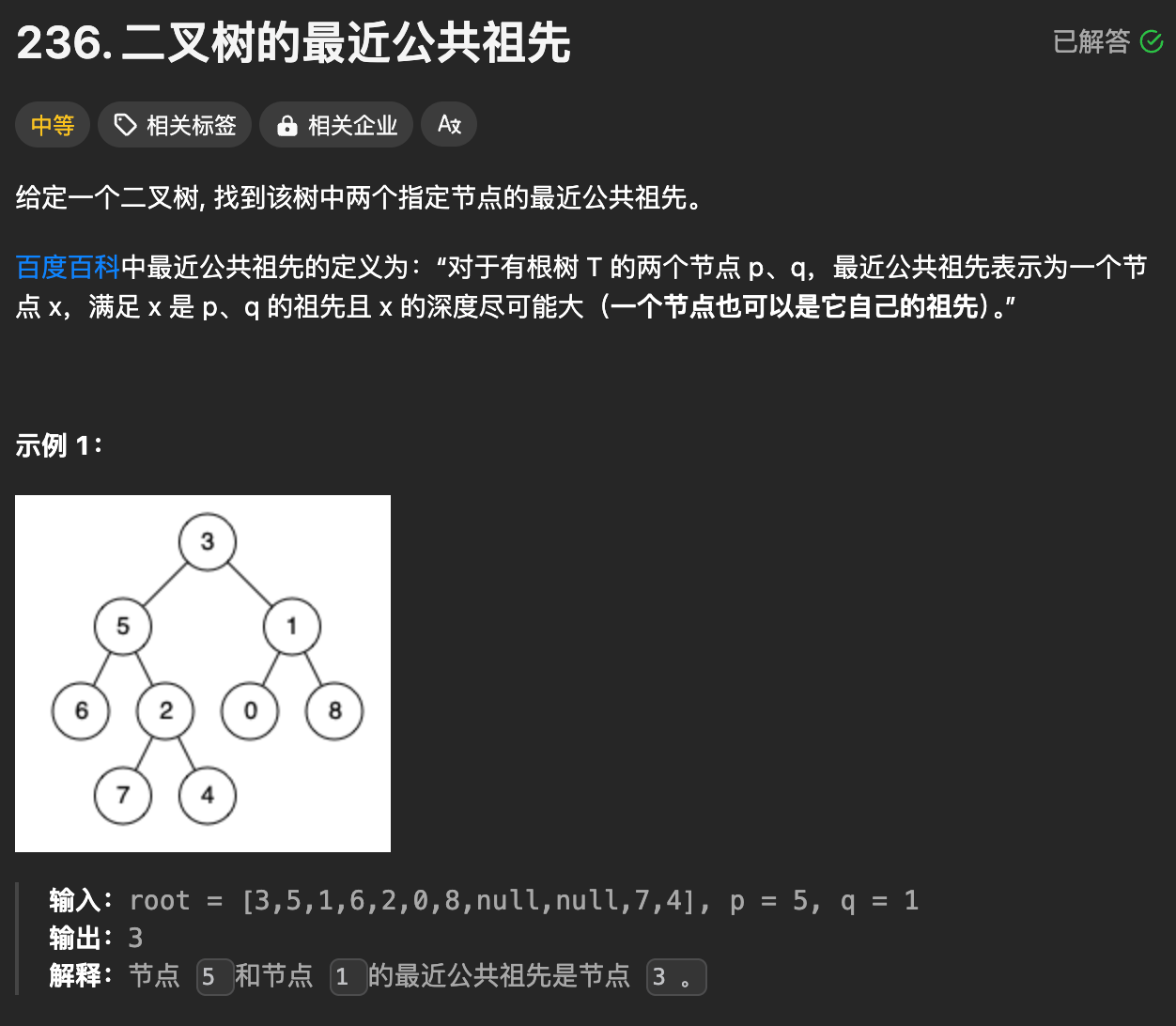
UniApp 实现的语音输入与语音识别功能
最近在开发跨平台应用时,客户要求添加语音输入功能以提升用户体验。经过一番调研和实践,我成功在UniApp项目中实现了语音输入与识别功能,现将过程和方法分享出来,希望对有类似需求的开发者有所帮助。
为什么需要语音输入功能?
随着移动设备的普及,语音交互已成为一种高效的人机交流方式。与传统的文字输入相比,语音输入具有以下优势:
- 操作便捷:免去键盘敲击,尤其适合单手操作或行走等场景
- 输入高效:语音输入速度通常快于手动输入
- 提升体验:为特定人群(如老年人、视障人士)提供便利
- 解放双手:适用于驾车、做家务等无法腾出手打字的场景
在商业应用中,语音输入可以显著降低用户的操作门槛,提高转化率和用户留存。
技术方案选型
在UniApp环境中实现语音识别,主要有三种方案:
- 使用原生插件:调用各平台的原生语音识别能力
- 对接云服务:接入第三方语音识别API(如百度、讯飞等)
- Web API:在H5平台利用Web Speech API
经过对比和测试,我最终采用了混合方案:
- 在App平台使用原生插件获取最佳体验
- 在微信小程序使用微信自带的语音识别能力
- 在H5平台尝试使用Web Speech API,不支持时降级为云服务API
实现步骤
1. App端实现(基于原生插件)
首先需要安装语音识别插件。我选择了市场上比较成熟的speech-baidu插件,这是基于百度语音识别SDK封装的UniApp插件。
安装插件后,在manifest.json中配置:
"app-plus": {
"plugins": {
"speech": {
"baidu": {
"appid": "你的百度语音识别AppID",
"apikey": "你的API Key",
"secretkey": "你的Secret Key"
}
}
},
"distribute": {
"android": {
"permissions": [
"<uses-permission android:name=\"android.permission.RECORD_AUDIO\"/>",
"<uses-permission android:name=\"android.permission.INTERNET\"/>"
]
}
}
}
接下来创建语音识别组件:
<template>
<view class="voice-input-container">
<view
class="voice-btn"
:class="{ 'recording': isRecording }"
@touchstart="startRecord"
@touchend="stopRecord"
@touchcancel="cancelRecord"
>
<image :src="isRecording ? '/static/mic-active.png' : '/static/mic.png'" mode="aspectFit"></image>
<text>{{ isRecording ? '松开结束' : '按住说话' }}</text>
</view>
<view v-if="isRecording" class="recording-tip">
<text>正在聆听...</text>
<view class="wave-container">
<view
v-for="(item, index) in waveItems"
:key="index"
class="wave-item"
:style="{ height: item + 'rpx' }"
></view>
</view>
</view>
</view>
</template>
<script>
// #ifdef APP-PLUS
const speechPlugin = uni.requireNativePlugin('speech-baidu');
// #endif
export default {
name: 'VoiceInput',
data() {
return {
isRecording: false,
timer: null,
waveItems: [10, 15, 20, 25, 30, 25, 20, 15, 10]
}
},
props: {
lang: {
type: String,
default: 'zh' // zh: 中文, en: 英文
},
maxDuration: {
type: Number,
default: 60 // 最长录音时间,单位秒
}
},
methods: {
startRecord() {
if (this.isRecording) return;
// 申请录音权限
uni.authorize({
scope: 'scope.record',
success: () => {
this.isRecording = true;
this.startWaveAnimation();
// #ifdef APP-PLUS
speechPlugin.start({
vadEos: 3000, // 静音超时时间
language: this.lang === 'zh' ? 'zh-cn' : 'en-us'
}, (res) => {
if (res.errorCode === 0) {
// 识别结果
this.$emit('result', res.result);
} else {
uni.showToast({
title: `识别失败: ${res.errorCode}`,
icon: 'none'
});
}
this.isRecording = false;
this.stopWaveAnimation();
});
// #endif
// 设置最长录制时间
this.timer = setTimeout(() => {
if (this.isRecording) {
this.stopRecord();
}
}, this.maxDuration * 1000);
},
fail: () => {
uni.showToast({
title: '请授权录音权限',
icon: 'none'
});
}
});
},
stopRecord() {
if (!this.isRecording) return;
// #ifdef APP-PLUS
speechPlugin.stop();
// #endif
clearTimeout(this.timer);
this.isRecording = false;
this.stopWaveAnimation();
},
cancelRecord() {
if (!this.isRecording) return;
// #ifdef APP-PLUS
speechPlugin.cancel();
// #endif
clearTimeout(this.timer);
this.isRecording = false;
this.stopWaveAnimation();
},
// 波形动画
startWaveAnimation() {
this.waveAnimTimer = setInterval(() => {
this.waveItems = this.waveItems.map(() => Math.floor(Math.random() * 40) + 10);
}, 200);
},
stopWaveAnimation() {
clearInterval(this.waveAnimTimer);
this.waveItems = [10, 15, 20, 25, 30, 25, 20, 15, 10];
}
},
beforeDestroy() {
this.cancelRecord();
}
}
</script>
<style scoped>
.voice-input-container {
width: 100%;
}
.voice-btn {
width: 200rpx;
height: 200rpx;
border-radius: 100rpx;
background-color: #f5f5f5;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
margin: 0 auto;
}
.voice-btn.recording {
background-color: #e1f5fe;
box-shadow: 0 0 20rpx rgba(0, 120, 255, 0.5);
}
.voice-btn image {
width: 80rpx;
height: 80rpx;
margin-bottom: 10rpx;
}
.recording-tip {
margin-top: 30rpx;
text-align: center;
}
.wave-container {
display: flex;
justify-content: center;
align-items: flex-end;
height: 80rpx;
margin-top: 20rpx;
}
.wave-item {
width: 8rpx;
background-color: #1890ff;
margin: 0 5rpx;
border-radius: 4rpx;
transition: height 0.2s;
}
</style>
2. 微信小程序实现
微信小程序提供了原生的语音识别API,使用非常方便:
// 在小程序环境下的代码
startRecord() {
// #ifdef MP-WEIXIN
this.isRecording = true;
this.startWaveAnimation();
const recorderManager = wx.getRecorderManager();
recorderManager.onStart(() => {
console.log('录音开始');
});
recorderManager.onStop((res) => {
this.isRecording = false;
this.stopWaveAnimation();
// 将录音文件发送到微信后台识别
wx.showLoading({ title: '识别中...' });
const { tempFilePath } = res;
wx.uploadFile({
url: 'https://api.weixin.qq.com/cgi-bin/media/voice/translatecontent',
filePath: tempFilePath,
name: 'media',
formData: {
access_token: this.accessToken,
format: 'mp3',
voice_id: Date.now(),
lfrom: this.lang === 'zh' ? 'zh_CN' : 'en_US',
lto: 'zh_CN'
},
success: (uploadRes) => {
wx.hideLoading();
const data = JSON.parse(uploadRes.data);
if (data.errcode === 0) {
this.$emit('result', data.result);
} else {
uni.showToast({
title: `识别失败: ${data.errmsg}`,
icon: 'none'
});
}
},
fail: () => {
wx.hideLoading();
uni.showToast({
title: '语音识别失败',
icon: 'none'
});
}
});
});
recorderManager.start({
duration: this.maxDuration * 1000,
sampleRate: 16000,
numberOfChannels: 1,
encodeBitRate: 48000,
format: 'mp3'
});
// #endif
},
stopRecord() {
// #ifdef MP-WEIXIN
wx.getRecorderManager().stop();
// #endif
// ...与App端相同的代码...
}
需要注意的是,微信小程序的语音识别需要获取access_token,这通常需要在后端实现并提供接口。
3. H5端实现
在H5端,我们可以利用Web Speech API来实现语音识别,当浏览器不支持时则降级为云服务API:
startRecord() {
// #ifdef H5
this.isRecording = true;
this.startWaveAnimation();
// 检查浏览器是否支持Speech Recognition
if ('webkitSpeechRecognition' in window || 'SpeechRecognition' in window) {
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
this.recognition = new SpeechRecognition();
this.recognition.lang = this.lang === 'zh' ? 'zh-CN' : 'en-US';
this.recognition.continuous = false;
this.recognition.interimResults = false;
this.recognition.onresult = (event) => {
const result = event.results[0][0].transcript;
this.$emit('result', result);
};
this.recognition.onerror = (event) => {
uni.showToast({
title: `识别错误: ${event.error}`,
icon: 'none'
});
};
this.recognition.onend = () => {
this.isRecording = false;
this.stopWaveAnimation();
};
this.recognition.start();
} else {
// 不支持Web Speech API,调用云服务API
this.useCloudSpeechAPI();
}
// #endif
// 设置最长录制时间
this.timer = setTimeout(() => {
if (this.isRecording) {
this.stopRecord();
}
}, this.maxDuration * 1000);
},
stopRecord() {
// #ifdef H5
if (this.recognition) {
this.recognition.stop();
}
// #endif
// ...与App端相同的代码...
},
useCloudSpeechAPI() {
// 这里实现降级方案,调用后端接口进行语音识别
uni.chooseFile({
count: 1,
type: 'file',
extension: ['.mp3', '.wav'],
success: (res) => {
const tempFilePath = res.tempFilePaths[0];
// 上传音频文件到后端进行识别
uni.uploadFile({
url: this.apiBaseUrl + '/speech/recognize',
filePath: tempFilePath,
name: 'audio',
formData: {
lang: this.lang
},
success: (uploadRes) => {
const data = JSON.parse(uploadRes.data);
if (data.code === 0) {
this.$emit('result', data.result);
} else {
uni.showToast({
title: `识别失败: ${data.msg}`,
icon: 'none'
});
}
},
complete: () => {
this.isRecording = false;
this.stopWaveAnimation();
}
});
}
});
}
4. 通用接口封装
为了让调用方便,我封装了一个统一的API:
// 在 utils/speech.js 中
const Speech = {
// 开始语音识别
startRecognize(options) {
const { lang = 'zh', success, fail, complete } = options;
// #ifdef APP-PLUS
const speechPlugin = uni.requireNativePlugin('speech-baidu');
speechPlugin.start({
vadEos: 3000,
language: lang === 'zh' ? 'zh-cn' : 'en-us'
}, (res) => {
if (res.errorCode === 0) {
success && success(res.result);
} else {
fail && fail(res);
}
complete && complete();
});
return {
stop: () => speechPlugin.stop(),
cancel: () => speechPlugin.cancel()
};
// #endif
// #ifdef MP-WEIXIN
// 微信小程序实现逻辑
// ...
// #endif
// #ifdef H5
// H5实现逻辑
// ...
// #endif
}
};
export default Speech;
实战案例:聊天应用中的语音输入
现在,我们来看一个实际应用场景 - 在聊天应用中添加语音输入功能:
<template>
<view class="chat-input-container">
<view class="chat-tools">
<image
:src="isVoiceMode ? '/static/keyboard.png' : '/static/mic.png'"
@tap="toggleInputMode"
></image>
<image src="/static/emoji.png" @tap="showEmojiPicker"></image>
</view>
<view v-if="!isVoiceMode" class="text-input">
<textarea
v-model="message"
auto-height
placeholder="请输入消息..."
:focus="textFocus"
@focus="onFocus"
@blur="onBlur"
></textarea>
</view>
<view v-else class="voice-input">
<voice-input @result="onVoiceResult"></voice-input>
</view>
<button
class="send-btn"
:disabled="!message.trim()"
@tap="sendMessage"
>发送</button>
</view>
</template>
<script>
import VoiceInput from '@/components/voice-input/voice-input.vue';
export default {
components: {
VoiceInput
},
data() {
return {
message: '',
isVoiceMode: false,
textFocus: false
};
},
methods: {
toggleInputMode() {
this.isVoiceMode = !this.isVoiceMode;
if (!this.isVoiceMode) {
this.$nextTick(() => {
this.textFocus = true;
});
}
},
onVoiceResult(result) {
this.message = result;
this.isVoiceMode = false;
},
sendMessage() {
if (!this.message.trim()) return;
this.$emit('send', this.message);
this.message = '';
},
onFocus() {
this.textFocus = true;
},
onBlur() {
this.textFocus = false;
},
showEmojiPicker() {
// 显示表情选择器
}
}
};
</script>
<style>
.chat-input-container {
display: flex;
align-items: center;
padding: 20rpx;
border-top: 1rpx solid #eee;
background-color: #fff;
}
.chat-tools {
display: flex;
margin-right: 20rpx;
}
.chat-tools image {
width: 60rpx;
height: 60rpx;
margin-right: 20rpx;
}
.text-input {
flex: 1;
background-color: #f5f5f5;
border-radius: 10rpx;
padding: 10rpx 20rpx;
}
.text-input textarea {
width: 100%;
min-height: 60rpx;
max-height: 240rpx;
}
.voice-input {
flex: 1;
display: flex;
justify-content: center;
}
.send-btn {
width: 140rpx;
height: 80rpx;
line-height: 80rpx;
font-size: 28rpx;
margin-left: 20rpx;
padding: 0;
background-color: #1890ff;
color: #fff;
}
.send-btn[disabled] {
background-color: #ccc;
}
</style>
性能优化和注意事项
在实际开发中,我遇到了一些需要特别注意的问题:
1. 权限处理
语音识别需要麦克风权限,不同平台的权限处理方式不同:
// 统一请求录音权限
requestAudioPermission() {
return new Promise((resolve, reject) => {
// #ifdef APP-PLUS
const permissions = ['android.permission.RECORD_AUDIO'];
plus.android.requestPermissions(
permissions,
function(e) {
if (e.granted.length === permissions.length) {
resolve();
} else {
reject(new Error('未授予录音权限'));
}
},
function(e) {
reject(e);
}
);
// #endif
// #ifdef MP-WEIXIN || MP-BAIDU
uni.authorize({
scope: 'scope.record',
success: () => resolve(),
fail: (err) => reject(err)
});
// #endif
// #ifdef H5
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
navigator.mediaDevices.getUserMedia({ audio: true })
.then(() => resolve())
.catch(err => reject(err));
} else {
reject(new Error('浏览器不支持录音功能'));
}
// #endif
});
}
2. 流量控制
语音识别需要上传音频数据,在移动网络下会消耗流量:
// 检查网络环境并提示用户
checkNetwork() {
uni.getNetworkType({
success: (res) => {
if (res.networkType === '2g' || res.networkType === '3g') {
uni.showModal({
title: '流量提醒',
content: '当前处于移动网络环境,语音识别可能消耗较多流量,是否继续?',
success: (confirm) => {
if (confirm.confirm) {
this.startSpeechRecognition();
}
}
});
} else {
this.startSpeechRecognition();
}
}
});
}
3. 性能优化
长时间语音识别会增加内存和电量消耗,需要做好优化:
// 设置最大录音时长和自动结束
setupMaxDuration() {
if (this.timer) {
clearTimeout(this.timer);
}
this.timer = setTimeout(() => {
if (this.isRecording) {
uni.showToast({
title: '录音时间过长,已自动结束',
icon: 'none'
});
this.stopRecord();
}
}, this.maxDuration * 1000);
}
// 空闲自动停止
setupVAD() {
// 监测静音,如果用户停止说话3秒,自动结束录音
let lastAudioLevel = 0;
let silenceCounter = 0;
this.vadTimer = setInterval(() => {
// 获取当前音量
const currentLevel = this.getAudioLevel();
if (Math.abs(currentLevel - lastAudioLevel) < 0.05) {
silenceCounter++;
if (silenceCounter > 30) { // 3秒 (30 * 100ms)
this.stopRecord();
}
} else {
silenceCounter = 0;
}
lastAudioLevel = currentLevel;
}, 100);
}
增强功能:语音合成(TTS)
除了语音识别外,语音合成(Text-to-Speech)也是很有用的功能,可以将文本转换为语音:
// 语音合成
textToSpeech(text, options = {}) {
const { lang = 'zh', speed = 5, volume = 5 } = options;
// #ifdef APP-PLUS
const speechPlugin = uni.requireNativePlugin('speech-baidu');
return new Promise((resolve, reject) => {
speechPlugin.textToSpeech({
text,
language: lang === 'zh' ? 'zh-cn' : 'en-us',
speed,
volume
}, (res) => {
if (res.errorCode === 0) {
resolve(res);
} else {
reject(new Error(`语音合成失败: ${res.errorCode}`));
}
});
});
// #endif
// #ifdef H5
return new Promise((resolve, reject) => {
if ('speechSynthesis' in window) {
const speech = new SpeechSynthesisUtterance();
speech.text = text;
speech.lang = lang === 'zh' ? 'zh-CN' : 'en-US';
speech.rate = speed / 10;
speech.volume = volume / 10;
speech.onend = () => {
resolve();
};
speech.onerror = (err) => {
reject(err);
};
window.speechSynthesis.speak(speech);
} else {
reject(new Error('当前浏览器不支持语音合成'));
}
});
// #endif
}
踩坑记录与解决方案
开发过程中,我遇到了一些常见问题与解决方法,分享如下:
- 百度语音插件初始化失败:检查API密钥配置和网络环境,特别是HTTPS限制
- H5录音无法使用:多数浏览器要求必须在HTTPS环境下才能使用麦克风
- 识别结果不准确:尝试调整录音参数,如采样率、声道数等,或者使用更专业的噪声抑制算法
- 微信小程序调用失败:检查access_token是否有效,注意token有效期
- 不同设备体验差异大:针对低端设备优化,如减少动画效果、降低采样率等
我们的解决方案是进行兼容性检测,并根据设备性能自动调整参数:
// 检测设备性能并调整参数
detectDevicePerformance() {
const platform = uni.getSystemInfoSync().platform;
const brand = uni.getSystemInfoSync().brand;
const model = uni.getSystemInfoSync().model;
// 低端安卓设备优化
if (platform === 'android') {
// 特定型号的优化
if (brand === 'samsung' && model.includes('SM-J')) {
return {
sampleRate: 8000,
quality: 'low',
useVAD: false // 禁用语音活动检测,降低CPU占用
};
}
}
// 默认配置
return {
sampleRate: 16000,
quality: 'high',
useVAD: true
};
}
总结与展望
通过本文,我们探讨了在UniApp中实现语音输入与识别功能的多种方案,并提供了具体的代码实现。这些实现方案已在实际项目中得到验证,能够满足大多数应用场景的需求。
语音技术在移动应用中的重要性不断提升,未来可以探索更多高级功能:
- 离线语音识别:降低网络依赖,提高响应速度
- 多语言支持:增加更多语言的识别能力
- 声纹识别:通过语音实现用户身份验证
- 情感分析:从语音中识别用户情绪
希望本文对你在UniApp中实现语音功能有所帮助!如有问题欢迎在评论区交流讨论。
参考资料
- UniApp官方文档
- 百度语音识别API文档
- Web Speech API