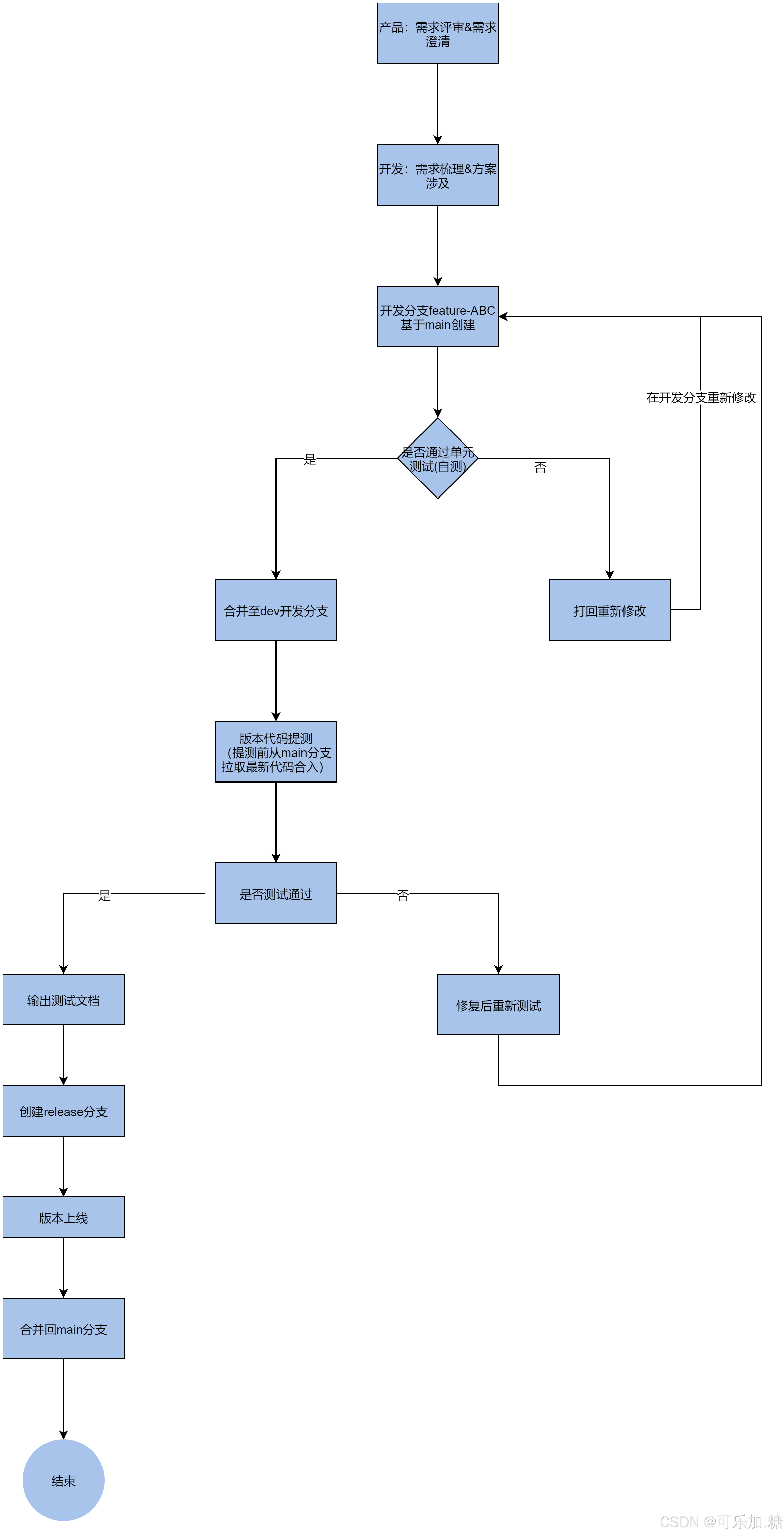
Redis解析
一、单线程模型
redis在io层面是多线程的,在数据处理层面是单线程的。
多线程一般用于:
- 关闭连接
- 删除/淘汰内存
- 网络IO
1.1 io多路复用
redis使用nio(select、poll、epoll)的方式处理socket
- 主线程负责接收建立连接请求,获取socket,并放入等待队列中
- 主线程轮询将可读的socket分配给io线程
- 主线程阻塞等待io线程读取socket完成
- 主线程指向io线程读取和解析出来的redis请求命令
- 主线程阻塞等待io线程将指令执行结果回写回socket
- 主线程清空队列,等待客户端后续请求
Redis线程模型(接收请求并返回数据流程)
- 主线程接收请求,获取socket,放入队列
- 主线程通过nio获取可读的socket,分配给io线程 (1、2涉及到nio(select、poll、epoll,主流是epoll))
- io线程解析socket(读取数据并解析为redis命令),将解析后的请求放入请求队列
- 主线程从请求队列中读取请求,执行操作
- 主线程将执行结果放入特定的结果队列(每个IO线程对应一个队列)
- io线程将数据写入客户端socket的内核发送缓冲区,然后通过网卡发送给用户。
二、Redis的过期删除和淘汰策略
Redis如何判断key已经过期?
typedef struct redisDb {
dict *dict; /* 数据库键空间,存放着所有的键值对 */
dict *expires; /* 键的过期时间 */
....
} redisDb;
将key设置过期时间时,redis会把该key带上过期时间存储到一个过期字典中,过期字典的key是设置的key,value是long long类型,存储key的过期时间
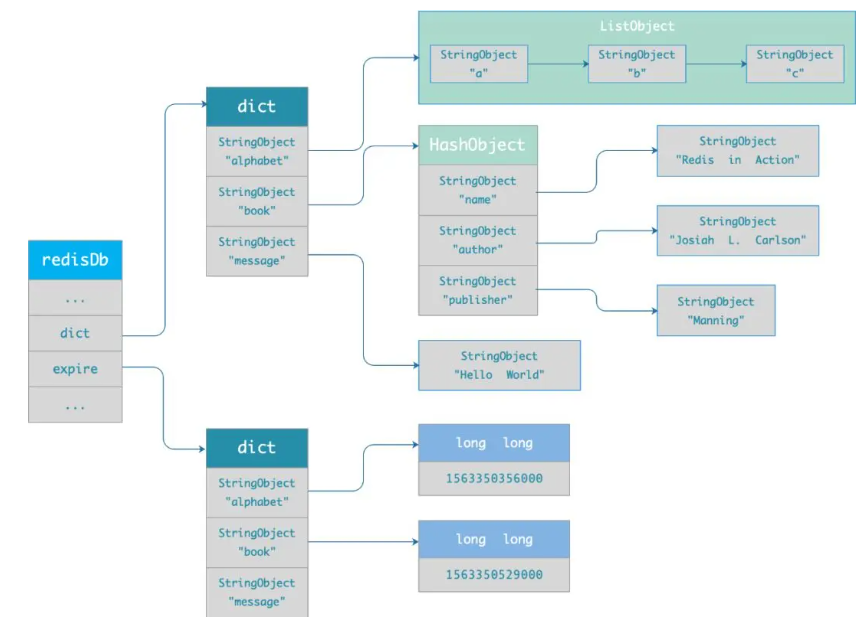
由图中可以看到redis存储数据就是一个大的dict,实际就是hash表
- 读取数据的时候如果key存在,还需要读取过期字典(如果没有设置过期时间不会存储在过期字典中,直接正常返回结果即可),获取key的过期时间,然后与当前系统时间比对
2.1 过期删除策略
- 定时删除
- 惰性删除
- 定期删除
定时删除
在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。
优点:
可以保证过期 key 会被尽快删除,也就是内存可以被尽快地释放。因此,定时删除对内存是最友好的。
缺点:
在过期 key 比较多的情况下,删除过期 key 可能会占用相当一部分 CPU 时间,在内存不紧张但 CPU 时间紧张的情况下,将 CPU 时间用于删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。所以,定时删除策略对 CPU 不友好。
惰性删除
不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
优点:
对CPU友好
缺点:
如果有些过期的数据后面再也没有被访问,就不会被删除,这样就会造成内存泄漏
定期删除
每隔一段时间随机从数据库中取出一定数量的key进行检查,如果过期就删除
例如:抽查20个,如果删除数量大于阙值(例如是4),则继续抽查,时间最大为25ms,超过25ms就结束
优点:
限制删除频率,缓解CPU压力,也能在一定程度上释放内存
缺点:
需要调整删除间隔和随机抽查策略,如果间隔过短,对CPU不友好,如果随机抽查效果不好,对内存不友好。
Redis使用策略:惰性删除+定期删除
2.2 内存淘汰策略
当redis内存达到最大设定的运行内存的时候,也就是说redis满了的时候,使用内存淘汰策略,删除一些key
八大淘汰策略
-
noeviction:如果redis执行增/改,会报错,如果执行查询或删除,可以正常执行
-
volatile-random:随机淘汰设置了过期时间的key-value
-
volatile-ttl:优先淘汰更早过期的k-v
-
volatile-lru:淘汰设置了过期时间的k-v中最久未使用的
-
volatile-lfu:淘汰设置过期的k-v中最少使用的
-
allkeys-random:随机淘汰任意kv
-
allkeys-lru:淘汰所有kv中最久未使用的
-
allkeys-lfu:淘汰所有kv中最少使用的
LRU算法内存污染问题:
redis处理:使用lfu算法(最多使用指的是频率高)
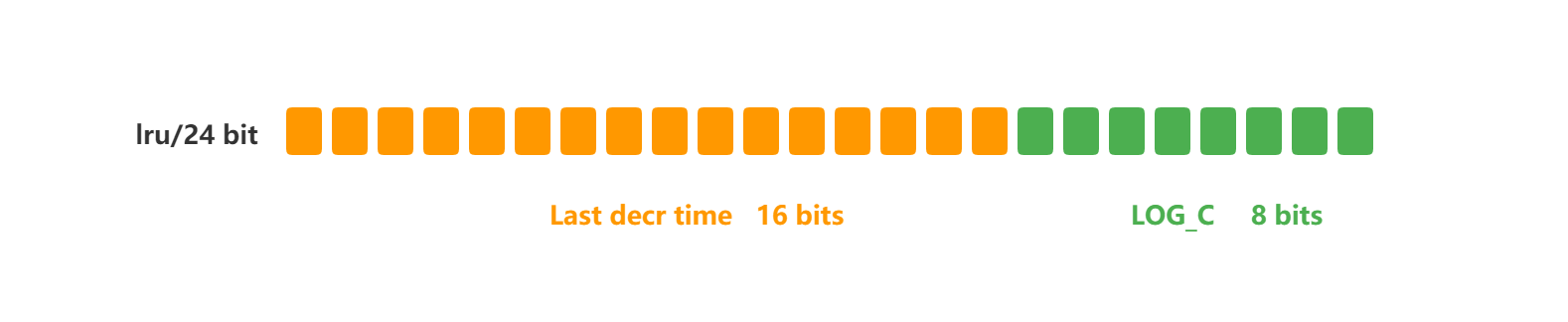
- ldt 是用来记录 key 的访问时间戳;
- logc 是用来记录 key 的访问频次,它的值越小表示使用频率越低,越容易淘汰,每个新加入的 key 的logc 初始值为 5。
每次访问会修改logc的值,根据当前时间的时间戳和记录的时间戳,也就是数据访问的时间差,来增加或减少logc的值
mysql处理:设置访问时间阈值
三、 持久化
RDB和AOF
AOF和RDB同时开启,只会用AOF,即使此时AOF文件因为异常原因不存在,也不会用RDB,原因就是既然开启了AOF就是说明你想要AOF少丢数据的能力,所以即使没有AOF文件也不会用RDB,这样异常你也能发现及时处理,不然后者丢了数据就是潜在风险
bgsave:是通过子进程执行而不是子线程
3.1 RDB
写入RDB文件:
- save
- bgsave
- 多少秒内执行写文件的次数超过多少
- 程序正常关闭前会执行一次持久化写入
写入RDB文件流程:
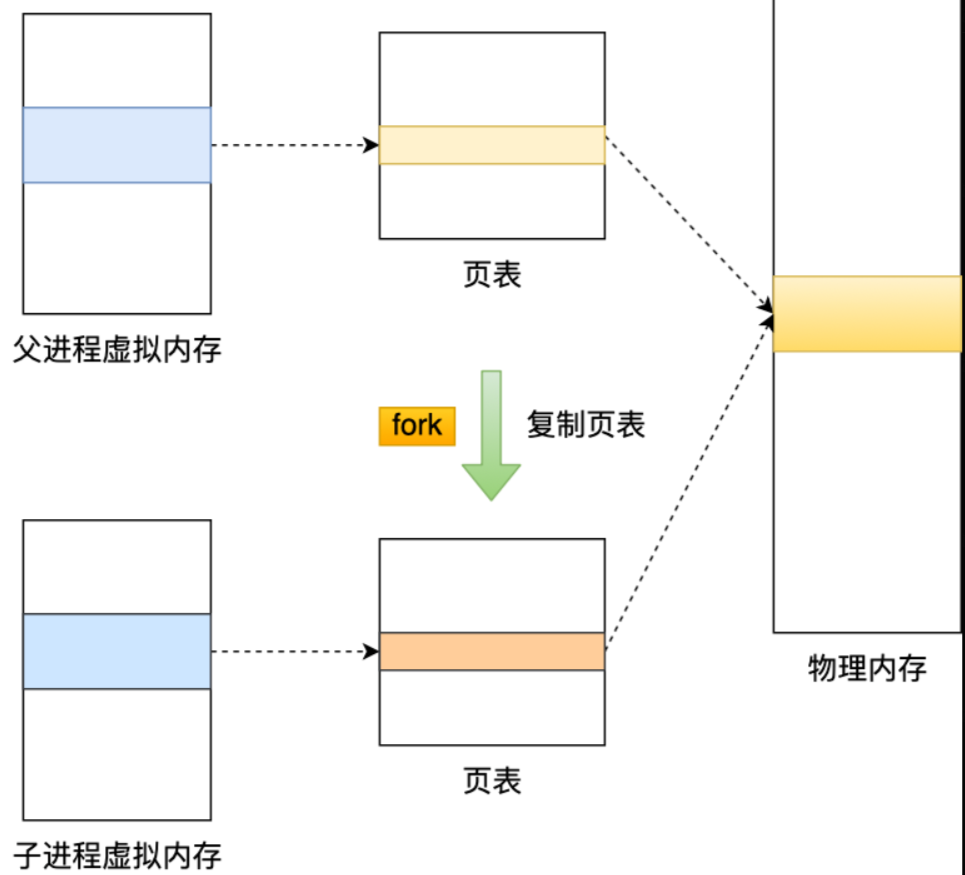
- fork一个子进程
- 子进程写数据到临时的RDB文件
- 写完之后用新的RDB替换旧的RDB文件
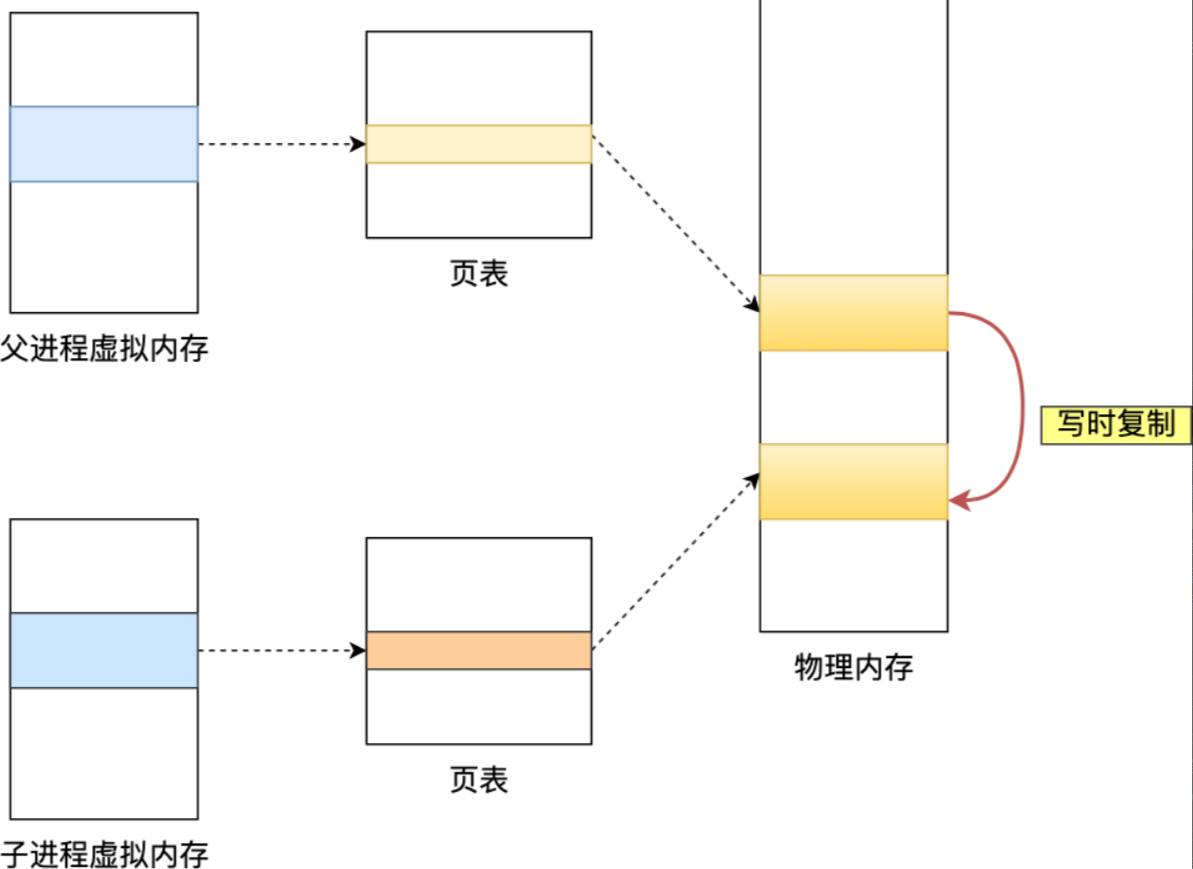
fork创建子进程之后,通过写时复制技术,子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。
所以刚开始的时候,主子进程共享同一个物理内存,但是如果主进程需要修改数据,会copy一个新的物理内存,旧的留给子进程使用,当子进程使用完之后会删除旧的那部分内存,在RDB写入过程中,这片内存存储的就是此刻Redis数据库中的数据
3.2 AOF
AOF开启后,在重启的时候会使用AOF恢复。
如果设置了过期时间的key ttl 只能是最新的了嘛?
答:不会,AOF在写入的时候会将过期时间转换成具体的事件,所以在恢复的时候会设置成具体的过期事件,但是恢复的时间点,如果过期了的键不会被删除。
3.2.1 AOF写入方式
- always:每次请求都刷入AOF,性能低,数据丢失小
- everysec:每秒刷入一次,性能数据丢失折中
- no:不主动刷盘,将刷盘操作交给操作系统,Linux一般每30秒刷一次,性能高,丢失数据风险大
3.2.2 写入AOF流程
- 写入aof_buff(aof缓冲区)
- write到内核缓冲区
- fsync到磁盘
3.2.3 AOF重写机制
-
当AOF文件超过设定阈值的时候,就需要对文件进行重写。
-
AOF 重写机制是在重写时,读取当前Redis中的所有键值对,然后将每一个键值对用一条命令记录到「新的 AOF 文件」,等到全部记录完后,就将新的 AOF 文件替换掉现有的 AOF 文件。
-
为什么写到新的AOF文件:因为如果写到就得AOF文件,且在过程中出错了,那就造成了AOF文件污染了。
-
Redis写入AOF是在主进程完成的,重写AOF是在子进程中完成的(fork子进程bgrewriteaof),原理和子进程写RDB文件一样,写时复制
-
在子进程重写时,主进程会将后续操作写入aof重写缓冲区,当子进程完成重写后,主进程再将缓冲区的指令写入新的aof中
注:AOF重写和RDB写入都涉及到子进程,所以在写时复制会对主进程造成阻塞,此外在子进程完成操作通知主进程的时候也会发生阻塞
3.3 混合持久化
本质就是AOF重写。
发生在AOF重写阶段,将当前状态保存为RDB二进制内容,写入新的AOF文件,再将重写缓冲区的内容追加到新的AOF文件,最后替代原有的AOF文件。
四、事务
4.1 ACID
redis提供了四个命令支持事务机制:
- MULTI:开启事务
- EXEC:提交事务
- DISCARD:放弃事务,情况命令队列
- WATCH:检测一个或多个键的值在事务执行期间是否发生变化,如果发生变化,就放弃当前事务
Redis使用multi命令开启事务,exec提交事务,中间的指令存在一个队列中,在提交时:
- 命令入队时报错(语法错误),会放弃事务执行,保证原子性
- 命令入队时没有报错但是执行时报错,如果开启了AOF,保证原子性,如果没有开启则不会保证原子性
4.2 Lua
- 会被redis当作事务执行
- 如果出错,后续指令不会再执行,但是前面执行成功的指令不会回滚
为什么multi需要watch而Lua不需要?
答:因为multi是命令存储,从指定命令到开始执行会存在时间差,那么这段时间就可能数据被修改,而Lua是直接将命令交给Redis并开始执行,因为是单线程,所以不会存在数据被其他线程修改。
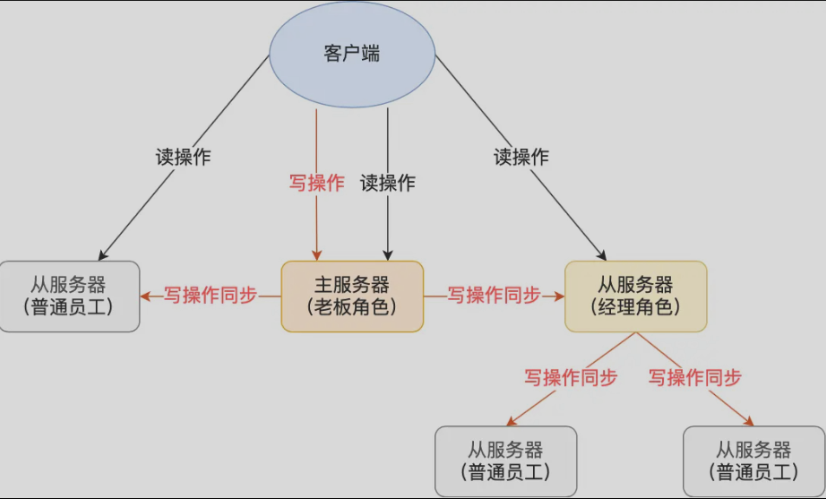
五、主从复制
- 全量复制
- 增量复制
-
全量复制:从服务器使用psync runid offset,向主服务器发送同步请求,主服务器接收到之后发送rdb文件给从服务器,并在主服务器产生rdb文件、从服务器加载RDB文件的过程中,将新的指令写入replication buffer中,从服务器完成之后,再将缓冲区中的指令发送给从服务器。
-
增量复制:主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接。是一个长连接,后续主服务器可以通过这个连接继续将写操作命令传播给从服务器,然后从服务器执行该命令。
增量复制过程中,如果网络断开,网络恢复后,如何处理
- 再进行一次全量复制
- 根据offset进行增量复制
具体选择:主服务器中有一个环形缓冲区,记录主服务器写指令的顺序。主服务器在开始网络正常的时候,会将写指令发送给从服务器,并将写指令存入环形缓冲区中,此外更新对应的offet。当从服务器发送offset时,判断从服务器要读取的数据是否在环形缓冲区,如果在就进行增量复制,如果不再就进行全量复制。
从机不是越多越好:
- 在全量复制的时候,主服务器需要生成rdb文件,fork子进程,会阻塞主进程,如果内存数据很大,会阻塞很久
- 主服务器向从服务器发送rdb文件会占用网络带宽,会对主服务器响应命令请求产生影响。
所以可以使用一个中间的从服务器,减轻主服务器的压力
六、哨兵模式
主观下线:某个哨兵判断主节点下线
客观下线:对于主节点,由于网络压力或系统压力,导致主节点没有及时给哨兵响应,经过多个哨兵决断后判断确实下线。
为了减少误判的情况,哨兵在部署的时候不会只部署一个节点,而是用多个节点部署成哨兵集群(最少需要三台机器来部署哨兵集群),通过多个哨兵节点一起判断(投票机制),就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。
为什么哨兵节点至少要有 3 个?
成为Leader必须获得一半的票数+1,如果是2个哨兵,则需要两票,挂了一个,最多只能获得一票,无法进行主从节点切换。如果 3 个哨兵节点,挂了 2 个怎么办?人为介入或增加哨兵节点数
哨兵的数量建议为奇数,quorum值(判断主节点是否单机的投票数)建议为哨兵节点数/2+1
两个投票:
- quorum值决定的主节点是否宕机的投票:如果投票结果大于等于quorum值,则判定宕机
- leader投票:判定主节点宕机后,选举leader哨兵,候选人是最先发现主节点宕机的哨兵(可能同一时刻有多个哨兵同时发现哨兵宕机),如果某个哨兵获取到大于等于一半加一的票数,且票数大于等于quorum值,则升级为leader。
主从故障转移
步骤:
- 在原主节点的从节点中选出一个作为新的主节点
- 修改其他的从节点的复制对象为新的主节点
- 将新的主节点的ip地址和信息通知给客户端
- 继续监视原主节点,当其恢复时设置为新主节点的从节点
- 选出新主节点:先过滤掉网络状态不好的节点,然后根据优先级、复制进度、ID号选择。
- 优先级:例如配置高的机器可以设置高优先级
- 复制进度:比较offset(选offset偏移量大的从节点,与原主节点offset偏移量差值小)
- ID号选择:选择id小的从节点
、
、
主节点故障并转移的步骤总结:
判断主节点故障 ——> 选举哨兵Leader ——> Leader选择新的主节点(优先级、复制量、id号) && 修改其他节点 && 通知客户端 && 监听原主节点
哨兵集群的组成
-
哨兵之间是如何连接的:通过 Redis 的发布者/订阅者机制来相互发现的。哨兵把自己的信息发送到_sentinel_: hello 频道,然后可以互相连接
-
哨兵在配置时候会指定主节点ip,通过向主节点发送info信息,获取从节点信息,并和从节点建立连接。
脑裂问题
脑裂就是指在同一时间主从集群中出现了两个主节点,会导致数据丢失。
-
网络问题:由于主节点和哨兵节点之间的网络问题,使得哨兵节点判断主节点客观下线,设置新的主节点,此时存在两个节点
-
负载问题:由于负载过高,主节点无法及时响应哨兵的心跳
数据丢失:新主节点发起全量复制,导致原主节点写数据丢失
解决:
- 与主节点连接的从节点数要尽可能多,建议配置为从节点一半加1
- 主节点与从节点的网络延迟要尽可能低,配置一个阙值。
七、集群
当redis内存使用很大的时候,虽然服务器配置的内存足够,但是在使用过程中,持久化fork操作由于内存很大(写时复制),需要阻塞主线程很长时间,所以内存很大时,需要使用集群,将大内存分散成多个小内存,这样就使得持久化操作不会阻塞很长时间
切片和实例(Redis节点)的对应关系
Redis集群使用hash槽(slot)根据key映射关系确定存储,一个切片集群共16384个hash槽,每个key会被映射到一个hash槽,集群中每个节点负责一部分hash槽。在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
客户端如何定位数据
-
实例-实例:实例之间会相互连接,组成集群,连接的时候会发送自己的hash槽信息,完成hash槽的分配信息扩散,实例之间通过Gossip协议进行交互,每个实例不需要和其他所有实例都建立连接。
-
客户端-实例:客户端连接任意实例的时候,实例就会把所有哈希槽的分配信息发送给客户端,这样客户端就知道所有实例的映射关系了。
重定向机制:
在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍,客户端访问新数据需要借助moved/ask命令。
- moved:当客户端访问实例中的hash槽时,由于hash槽已经迁移至其他实例,该实例会使用moved命令,客户端会修改hash槽的映射关系
- ask:hash槽在迁移过程中被访问(还未迁移完成),使用ask命令,不会修改客户端hash槽的映射。只针对已经迁移过去的key,如果key还未被迁移,则直接返回结果
八、Redis应用场景
8.1 缓存异常问题
缓存击穿、缓存穿透、缓存雪崩
解决:
-
缓存穿透:
- 设置不存在的k,v设置为null,放置在缓存中,并设置过期时间(建议30秒,太长可能导致后面增加这条数据缓存出现不一致问题,太短不能有效避免穿透)
- 接口层校验,对于异常信息直接拦截,例如id<0
- 布隆过滤器
-
缓存雪崩:
- 设置随机数,使得kv在一段时间内随机过期
- 互斥锁:使用互斥锁,使得允许只有一个线程能获取锁去查数据库,从而更新缓存。(需要设置过期时间)可以多设置几把锁,但是数量不能太多,以免db崩溃
- 后台更新缓存
- redis宕机引起的宕机:使用服务熔断或请求限流;构建主从集群
-
缓存击穿:
- 互斥锁
- 设置热点数据永不过期,或者在数据快要过期时通知后台线程重新设置过期时间
8.2 缓存一致问题
- 先修改数据库,再删除缓存
(如果由于网络原因,导致删除缓存请求再回写缓存之前,会出现数据不一致问题(如图所示);或者删除缓存时redis宕机,恢复之后也会出现数据不一致问题)
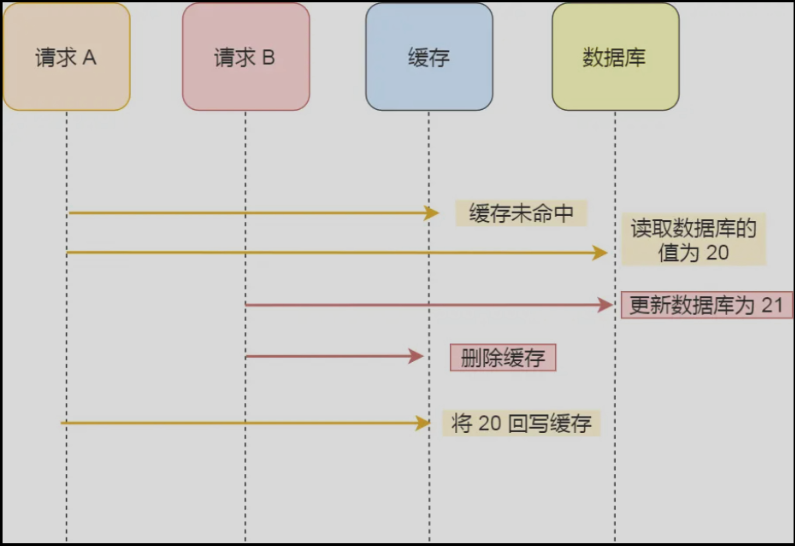
- 延迟双删
8.3 分布式锁
- 过期时间和存kv原子操作(set key v ex xx nx)
- owner
- 检查是否是owner和delete要原子操作,lua脚本
红锁和锁丢失
8.3.1 NPC问题(没有完全可靠的分布式锁):
N:Network Delay(网络延迟),锁在redis中设置的时间,到客户端认为自己获取到锁的时间,中间存在网络延迟差。
P:Process Pause(进程暂停),进程运行过程中发送GC,使得redis中实际锁已经过期,但是线程还认为自己持有锁(GC导致时间差)
C:Clock Drift(时钟漂移),由于原来线程时钟漂移,使得实际已经锁过期,原来线程还是认为自己持有锁,则此时会发生多个线程获取锁。
总结:NPC问题本质就是由于时间差导致原线程仍然认为自身持有锁,但是实际上锁已经过期
8.3.2 Redisson
可重入:
使用hash结构,记录锁的重入次数,每次释放,重入次数减一,减到0的时候将锁删除
重试机制:
tryLock(获取锁的最大等待时间,过期时间,过期时间的单位)
WatchDog机制:
如果设置了过期时间,则不会使用看门狗机制,如果没有设置过期时间,则默认看门狗机制是30秒一次,且会一直续期。
8.4 Hot key、Big key(数据倾斜):
Hot Key处理:
- 读写分离(多级缓存)
- 拆分
Big Key处理:
- 拆分
- 压缩
8.5 秒杀
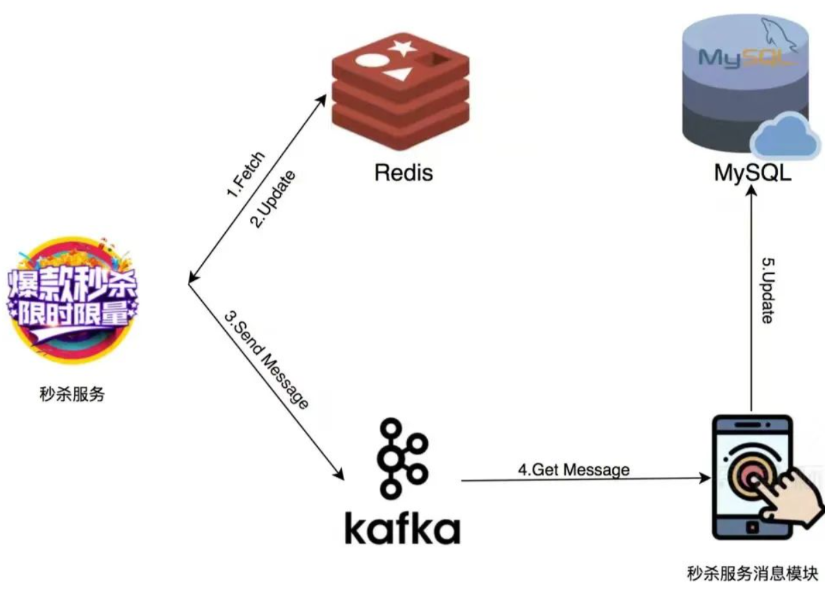
处理超卖:
使用lua脚本,使得redis判断是否有库存和更新库存是原子操作
处理少卖:
少卖出现场景:
- 图中第2步,实际是更新成功的,但是由于redis返回结果(可能由于网络原因)超时
- 第3步发送给消息队列生成订单失败
第二种情况出现解决方案:
- kafka的渐进式重试(先1s后重试一次,再2s、4s、8s…)
- 第一种方案的基础上,将这条消息记录在磁盘上,慢慢重试;