解这两个模型的特点和潜力。
二、LLaVA与LLaMA的定义
2.1 LLaMA
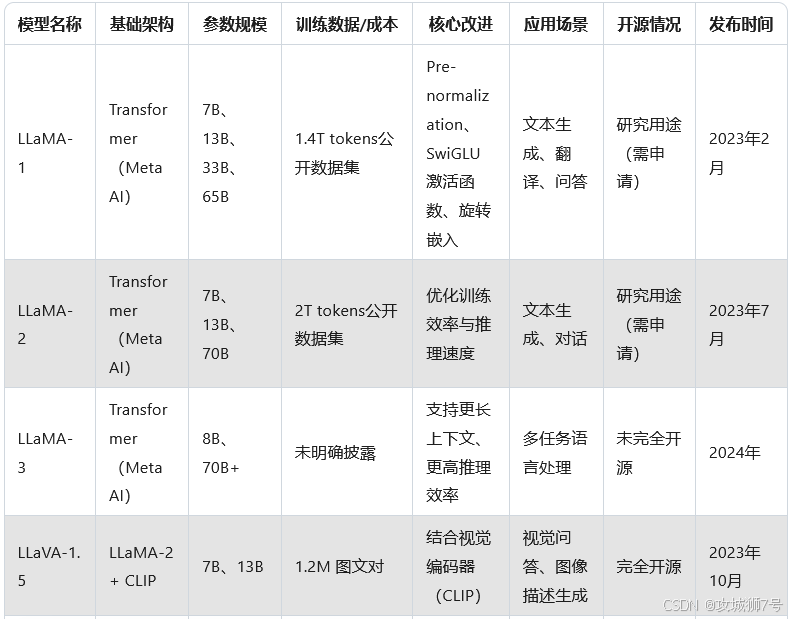
LLaMA(Large Language Model Meta AI)是由Meta AI(原Facebook AI)开发的开源大语言模型。它基于Transformer架构,通过大规模预训练和微调,能够生成高质量的自然语言文本。LLaMA的设计初衷是提供一个高效、可扩展的模型,以支持各种NLP任务,如文本生成、问答、翻译等。LLaMA的开源特性使其成为学术界和工业界研究的热点,也为后续的多模态模型奠定了基础。
在2024年4月,Meta发布了第四代Llama系列模型——Llama 4,这是一个具有重大突破的多模态模型系列。Llama 4系列包括三个主要模型:
(1)Llama 4 Scout:
- 170亿活跃参数,16个专家
- 支持1000万token的上下文窗口
- 可在单个NVIDIA H100 GPU上运行
- 性能优于Gemma 3和Gemini 2.0 Flash-Lite
(2) Llama 4 Maverick:
- 170亿活跃参数,128个专家
- 总参数量达4000亿
- 性能超越GPT-4o和Gemini 2.0 Flash
- ELO评分达1417,展现卓越的性能成本比
(3)Llama 4 Behemoth:
- 2880亿活跃参数,近2万亿总参数
- 在数学、多语言和图像基准测试中超越GPT-4.5
- 作为teacher模型用于知识蒸馏
Llama 4系列的主要技术特点:
- 原生多模态架构:在模型结构层面融合文本、图像和视频输入
- 混合专家(MoE)架构:显著降低计算开销和部署门槛
- iRoPE位置编码:支持超长上下文处理
- 高效训练体系:
- 使用超过30万亿tokens的多语种数据
- 支持FP8精度训练
- 采用MetaP技术优化训练过程
- 全面的安全机制:
- Llama Guard和Prompt Guard提供安全防护
- GOAT系统增强红队测试
- 显著降低敏感话题的拒答率
2.2 LLaVA
LLaVA(Large Language and Vision Assistant)是由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学的研究人员共同设计的多模态大语言模型。它基于LLaMA的架构,通过引入视觉编码器(如CLIP或DALL-E),能够同时处理文本和图像输入,生成与图像相关的自然语言描述或回答。LLaVA的目标是构建一个能够理解、分析和生成多模态内容的AI助手,为用户提供更丰富的交互体验。
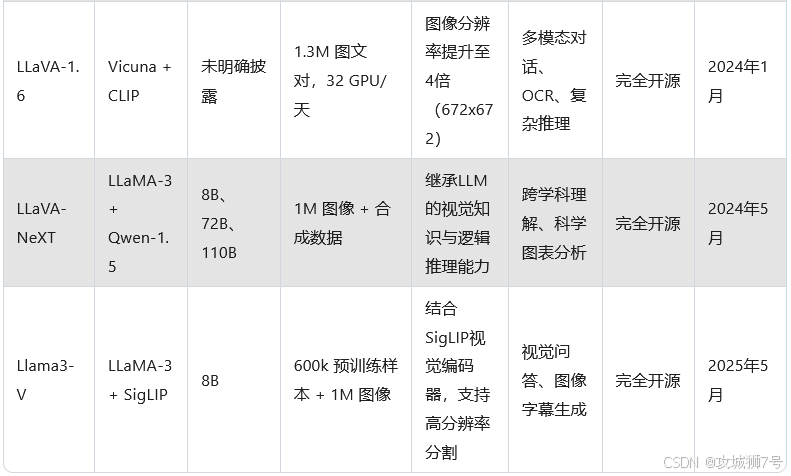
在2024年,LLaVA迎来了重大升级,推出了LLaVA-NeXT版本。这个新版本由字节跳动、香港科技大学和南洋理工大学的研究人员共同开发,采用了最新的LLaMA-3(8B)和Qwen-1.5(72B & 110B)作为基础语言模型,显著提升了多模态能力。LLaVA-NeXT在多项基准测试中展现出与GPT-4V相当的性能,同时保持了高效训练的特点,最大的110B参数版本仅需在128台H800服务器上训练18小时即可完成。
2.3 LLaVA-NeXT 的技术突破
(1)模型架构与训练
- 模型规模:提供三种参数规模版本
- LLaMA-3-LLaVA-NeXT-8B
- LLaVA-NeXT-72B
- LLaVA-NeXT-110B
- 训练效率:
- 8B版本:8个A100-80G GPU,20小时
- 72B版本:64个A100-80G GPU,18小时
- 110B版本:128个H800-80G GPU,18小时
- 训练数据:
- 第一阶段:558K样本
- 第二阶段:790K样本
- 总训练数据:1348K样本
(2)评估基准与性能
LLaVA-NeXT在多个关键基准测试中展现出卓越性能:
1. MMMU(跨学科理解):评估模型在跨学科领域的理解能力
2. Mathvista(视觉数学推理):测试模型在视觉数学问题上的推理能力
3. AI2D(科学图表理解):评估模型对科学图表的理解能力
4. LLaVA-Bench(Wilder):专门用于评估日常视觉对话场景的新基准
(3) LLaVA-Bench(Wilder)数据集
这是一个专门用于评估多模态模型在日常视觉对话场景中表现的新基准:
- 数据集规模:
- 轻量级版本:120个测试案例
- 进阶版本:1020个测试案例
- 数据特点:
- 覆盖数学解题、图像解读、代码生成等多个场景
- 数据来源于真实用户需求
- 经过严格的隐私保护和风险评估
- 参考答案由GPT-4V生成并经过人工验证
- 评估方法:
- 采用GPT-4V作为评分标准
- 直接比较模型回答与参考答案的匹配度
- 确保评分标准的一致性和公平性
(4)性能对比
LLaVA-NeXT在各项基准测试中展现出与GPT-4V相当的性能:
- 多模态理解:在视觉-语言任务中达到最先进水平
- 推理能力:在复杂场景下的逻辑推理能力显著提升
- 知识应用:在跨学科知识应用方面表现优异
- 实际应用:在日常对话场景中展现出强大的实用性
三、产生的背景
3.1 LLaMA的背景
LLaMA的诞生源于Meta AI对开源AI技术的追求。在2023年,Meta AI发布了LLaMA模型,旨在推动AI技术的民主化和透明化。LLaMA的开源特性使其成为学术界和工业界研究的热点,也为后续的多模态模型奠定了基础。LLaMA的设计理念是提供一个高效、可扩展的模型,以支持各种NLP任务,如文本生成、问答、翻译等。
3.2 LLaVA的背景
LLaVA的出现是AI技术向多模态方向发展的必然结果。随着计算机视觉和自然语言处理技术的成熟,研究者们开始探索如何将这两种能力结合起来,构建更智能的AI系统。LLaVA基于LLaMA的架构,通过引入视觉编码器,能够同时处理文本和图像输入,生成与图像相关的自然语言描述或回答。LLaVA的目标是构建一个能够理解、分析和生成多模态内容的AI助手,为用户提供更丰富的交互体验。
四、与其他竞品的对比
4.1 LLaMA的竞品
- GPT-4:由OpenAI开发,是目前最强大的大语言模型之一,支持多模态输入,但未开源。
- Claude:由Anthropic开发,专注于安全性和可控性,支持多模态输入,但未开源。
- PaLM:由Google开发,支持多模态输入,但未开源。
LLaMA的优势在于其开源特性,使得研究者可以自由使用和修改模型,推动AI技术的民主化和透明化。
4.2 LLaVA的竞品
- GPT-4V:OpenAI的多模态模型,支持图像和文本输入,但未开源。
- Claude 3 Opus:Anthropic的多模态模型,支持图像和文本输入,但未开源。
- PaLM 2:Google的多模态模型,支持图像和文本输入,但未开源。
LLaVA的优势在于其开源特性,使得研究者可以自由使用和修改模型,推动AI技术的民主化和透明化。
五、应用场景
5.1 LLaMA的应用场景
- 文本生成:LLaMA可以生成高质量的自然语言文本,适用于内容创作、广告文案、新闻报道等。
- 问答系统:LLaMA可以回答用户的问题,适用于客服机器人、教育辅导、知识库等。
- 翻译:LLaMA可以翻译不同语言之间的文本,适用于跨语言交流、国际化产品等。
5.2 LLaVA的应用场景
- 图像描述:LLaVA可以生成与图像相关的自然语言描述,适用于图像标注、内容审核、社交媒体等。
- 视觉问答:LLaVA可以回答与图像相关的问题,适用于教育辅导、医疗诊断、智能客服等。
- 多模态交互:LLaVA可以同时处理文本和图像输入,生成多模态内容,适用于虚拟助手、智能家居、自动驾驶等。
六、LLaVA和LLaMA的学习地址与开源情况
6.1 LLaMA 和 Llama 4
- 学习地址:
- 官方下载:[Meta AI官网](https://llama.meta.com/)
- Hugging Face:[Meta Llama](https://huggingface.co/meta-llama)
- 在线体验:[Meta AI](https://ai.meta.com/)
- 开源情况:LLaMA和Llama 4都是开源的,研究者可以自由使用和修改模型。
- Llama 4特性:
- 多模态能力:原生支持文本、图像和视频处理
- 超长上下文:支持高达1000万token的上下文窗口
- 高效推理:采用MoE架构,显著降低计算开销
- 安全机制:提供全面的安全防护和合规治理
- 应用场景:支持多文档摘要、代码处理、图像理解等
6.2 LLaVA
- 学习地址:
- 论文链接:[LLaVA 论文](https://arxiv.org/pdf/2304.08485.pdf)
- 项目链接:[LLaVA 项目](https://llava-vl.github.io/)
- GitHub 地址:[LLaVA GitHub](https://github.com/haotian-liu/LLaVA)
- LLaVA-NeXT GitHub:[LLaVA-NeXT GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT)
- Demo 链接:[LLaVA-NeXT Demo](https://llava-next.lmms-lab.com/)
- 开源情况:LLaVA 和 LLaVA-NeXT 都是开源的,研究者可以自由使用和修改模型。
- LLaVA-NeXT 特性:
- 模型规模:提供8B、72B和110B三种参数规模
- 训练效率:最大模型仅需18小时训练时间
- 性能提升:在多项基准测试中达到与GPT-4V相当的水平
- 评估基准:包含LLaVA-Bench(Wilder)等新的评估数据集
- 应用场景:优化了视觉对话功能,满足多样化的现实场景需求
- 开源资源:
- 代码仓库:[GitHub](https://github.com/LLaVA-VL/LLaVA-NeXT)
- 在线演示:[Demo](https://llava-next.lmms-lab.com/)
- 评估数据集:[Hugging Face](https://huggingface.co/datasets/liuhaotian/llava-bench-in-the-wild)
七、结语
LLaVA和LLaMA作为多模态大语言模型的代表,不仅推动了AI技术的发展,也为用户提供了更丰富的交互体验。特别是LLaVA-NeXT的推出,通过整合最新的语言模型技术,进一步缩小了开源模型与私有模型之间的性能差距。它们的开源特性使得研究者可以自由使用和修改模型,推动AI技术的民主化和透明化。未来,随着技术的不断进步,LLaVA和LLaMA将在更多领域发挥重要作用,为人类带来更智能、更便捷的生活。
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!