文章目录
- 一、如何实现一条用例,实现覆盖所有用例的测试
- 1、结合数据驱动:编辑一条用例,外部导入数据实现循环测试
- 2、用例体:实现不同用例的操作步骤+对应的断言
- 二、实战
- 1、项目路径总览
- 2、common 文件夹下的代码文件
- 3、keywords 文件夹下的代码文件
- 4、testcases 文件夹下的代码文件
- 4、testdata 文件夹下的 case_data.xlsx 文件
- 5、config.py 文件
- 三、web 自动化测试完结-项目代码(总)
一、如何实现一条用例,实现覆盖所有用例的测试
1、结合数据驱动:编辑一条用例,外部导入数据实现循环测试
2、用例体:实现不同用例的操作步骤+对应的断言
- 封装对应的方法,可以执行所有用例的操作步骤+断言
二、实战
通过读取 excel 数据,进行数据驱动自动化测试
通过反射函数,实现关键字驱动
即使不懂代码的人,也能通过编辑 excel 数据进行测试
1、项目路径总览
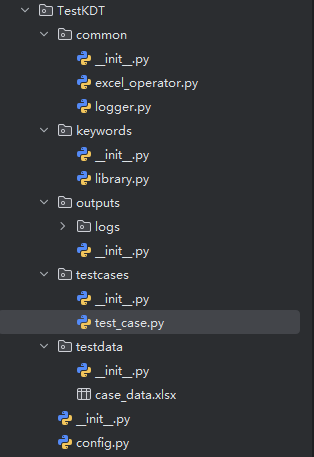
2、common 文件夹下的代码文件
2.1 excel_operator.py 文件
是对 excel 操作进行封装的方法
import os.path
import time
import openpyxl
from TestKDT import config
from openpyxl.styles import Font,PatternFill,colors
class ExcelOperator:
"""
操作 excel 文件
"""
def __init__(self,filename=os.path.join(config.testdata_dir,"case_data.xlsx")):
# 获取到测试用例 excel 的文件路径
self.file_path = filename
# 获取到测试用例 excel 工作簿
self.wk = openpyxl.load_workbook(filename)
def get_case_data(self):
# """获取 excel 工作簿中所有工作表的数据"""
# self.sheetnames = self.wk.sheetnames
"""获取 excel 工作簿中要执行的用例工作表的数据"""
self.sheetnames = self.get_cases_name()
values= []
# 循环每个工作表
for sheet_name in self.sheetnames:
# 获取某个工作表某个区间列的数据
value = self.get_startcol_endcol_value(sheet_name)
case_data = {'case_name': sheet_name, 'steps_data': value}
values.append(case_data)
return values
# 获取执行用例的工作表名称
def get_cases_name(self):
# 获取汇总用例的工作表
cases_sheet = self.wk[config.cases_sheet_name]
cases_name = []
# 根据是否执行,取到用例的名称
for row in range(2,cases_sheet.max_row+1):
# 循环汇总表每一行数据
is_execute = cases_sheet.cell(row, config.case_is_execute).value
if is_execute=="y":
case_name = cases_sheet.cell(row, config.case_name).value
cases_name.append(case_name)
return cases_name
# 获取某个工作表某个区间列的数据
def get_startcol_endcol_value(self,sheetname,startcol=config.keyword_col,endcol=config.action_col):
# 获取工作表
sheet = self.wk[sheetname]
values = []
# 循环对应工作表中的每一行数据
for row in range(2,sheet.max_row+1):
step_data = []
for col in range(startcol,endcol+1):
value = sheet.cell(row=row,column=col).value
if value is not None:
step_data.append(value)
values.append(step_data)
return values
# 将测试步骤的结果写入 excel 文件的用例工作表中
def write_step_result(self, sheet_name, row, col, result):
"""写入测试步骤的结果"""
case_sheet = self.wk[sheet_name]
# 写入每步操作步骤结束时间
self.write_current_time(case_sheet,row,config.step_end_time)
# 写入测试步骤的结果
case_sheet.cell(row, col).value = result
# 颜色填充 绿色通过 红色失败
red_fill = PatternFill(fill_type="solid", fgColor="00FF0000")
green_fill = PatternFill(fill_type="solid", fgColor="0000FF00")
if result == 'FAIL':
case_sheet.cell(row, col).fill = red_fill
else:
case_sheet.cell(row, col).fill = green_fill
self.wk.save(self.file_path)
# 将测试用例的结果写入 excel 文件的用例汇总表中
def write_cases_result(self, case_name, sheet_name=config.cases_sheet_name, col=config.case_result,):
"""写入测试用例的结果"""
cases_sheet = self.wk[sheet_name]
for row in range(2,cases_sheet.max_row+1):
# 循环汇总表的每一行
col_case_name = cases_sheet.cell(row, config.case_name).value
if col_case_name == case_name:
# 获取执行的用例
case_name = cases_sheet.cell(row, config.case_name).value
sheet = self.wk[case_name]
# 写入每条测试用例的结束时间
self.write_current_time(cases_sheet, row, config.case_end_time)
# 获取每条执行用例的结果
steps_result = self.get_sheet_col_value(sheet=sheet, col=config.step_result)
# 颜色填充 绿色通过 红色失败
red_fill = PatternFill(fill_type="solid", fgColor="00FF0000")
green_fill = PatternFill(fill_type="solid", fgColor="0000FF00")
# 将结果写入汇总表中
if 'FAIL' in steps_result:
cases_sheet.cell(row, col).value = 'FAIL'
cases_sheet.cell(row, col).fill = red_fill
else:
cases_sheet.cell(row, col).value = 'PASS'
cases_sheet.cell(row, col).fill = green_fill
self.wk.save(self.file_path)
def get_sheet_col_value(self, sheet, col):
"""获取某个工作表某列的所有数据"""
values = []
for row in range(2, sheet.max_row + 1):
step_col_value = sheet.cell(row, col).value
values.append(step_col_value)
return values
def write_current_time(self, sheet, row, col):
"""将当前时间写入某个表格中"""
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
sheet.cell(row, col).value = current_time
if __name__ == '__main__':
# print(ExcelOperator().get_startcol_endcol_value("登录",3,6))
print(ExcelOperator().get_cases_name())
2.2、logger.py 文件
和之前 POM 的日志一样
import logging
import os
import time
from TestKDT import config
class FrameLogger:
def get_logger(self):
# 创建日志器
logger = logging.getLogger("logger")
# 日志输出当前级别及以上级别的信息,默认日志输出最低级别是warning
if not logger.handlers:
logger.setLevel(logging.INFO)
# 创建控制台处理器----》输出控制台
SH = logging.StreamHandler()
# 创建文件处理器----》输出文件
log_path = os.path.join(config.logs_dir, f"log_{time.strftime('%Y%m%d%H%M%S', time.localtime())}.txt")
FH = logging.FileHandler(log_path,mode="w",encoding="utf-8")
# 日志包含哪些内容 时间 文件 日志级别 :事件描述/问题描述
formatter = logging.Formatter(fmt="[%(asctime)s] [%(filename)s] %(levelname)s :%(message)s",
datefmt='%Y/%m/%d %H:%M:%S')
logger.addHandler(SH)
logger.addHandler(FH)
SH.setFormatter(formatter)
FH.setFormatter(formatter)
return logger
3、keywords 文件夹下的代码文件
3.1 library.py 文件
是对各种关键字函数的封装
import os
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from TestKDT import config
from TestKDT.common.logger import FrameLogger as log
class Library:
# 登录用例 = 多个操作步骤组成 基于每个操作步骤封装对应的关键字函数
# 登录用例:
# 1、打开浏览器- 关键字函数- open_browser()
# 2、加载项目地址- 关键字函数- load_url()
# 3、输入用户名- 关键字函数- input()
# 4、输入密码- 关键字函数- input()
# 5、点击登录- 关键字函数- click()
def __init__(self):
self.logger = log().get_logger()
def open_browser(self,browser):
"""打开浏览器"""
# 传入的浏览器参数保持首字母大写
browser = browser.capitalize()
# 获取不同类型的浏览器驱动
try:
self.driver = getattr(webdriver, browser)()
self.logger.info(f"打开{browser}浏览器成功")
except:
self.logger.error(f"打开{browser}浏览器失败")
raise
def load_url(self, url):
"""加载地址"""
try:
self.driver.get(url)
self.logger.info(f"加载项目地址{url}成功")
except:
self.logger.error(f"加载项目地址{url}失败")
raise
# 等待元素可见
def wait_ele_visibility(self, page_name, loc, timeout=15, poll_fre=0.5):
try:
WebDriverWait(self.driver, timeout, poll_fre).until(EC.visibility_of_element_located(loc))
# WebElement对象
self.logger.info(f"在[{page_name}]页面,找到元素:{loc}可见")
except:
self.logger.error(f"在[{page_name}]页面,未找到元素:{loc}可见!!!")
raise
# 等待元素存在
def wait_ele_presence(self, page_name, loc, timeout=15, poll_fre=0.5):
try:
WebDriverWait(self.driver, timeout, poll_fre).until(EC.presence_of_element_located(loc))
self.logger.info(f"在[{page_name}]页面,找到元素:{loc}存在")
except:
self.logger.error(f"在[{page_name}]页面,未找到元素:{loc}存在!!!")
raise
def locator(self, page_name, by_type, express):
# 定位元素
try:
el = self.driver.find_element(by_type, express)
self.logger.info(f"在[{page_name}]页面,通过[{by_type}]方法和[{express}]语句,定位元素成功")
except:
self.save_screenshot(by_type)
self.logger.error(f"在[{page_name}]页面,通过[{by_type}]方法和[{express}]语句,定位元素失败!!!")
raise
return el
def input(self, page_name, by_type, express, text):
"""输入"""
loc = (by_type, express)
try:
self.wait_ele_visibility(page_name, loc)
self.locator(page_name,by_type, express).send_keys(text)
self.logger.info(f"在[{page_name}]页面,元素{loc}输入:{text} 成功!")
except:
self.logger.error(f"在[{page_name}]页面,元素{loc}输入失败!")
# 失败截图
self.save_screenshot(page_name)
raise
def click(self, page_name, by_type, express):
"""点击"""
loc = (by_type, express)
try:
self.wait_ele_visibility(page_name, loc)
self.locator(page_name,by_type, express).click()
self.logger.info(f"在[{page_name}]页面,元素{loc}点击成功!")
except:
self.logger.error(f"在[{page_name}]页面,元素{loc}点击失败!")
# 失败截图
self.save_screenshot(page_name)
raise
def move_element(self, page_name, by_type, express):
"""移动鼠标"""
loc = (by_type, express)
try:
self.wait_ele_visibility(page_name, loc)
el = self.locator(page_name, by_type, express)
# 将鼠标移到元素上
ActionChains(self.driver).move_to_element(el).perform()
self.logger.info(f"在[{page_name}]页面,鼠标移到元素{loc}成功!")
except:
self.logger.error(f"在[{page_name}]页面,鼠标移到元素{loc}失败!")
# 失败截图
self.save_screenshot(page_name)
raise
def assert_text(self,page_name, by_type, express, expect):
"""断言"""
loc = (by_type, express)
try:
self.wait_ele_visibility(page_name, loc)
el = self.locator(page_name, by_type, express)
fact = el.text
self.logger.info(f"在[{page_name}]页面,元素{loc}文本内容获取成功!")
except:
self.logger.error(f"在[{page_name}]页面,元素{loc}文本内容获取失败!")
# 失败截图
self.save_screenshot(page_name)
raise
if fact == expect:
pass
else:
raise Exception(f"在[{page_name}]页面,断言失败,assertText:{fact} != {expect}")
def save_screenshot(self,img_name):
file_name = os.path.join(config.screenshots_dir, img_name+'.png')
self.driver.save_screenshot(file_name)
self.logger.error(f"失败截图,截取当前网页,存储的路径:{file_name}")
# 封装方法,可以调用当前类下的所有关键字函数
# *args:不定长参数
def run(self,keyword,*args):
print(keyword, args)
# 实现打开浏览器
# keyword = "open_browser"
# args = ("edge",)
# 调用关键字函数,基于反射
getattr(self, keyword)(*args)
4、testcases 文件夹下的代码文件
4.1 test_case.py 文件
编写测试用例
import time
import unittest
from selenium.webdriver.common.by import By
from TestKDT.keywords.library import Library
from ddt import ddt,data,file_data,unpack
from TestKDT.common.excel_operator import ExcelOperator
from TestKDT import config
@ddt
class TestCase01(unittest.TestCase):
# 如何实现一条用例,实现覆盖所有用例的测试
# 每条用例的数据: 关键字函数 + 测试数据
# case_data = [["open_browser","edge"],["load_url","http://116.62.63.211/shop/user/logininfo.html"],
# ["input",(By.NAME, "accounts"), "hc_test"],
# ["input",(By.XPATH, '//input[@type="password"]'),"hctest123"],
# ["click",(By.XPATH, '//button[text()="登录"]')]]
excel = ExcelOperator()
case_data = excel.get_case_data()
@data(*case_data)
def test_cases(self,case_data):
# 打印每条用例的数据
print(case_data)
case_name = case_data['case_name']
steps_data = case_data['steps_data']
# 用例体 = 操作步骤+ 断言
# 封装对应的方法,可以执行所有用例的操作步骤 + 断言
lib = Library()
for index, step_data in enumerate(steps_data):
try:
# 执行用例的操作步骤
lib.run(*step_data)
# 当前执行步骤为 PASS
# index 0 行数 2 因为第一行不是测试数据,而是列说明
self.excel.write_step_result(sheet_name=case_name, row=index+2, col=config.step_result, result="PASS")
except Exception as error:
# 当前执行步骤为 FAIL
self.excel.write_step_result(sheet_name=case_name, row=index+2, col=config.step_result, result="FAIL")
self.excel.write_cases_result(case_name)
4、testdata 文件夹下的 case_data.xlsx 文件
- 4.1 用例汇总统计
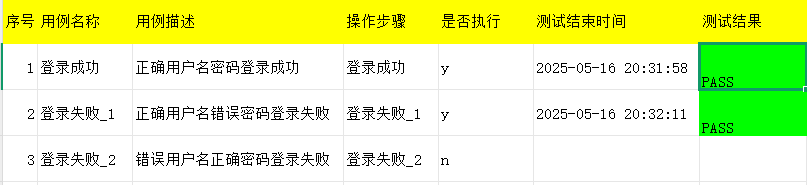
- 4.2 登录成功

- 4.3 登录失败-1

- 4.4 登录失败-2

5、config.py 文件
是项目的路径以及其他数据内容
import os
# 根路径
base_dir = os.path.dirname(os.path.abspath(__file__))
# 用例路径
testcases_dir = os.path.join(base_dir, 'testcases')
# 数据路径
testdata_dir = os.path.join(base_dir, 'testdata')
# 测试报告路径
reports_dir = os.path.join(base_dir, 'outputs/reports')
# 日志路径
logs_dir = os.path.join(base_dir, 'outputs/logs')
# 失败截图
screenshots_dir = os.path.join(base_dir, 'outputs/screenshots')
# 测试用例 excel 中关键字所在列
keyword_col = 3
# 测试用例 excel 中操作值所在列
action_col = 7
# 用例汇总表名称
cases_sheet_name = "用例汇总统计"
# 用例汇总表中是否执行所在列数
case_is_execute = 5
# 用例汇总表中用例名所在列数
case_name = 2
# 用例汇总表中测试结果所在列数
case_result = 7
# 用例汇总表中测试结束时间所在列数
case_end_time = 6
# 用例工作表中执行结果所在列数
step_result = 9
# 用例工作表中执行时间所在列数
step_end_time = 8
# ---调试
print(testdata_dir)
三、web 自动化测试完结-项目代码(总)
Test-Web.zip