1.select语句的语法格式
select 字段列表 from 表名
where 条件表达式
group by 分组字段 [having 条件表达式]
order by 排序字段 [asc|desc];
说明:
from 子句用于指定检索的数据源
where子句用于指定记录的过滤条件
group by 子句用于对检索的数据进行分组
having 子句通常和group by 子句一起使用,用于过滤分组后的统计信息
order by子句用于对检索的数据进行排序处理,默认为升序asc
2.select子句指定字段列表
(1)字段列表可以包含字段名,也可以包含表达式,字段名之间使用逗号分隔,并且顺序可以任意指定
(2)可以为字段列表中的字段名或者表达式指定别名,中间使用as关键字分隔即可
(3)多表查询时,同名字段前必须添加表名前缀,中间使用"."分隔
(4)结果集中的列名为字段列表中的字段名或者表达式名
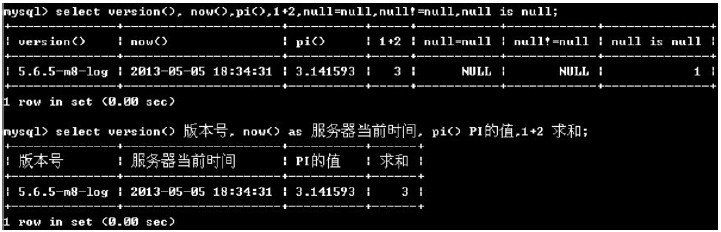
例如:select version(), now(), pi(), 1+2, null=null, null!=null, null is null;的查询如下:
(5)检索表student全部记录
select * from student;
3.使用谓词过滤记录
MYSQL中的两个谓词distinct和limit可以过滤记录
(1)使用谓词distinct过滤结果集中的重复记录
数据库表中不允许出现重复的记录,但这不意味着select的查询结果击中不会出现记录重复的现象。如果需要过滤结果集中重复的记录,可以使用谓词关键字distinct,语法格式如下:
distinct 字段名;
例如:select distinct department_name from classes;
(2)使用谓词limit查询某几行记录
使用select语句时,经常需要返回前几条或者中间某几条记录,可以使用谓词关键字limit实现。语法格式如下:
select 字段列表
from 数据源
limit [start,] length
例如:前三条记录
select * from student limit 0,3; 等效于 select * from student limit 3;
从第二条记录开始的3条记录
select * from choose limit 1,3;
4.使用from指定数据源
在实际应用中,为了避免数据冗余,需要将一张大表划分成若干张小表。但检索数据时,为了更加直观看到所有数据,往往需要将若干张小表缝补连接成成一张大表。连接的方法有两种,一种是在from子句使用连接运算,讲多个数据源按照某种连接条件“缝补”在一起,一种是在where子句中指定连接条件。
通过from指定连接运算的格式如下:
from 表名1 连接类型 join 表名2 on 连接条件;
SQL标准中,连接类型有inner连接和outer连接,而外连接又分为left左外连接,right右外连接以及full完全外连接。
如果表1和表2存在相同意义的字段,则可以通过该字段连接这两张表。例如,在student表中,想要直接看到学生和其班级信息,可以通过班级id把班级信息连接上来。
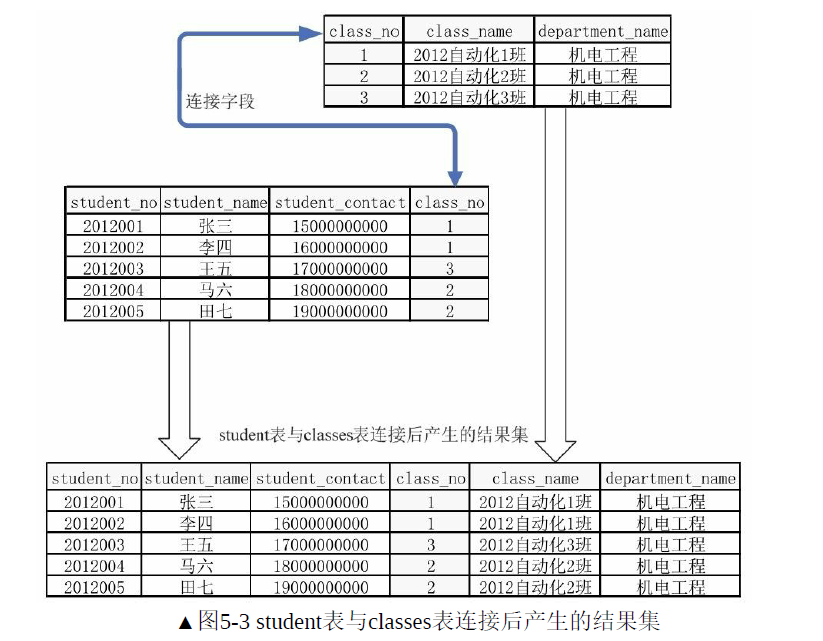
(1)内连接:
from 表1 inner join 表2 on 连接条件
重点:会过滤掉表1和表2的不符合条件的信息
(2)左外连接:
from 表1 left join 表2 on 连接条件
重点:保留表1的全部信息,而表2 不符合的信息则过滤掉,表1如果存在某些匹配不到表2的信息,则该行的表2部分信息都是NULL
(3)右外连接:
from 表1 right join 表2 on 连接条件
重点:保留表2的全部记录,而表1中不符合的信息则过滤掉,表2中如果存在某些匹配不到表1的信息,则该行的表1部分则都是NULL。
(4)全连接:
MYSQL暂不支持全连接运算,不赘述。
5.多表连接
格式如下:
from 表1 连接类型 join 表2 on 连接条件
连接类型 join 表3 on 连接条件
6.使用where子句过滤结果集
(1)单一条件过滤
where 表达式1 比较运算符 表达式2
select * from classes where class_name=‘2012自动化2班’;
(2)is NULL运算
表达式 is [not] NULL
判断表达式的值是否为NULL或者不为NULL
(3)逻辑运算符
逻辑非为符号 !, 一般用于"! 布尔表达式"
例如: select * from course where !(up_limit=60);
等效于: select * from course where up_limit != 60;
(4)and逻辑运算 和 or逻辑运算
布尔表达式1 and|or 布尔表达式2
(5)between … and …
用于判断一个表达式的值是否位于指定的取值范围内
(6)in运算符
in运算符用于判断一个表达式的值是否位于一个离散的数学集合内
格式:表达式 [not] in (数学集合)
例如:select * from student where substring(student_name, 1, 1) in ('张’, ‘田’);
(7)like进行模糊查询
like运算符用于判断一个字符串是否与给定的模式相匹配。模式是一种特殊的字符串,特殊之处在于它不仅包含普通字符,还包含通配符。
格式:字符串表达式 [not] like 模式
通配符:
%(匹配零个或多个字符组成的任意字符串)
_ (匹配任意一个字符)
例如:
检索所有姓张但是名字只有两个字的学生的信息
select * from student where student_name like ‘张_’;
检索姓名中带有’三’的所有学生的信息
select * from student where student_name like ‘%三%’;
7.使用order by排序
order by 字段名1 [asc|desc] […, 字段名n [asc|desc]]
(1)单个排序
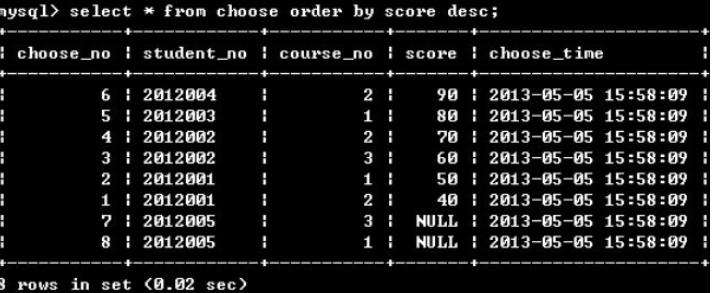
(2)多重排序
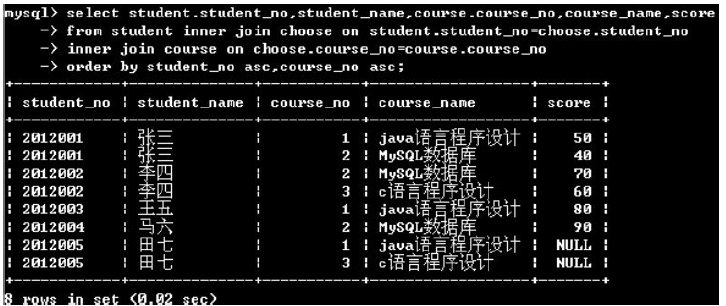
8.使用聚合函数汇总结果集
(1)聚合函数:sum(), avg(), count(), max(),min()
9.使用groupby子句对记录进行分组
格式:group by 字段列表[having 条件表达式][with rollup]
(1)单独使用group by没意义,因为只保留各分组的一条记录
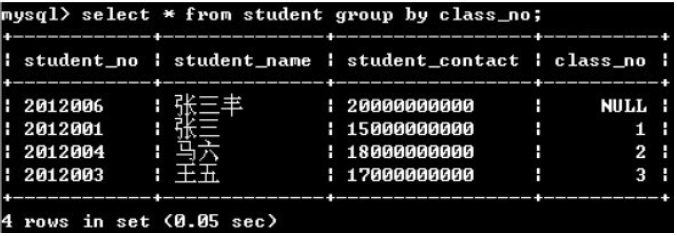
(2)group by + 聚合函数
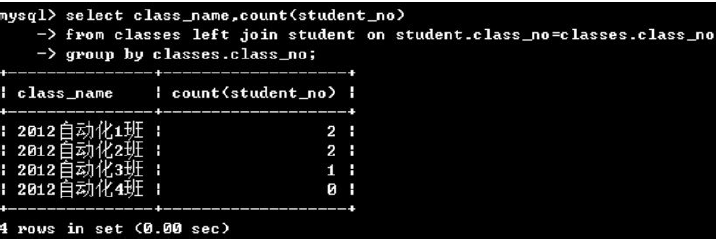
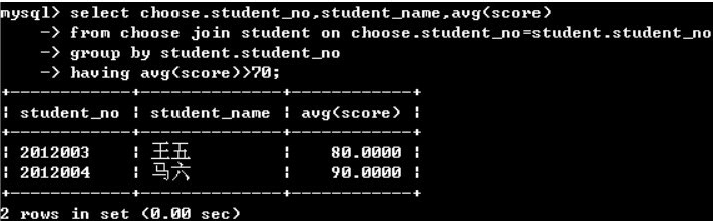
(3)group by +having子句
having子句无法用where代替,因为where和group by和having同时存在的时候,where首先运行,然后group by和having对where运算结果进行过滤筛选。
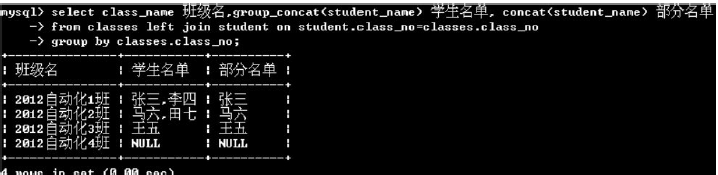
(4)group_concat()
group_concat()函数可以将各个字段的值用逗号连接起来
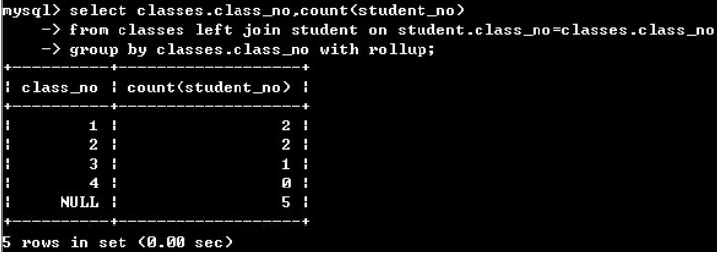
(5)group by + 聚合函数 + with rollup
在原先的group by+聚合函数中,聚合函数处理每个分组,但是没有处理整个表,with rollup在最后加上一行处理整个表的结果
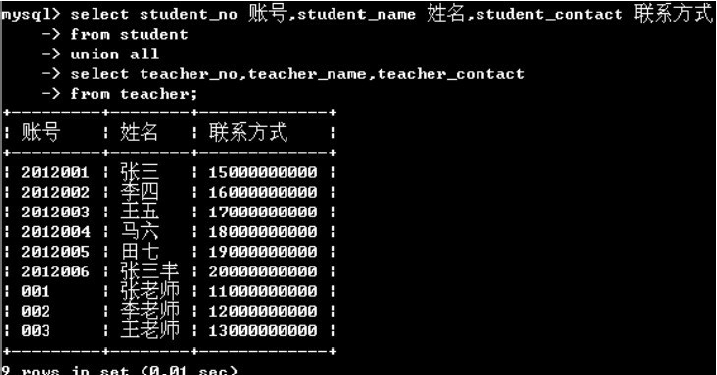
10.合并结果集
格式:
select 字段列表1 from table1
union [all]
select 字段列表2 from table2
要求:字段列表1和字段列表2的字段个数和对应的数据类型必须一致
union和union all 的区别:当使用union时,MYSQL会筛选掉select结果中重复的记录。而是用union all时,MYSQL会直接合并两个结果集。
例如:查询所有学生和老师的联系方式
11.子查询
(1)如果子查询返回单个值,则可以将这个子查询结果和其他表达式的值进行比较
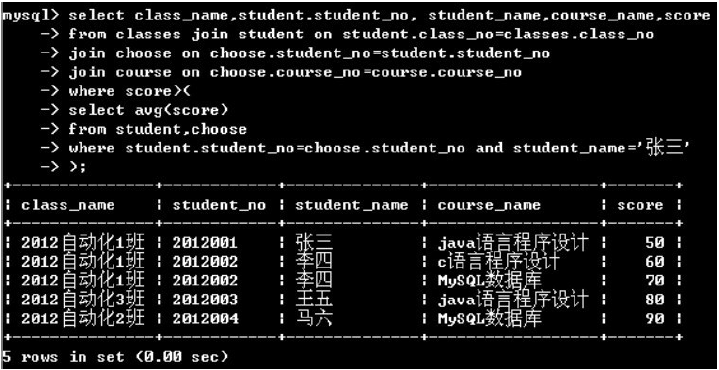
(2)子查询+in运算符
子查询经常与in运算符一起使用,用于将一个表达式的值与子查询返回的一列值进行比较,如果表达式的值是此列中的任何一个值,则条件表达式的结果为true,否则为false
例如:select id, name,sex from human where id in (select human_id from bese_human);
(3)子查询+exists运算符
exists逻辑运算符用于检测子查询结果集中是否包含记录。如果结果集中至少包含一条记录,则exists的结果为true,否则为false
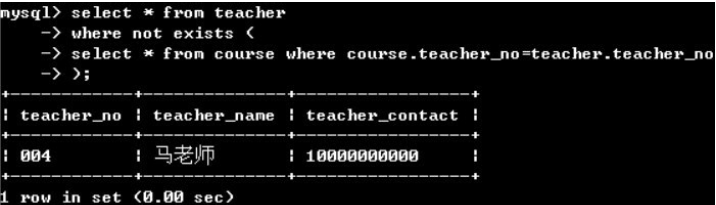
例如:检索没有申请选修课的教师的信息
select * from teacher
where not exists(
select * from course where course.teacher_no=teacher.teacher_no
);
说明:遍历到teacher表一行,则执行子查询,子查询为true则不显示,子查询不是true则展示
(4)子查询+any运算符
any运算符通常与比较运算符一起使用。使用any运算符时,通过比较运算符将一个表达式的值与子查询返回的一列值逐一进行比较,若某次比较结果为true,否则为false。
select * from
student join classes on student.class_no=classes.class_no
join choose on choose.student_no=student.student_no
where score > any(
select score from choose where class_no = 1;
);
(5)子查询+all运算符
all运算符通常与比较运算符一起使用。使用all运算符时,通过比较运算符将一个表达式的值与子查询返回的一列值逐一进行比较,若所有比较结果为true,则为true,否则为false。
select * from
student join classes on student.class_no=classes.class_no
join choose on choose.student_no=student.student_no
where score > all(
select score from choose where class_no = 1;
);
12.正则表达式模糊查询
与like运算符相似,正则表达式主要用于判断一个字符串是否与给定的模式匹配。但正则表达式的模式匹配功能比立刻运算符的模式匹配功能更为强大,且更加灵活。使用正则表达式进行模糊查询时,需要使用regexp关键字,语法格式如下:
字段名 [not] regexp [binary] ‘正则表达式’
说明:正则表达式匹配英文字母时,默认情况下不区分大小写,除非添加binary选项或者将字符序collation设置为bin或者cs。
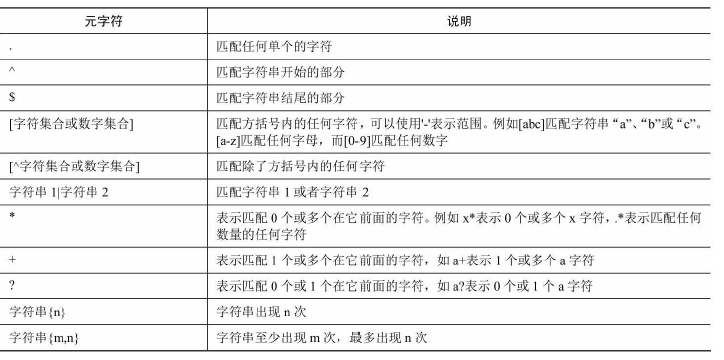
正则表达式由一些普通字符和一些元字符构成,普通字符包括大写字母,小写字母和数字,甚至是中文简体字符。而元字符具有特殊的含义。
元字符:
(1)检索含有‘java’的课程信息
select * from course where course_name regexp ‘java’;
(2)检索以‘java’结尾的课程信息
select * from course where course_name regexp ‘java$’;
(3)检索以‘java’开头的课程信息
select * from course where course_name regexp ‘^java’;
(4)检索以15或者18开头的数字,后面跟着9个数字
select * from course where course_number regexp ‘1[58][0-9]{9}’
13.MYISAM存储引擎的全文检索
对于海量数据库而言,使用like关键字或者正则表达式对字符串进行模糊查询,很多时候无法使用索引,因此需要进行全表扫描,检索效率较低。如果模糊查询并发操作较多,将会急剧降低数据库的检索性能,甚至导致服务器宕机。
使用like或者正则表达式进行模糊查询,当模式的第一个字符是通配符时,将导致索引无法使用。
针对这一个问题,MYSQL中的全文检索使用特定的分词技术,利用查询的关键字和查询字段内容之间的相关度进行检索。通过全文索引可以提高文本匹配的速度。
格式:
select 字段列表
from 表名
where match (全文索引字段1,全文索引字段2, …) against (搜索关键字[全文检索方式])
注意:使用全文检索前,需要在某些字段创建全文索引,使之成为全文索引字段。
(1)检索书名或者简介中设计"practices"单词的所有图书信息
select * from book where match (name, brief_introduction) against (‘practices’)\G

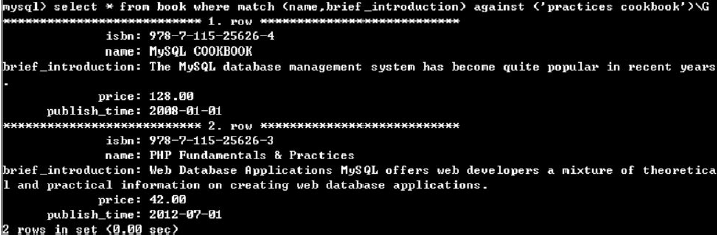
(2)检索书名或者简介中设计"practices"或者“cookbook”单词的所有图书信息
select * from book where match (name, brief_introduction) against (‘practices cookbook’)\G
(3)MYSQL对于全文检索的结果集是按照关联度进行排序的(大致,实际上比较繁杂)。而关联度信息正是全文检索的子句得出的结果
select isbn,name match(name, brief_introduction) against (‘practices cookbook’) 关联度 from book;
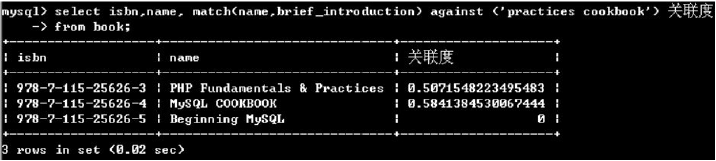
(4)MYSQL在执行全文检索时,会计算检索词在表中记录的频率,如果频率高达100%,意味着所有记录都含有该检索词,那么该全文检索实际上没有太多意义。
MYSQL在进行全文检索时,默认情况下忽略权重超过50%的记录,这个50%称为阈值。
(5)MYSQL对搜索关键字规定了最小长度和最大长度
show variables like ‘ft_min_word_len’;
show variables like ‘ft_max_word_len’;
这两个变量是静态变量,不能使用set命令设置,可以在my.cnf配置文件的[mysqld]选项组中加上想要的设置。
(6)MYSQL在MYISAM引擎的全文搜索中,内置了545个停用词,其中包括has,all,be,been,that等单词。MYISAM忽略搜索中的停用词,可以使用show variables like 'ft_stopword_file’查看停用词。
‘ft_stopword_file’变量也是静态变量,无法使用set命令进行设置,管理员可以自行创建停用词文件,然后在my.cnf配置文件的[mysqld]选项组中加上“ft_stopword_file=‘文件路径’”的方法设置全文检索停用词。
14.全文检索方式
常用全文检索方式有3种:自然语言检索,布尔检索和查询扩展检索
(1).自然语言检索
MYSQL全文检索中的默认类型,单表查询,存在阈值限制
(2).布尔检索
没有阈值限制,且可以进行多表查询,还可以包含特定意义的操作符,如+,-,<,>等。
(3).查询扩展检索
查询扩展检索是对自然语言检索的一种改动,当查询短语很短时游泳。先进行自然语言检索,然后把关联度较高的记录中的词添加到搜索关键字中进行二次自然语言检索,然后返回查询结果集。
15.innodb表的全文检索
(1)innodb存储引擎忽略了全文检索中阈值的概念
(2)innodb_ft_min_token_size(默认值3)和innodb_ft_max_token_size(默认值84)定义了搜索关键字的最小长度以及最大长度
(3)innodb_ft_enable_stopword(默认值ON)定义了是否开启停用词
(4)innodb的停用词在information_schema数据库的INNODB_FT_DEFAULT_STOPWORD表中定义







![[IMX] 02.GPIO 寄存器](https://i-blog.csdnimg.cn/direct/d8e69ec1a56841cc8d8dcb616936f599.png)